この記事は「RookだらけのAdvent Calender」12日目の記事です。
昨日はRookを使ってYugaByteDBのインストールが簡単に行えることを紹介しました。
本日はYugaByteDB内にデータベースを作成し、テストデータのロードと各種クエリの実行を試していきます。
YugaByteDBの2つのインターフェース
YugaByteDBには、YugaByte Query Layer(YQL)というクエリ/コマンドのコンパイルやランタイムを担当する上位階層があります。
現在のところ、YQLは以下の2つの分散SQL APIを提供しています。
- YSQL ・・・PostgreSQL互換のSQL API
- YCQL ・・・CassandraのCQLをベースに開発されたセミ・リレーショナルなAPI
このYQLと分散ドキュメントストアであるDocDBの2層で構築されたコンポーネントが、これまで話してきたTServerということになります。
(YQLとDocDBの階層化構造)

本日は扱える2つのAPIのうち、YSQLを試していきます。
サンプルデータのロードと確認
YugaByteDBのquick-startにある「Explore Yugabyte SQL (YSQL)」の「1.Load sample data」に従って、サンプルデータをセットアップします。
必要ファイルをダウンロードし、Kubernetesで起動しているTServerのコンテナ内にコピーした後、yb_dataのデータベースをCreateし、そこにテーブル作成とデータロードを行っていきます。
ここまで完了すると、テーブルとシーケンスが4つずつ出来ていますので確認してみます。
# ysqlshで接続
$ kubectl -n rook-yugabytedb exec -it yb-tserver-hello-ybdb-cluster-0 /home/yugabyte/bin/ysqlsh -- -h yb-tserver-hello-ybdb-cluster-0 --echo-queries
ysqlsh (11.2)
Type "help" for help.
postgres=# \c yb_demo
You are now connected to database "yb_demo" as user "postgres".
yb_demo=# \d
List of relations
Schema | Name | Type | Owner
--------+-----------------+----------+----------
public | orders | table | postgres
public | orders_id_seq | sequence | postgres
public | products | table | postgres
public | products_id_seq | sequence | postgres
public | reviews | table | postgres
public | reviews_id_seq | sequence | postgres
public | users | table | postgres
public | users_id_seq | sequence | postgres
(8 rows)
YSQLでは基本的なPostgreSQLの組込み関数に対応しています。(詳細なYSQL APIはこちらで。)
各テーブルの件数を確認してみましょう。
yb_demo=# select 'users' , count(*) from users
union select 'products' , count(*) from products
union select 'orders' , count(*) from orders
union select 'reviews' , count(*) from reviews;
?column? | count
----------+-------
users | 2500
reviews | 1112
orders | 18760
products | 200
(4 rows)
問題なくデータがロードされています。
実行計画の確認
ただcount(*)するだけではつまらないので、YugaByteDBがSQLをどのように実行しているのか、実行計画を見てみましょう。
1 yb_demo=# EXPLAIN SELECT users.id, users.name, users.email, orders.id, orders.total
2 FROM orders INNER JOIN users ON orders.user_id=users.id
3 LIMIT 10;
4 QUERY PLAN
5 -------------------------------------------------------------------------------------
6 Limit (cost=0.00..0.43 rows=10 width=88)
7 -> Nested Loop (cost=0.00..213.43 rows=5000 width=88)
8 -> Foreign Scan on orders (cost=0.00..100.00 rows=1000 width=24)
9 -> Index Scan using users_pkey on users (cost=0.00..0.11 rows=1 width=72)
10 Index Cond: (id = orders.user_id)
11 (5 rows)
8行目に注目しましょう。
ここでForeign Scanという実行計画が登場しています。これはPostgreSQLが持つFDW(Foreign Data Wrapper)が使われていることを示しています。
YugaByteDBでは実行計画中でそのうちのテーブルを外部表として扱っているようです。
FDWの詳細はこちらをご覧下さい。
Tabletの状況を確認する
では、ここまでのデータは構築した3台のTServerにどのように分散されたのでしょうか。イメージとしては下図のようになります。
(Kubernetes上に構築されたYB-TServerのShardingイメージ図)
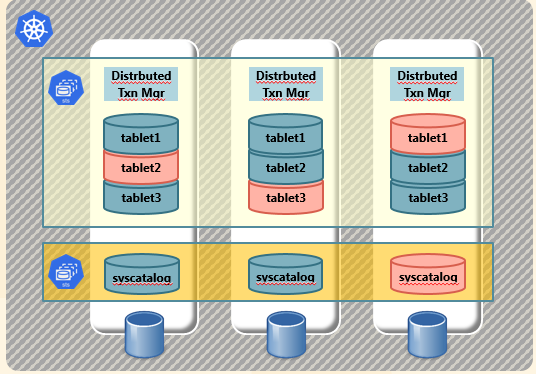
- tablet1内のデータは3重に分散され、Raftで右のノードがLeaderであることが決定しています。
- tablet2内のデータは3重に分散され、Raftで左のノードがLeaderであることが決定しています。
- 同様にYB-Masterが持つsyscatalogも分散され、Raftにより右のノードがLeaderとなっています。
実際には1つのテーブルに対して、複数のTabletでデータが分散されるため、上図のような単純なイメージとはなりませんが、概要はこのような感じです。
まとめ
さて、本日はYugaByteDBを実際に使うために、どのようなAPIがあり、どのようにデータを格納・参照するのかの手順を詳細に確認してきました。
また、YugaByteDBの特徴であるデータの分散配置(Sharding)についてもイメージを説明しました。
明日はYugaByteDBが活きるユースケースについて、少し考えてみたいと思います。
よろしくお願いします。