この記事は「RookだらけのAdvent Calender」11日目の記事です。
昨日分は概要ということで、Rookのストレージ・プロバイダーとしてYugaByteDBが入っている意味や、データベースとしてのアーキテクチャなどを簡単に解説しました。
本日からは実際にYugaByteDBをさわっていきますが、まずはRookを使ってインストールしていきます。
Rook quick start -YugaByteDB-
インストールの前提条件として、以下が必要になります。
- Kubernetesクラスタ
- 3台以上のWorker Node
- standardの名前で利用可能なStorageClass ※クラウドストレージが使いやすいはず。
上記はcluster.yamlを修正する場合には必須ではありませんが、デフォルトのyamlをapplyする際には確認しておきましょう。
準備が出来ていれば、quick startに書いてある通りにインストールを進めます。
インストールは簡単
YugaByteDBのRook対応は現時点でシンプルなので、インストール自体も簡単、2つのYAMLをapplyするだけです。
$ kubectl apply -f cluster/examples/kubernetes/yugabytedb/operator.yaml
$ kubectl apply -f cluster/examples/kubernetes/yugabytedb/cluster.yaml
これにより、rook-yugabytedb-systemとrook-yugabytedbの2つのNamespaceが切られ、OperatorおよびYugaByteDBのコンポーネントが配置されます。
KubernetesレベルでどんなPodが配置されたかを確認すると以下のようになっています。
$ kubectl get pod -n rook-yugabytedb-system
NAME READY STATUS RESTARTS AGE
rook-yugabytedb-operator-7f4b8c7dc5-prpk4 1/1 Running 0 1d
$ kubectl get pod -n rook-yugabytedb
NAME READY STATUS RESTARTS AGE
yb-master-hello-ybdb-cluster-0 1/1 Running 0 1d
yb-master-hello-ybdb-cluster-1 1/1 Running 0 1d
yb-master-hello-ybdb-cluster-2 1/1 Running 0 1d
yb-tserver-hello-ybdb-cluster-0 1/1 Running 0 1d
yb-tserver-hello-ybdb-cluster-1 1/1 Running 0 1d
yb-tserver-hello-ybdb-cluster-2 1/1 Running 0 1d
何が出来たか
先ほどのPodを確認すると、YugaByteDBの2種類のプロセスが確認できます。
- YB-Master process ・・・メタデータの管理や操作の振分けを担当
- YB-TServer process ・・・テーブルデータの保持/提供を担当
詳しい用語の解説はこちらの公式ドキュメントに記載があります。
MasterおよびTServerではメタデータ/ユーザデータを3重に分散して持ち、RaftによりLeader-Followerを決定しています。
上記の用語を抑え、Kubernetes上のNodeに分散配置されたYugaByteDBのプロセスを図示すると下図のようになります。それぞれのPodにはPersistentVolumeが接続されています。
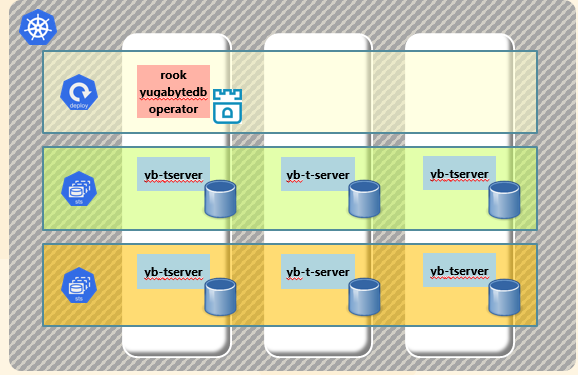
YugaByteDBへの接続
構築が完了したYugaByteDBには、YB-TServerのPodにkubectl execで接続し、そこからysqlshというクライアントツールでログインします。
※ysqlshはPostgreSQLのpsqlに相当するものと考えて下さい。
(kubectlとysqlshを使った接続の例)
$ kubectl -n rook-yugabytedb exec -it yb-tserver-hello-ybdb-cluster-0 /home/yugabyte/bin/ysqlsh -- -h yb-tserver-hello-ybdb-cluster-0 --echo-queries
ysqlsh (11.2)
Type "help" for help.
postgres=#
見て頂くと分かるとおり、ysqlshの表示内容はpsqlそのものです。
Web UIも同時に起動される
YugaByteDBをRookでインストールすることで、管理用のユーザインタフェースも同時に導入されます。
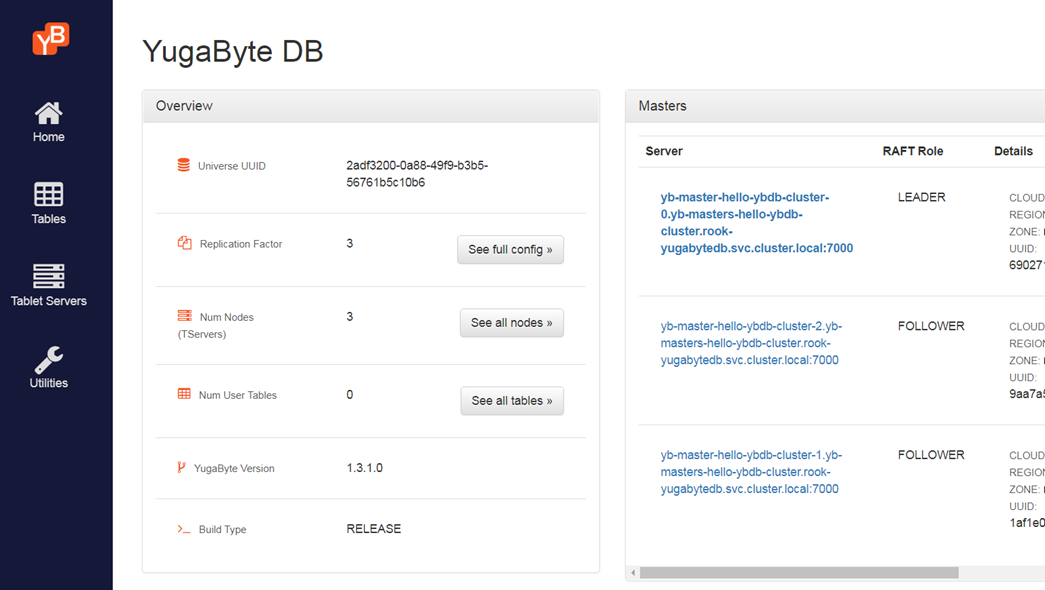
こちらの利用にはKubernetes環境に応じたServiceのセットアップが必要になりますので、こちらを参考に設定して下さい。
まとめ
ここまでRookでYugaByteDBをインストールし、CLIとUIでの接続を試してきました。
明日からは実際にテーブルを作成し、データを入れた後にSQLクエリの実行を行っていきます。
よろしくお願いします。