TL;DR
- StolonはKubernetes上にレプリケーション設定されたPostgreSQLクラスタを構築してくれる。
- 障害時にはネットワーク分断を考慮したMaster選出が行われ、可用性を高めている。
- StolonではStandbyノードへの参照クエリ振分けは行われない。
- シェアードナッシングで構築は容易だが、運用にはPostgreSQLの知識を要する。
Stolonとは
StolonはKubernetes上にPostgreSQLのStreaming Replicationを構成してくれるOSSです。
CNCF LandscapeでもDatabaseとして登録され、PostgreSQL on Kubernetesという観点では古参のプロジェクトになっています。
<図1 CNCF LandscapeにおけるStolonの位置付け>
Stolon開発の動機はこちらのブログに書かれていますが、ネットワーク分断体制の高いシェアードナッシング型の高可用性RDBMSをKubernetesで実現する、ということが目標になっています。
Stolonのアーキテクチャ
分散システムであるKubernetes上にPostgreSQLを配置するにあたり、ネットワークが分断した際に複数のMasterインスタンスが立ち上がることは最も避けるべきことです。
そのため、Stolonでは以下のようなコンポーネントを組み合わせることでリーダー選出のメカニズムを用いて、常に一貫性のあるデータベースクラスタを実現しています。
- sentinel・・・PostgreSQLインスタンスを監視し、最適なMasterを選出する。
- keeper・・・PostgreSQLインスタンスの本体。Read/Write可能なMasterとReadOnlyのStandbyに分かれる。
- proxy・・・クライアントからのアクセスポイントとなり、接続を管理する。
<図2 Stolonのアーキテクチャ>

Stolonを使うメリット
Stolonを使うことでPostgreSQLのStreaming Replication構成をKubernetes上に簡単に構築できます。
実はPostgreSQLのレプリケーション機能には自動フェイルオーバが含まれていません。そのため、pgpool-2のような別ツールを用いて、障害時の自動復旧を実現する必要があります。Stolonにより自動復旧も同時に実現されますので、この点でもメリットは大きいと言えます。
共有ディスクやLinux-HAの構成などを準備しなくとも、KubernetesとStolonで可用性の高いPostgreSQLを構築することが可能となります。
Stolonに足りないもの
Stolonの最大の欠点は、Standbyインスタンスへのクエリ振分けが提供されない点です。
PostgreSQLのStreaming ReplicationではMaster以外のインスタンスでも参照のみのアクセスが可能で、SELECT文をそちらで処理させることによりRead Query Offloadingが可能です。これにより限定的にデータベースのスケールアウトが可能となりますが、Stolonのproxyではこれに必要な振分けが出来ません(将来的な実装の優先順位も低いようです)。
そして、DBクラスタのデプロイ用にYAMLとHelmチャートは提供されていますが、Database on Kubernetesでは主流となりつつあるOpereatorやCRDによるクラスタ管理は実装されていません。
そのため、バックアップ等のオペレーションを助ける機能はPostgreSQL基本機能(pg_dumpなど)のみとなり、拡張ポイントも用意されていません。
そうした意味で、一世代前のPostgreSQL on Kubernetesになってしまっている感があります(私見です)。
Stolonのインストール
では、実際にStolonをインストールしていきましょう。
準備するものは以下となります。
- Kubernetesクラスタ・・・特にバージョンは問わないようです。今回は1.13で検証しています。
- Workerノード2台
今回のシステム構成図は以下のようになります。
<図3 Stolonインストール時の構成>

(Step1) クラスタの初期化
まず、必要なRoleの作成とStolonのクラスタ初期化を行います。
今回はkeeperが使うVolumeを変更したYAMLを用意したので、そちらのリポジトリから構築してみます。
$ git clone https://github.com/tzkoba/postgres-on-k8s.git
$ cd postgres-on-k8s/postgres-install/stolon/
# RoleとRoleBindingの作成
$ kubectl apply -f role.yaml
$ kubectl apply -f role-binding.yaml
# stolonctlによる初期化
$ kubectl run -i -t stolonctl --image=sorintlab/stolon:master-pg10 --restart=Never --rm -- /usr/local/bin/stolonctl --cluster-name=kube-stolon --store-backend=kubernetes --kube-resource-kind=configmap init
If you don't see a command prompt, try pressing enter.
Please enter 'yes' or 'no'
Are you sure you want to continue? [yes/no] yes
pod "stolonctl" deleted
内部を詳しくは見ていないのですが、一時的にPodを作成してクラスタの初期化処理を行っているようです。前述したOperatorやJob等でも代替可能な気がします。
(Step2) sentinelのデプロイ
次にsentinelをデプロイします。デフォルトではReplicasが2ですので、Podが2つ立ち上がります。
$ kubectl create -f stolon-sentinel.yaml
deployment.extensions/stolon-sentinel created
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
stolon-sentinel-5cbc59c45-b8pd4 1/1 Running 0 62s
stolon-sentinel-5cbc59c45-kchc7 1/1 Running 0 62s
(Step3) keeperのデプロイ
次にPostgreSQLインスタンスの本体であるkeeperをデプロイします。
今回、keeperでマウントするVolumeとしてLocal Volumeを利用しています。(ローカルボリュームって何?という方はこちらをご覧下さい。)
そのため、以下のような手順でStorageClassとPersistentVolume、PersistentVolumeClaimを作成後に、keeperのStatefulSetをデプロイします。
※なお現在のLocal Volumeは動的プロビジョニングをサポートしていません。
# kubernetes.io/no-provisionerのStorageClassを作成
$ kubectl apply -f sc-stolon-local.yaml
# 上記StorageClassを指定したPVを2つ作成、Local VolumeではNodeAffinityが必須
$ kubectl apply -f pv-stolon-local.yaml
# keeperのデプロイ
$ kubectl apply -f stolon-keeper.yaml
statefulset.apps/stolon-keeper created
(Step4) proxy、Serviceの設定
最後にproxyをデプロイし、必要なServiceを作成します。proxyは特にデフォルトのyamlを修正する必要はありません。
$ kubectl create -f stolon-proxy.yaml
deployment.extensions/stolon-proxy created
$ kubectl create -f stolon-proxy-service.yaml
service/stolon-proxy-service created
ここまでデプロイが終わると以下のようにPodとServiceが作成されています。
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
stolon-keeper-0 1/1 Running 0 5m36s
stolon-keeper-1 1/1 Running 0 5m35s
stolon-proxy-b7c9b5d7f-hmvd7 1/1 Running 0 2m42s
stolon-proxy-b7c9b5d7f-pqd86 1/1 Running 0 2m42s
stolon-sentinel-5cbc59c45-b8pd4 1/1 Running 0 37m
stolon-sentinel-5cbc59c45-kchc7 1/1 Running 0 37m
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
stolon-proxy-service ClusterIP 10.43.6.230 <none> 5432/TCP 78s
helmによるデプロイも可能
今回はStolonのgithubにあるKubernetesでの構築手順に従ってそれぞれのYAMLを適用していますが、こちらにhelmチャートも用意されています。
このあたりはお好みでどうぞ。
障害発生時の動き
さて、ここまででStolonによるPostgreSQLのStreaming Replication構成のデプロイが完了しました。
ここからは高可用性をうたうStolonで各種障害時にどのような動きとなるのかを確認していきましょう。
Streaming replicationの設定確認
まずは2台構成のStreaming Replicationの状態を確認します。
postgres=# select * from pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
usename | repluser
application_name | stolon_e8cd34f4
state | streaming
sync_state | async
(一部略)
postgres=# show wal_level;
-[ RECORD 1 ]------
wal_level | replica
postgres=# show synchronous_commit;
-[ RECORD 1 ]------+---
synchronous_commit | on
Streaming Replicationの仕様はこちらの資料などをご覧頂くとして、上記からレプリケーションが行われており、同期状態にあることがわかります。
- Streaming Replicationがasync(非同期モード)で設定されており、StandbyにWALが転送されている。
- MasterインスタンスでのコミットはWALがStandbyインスタンスでディスク書込みされるまで待機する。
上記の設定ではMasterでCommitされたデータがStandbyから参照可能であることは保証されておらず、時間差で反映されることになります。
Standbyインスタンスが稼動するノードの障害
まずはStandbyノードの障害時の動きを見ていきます。
<図5 Standbyノードの障害>
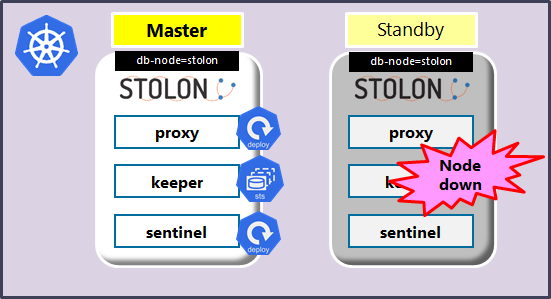
障害発生時には以下のように動作します。
- Masterでのクエリ実行、トランザクションは引き続き実行可能。
- sentinelによるリーダー選出は実行されない。
- 上記のようにproxyが障害ノードに存在し、クライアントがそちらに接続している場合、コネクションが切断されるが再接続によりサービス継続は可能。
- pg_stat_replicationからはレコードが消える?(詳細確認中)
障害復旧時(Standbyノード起動時)には以下のように動作します。
- StatefulSetがkeeperを復旧ノードで起動。
- keeperがstandbyとしてPostgreSQLを起動。
- WAL適用を行ってデータベースを復旧。
- 障害ノードで動いていたsentinel、proxyは自動で再スケジュールされない。
詳細はStandbyノードのkeeperのログとして出力されます。
WARN cmd/keeper.go:166 password file permissions are too open. This file should only be readable to the user executing stolon! Continuing... {"file": "/etc/secrets/stolon/password", "mode": "01000000777"}
INFO cmd/keeper.go:1948 exclusive lock on data dir taken
INFO cmd/keeper.go:500 keeper uid {"uid": "keeper1"}
INFO cmd/keeper.go:998 our db boot UID is different than the cluster data one, waiting for it to be updated {"bootUUID": "77af7815-d688-4330-919e-4aae1027b9c4", "clusterBootUUID": "155c1133-7a4b-497c-ad74-1681cc678c73"}
INFO cmd/keeper.go:998 our db boot UID is different than the cluster data one, waiting for it to be updated {"bootUUID": "77af7815-d688-4330-919e-4aae1027b9c4", "clusterBootUUID": "155c1133-7a4b-497c-ad74-1681cc678c73"}
INFO cmd/keeper.go:1447 our db requested role is standby {"followedDB": "f852cd7c"}
INFO cmd/keeper.go:1466 already standby
INFO postgresql/postgresql.go:307 starting database
LOG: listening on IPv4 address "10.42.10.10", port 5432
LOG: listening on Unix socket "/tmp/.s.PGSQL.5432"
LOG: database system was shut down in recovery at 2019-06-04 05:57:41 UTC
LOG: entering standby mode
LOG: redo starts at 0/8DAA418
LOG: consistent recovery state reached at 0/8DAA4F8
LOG: invalid record length at 0/8DAA4F8: wanted 24, got 0
LOG: database system is ready to accept read only connections
LOG: started streaming WAL from primary at 0/8000000 on timeline
上記の動作は単純なノードダウンを想定したケースで、復旧ノードでは障害発生時点までのデータ及びWALが保持されていることが前提となります。
Masterインスタンスが稼動するノードの障害
次にMasterインスタンス障害時の動きを見ていきます。
<図6 Masterノードの障害>
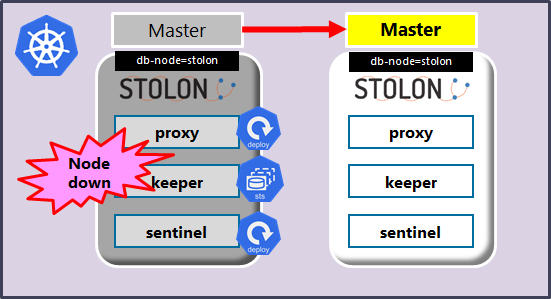
障害発生時には以下のように動作します。
- sentinelによるリーダー選出が実行され、Standbyインスタンスから1台が選出される。
- Standbyのプロモーションが実行される。完了までトランザクションは実行不可能。
- Masterの障害検知から昇格と接続受付まで50秒程度かかっている(チューニング可否は確認中)
- クライアントからは再接続が必要。
プロモーションに関わるログはStandby側のkeeperで出力されています。
2019-06-05 12:12:34.012 UTC [37] LOG: replication terminated by primary server
2019-06-05 12:12:34.012 UTC [37] DETAIL: End of WAL reached on timeline 1 at 0/9B7C6A8.
2019-06-05 12:12:34.012 UTC [37] FATAL: could not send end-of-streaming message to primary: no COPY in progress
2019-06-05 12:12:34.012 UTC [33] LOG: invalid record length at 0/9B7C6A8: wanted 24, got 0
2019-06-05 12:12:34.020 UTC [28903] FATAL: could not connect to the primary server: server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
2019-06-05T12:12:36.729Z INFO cmd/keeper.go:1447 our db requested role is standby {"followedDB": "f852cd7c"}
2019-06-05T12:12:36.729Z INFO cmd/keeper.go:1466 already standby
2019-06-05T12:13:11.966Z INFO cmd/keeper.go:1566 postgres parameters not changed
2019-06-05T12:13:11.966Z INFO cmd/keeper.go:1593 postgres hba entries not changed
2019-06-05T12:13:16.982Z INFO cmd/keeper.go:1397 our db requested role is master
2019-06-05T12:13:16.983Z INFO cmd/keeper.go:1426 promoting to master
2019-06-05T12:13:16.983Z INFO postgresql/postgresql.go:501 promoting database
2019-06-05 12:13:16.984 UTC [33] LOG: received promote request
2019-06-05 12:13:16.984 UTC [28916] FATAL: terminating walreceiver process due to administrator command
2019-06-05 12:13:16.985 UTC [33] LOG: redo done at 0/9B7C638
2019-06-05 12:13:16.985 UTC [33] LOG: last completed transaction was at log time 2019-06-04 06:18:50.012126+00
2019-06-05 12:13:16.988 UTC [33] LOG: selected new timeline ID: 2
2019-06-05 12:13:17.045 UTC [33] LOG: archive recovery complete
2019-06-05 12:13:17.060 UTC [32] LOG: database system is ready to accept connections
waiting for server to promote.... done
server promoted
2019-06-05T12:13:17.098Z INFO cmd/keeper.go:1566 postgres parameters not changed
2019-06-05T12:13:17.098Z INFO cmd/keeper.go:1593 postgres hba entries not changed
2019-06-05T12:13:22.115Z INFO cmd/keeper.go:1397 our db requested role is master
2019-06-05T12:13:22.116Z INFO cmd/keeper.go:1433 already master
障害復旧時(元Masterノードの起動時)にはStandbyノードの起動時と同様の動きとなり、WALからリカバリ後にStandbyインスタンスとしてクラスタに参加します。
まとめ
さて、どうだったでしょうか。
PostgreSQLのStreaming Replicationはver10から構築が容易になったとされますが、それでもDB技術者以外には敷居が高いものでした。
それらを容易に行ってくれるStolonは魅力的なソリューションです。
一方で設計方針は新しいとはいえず、最近ではより高機能なPostgreSQL on Kubernetesのソリューションが出てきています。
次回以降はそうしたOSSを紹介していきたいと思います。
よろしくお願いします。