はじめに
docker composeを使って、ollama + open-webui + mcpo によるローカルLLMでMCPサーバーの使用を体験してみようと思います。初心者向け解説は他記事に任せます。自分がやったことを雑多にまとめます。
Open WebUIとMCPOでローカルLLMにMCPツールを使ってもらう この記事とほぼ内容かぶります。
異なるのはMCPOもdockerコンテナで建てたことです。
同記事ではdaemon化していて、より難しそう?全部dockerで統一したらいいのにな、と思いました。記事が4月だからまだmcpoコンテナが出ていなかったのか?
Open-webuiではMCPではなく、MCPOを使う理由
your cloud instance can’t speak directly to an MCP server running locally on your machine via stdio.
インスタンスは、stdio 経由でローカル マシン上で実行されている MCP サーバーに直接通信できません。
出典: MCP Support
使用するコンテナ
使うコンテナは以下のリポジトリ
記事作成時点ではmcpoのリポジトリがPublic archiveとなってから3ヶ月過ぎているが、大丈夫だろうか。他に移転してしまったのだろうか。知っている人いたら教えてください。軽くググった感じ出てきませんでした。 issueに「公式にPRしろ」というコメントが合ったので、upstreamリポジトリに合流したためPublic Archiveとなっているようです。1
DooD コンテナの自作
2025/7/17 追記
後述するように、dockerhub/mcpにてMCPサーバー自体をdockerによる実行環境に落とし込んでいる実績が多数あるので、mcpoもdockerとしてMCPサーバーをインストールできるべきです。フォークして作りました。1
やったことはapt install docker と npm install deno を追記しただけです。自身がdeno使いなので、そのうち自作MCPサーバーをdenoで作ってやろうと考えているので、ついで作業です。
コンテナの設定
まずはコンテナ構成をyamlに書きます。
# docker の場合
# docker run -t --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
# docker run -t -p 13000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui ghcr.io/open-webui/open-webui:cuda
services:
ollama:
image: ollama/ollama:0.9.6
volumes:
- ollama:/root/.ollama
ports:
- "11434:11434"
# 以下はGPUを使う人のみ
deploy:
resources:
reservations:
devices:
- capabilities: [gpu]
open-webui:
image: ghcr.io/open-webui/open-webui:cuda
hostname: open-webui
ports:
- "13000:8080"
volumes:
- open-webui:/app/backend/data
extra_hosts:
- "host.docker.internal:host-gateway"
# 以下はGPUを使う人のみ
deploy:
resources:
reservations:
devices:
# - driver: nvidia # お手本に書いてあったが、書くと動作しなかったのでコメントアウト
# - count: all # お手本に書いてあったが、書くと動作しなかったのでコメントアウト
- capabilities: [gpu]
mcpo:
image: u1and0/mcpo
ports:
- "18000:8000"
environment:
- DOCKER_HOST=unix:///var/run/docker.sock # DoonDする設定
volumes:
- /var/run/docker.sock:/var/run/docker.sock # DooDする設定
- ./config.json:/app/config.json # 後述のconfig.jsonと同期する設定
command:
["--config", "/app/config.json"] # 元のDockerfileのCMDは`mcpo --help`なので上書き必須
volumes:
ollama:
external: true # 既存volume使い回しのため
open-webui:
external: true # 既存volume使い回しのため
GPUを使うので、deployの部分に書き足しています。open-webuiはmainではなく、cudaタグを使用します。GPUを使用しないと低速なのでおすすめしませんが、どうしてもGPUが使えないけど試したい方は、open-webuiのタグをmainにしてdeploy以下をコメントアウトしましょう。
external: true は事前にdocker単体でvolumeを作っていたのでそれを使いまわすためにつけた。初めてdocker-compose.ymlでボリューム作る人には不要です。
DooD(Docker outside of Docker)2は、ホストOSのdocker環境をマウントし、コンテナがホストシステムに対してほぼ完全なroot権限を持つことになりますので、セキュリティリスクを受け入れられる場合にのみ記述してください。
config.jsonをmcpoコンテナにボリュームマウントすることで、config.jsonを書き換えるだけで自由にツールを入れ替えることができます。ツールを入れ替えたらmcpoコンテナだけを再起動してください。
MCPの設定
そしてMCPの設定をconfig.jsonに書きます。
{
"mcpServers": {
"memory": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-memory"
]
},
"time": {
"command": "uvx",
"args": [
"mcp-server-time",
"--local-timezone=Asia/Tokyo"
]
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
},
"duckduckgo": {
"command": "docker",
"args": [ "run", "-i", "--rm", "mcp/duckduckgo" ]
}
}
}
立ち上げるには、docker-compose.ymlとconfig.jsonを同じディレクトリに入れて、docker compose upです。構成簡単ですね。そしてブラウザにlocalhost:13000 を打ち込んで接続してください。open-webuiのログイン画面が表示されますので、メールアドレス(仮でOK)とパスワードを設定してログインしましょう。
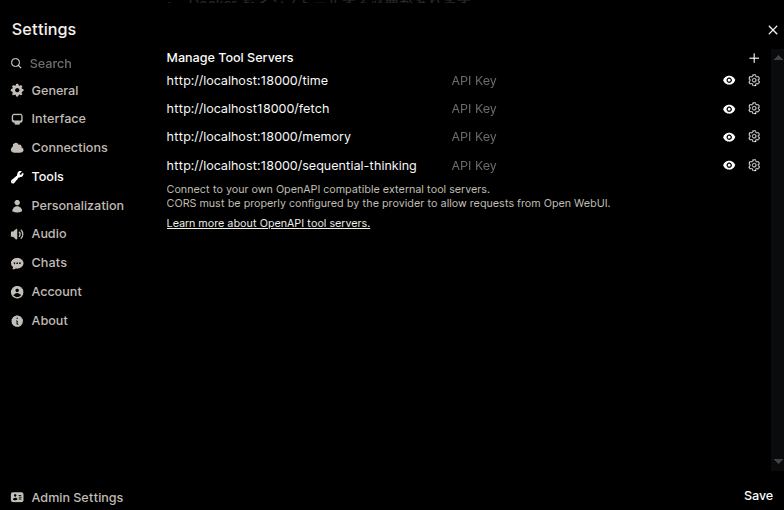
画像とconfig.jsonの内容が違いますが、書いた日付とキャプチャした日付が違うため。サーバーを外部においた場合はlocalhostを適切なIPに変えましょう。
次にユーザーセッティングからToolsを選択し、config.jsonに記載したツールとそのエンドポイントを入力しましょう。最後にSaveボタンを押してください。
時刻を聞いてみた
LLMには難しい、時刻を聞く問題。情報を与えられない限りLLMは適当な数値を言うはずです。
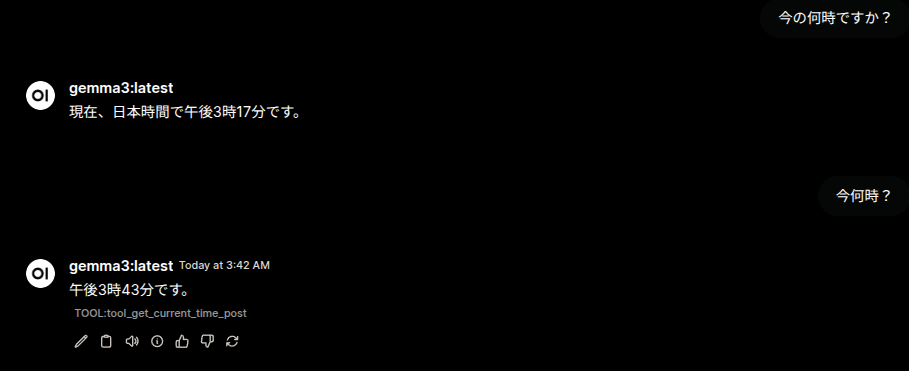
1つ目の回答はMCPサーバー使っていないながらもやや惜しい、AM3:40をPM3:17と間違えています。ツールを使っていなければ当然です。
2つ目の回答はAM3:42を午後3時43分と答えています。AMとPMを間違えていますが、TOOL:tool_get_current_time_post と表示されているので、ツールは使えたようです。
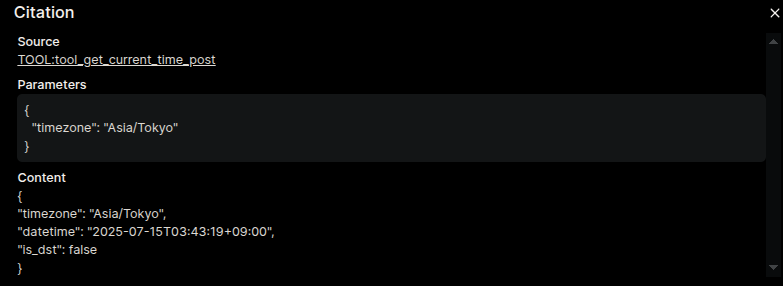
TOOL:... の部分をクリックすると、設定したタイムゾーンや取得した日時、確かに03:43と書かれていますが、AMかPMか、12時間表記か24時間表記か明記されていないので、前の会話の「午後3時...」に引っ張られてしまったのでしょう。つまりツールを使えたが、前の会話のせいで凡ミスした、と。
MCPサーバーの疎通チェック
ここまでで問題がない方は無視して次に進んでください。
MCPサーバーが正常に動作しない場合のチェック項目です。
- OpenWebUIのTool設定を保存したときにエラーが出ないか。エラーが出る場合はmcpoサーバーが立ち上がっているか、
docker psやdocker compose psで確認してください。 - IPアドレス、ポート番号が正しいか。
ip aコマンドやdocker-compose.ymlの設定と見比べてください。OpenWebUIを外部サーバーに設定した場合はファイアウォールの設定やポート開放が必要です。 -
curl http://localhost:18000/TOOL_NAME/openapi.jsonでレスポンスが返ってくるか。TOOL_NAMEは適切なツール名に変更して下さい。レスポンスが返ってこなければuvx,npx,dockerによるMCPサーバーのインストールが正常に完了しているかコンテナログを見るなどして確認してください。 - ツールに対してLLMが使うリクエストをPOSTしてみる。例えばtime MCPサーバーの場合、
curl http://localhost:18000/time/get_current_time -H "Content-Type: application/json" -d '{"timezone": "Asia/Tokyo"}'のレスポンスをLLMは使用します。 レスポンスが異常の場合は、項目3と同様の手順でMCPサーバーのインストール状態を確認してください。
様々なMCPコンテナ
コンテナとしてポータブルに使えるMCPサーバーがdockerhub/mcpこんなにも出ていることに驚きました。日々のニュース記事で見る感じ続々と出ているとは聞いていたけど、記事を書いた時点で142リポジトリ!alephpiece/mcpoではdockerコマンドは使えず、dockerを使って公開されているコンテナ、あるいはnpxまたはuvxを使って公開されているコードを取得してくるようです。dockerならdockerhub、uvxならPyPI, npxならnpmから。
複数のMCPサーバーを使いこなしてもらう
2025/7/17追記
MCPサーバーをdockerコンテナとしてインストールできるようになったので、テストがてらdockerで導入したMCPサーバーとnpxで導入したMCPサーバーをLLMに併用してもらいます。
以下のプロンプトを打ち込んで、timeとduckduckgoを使ってまとめてもらいました。
現在、何月何日なのか確認の上、その日付で起こった歴史上重要なイベントを検索して結果をまとめてください
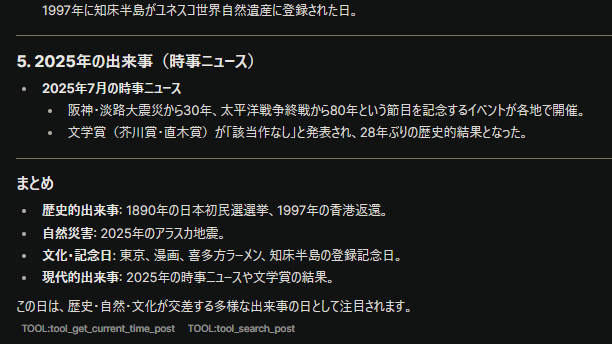
確かにTOOL:... に get_current_time_post と tool_serach_post が並んでいます。
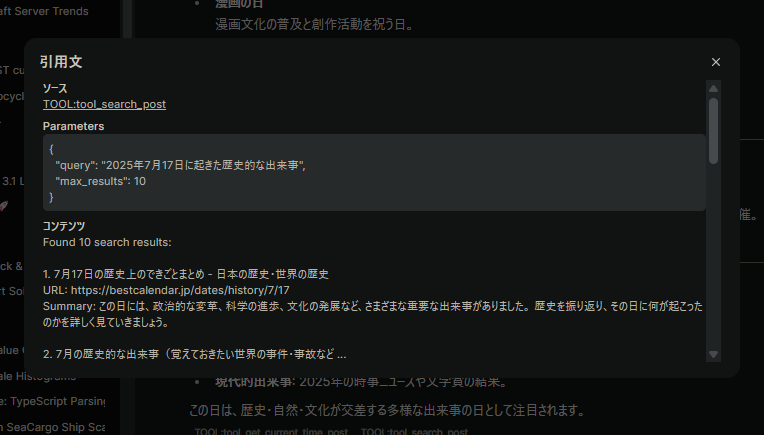
ツールの詳細を開くとそれぞれ時刻の取得と「2025年7月17日に起きた歴史的な出来事」をクエリとした検索を実行しています。
まとめ
open-webuiとollamaは以前から使用しており、セキュリティ面が気になる局面で使用できるかと準備だけしておりましたが、個人が用意するPCでは速度や規模の面でクラウドLLMに叶うはずもなく、この構成が活きることはありませんでした。
しかしながら、今になって到来しているMCPサーバーブーム!この技術はユーザーのニッチな要求に厳格に答えつつ、LLMと統合することでより柔軟性を取り入れたツール製作に役立つ技術です。LLMサーバーはユーザーのローカルなデータやAPIへアクセスできるので、クラウドLLMを使うよりローカルLLMを使うことで完全にセキュリティを保った構成でLLMツールを作成できるので、今後の伸びに非常に注目です。
-
公式がどこのこととは明確に書かれていませんでしたがたぶんopen-webui/mcpoのことだと思うので、こちらをフォークして、dockerコマンドが使える用に改造しました。フォークしっぱなしだとalephpiece氏の二の舞いになってしまうので、そのうちPRします。 ↩ ↩2 ↩3 ↩4
-
dindとdoodを勘違いしていました。うさぎさんの解説で勘違いが解けました。うさぎでもわかるdindとdoodしかしよーくこのセキュリティリスクのことを考えると、外部コードをLLMにバシバシ実行させる権限を与えるMCPサーバーが危険だから、わざわざコンテナに分離したのに、またホストのルート権限をコンテナに渡してしまうこの所業はまるで「島流しにした極悪殺人鬼にボートを渡していつでも本島に戻ってこれるようにした」かのよう...。本来の隔離という目的を無意味にしてしまう危険な所業。安易にコンテナとしてMCPを使えるようにしないで、より慎重に、コンテナ内で実行され得るソースコードを隅から隅までチェックする必要性が浮上してしまうので、
uvxやnpx経由のMCPサーバー使用をコンテナ分離して使用するのが安全でしょう。 ↩