※2023年8月現在troccoエージェント機能はクローズとなっております
この記事は
データエンジニアのためのSaaS「trocco(トロッコ)」のアドベントカレンダー 2021
3日目の記事になります。
こんにちは。trocco開発メンバーのいとうです。
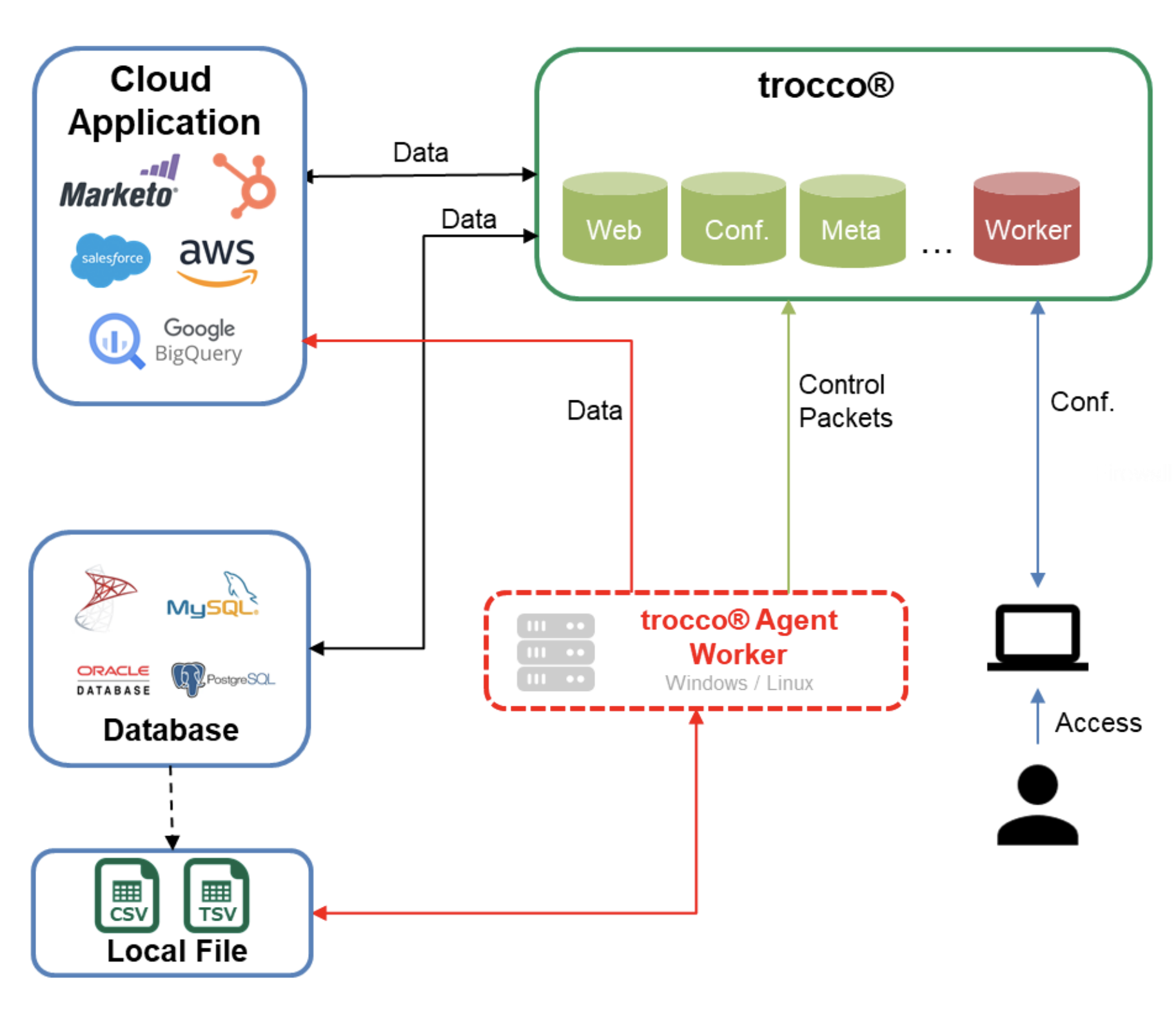
この記事ではtroccoエージェントを利用して
外部からのアクセスができない(が、内部起点にインターネットへはアクセスできる)サーバから、データをbigqueryに転送する仕組みを構築してみます。
背景
trocco®はインターネットに公開されたデータベースやサービスに対して
データを抽出したり送り込んだりできますが、ご利用者の環境によっては外部からのアクセスが許可できなかったりします。
例)オンプレなどのデータセンターに存在するサーバなど
そういった制約において、trocco®では以下の手段を用意しています。
- 踏み台方式
- エージェント方式
この記事ではエージェント方式について紹介します。
troccoエージェントとは
外部アクセスができないサーバの上に存在するデータを
troccoを使ってデータ連携する場合に利用できる機能です。
サーバーにエージェントプログラムを起動しておくことで、
定期的にtrocco®と通信しデータを転送できます。
今回は開発環境Macbookをオンプレサーバーの代わりとして構成します。
準備
trocco®の設定
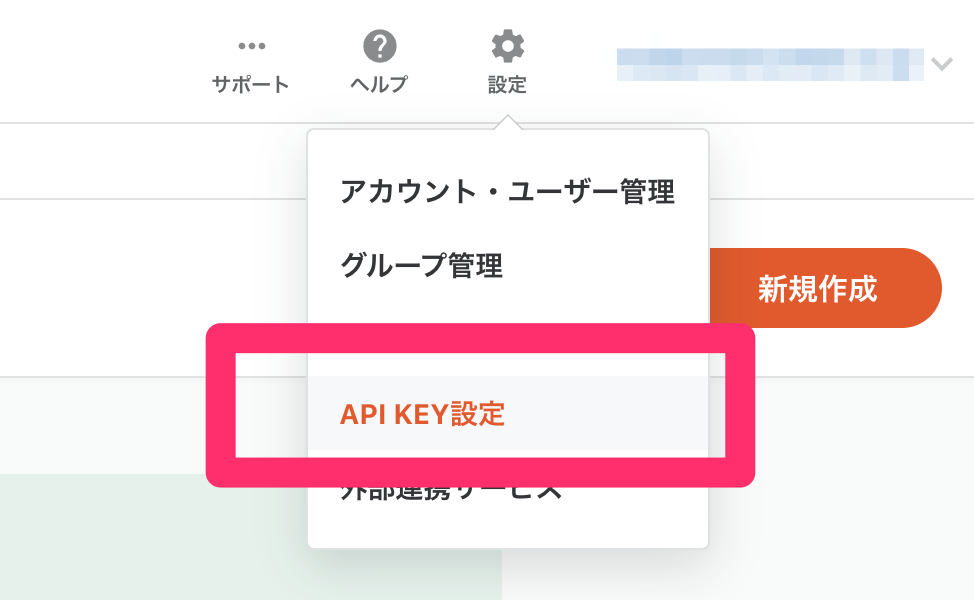
APIキーの発行
troccoエージェントとtrocco®との通信のためにAPIキー発行します。
ポータルページ右上の設定から「API KEY設定」を選択します。
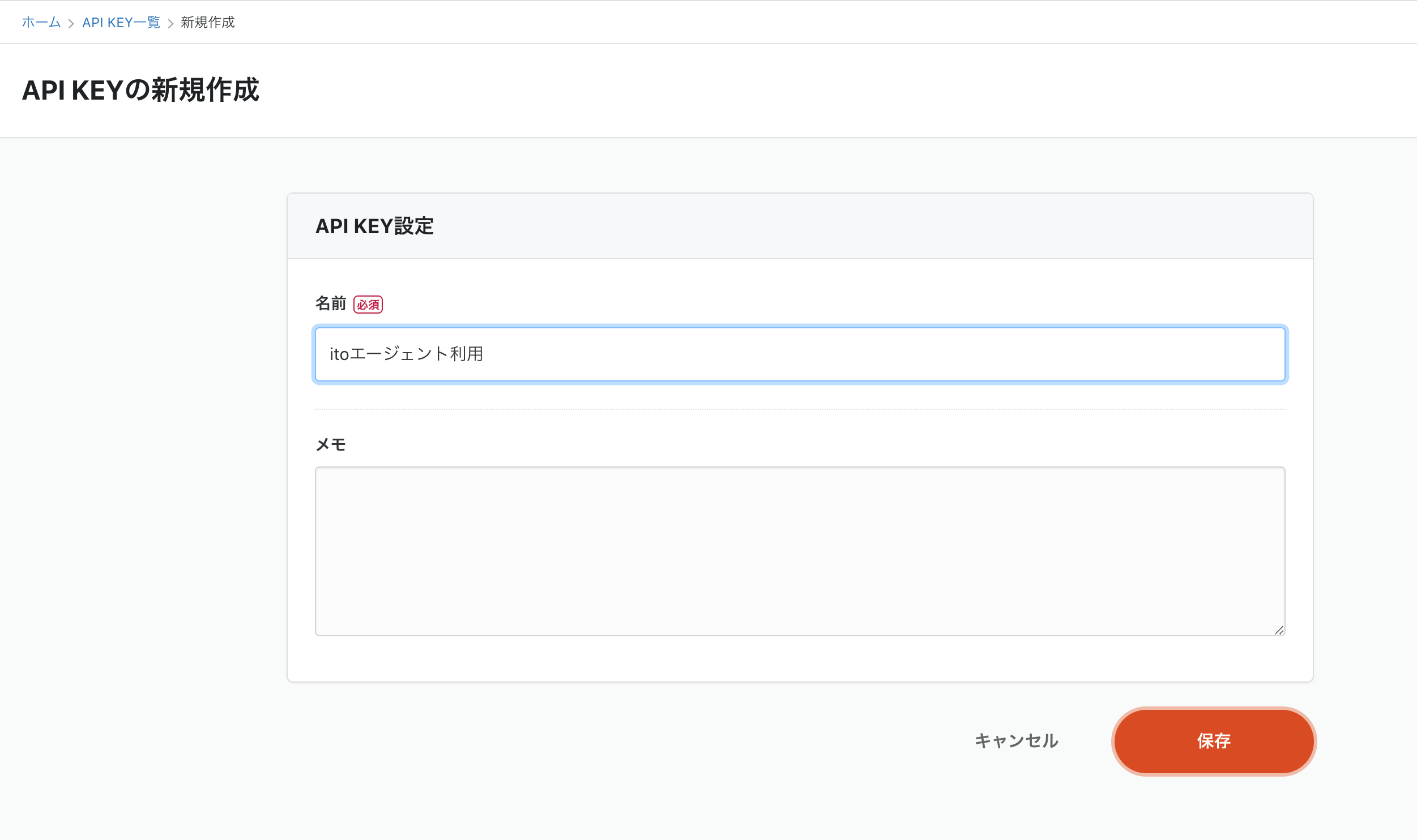
新規作成から、任意の情報を記載します。実運用では
利用者や用途できるだけ具体的な情報を残しておくと良さそうです。
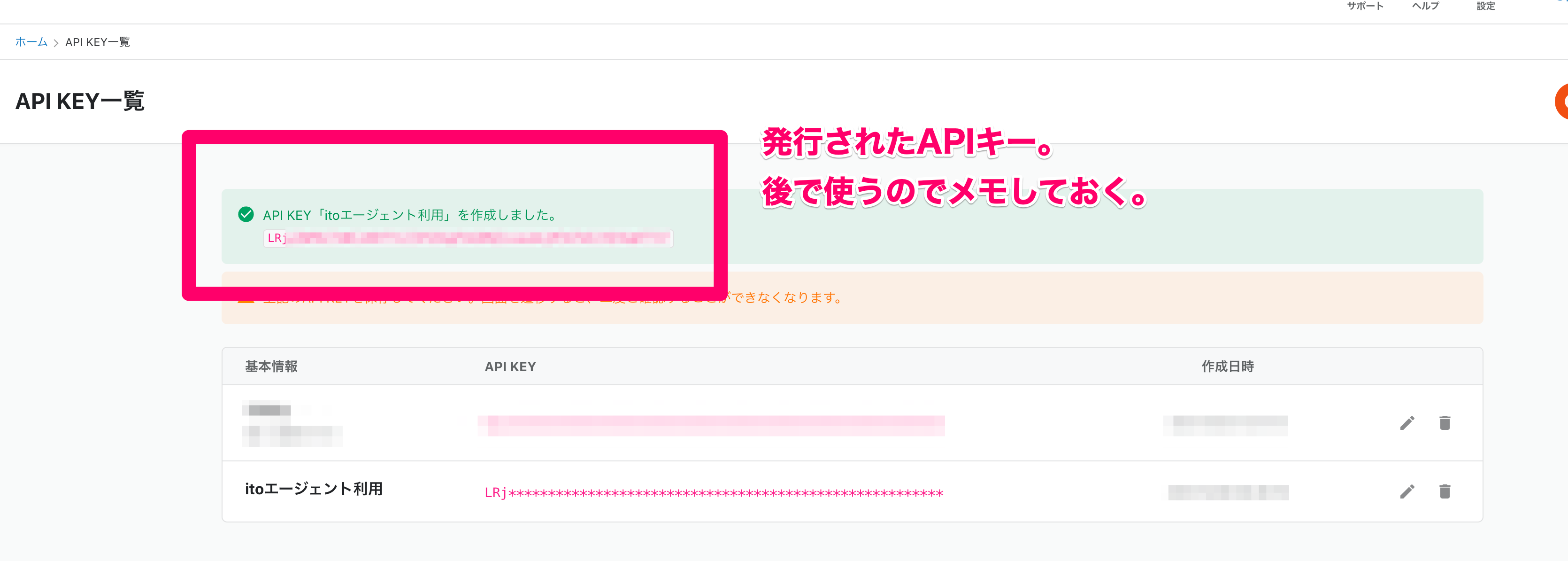
保存ボタンを押すと、APIキーが発行されます。APIキーはtrocco®内部で暗号化されているため、
ここの画面を抜けると参照できなくなります。
忘れないようにメモしておいてください。今回私はローカルPCのメモ帳にコピペしました。
エージェント定義の作成
trocco®上でエージェントの設定を作成します。
サイドメニューから「オンプレミス・データ転送」にある「エージェント」をクリックし
遷移先のページより、「新規作成」ボタンをクリックします。
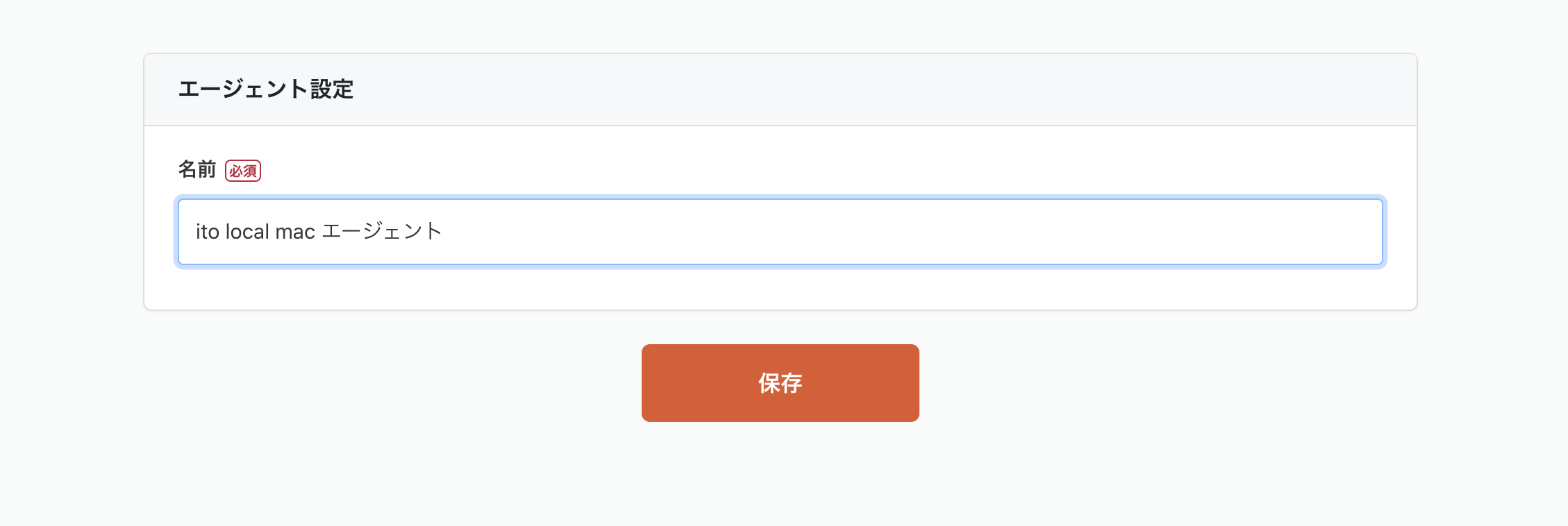
こちらの任意の名前を設定します。今回は「ito local mac エージェント」としました。
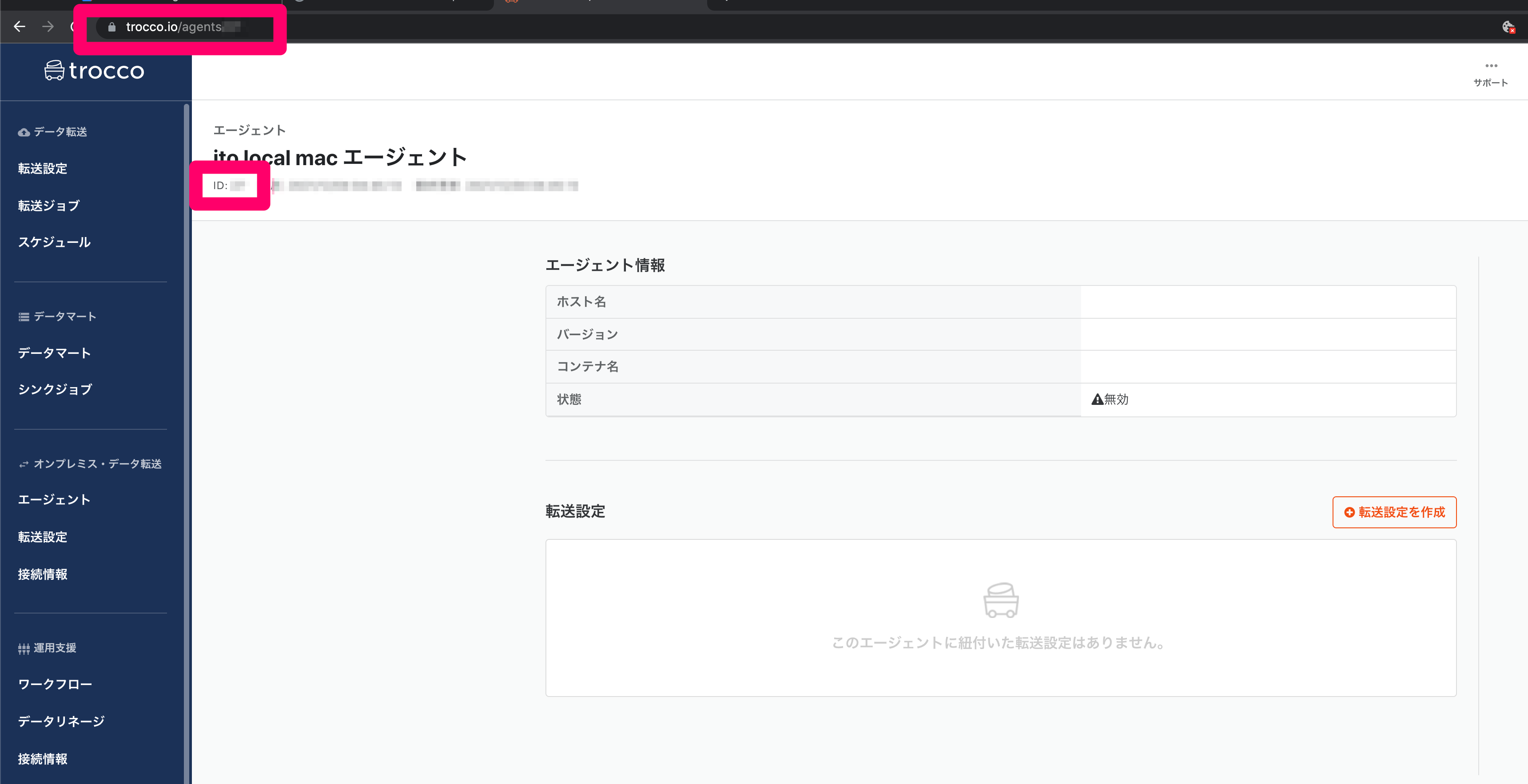
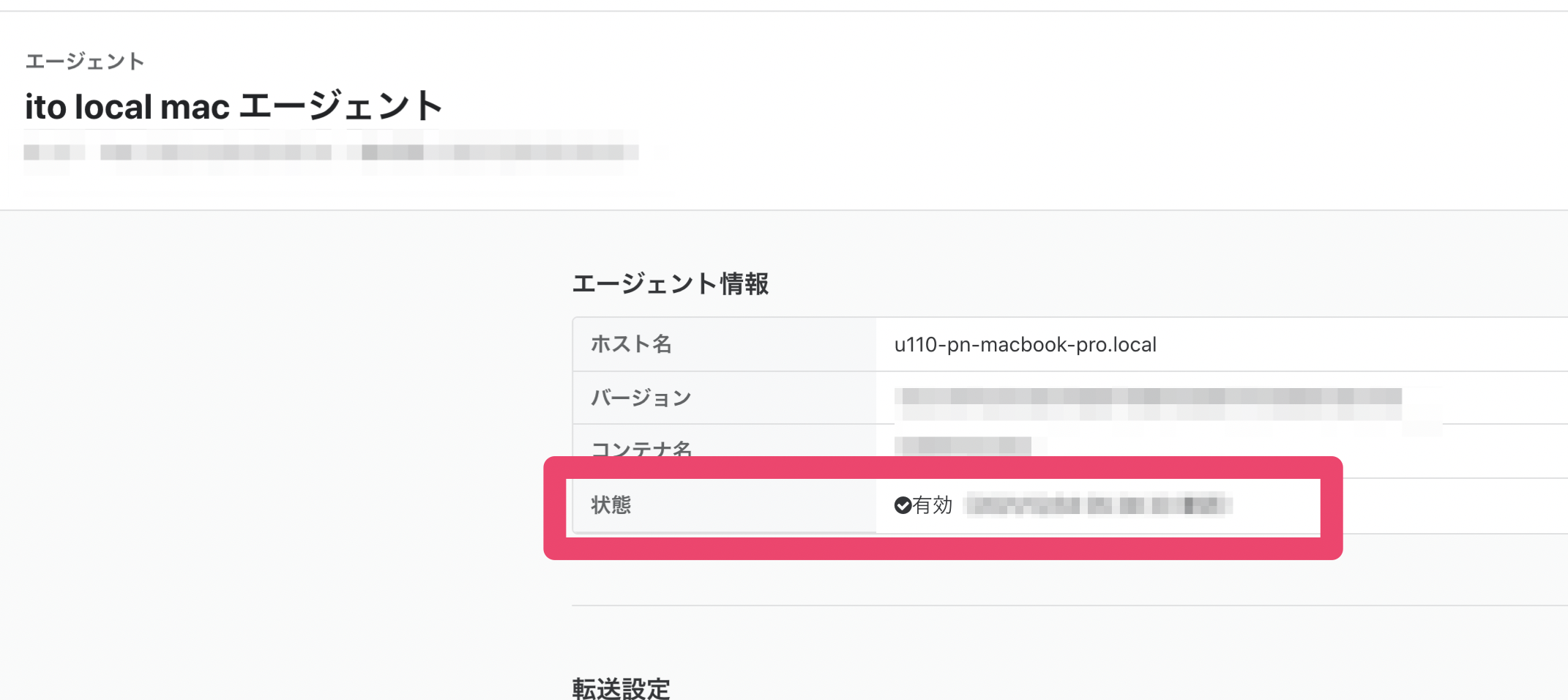
保存ボタンを押すと、エージェント詳細画面になります。ID(数値)が表示されていますので、こちらもメモしておきます。
IDは画面右上に表示されている数値、もしくはURLから確認できます。
オンプレサーバ(今回はMacbook)にエージェントプログラムをインストールした後に
もう一度この画面を利用しますが、trocco®の設定はここまでです。
サーバ側の設定
次はオンプレ側の設定になります。
今回はMacbookを利用しますが、Linuxコンテナの利用できるDockerが使えれば、
LinuxやWindowsでも同様に設定できます。
Dockerのインストール
troccoエージェントはdockerを使って動作します。
今回はMacで動かすので、Docker Desktop for Macをインストールしておきます。
Dockerコンテナイメージのダウンロード
エージェントの実体となるプログラムをダウンロードします。
実運用時はtrocco®のサポートチームから署名付きURLなどでダウンロードリンクを提供します。
ダウンロードしたtarファイルを元に以下のコマンドでイメージがDockerにインストールされます。
docker load -i trocco-agent.tar # tarファイルよりイメージのインストールするコマンド
...
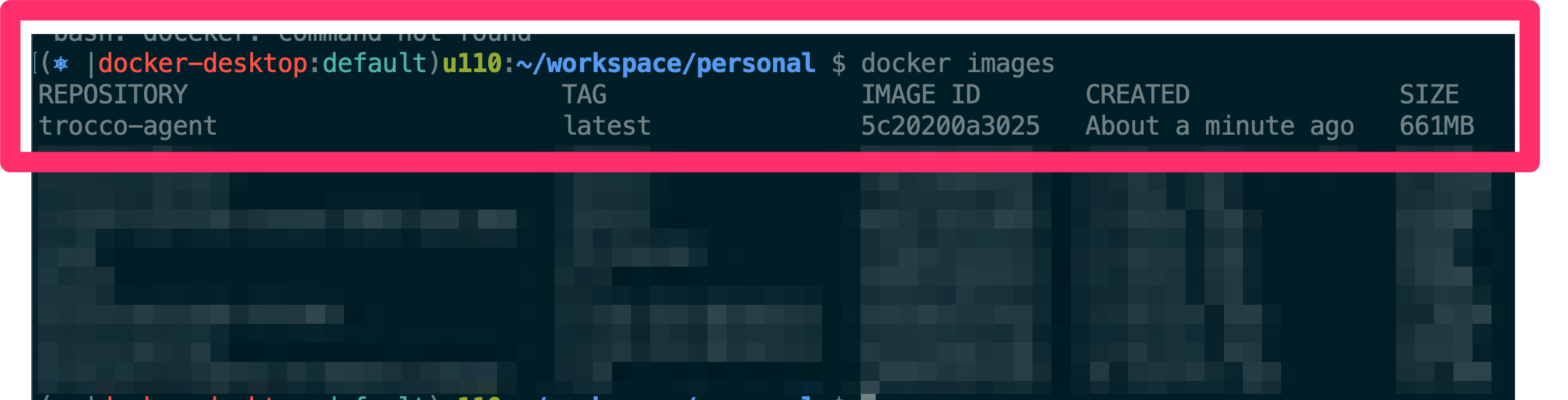
docker images # イメージの一覧を表示するコマンド
docker images で trocco-agent が存在すればokです。
起動
エージェントを以下のコマンドで起動します。
trocco®の設定時にメモしておいた2点
- APIキー
- エージェントID
をここで利用します。
起動コマンドはこんな感じです。
docker run \
-d \
--volume <ローカルのデータ配置パス>:/tmp/documents \
--restart=always \
--log-opt max-size=10m \
--log-opt max-file=3 \
--env AGENT_ID=27 \
--env TROCCO_API_TOKEN=LR***** \
--env DOCKER_HOST=*** \
--name trocco-agent \
trocco-agent \
./run-trocco-agent
今回はmakefileにて以下のように設定しました。
agent-id:=***
api-key:=LR****
run:
docker run \
-d \
--volume $(PWD):/tmp/documents \
--restart=always \
--log-opt max-size=10m \
--log-opt max-file=3 \
--env AGENT_ID=$(agent-id) \
--env TROCCO_API_TOKEN=$(api-key) \
--env DOCKER_HOST=$(shell HOSTNAME) \
--name trocco-agent \
trocco-agent \
./run-trocco-agent
trocco®とtroccoエージェントの疎通確認
サンプルデータ
Macbookのプロセスデータを取ってみます。
こちらの記事を参考にしました。
実行したコマンド
top -l 1 -o MEM -n 10 | jq -rcsR '[ gsub("\n$";"") | splits("\n") | sub(" +$";"") | sub("^ +";"")] | .[0:5] as $titles | .[11:] as $data | {"sys": [$titles | .[] | split(",") | [.[] | sub("^ +";"")]]} as $sys | [$data[0] | splits(" +") | sub("%";"") | sub("\\+";"")] as $row_keys | $data[1:] | [.[] | [splits(" +")]] | {"task":[.[] | [. as $r | range($row_keys|length) | {"key": $row_keys[.], "value": $r[.]}] | from_entries] | sort_by(.MEM) | reverse | .[:10]} as $task | $sys * $task' > out.json
out.jsonの中身は以下のようになります。
{
"sys": [
[
"Processes: 543 total",
"3 running",
"540 sleeping",
"3513 threads"
],
...
],
"task": [
{
"PID": "7931",
"COMMAND": "com.docker.hyper",
"CPU": "0.0",
...
},
{
"PID": "4729",
"COMMAND": "VirtualBoxVM",
...
"RPRVT": "N/A",
"VPRVT": "N/A",
"VSIZE": "N/A",
"KPRVT": "N/A",
"KSHRD": "N/A"
},
...
]
}
転送設定の作成
ここからは実際にデータを転送する設定を作成していきます。
troccoエージェント --> GCS
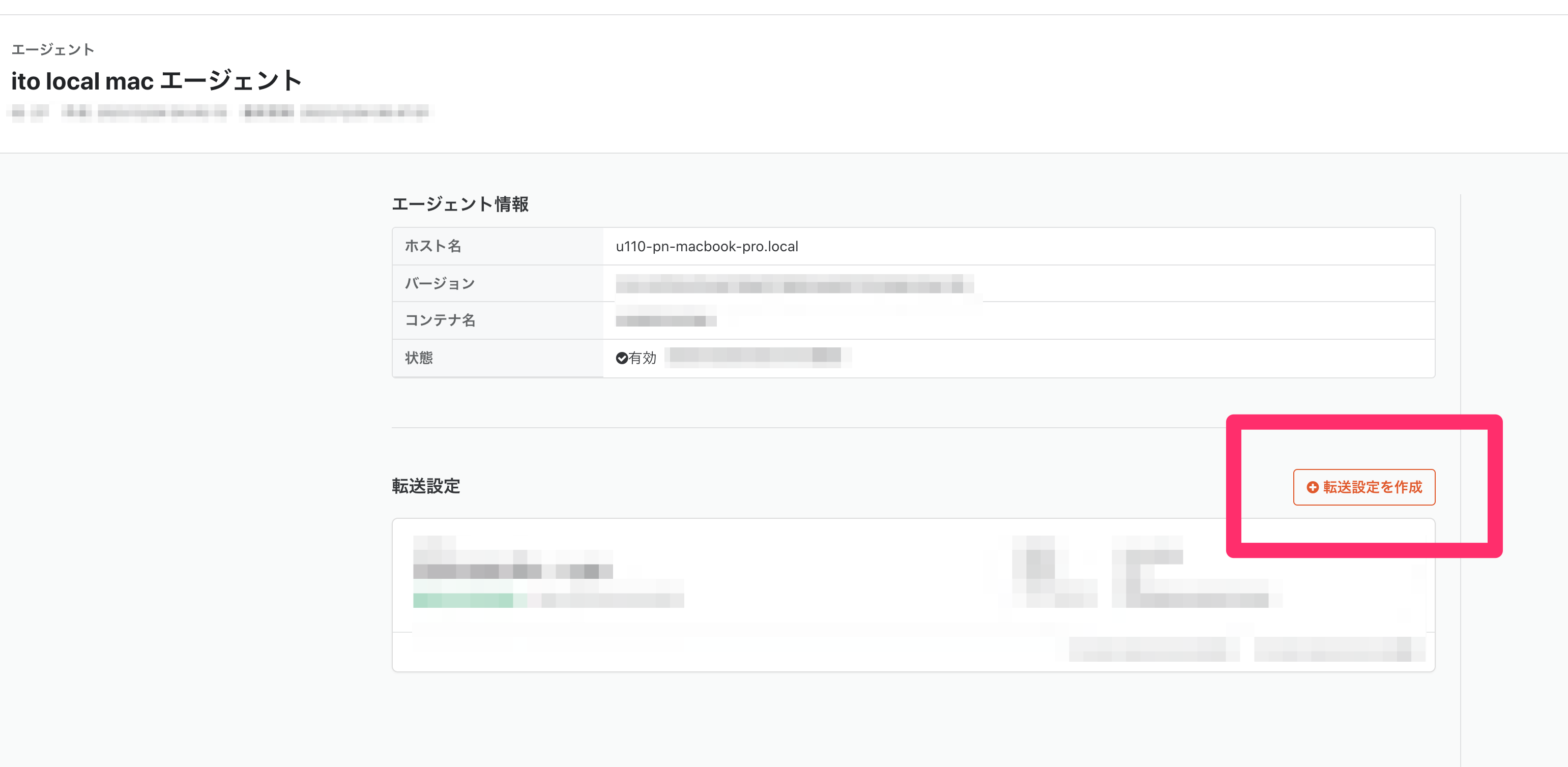
エージェントの画面から、「転送設定を作成」を作ります。
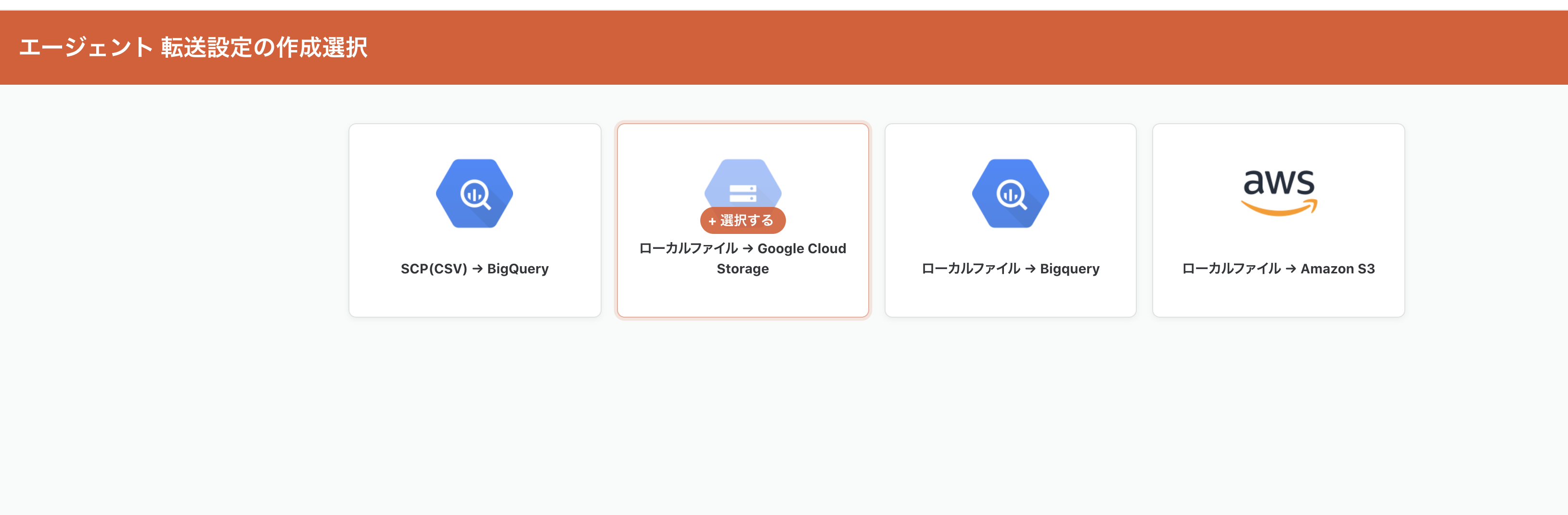
troccoエージェントの転送方式は
- SCP(CSV) --> BigQuery
- ローカルファイル --> Google Cloud Storage
- ローカルファイル --> BigQuery
- ローカルファイル --> Amazon S3
があります。今回はBigQueryに転送したいのですが、jsonファイルを整形したいので
一度GCSに出力して、trocco本体で整形処理を行った上でBigQueryに送りたいので
ローカルファイル --> Google Cloud Storage を選びます。
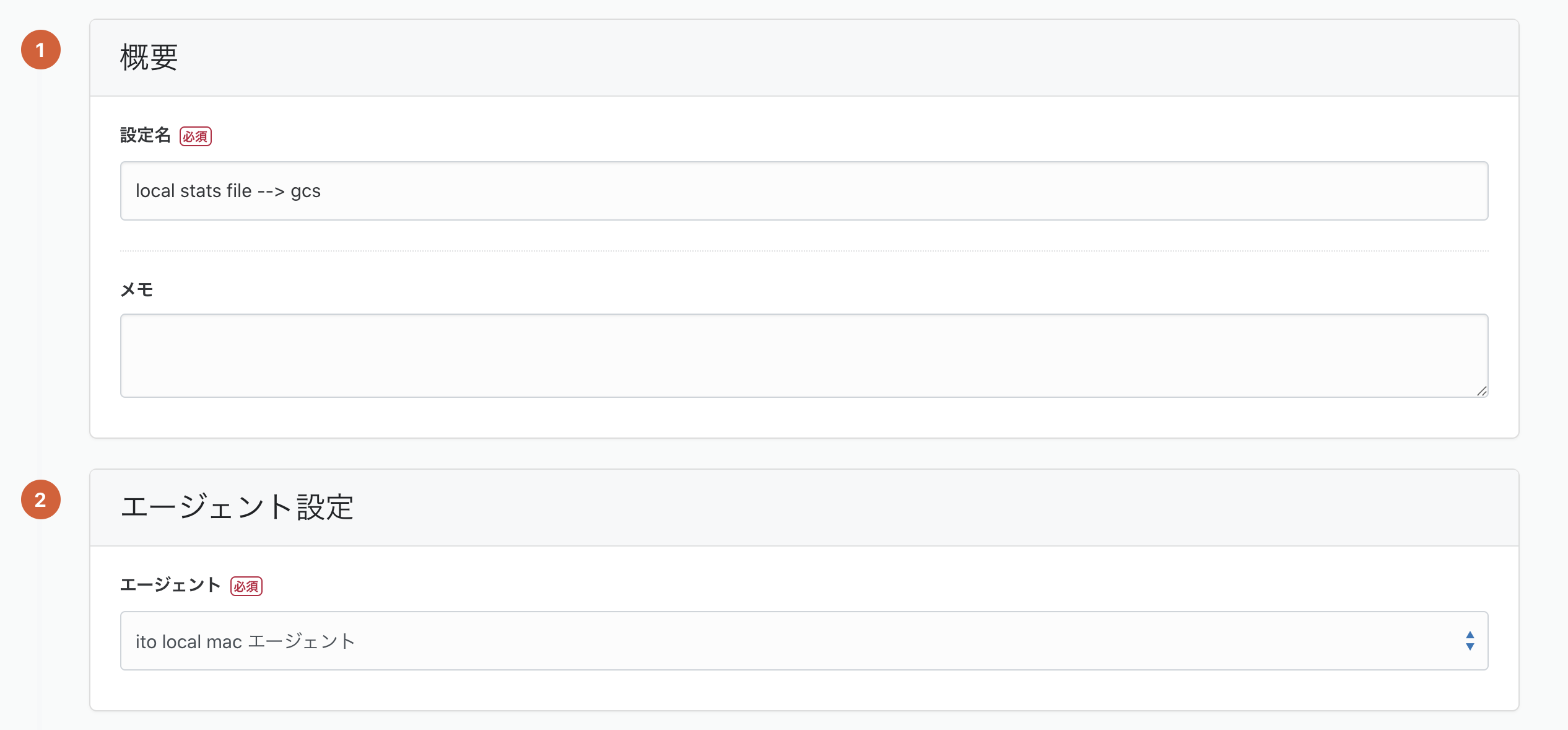
転送設定の名前と、作成したエージェントを選択します。
転送元設定
- ファイルタイプ:
csv形式(カンマ区切り) - 転送パターン: 差分転送
- 対象ファイルパスプレフィックス:
/tmp/documents/*.json
とします。
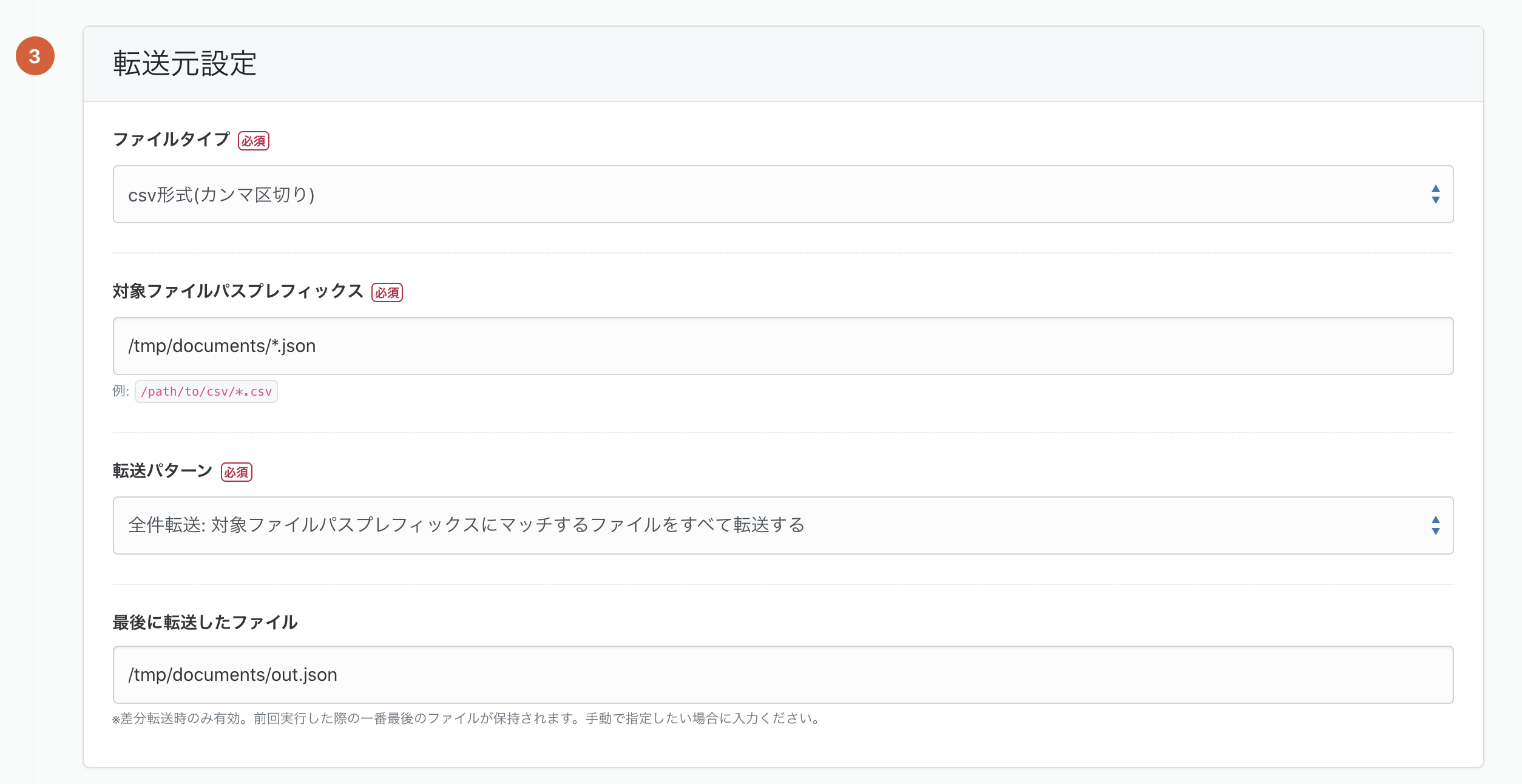
転送先設定は
- Google Cloud Storage接続情報
- Google Cloud Storageバケット名
- ファイルパス
を指定します。
trocco®のGoogle Cloud Storage接続情報の設定方法については
troccoの中の人達が丁寧に trocco公式ドキュメントにまとめてくれています!参考にしてみてください。
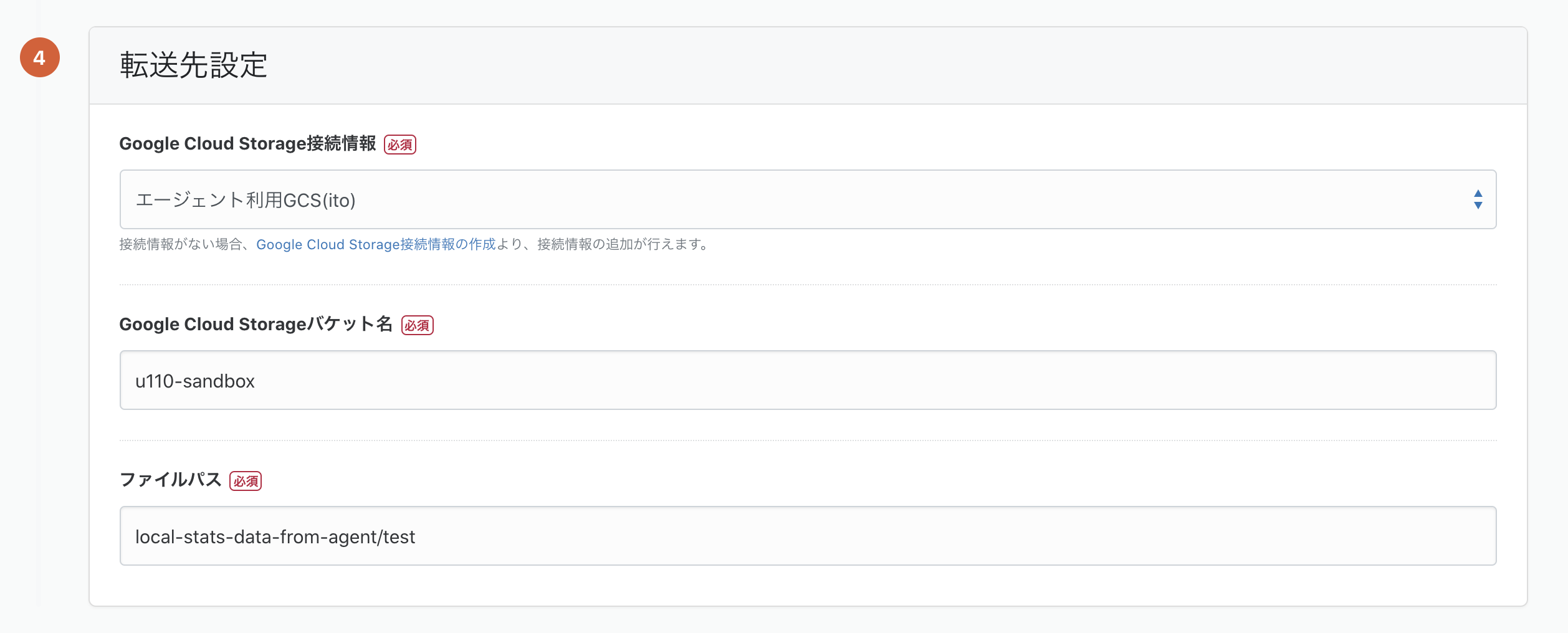
「この内容で保存する」を押すとスケジュール設定画面になります。
ここではCRON形式でスケジュールを設定できますが、
今回は何も入力せず、再度「この内容で保存する」を押して設定を完了させてください。
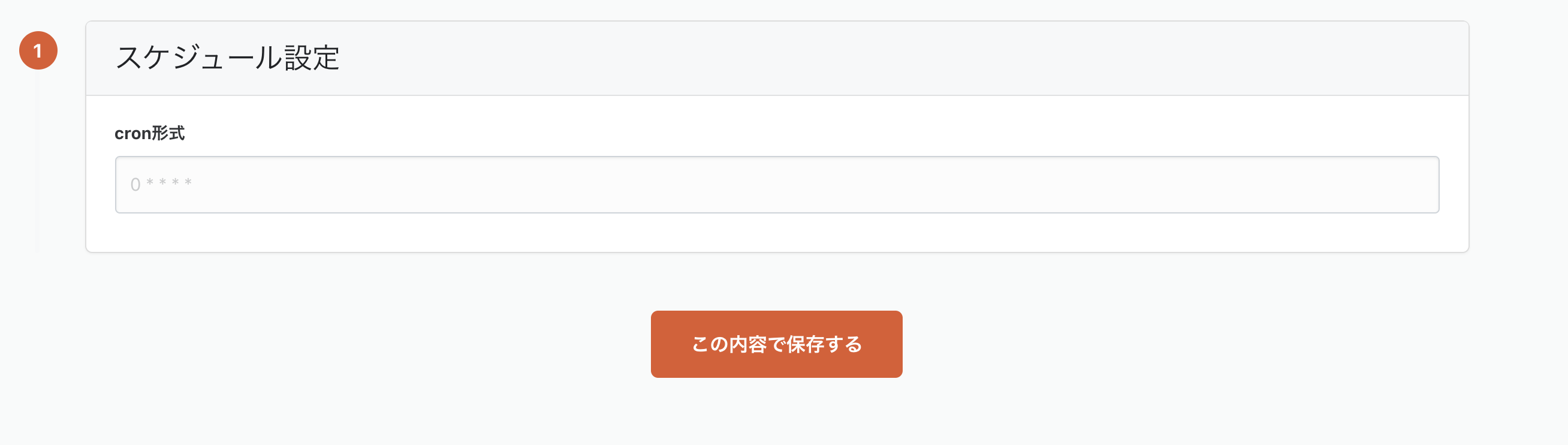
これで Macbookからtroccoエージェントを介してGCSへ転送する設定が作成できました。
ジョブ実行したあとに画面キャプチャを撮ったので既にジョブ履歴が表示されています(笑
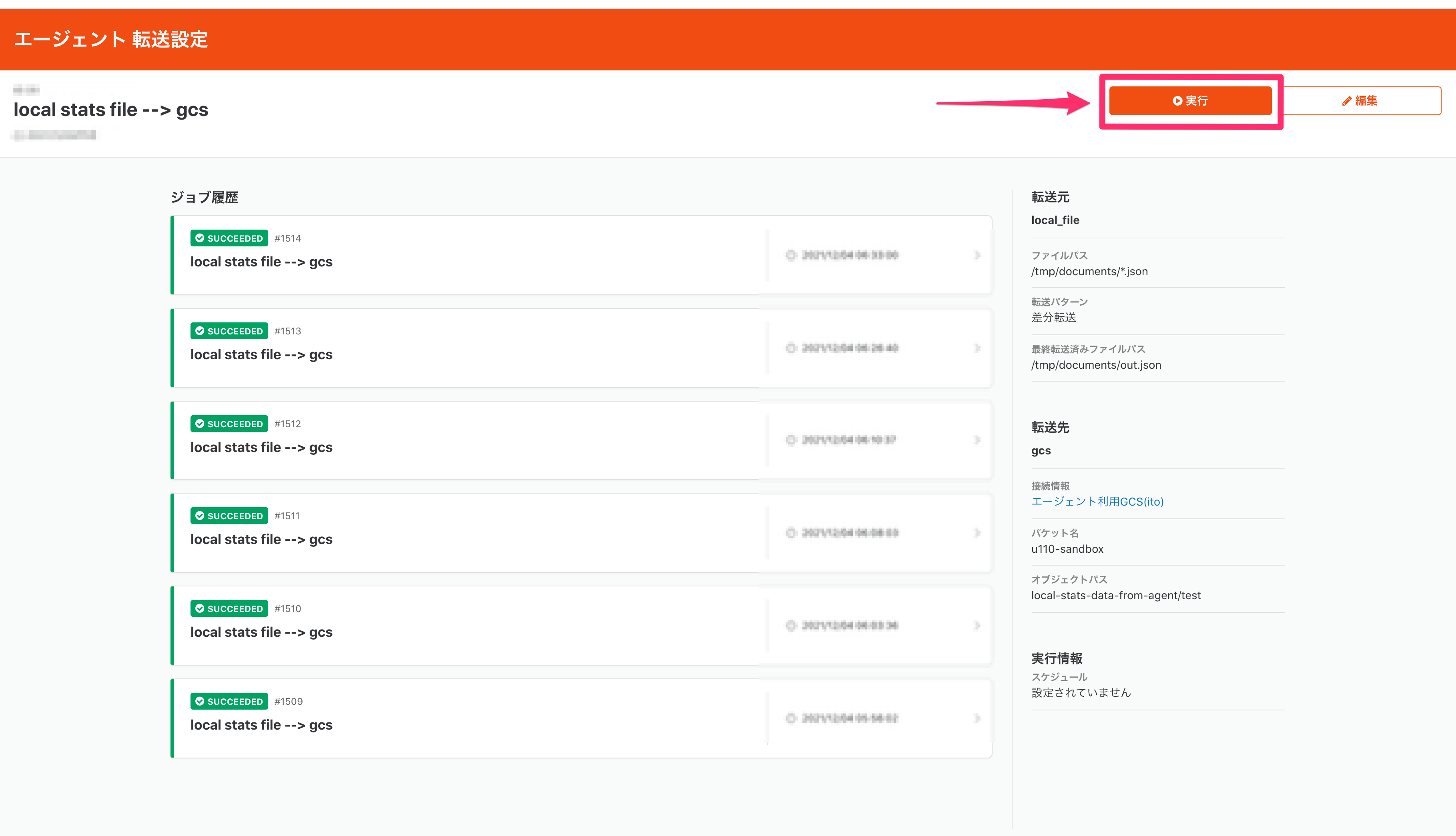
では実際に実行してみます。右上の「実行」ボタンを押すと確認モーダルが出ます。
(改めてこのモーダル見ると、ちょっと不安になりますね。。汗 UX改善タスクとしてissueにしておきます笑)
気にせず、はいを押すとジョブが実行されます。
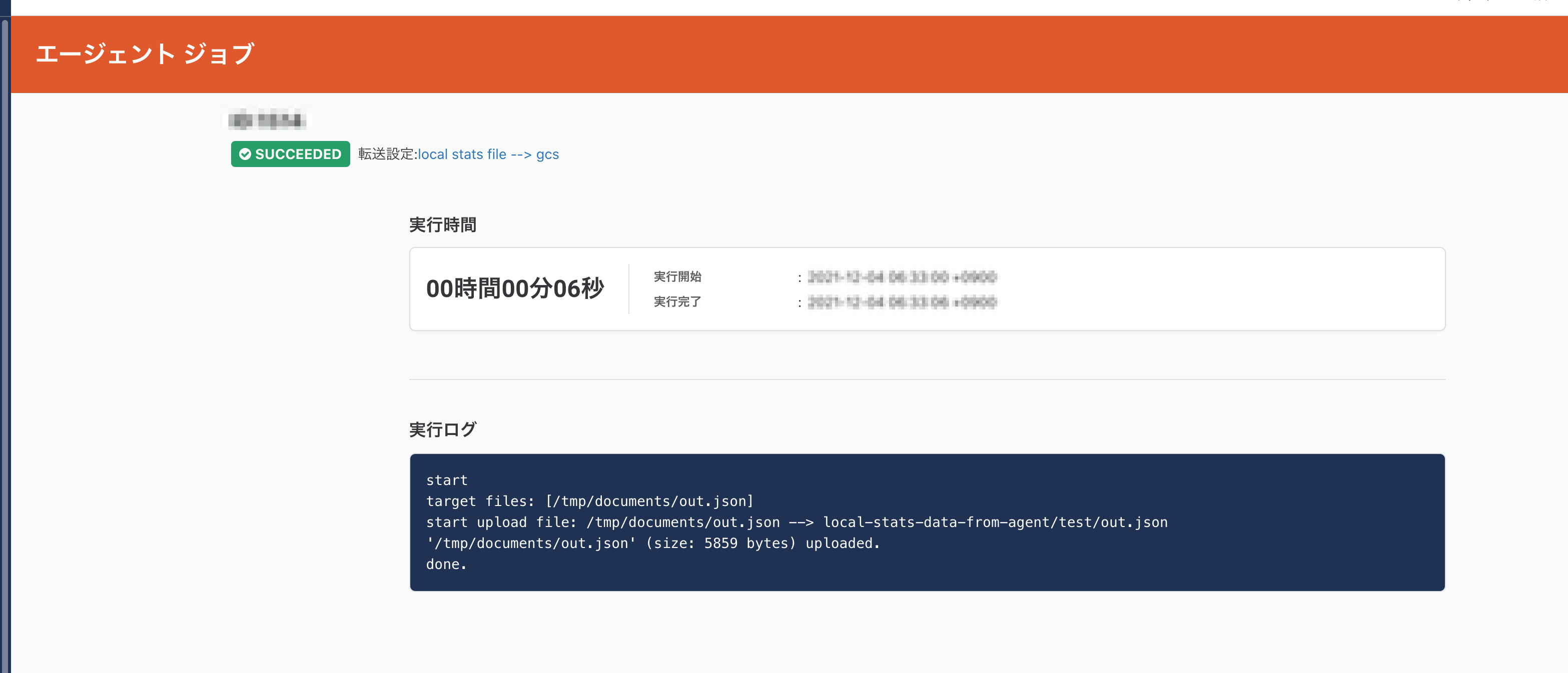
問題なく転送されたようです。
ちなみに、内部の動きとしては trocco®からエージェントに通信したわけでなく
エージェントが定期的にtrocco®に対してリクエストを投げていて、実行待ちジョブが存在した場合に
転送設定を読み取りに行き、ジョブを開始します。そのため実行開始までに数秒のラグがあります。
GCS --> BigQuery
ここまでで、だいぶお腹いっぱいなのですがBigQueryまで転送しちゃいましょう。
あとはいつもの?trocco®の転送設定を作成します。
trocco®サイドバーのデータ転送項目の転送設定を選び、新規転送設定作成ボタンをクリックし
- 転送元: Google Cloud Storage
- 転送先: Google BigQuery
を選び、「この内容で作成」ボタンを作成します。
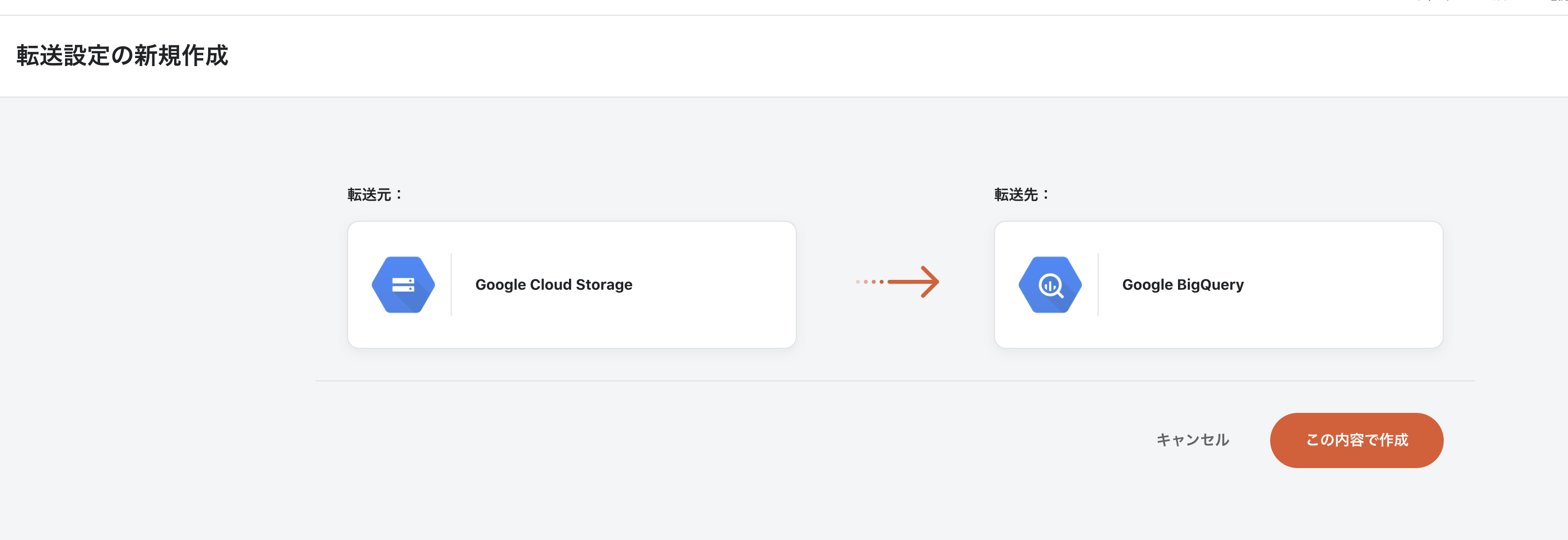
編集画面になります。
この名前もこれまで通り、具体的な名前を記載することをおすすめします。
転送元Google Cloud Storageの設定は
troccoエージェントの転送設定で準備した出力先と同じ接続情報を今度は転送元として利用します。
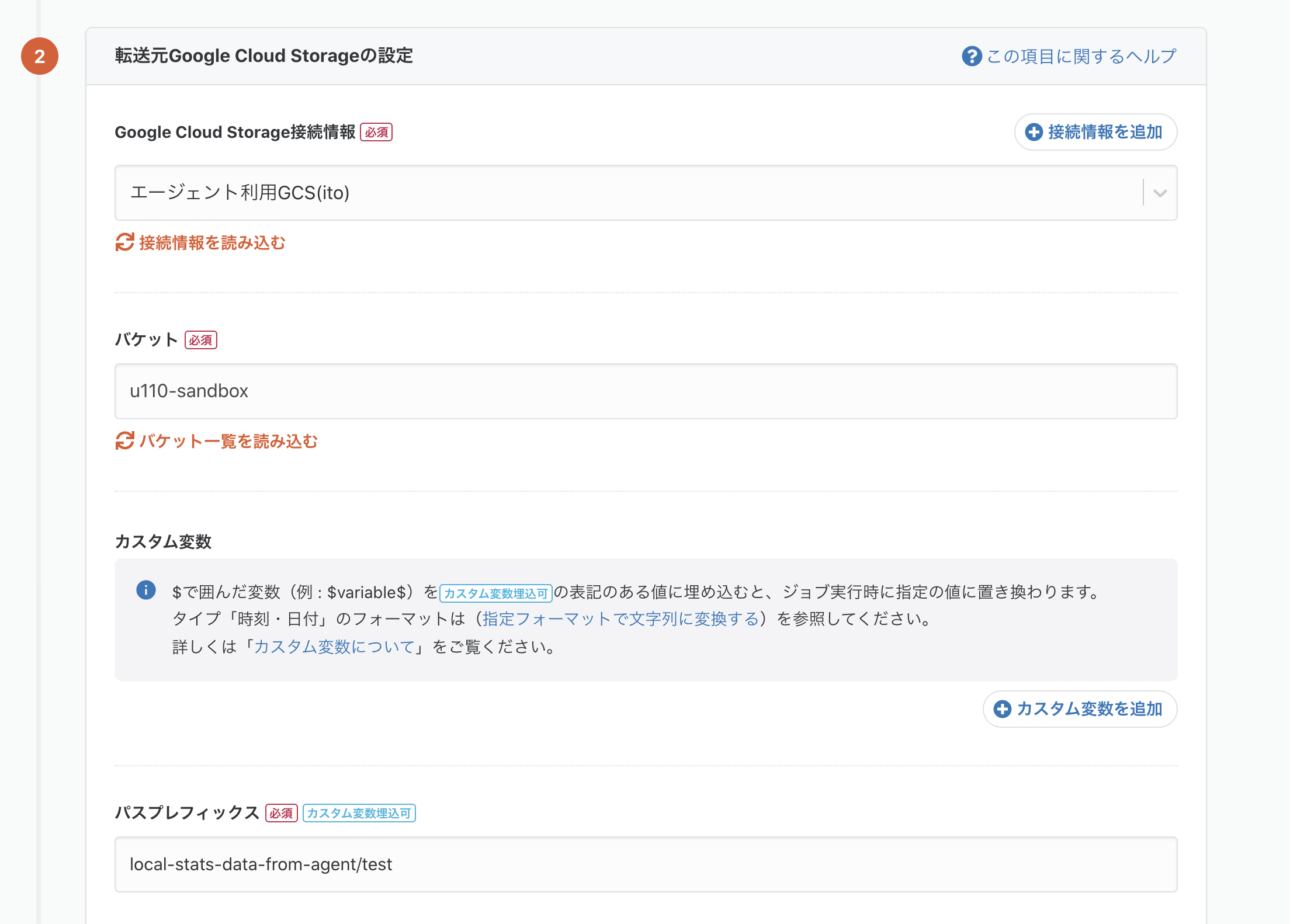
今回trocco本体の転送設定を挟みたかった理由の一つがこちらの設定です。
- 入力ファイル形式: JSONPath
- JSONPATH:
$.task
この設定をすることで、ローカルに出力したjsonファイルの taskキー配下の値を転送するようにできます。
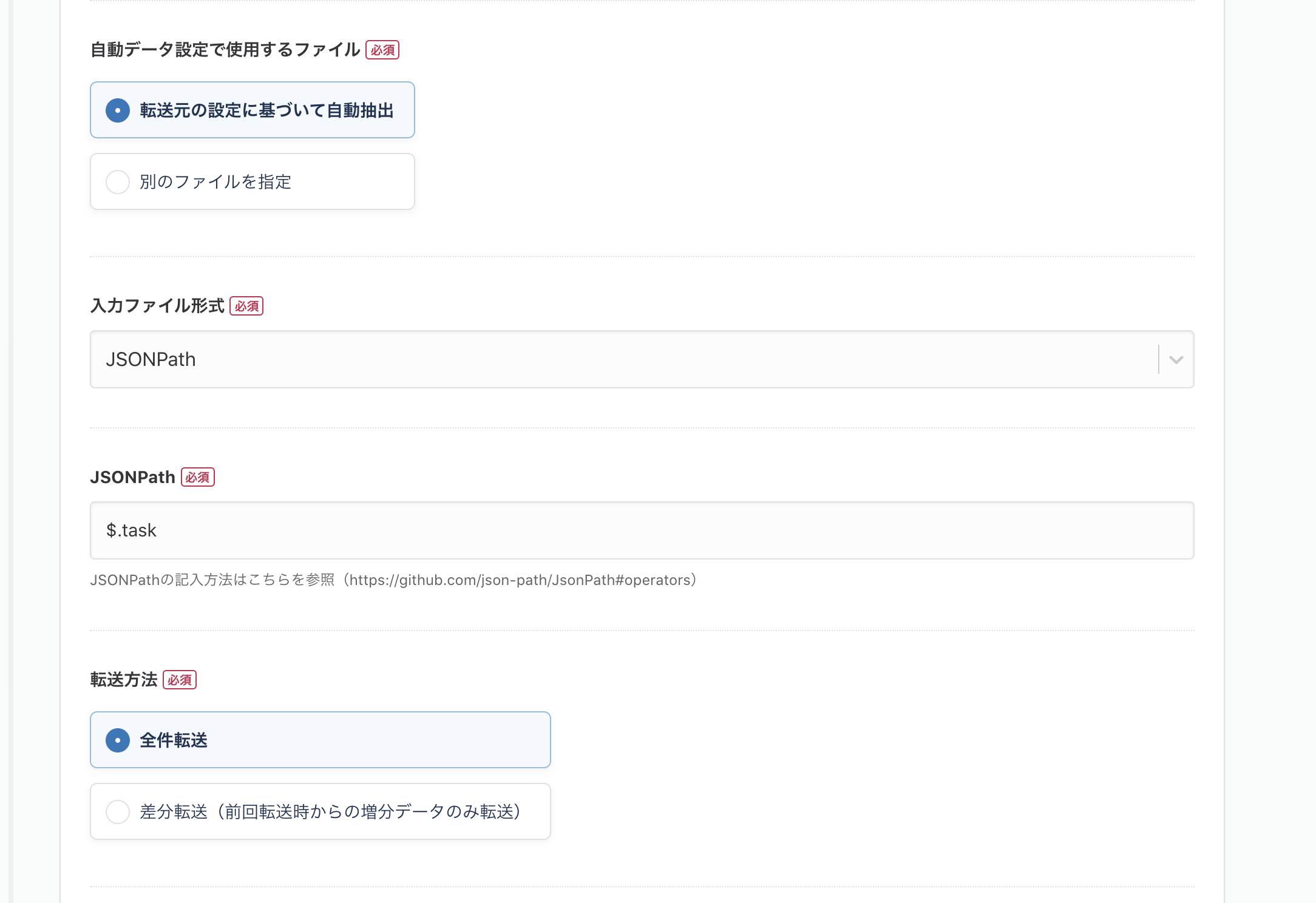
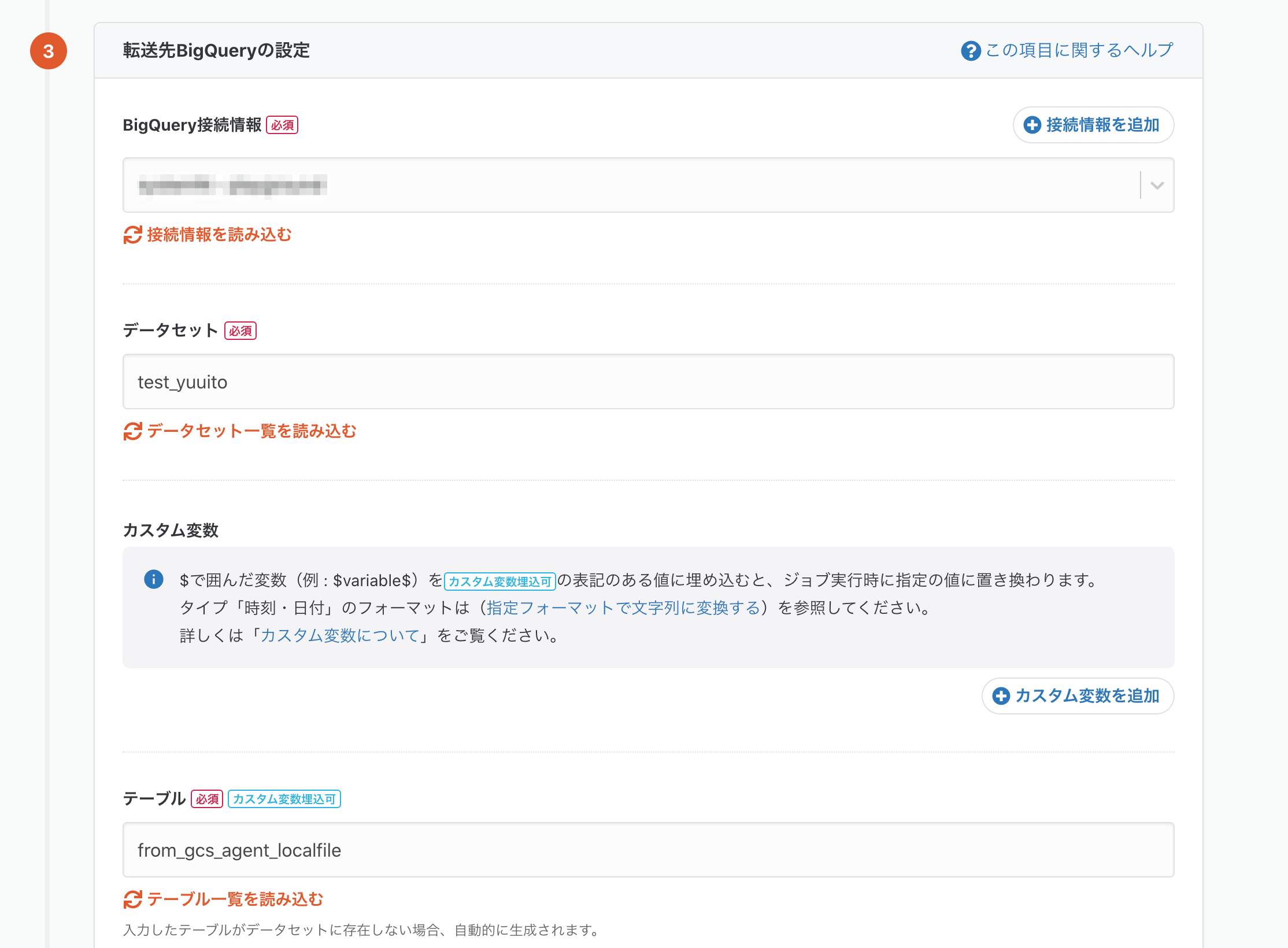
転送先のBigQueryの設定は以下の通りです。
BigQueryの接続情報についても中の人達が懇切丁寧にドキュメントにまとめてくれているので
こちらを参照ください。今回は私のほうですでに準備してある接続情報を選んで、データセット、テーブル名を指定します。
一通り設定を終えたらページ下部にある「次のSTEPへ」ボタンを押しますと、
データプレビュー・詳細設定画面になります。
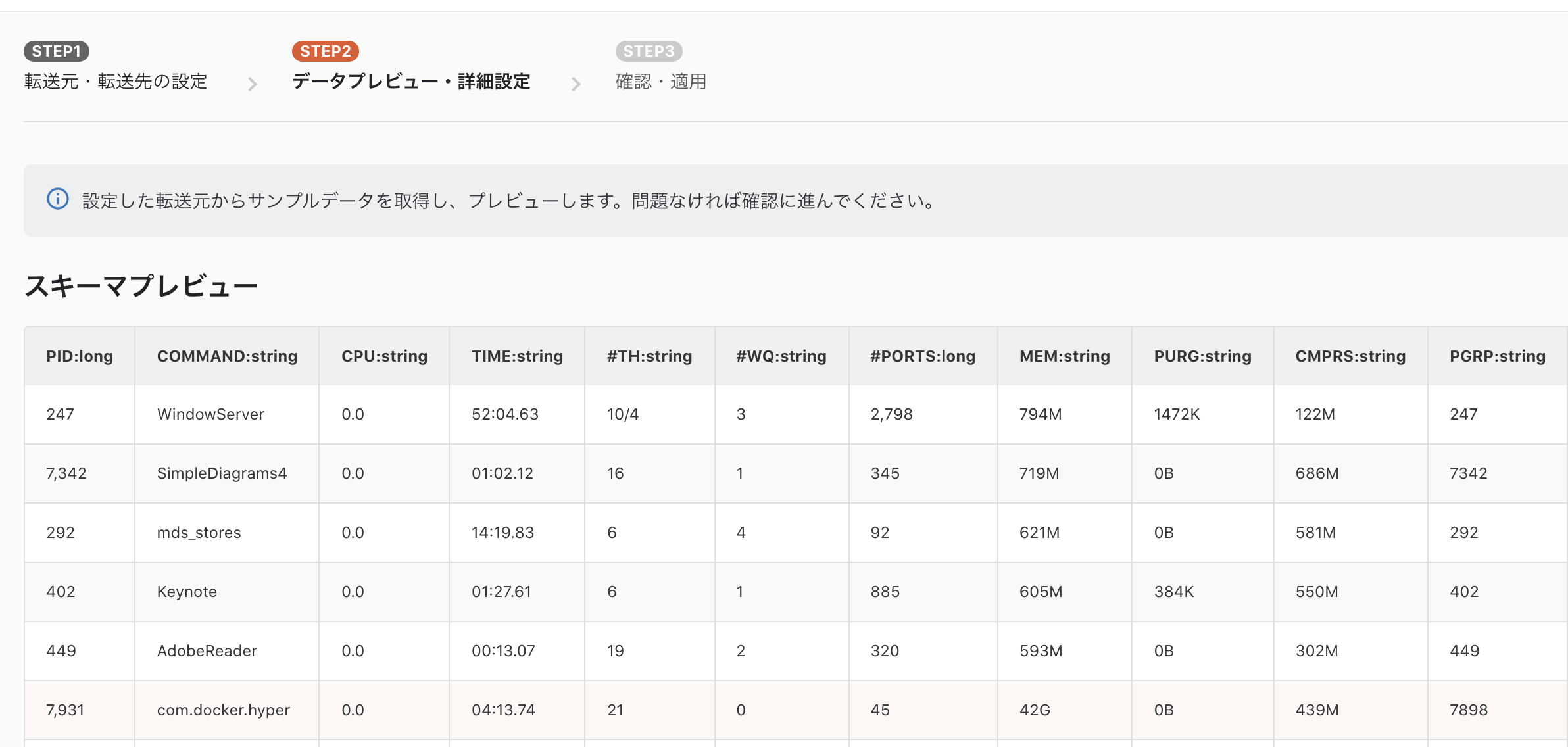
少し待つと、上記のようにデータがとれることが確認できるはずです。
ここまでくれはほぼ完成です!!(マジモンのフラグだと気づいたのはもう少し後の話。。)
確認画面に遷移し、「保存して適用」を押してください。
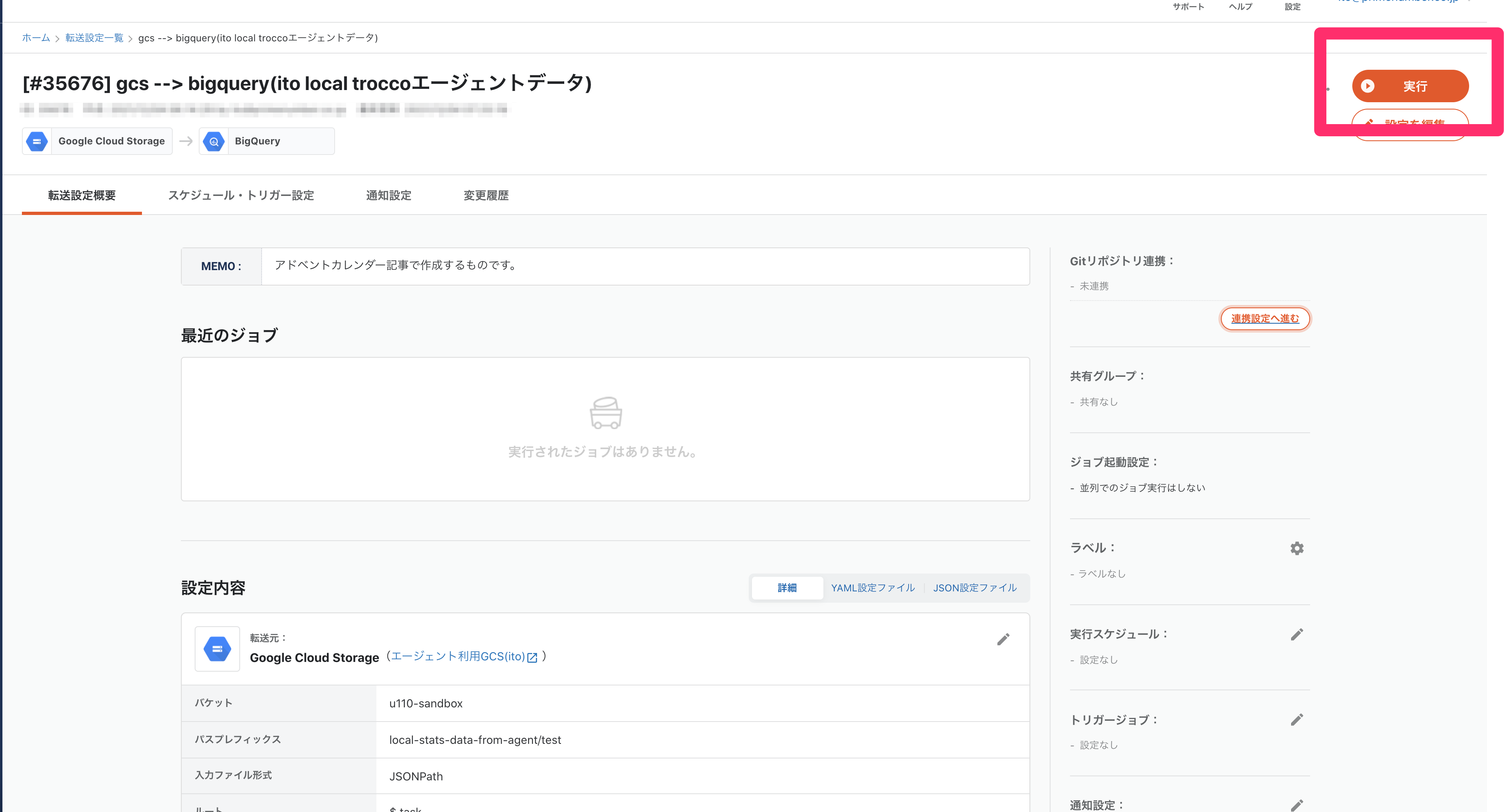
転送設定の詳細画面に遷移しますので、右上の実行ボタンを押します。
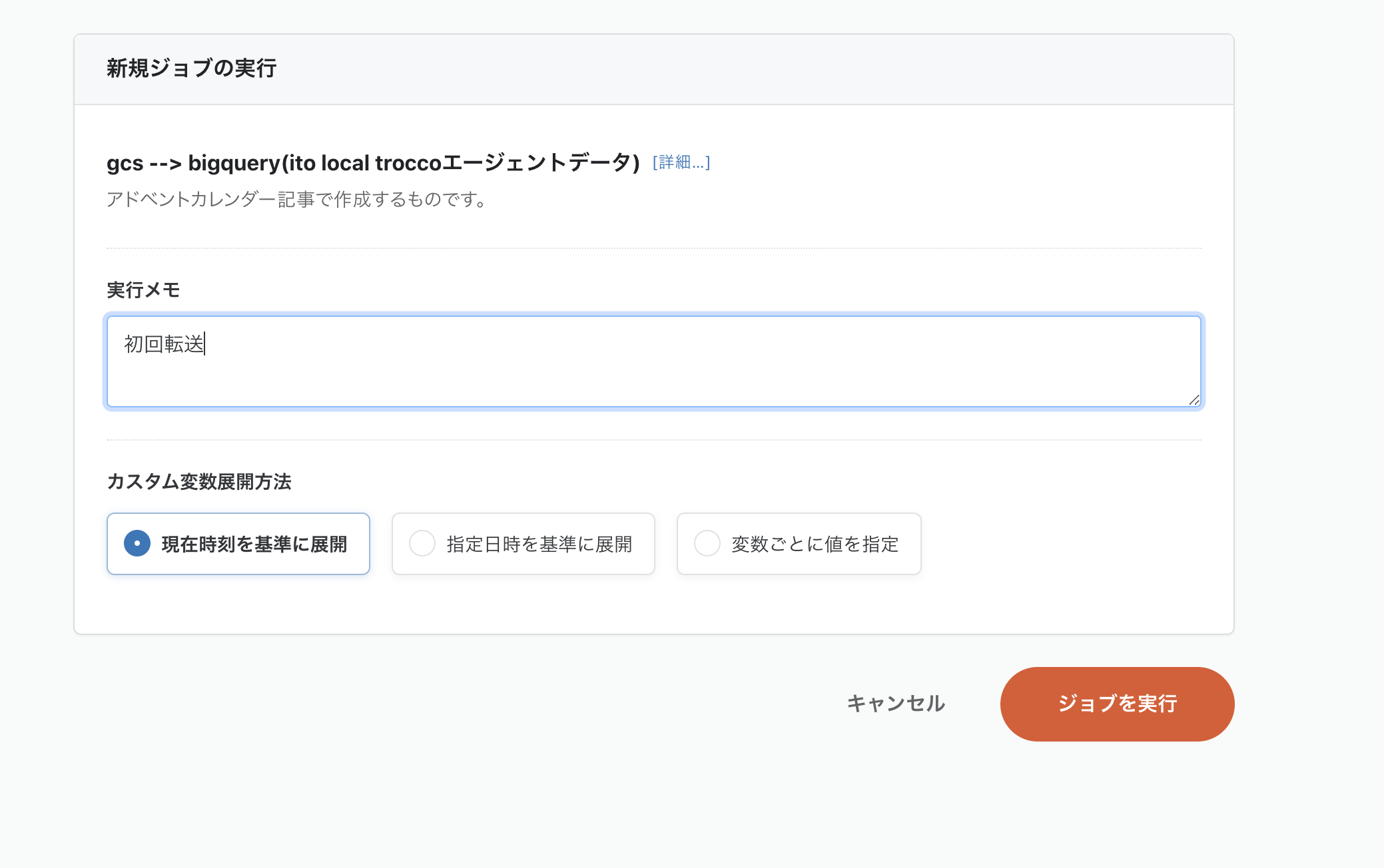
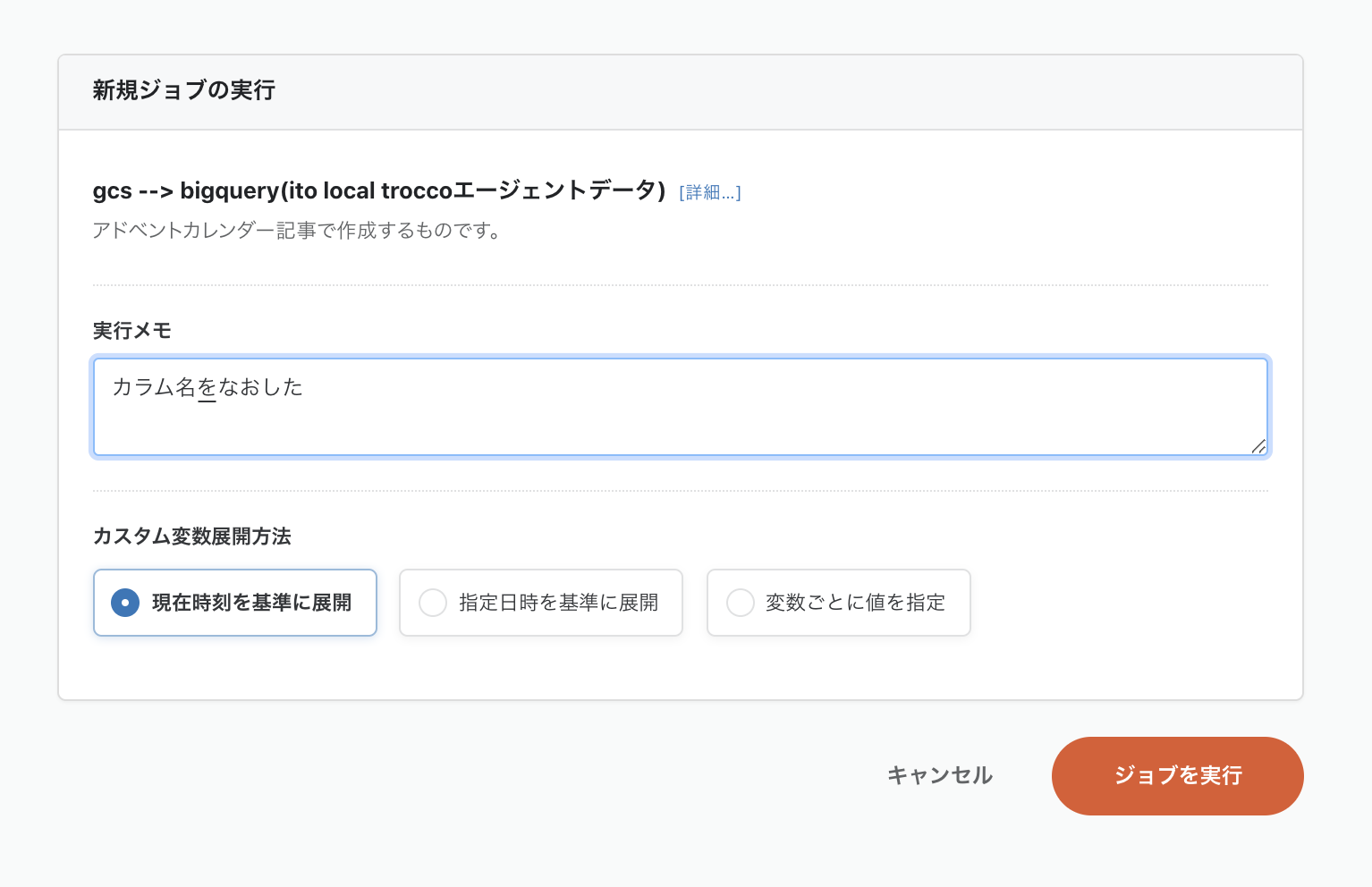
ジョブ実行画面です。ジョブを実行ボタンを押します。
おっと、エラーですね...何も考えずにサポートに問い合わせたいところですが、
問い合わせ -> 中の人 -> itoですね、自分でやってください -> 自分と返ってくるので自分で読み解きます。

invalid: Invalid field name "#TH". Fields must contain only letters, numbers, and underscores, start with a letter or underscore, and be at most 300 characters long.
丁寧にメッセージがかかれていました。BigQueryのカラム名のルールに則ってなかったようです。
転送設定を直しましょう。
転送設定の編集から、プレビュー画面に行き、スクロールすると「カラム定義」項目があります。
ここでカラム名を見ます。
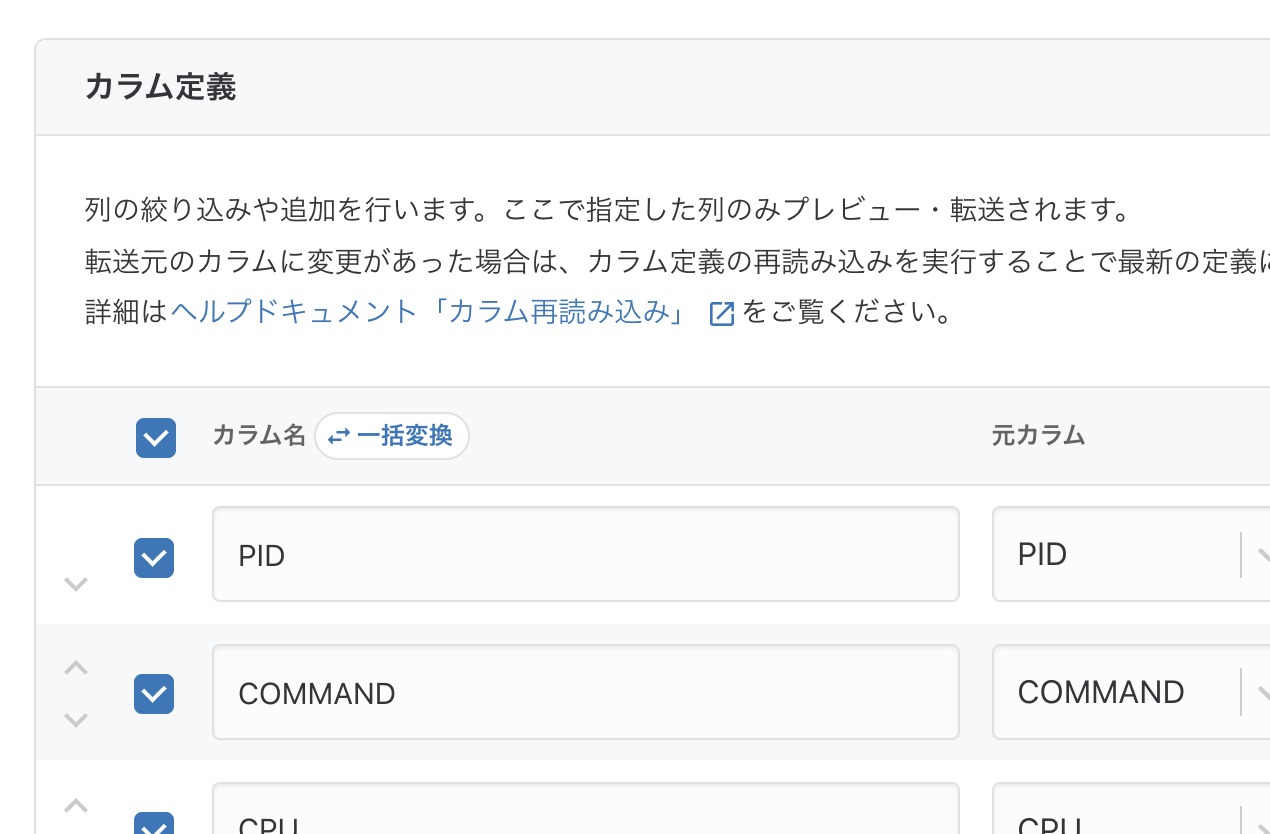
一括変換 という機能がありますね。記事考えているときはこの機能こと忘れてましたが、便利機能の一つです。
カラム名の右のチェックボックスを指定するとボタンがゆうこうになります。今回はすべて選んでボタンを押します。
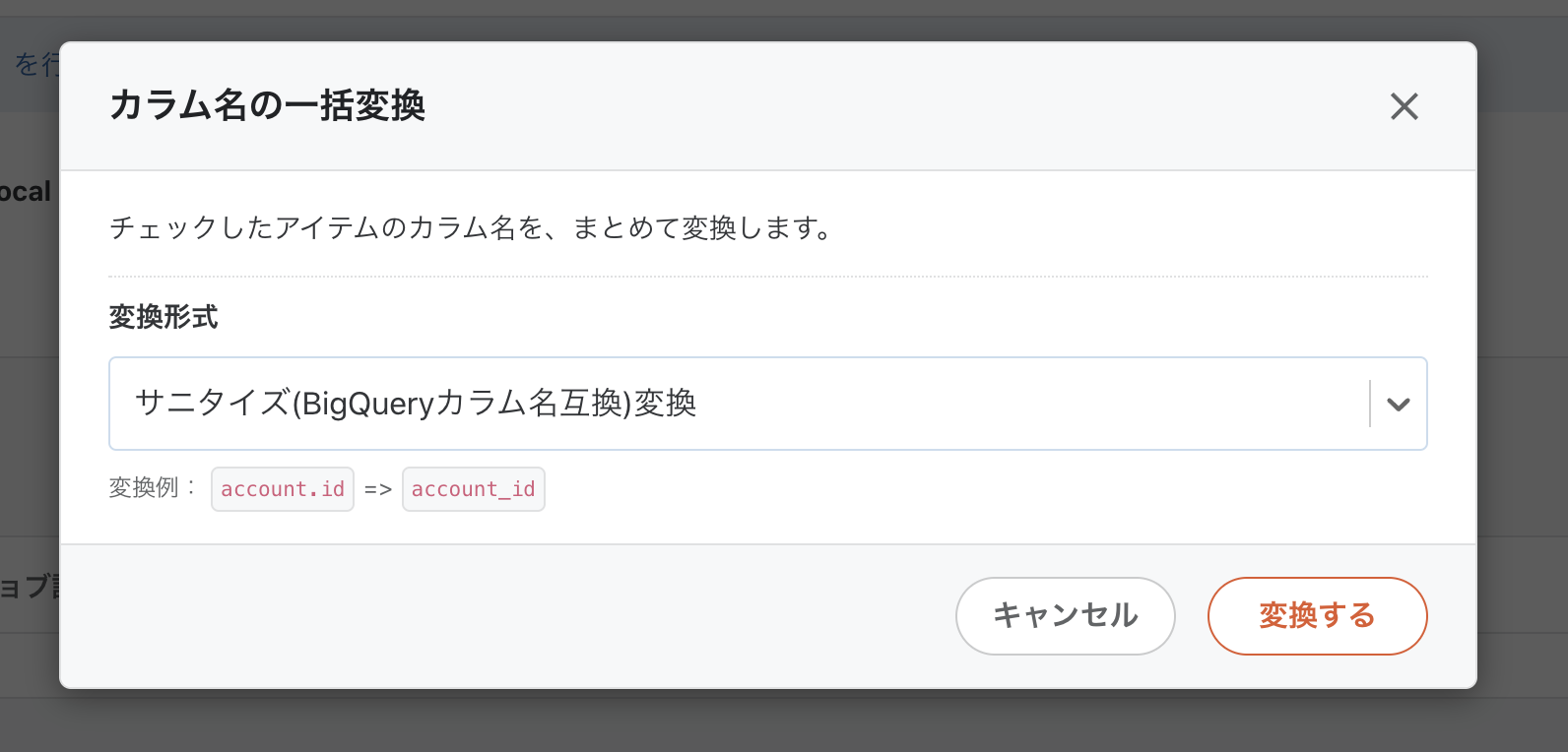
変換するを押すと、

エラーに出ていた #TH を _TH と変換してくれました。他のカラムについての反映されています。
カラムが多いときにはとても便利そうですね!!
この変更を再度プレビューで確認します。
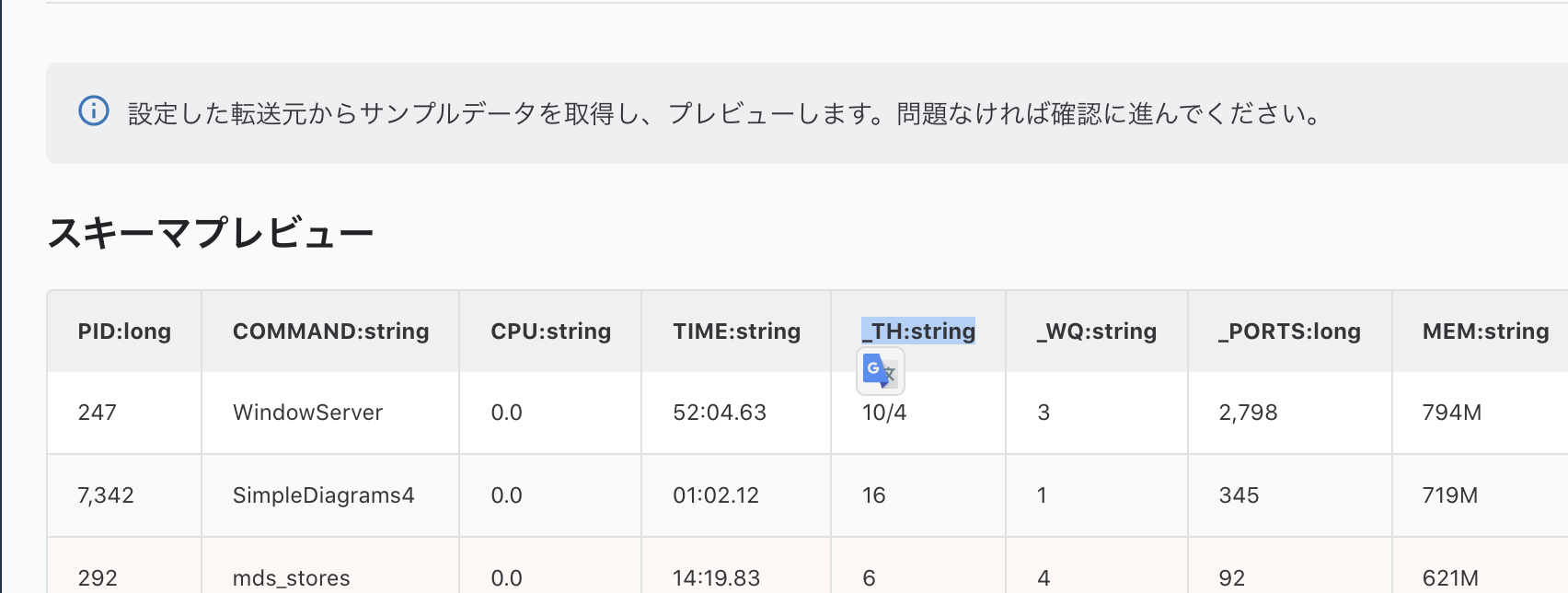
変換されてますね。問題なさそうなので、確認画面に行きます。
確認画面では変更内容の差分がハイライトされます。Webエンジニアにはおなじみのdiff表示ですね。
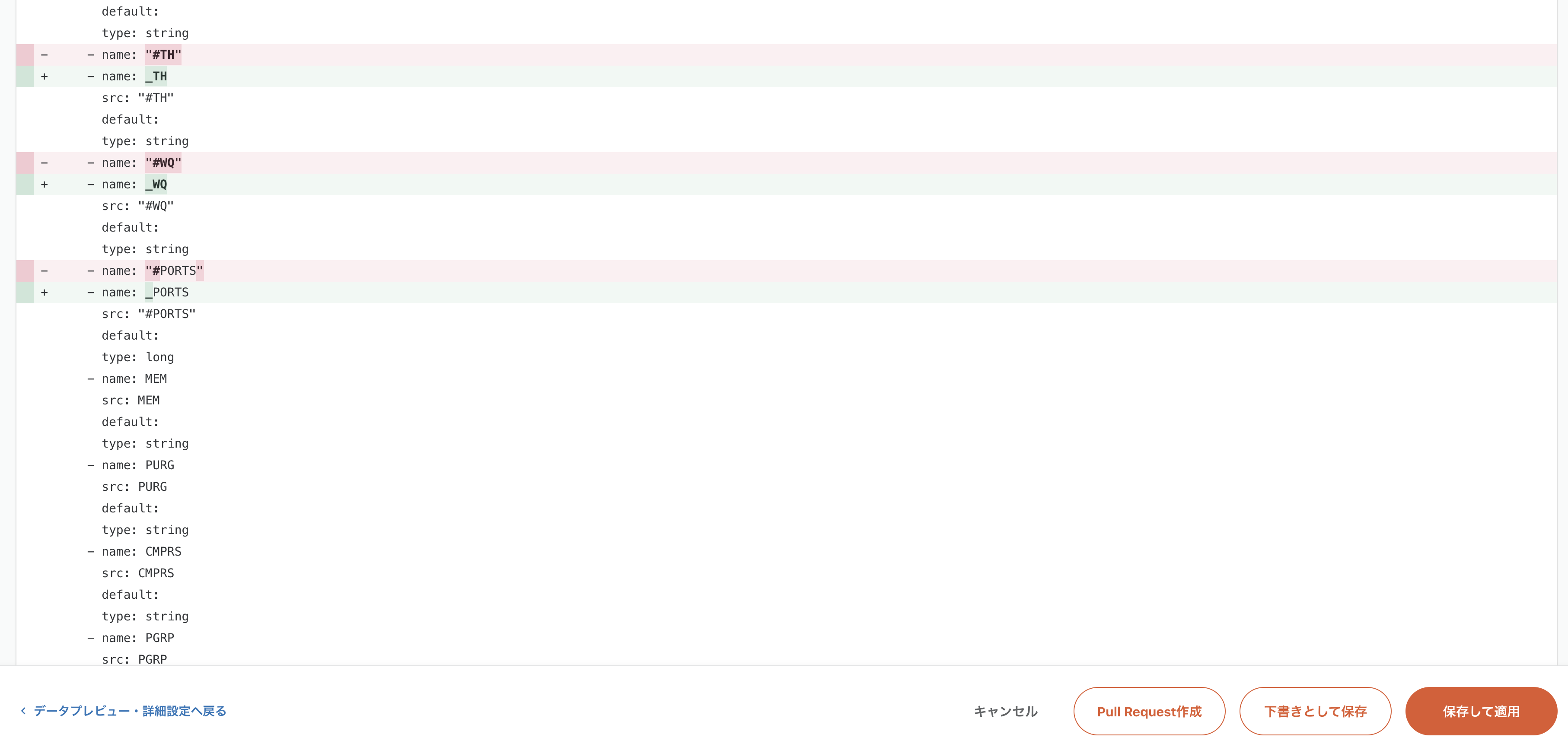
またまた便利機能が見つかってしまった。。 スキーマ追従機能 になります。
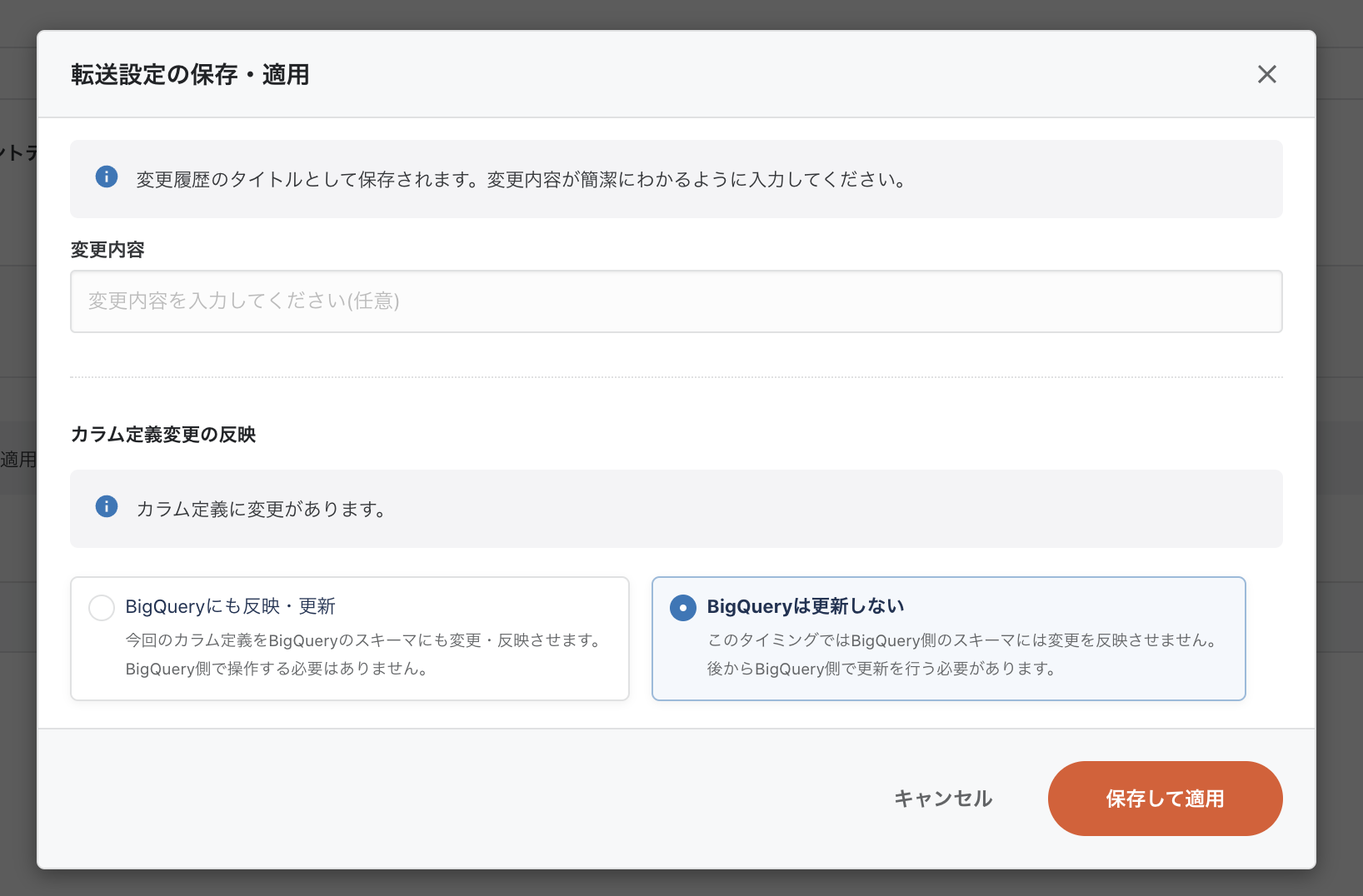
最初の設定からスキーマが変わったので変更前に転送先のテーブルのスキーマを追従するか聞いてくれました。
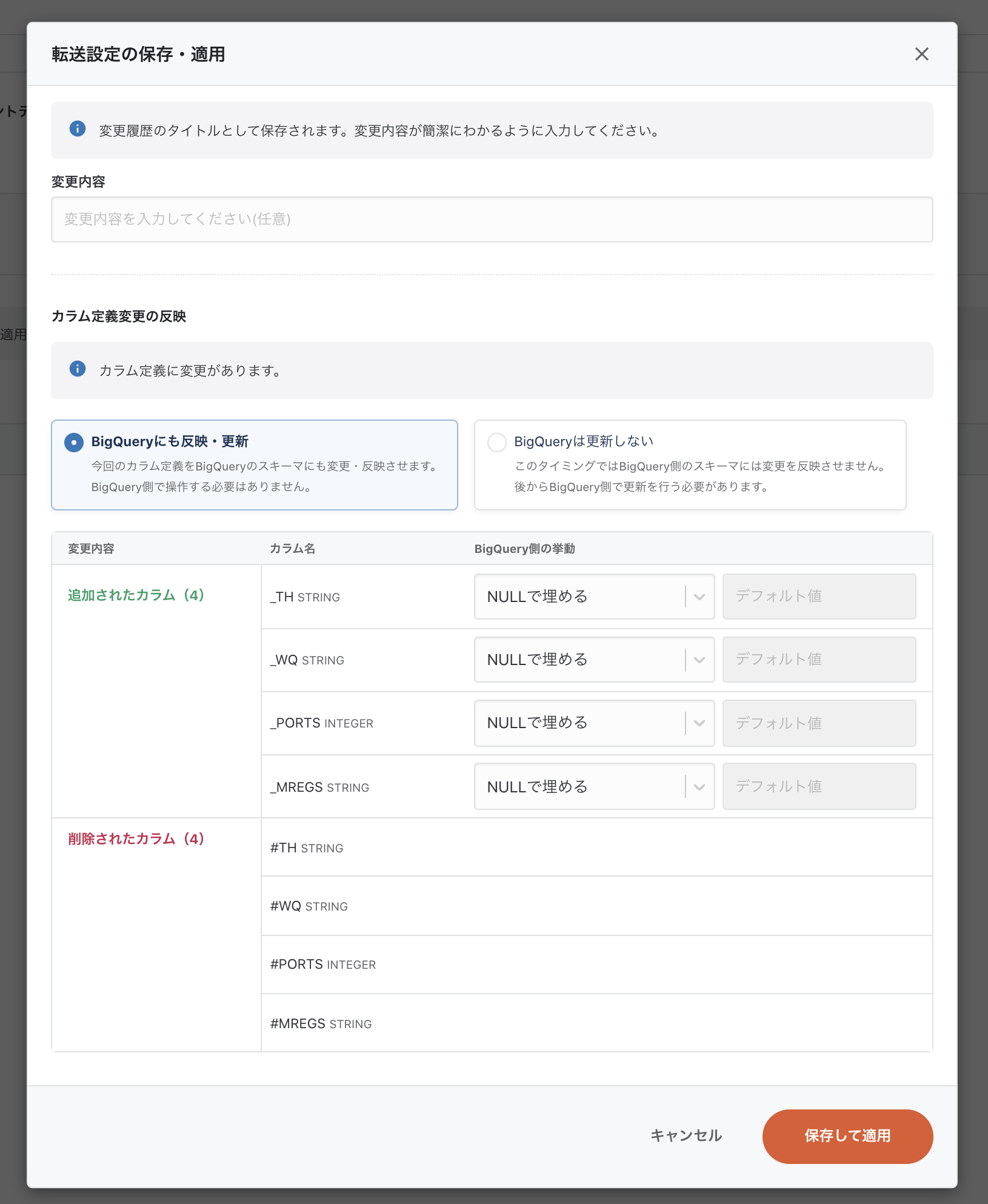
ですが、今回はテーブルがまだ作成されていないので、追従は不要のためBigQueryには更新しないを選び保存します。
リベンジです。うまく転送できるか?!
...
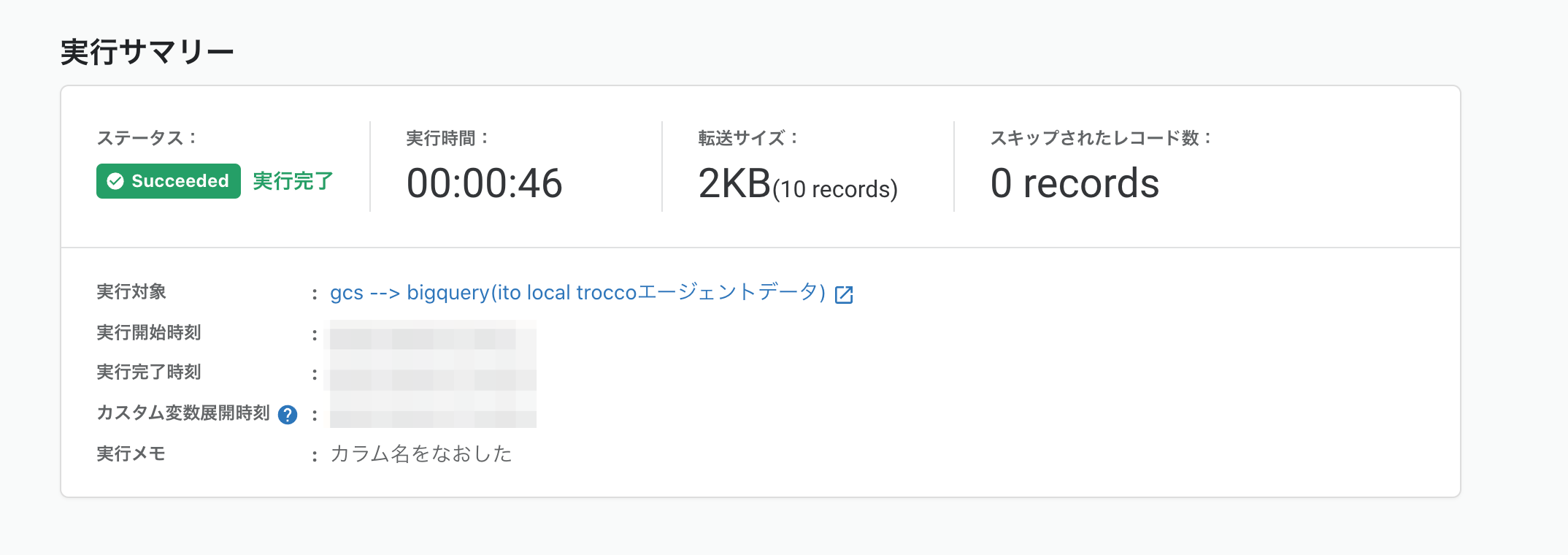
やったー!BigQueryコンソールでも確認できました。
Google Chome とカラムが別れてしまっていますね汗 json出力をなおしたほうが良さそうですが、これまた別の機会にします。
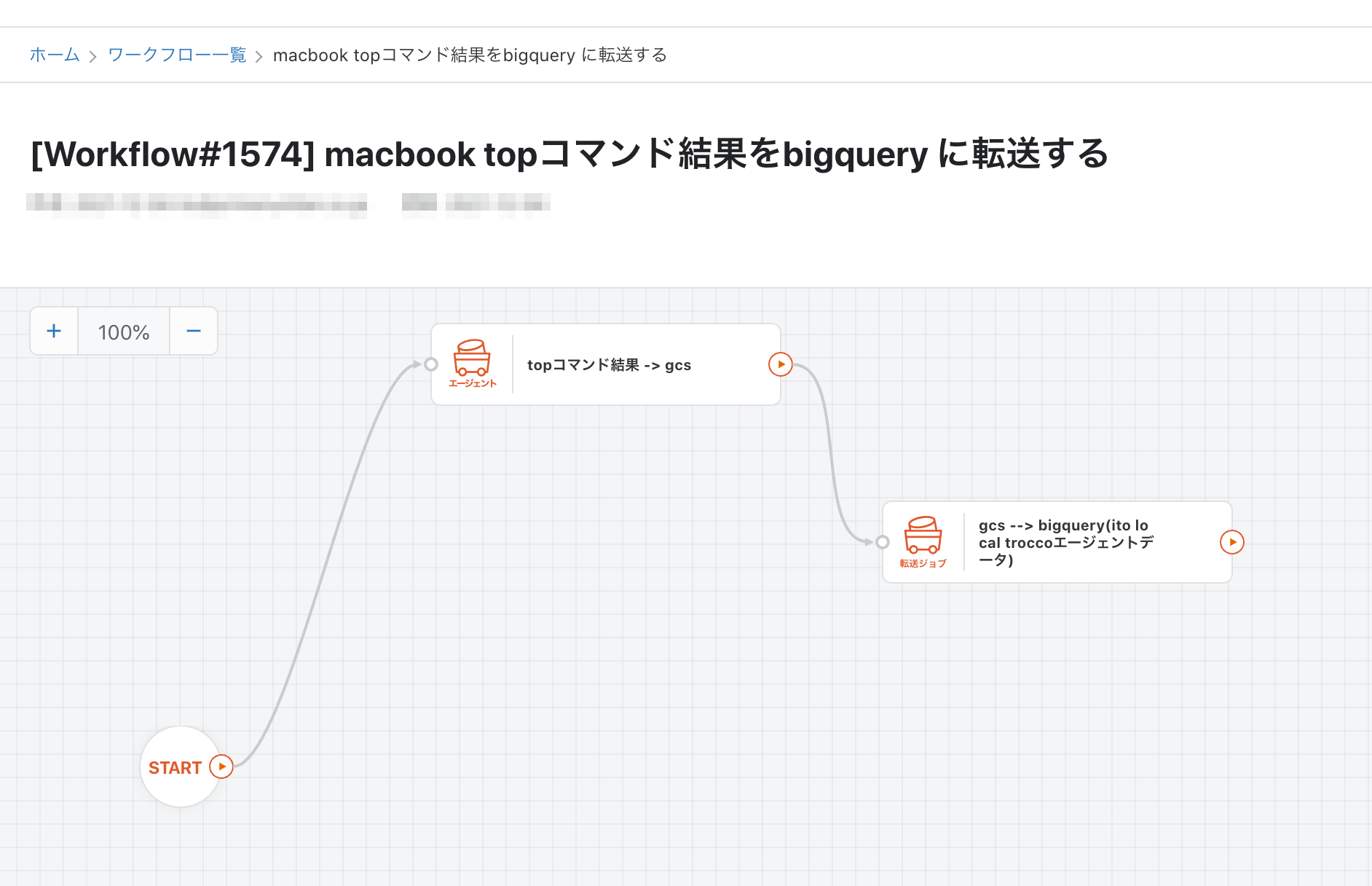
余談: troccoワークフロー
今回は2つの転送設定を個別に動かしましたが、
troccoワークフローを使い、2つのジョブの前後関係を設定し、定期実行することができます。
前後関係を考慮して、それぞれ別のスケジュールを組む必要はなく
ワークフローを作成し、一つのスケジュール設定で実現できます。
まとめ
troccoエージェントを使って、データをBigQueryに転送してみました。
ちょっとしたエラーに遭遇しましたが、別の機能の紹介をしつつ無事終えました。
trocco®に興味ある方はぜひご連絡ください。
「この記事読んだ!」と問い合わせいただけたらとっても嬉しいです。