本記事はPostgreSQL on Kubernetes Advent Calendar 2018の1日目です。
正確にいうと PostgreSQL on Kubernetes 2018(全部俺) の第一回です。
今日は初日になりますので、「どんな話なの?」「なんでデータベースをk8sにのせるの?」といった辺りの概要をお話したいと思います。
TL;DR
- Kubernetesは既に標準プラットフォーム
- データベースもこれをフォローしておかないと、デバイス対応で困ったりすると思うよ。
- すでにPostgreSQL on k8sとかMySQL on k8sの事例もあるよ。
Kubernetesを取り巻く状況
昨今はねこも杓子もコンテナの時代になりつつありますが、その界隈の覇権がDockerからKubernetesに完全に移ったように見えます。
これはただ単に抽象化レイヤの中で上位に移行したというよりも、コンテナを取り巻くエコシステムの中心がKubernetesに移ったということを意味しています。
これはデータベース on Kubernetesにおいても重要な意味を持ちます。
データベースの性能向上にはその時代の最新のデバイス採用が欠かせませんが、それらは今後Kubernetesからの利用を前提とする可能性がある、ということです。
例えば、2018年に入ってKubernetes on NVIDIA GPUsという発表がなされました。
リンクのスタック図にあるように、元々NVIDIAのGPUはDocker対応を発表していましたが、Kubernetes対応を発表することで、巨大なクラスタによる機械学習等に用途を拡大しようとしています。
他にも以下のようなデバイスが今後Kubernetes対応していくことは十分に考えられ、データベースとしてもそのエコシステムを無視することはできなくなるもとの考えられます。
- NVMeストレージ ※KumoScaleなど
- 高帯域イーサやInfiniBandなど
- FPGAなどのアクセラレータ系
- SCM(Storage Class Memory)※Intel Optane Memoryなどもこれに相当
データベースをKubernetesに載せる意義
では現時点で考えた場合、データベースをKubernetesに載せることに意味はあるでしょうか?
まず考えられるメリットは以下です。
- インフラ全体としての学習コストの低下
Webシステムを構築することを考えた場合、WebサーバやアプリケーションサーバはKubernetes上に構築(移行)したとしても、データベースはクラスタ外に置くケースが殆どではないでしょうか。
もっといえば、データベースはAmazon RDSのようなマネージドなDBサービスを用いて構築してそこに接続する方式が多いように思います。
この構成自体に問題はなく、むしろ固い方式といえます。
当Advent Calenderでも触れますが、現時点でデータベース on Kubernetesを採用した場合、運用面でのデメリット(というか使い勝手の違い)が多く生じます。
それでもデータベースをKubernetes上で稼動させるメリットがあるとすれば、プラットフォームの統一による管理性の向上や学習コストの低下があげられるでしょう。
2018年時点ではAmazon RDS(やGoogle Cloud SQL)の使い勝手が悪いという人はいないでしょう。
しかし、今後Kubernetesがエコシステムを拡大していくとすれば、早いうちにそちらへインターフェースを統合しておくことのメリットが生まれてきます。
今回の連載を通して、これらのメリットを皆さんにも考えて頂く機会が生まれれば、私個人としても幸いです。
先行事例:データベース on Kubernetes
さて、ではここからは2018年末時点でのデータベース on Kubernetesとして公開されている事例をいくつか見て行きたいと思います。
なお、ここではデータベース=RDBという意味で使っています。他の方式のデータベースは紹介しておりませんが、ご了承下さい。
Stolon
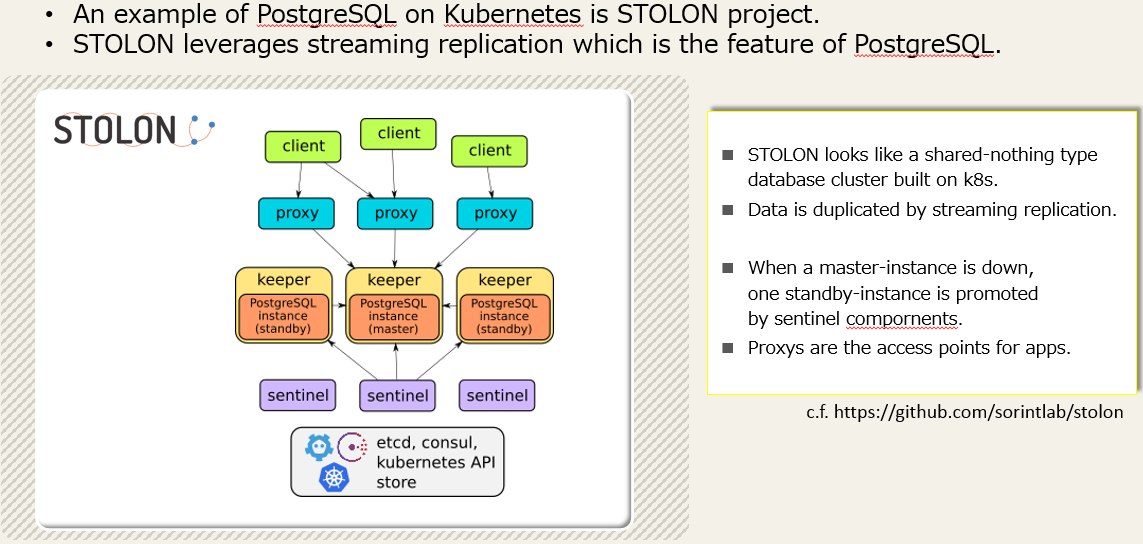
StolonはPostgreSQL on Kubernetesの実装例です。
下図にあるように、StolonではKubernetesクラスタ内にストリーミングレプリケーションを利用した複数のDBインスタンスを立ち上げます。
masterの障害時にはstandbyのうち一台が昇格する、という構成を取っています。
Vitess
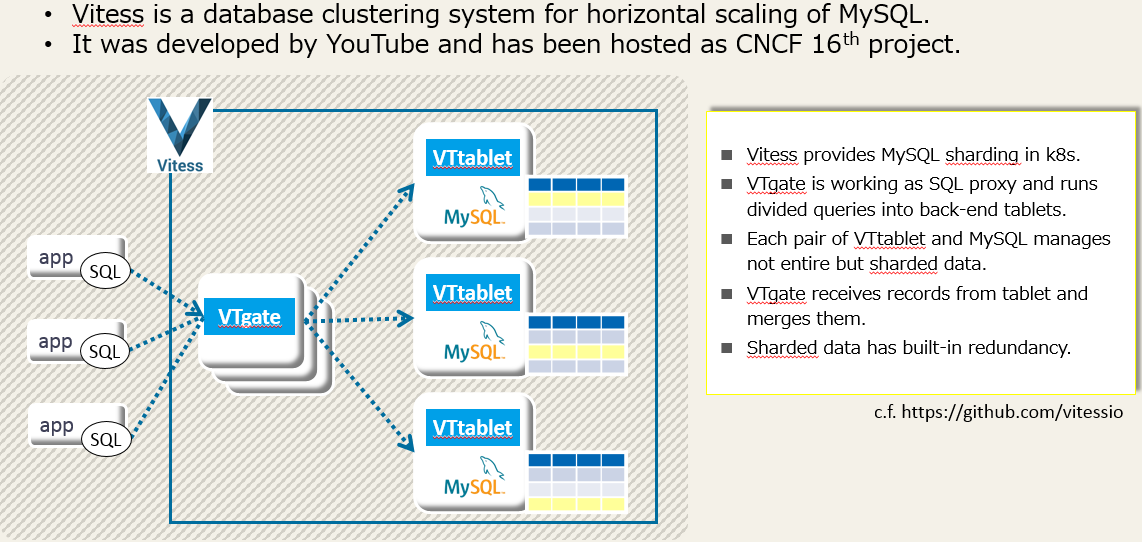
VitessはYoutubeによって開発されたOSSで、MySQLをKubernetes上に展開してスケールアウトさせるサービスです。
データベース・シャーディングの仕組みが作りこまれており、アプリケーションから見ると単一のテーブルがk8s上では複数のシャードに分割されて管理されます。
性能面で優位性がありますが、シャードのレプリカ数が設定できれば同時に耐障害性も備えることになります(但し未検証)。
詳細はcotocさんの資料を読むと良く分かると思います。
まとめ
ということで、PostgreSQL on Kubernetes Advent Calender2018の初日は、Kubernetesが現在おかれている状況とデータベースの対応を整理しました。
明日からは今回の主題であるPostgreSQL on Kubernetesのリファレンス・アーキテクチャの解説に入ります。
よろしくお願いします。