はじめに
バンディット問題に対する基本的な方策アルゴリズムについて勉強したのでそのまとめです。
バンディット問題とは
バンディット問題とは
- 未知の報酬が設定された選択肢が多数存在する
- 多数の選択肢の中から1つを選択する
- 選んだ選択肢に対する報酬を得る
- 選ばなかった選択肢に対する報酬は得られない
という設定において、繰り返し選択を行う過程で得られる報酬を最大化しようという問題です。特に選択肢が複数あるケースは多腕バンディット問題と呼ばれます。
報酬を最大化するためにはいろいろと試すことで報酬の高い選択肢を探す必要がありますが、探索に重点を置きすぎると探索に時間をかけた分だけ高報酬の選択肢から報酬を受ける期間が短くなってしまい、結果として得られる報酬の総和は低くなってしまいます。
そのためバンディット問題では得られる報酬を最大化するためには、良い選択肢の探索と過去に選んだ選択肢に対する知識の利用のバランスが重要になります。
今回は選択肢からの報酬が確率的に得られる確率的バンディット問題を対象とします。
応用例-インターネット広告
ウェブサイトの広告はユーザーのクリックや広告商品を購入する行動を報酬と考えると、多数ある広告から表示する広告を選択し、最終的な報酬の最大化を目指す過程はバンディット問題として捉えることができます。
方策アルゴリズム
方策アルゴリズムとはバンディット問題に対し、ベスト(最適解)とまでは行かなくともそこそこうまくいく近似解として提案されているアルゴリズムです。以下では基本的な方策アルゴリズムの説明を行います。
ε-greedy法
$\epsilon$-greedy法では全期間を通して選択を行う回数を$T$、選択肢の数を$K$、パラメータを$\epsilon$ $(0 < \epsilon < 1)$ とすると
- $1$ ~ $\epsilon T$ 回目の選択 : 各選択肢を$\epsilon T/K$回ずつ選択する
- $\epsilon T+1$ ~ $T$ 回目の選択 : 上の選択で最も報酬の良かった選択を選択し続ける
のように選択を行います。最初はいろいろ試して、良かったものに全力投球するという考え方で非常に直感的です。
わかりやすい半面、欠点としてはアルゴリズムの性能がパラメータ$\epsilon$の値に大きく依存すること、選択肢の数が多い場合は性能が落ちる点(選択肢の数が多いと探索期間にその分だけ報酬が最大でない選択肢を選ばなければならないため)が挙げられます。
UCB方策
UCB(Upper Confidence Bound)方策のアルゴリズムでは選択肢に対して、UCBスコア
\overline{\mu}_i(t) = \hat{\mu}_i(t) + \sqrt{\frac{\log t}{2N_i(t)}} \\
$\overline{\mu}_i(t)$ : $t$回目の選択における選択肢$i$のUCBスコア
$\hat{\mu}_i(t)$ : $t$回目までに選択した結果得られた選択肢$i$の報酬の平均(報酬の標本平均)
$N_i$ : $t$回目までに選択肢$i$を選択した回数
の計算を行い、スコア値が大きい選択肢ほど優先的に選択します。
この式を見ると右辺第1項は選択肢の報酬の標本平均となっており、式全体としては標本平均+補正項という形になっています。
報酬の分布は選択を無数に繰り返していくことである分布に近づいていきます。上式の補正項はすでに観測した報酬の分布と近づいていく先の分布(報酬の真の分布)との差を反映しており、この差を考慮して選択を行うことで報酬の最大化を目指します。
UCB方策のアルゴリズムは以下の様になります。
UCB方策
選択を行う回数を$T$、選択肢の数を$K$とします。
- 全ての選択肢を1回ずつ選択する。
- 各選択肢についてUCBスコアを計算する
- UCBスコアが最大の選択肢を選択する(スコアが等しい選択肢については適当に選択する)
- 2, 3を繰り返す。
先程の$\epsilon$-greedy法とは異なり、外部パラメータが存在しないので扱いやすいです。
UCB方策には更に報酬の最大化を追求したKL-UCB方策などの発展形があります。
UCBスコアは選択時点での報酬の標本と漸近分布(選択を無限に繰り返した場合に得られる報酬の分布)の違いを考慮して設計されているため選択回数がそこまで多くない場合は性能が安定しないようです。
トンプソンサンプリング
トンプソンサンプリングは確率一致法と呼ばれる手法の一種で、選択によって得られる報酬の期待値を定式化し、選択-期待値評価のサイクルを繰り返して行きます。UCB方策とは異なり漸近していく分布を考慮していないため、有限回の選択において性能が良いようです。
アルゴリズムは以下です。
トンプソンサンプリング
パラメータ
$\alpha > 0$, $\beta > 0$
$m_i$: 選択肢$i$から得た累積報酬
$n_i$: 選択肢$i$の総選択回数
$\tilde{\mu_i}$: ランダム生成した選択肢$i$の報酬の期待値
$X_i(t)$: 選択肢$i$を選択して得られる報酬(0 or 1)
- 各$i$に対し$m_i=0$、$n_i=0$とする。
- 各選択肢$i$に対して乱数$\tilde{\mu_i}$をベータ分布$Beta(\alpha+m_i, \beta+n_i-m_i)$からサンプリングする。
- 2の乱数$\tilde{\mu_i}$が最大となる選択肢$i$を決定する。
- 選択肢$i$を選択し、報酬$X_i(t)$を得る。
- $n_i = n_i + 1$、 $m_i = m_i + X_i(t)$
- 2~5を繰り返し実行する。
トンプソンサンプリングの背後にあるのはベイズの定理です。
\pi(\mu\,|\,X)\propto f(X\,|\,\mu)\,\pi(\mu)
左辺は事後分布、右辺第1項が尤度、右辺第2項が事前分布となっています($X$はデータを、$\mu$は分布のパラメータを表します)。
ベイズ統計ではデータの生成元の分布に対して事前分布を設定し、設定した事前分布から実際に観測したデータが生成される確率(尤度)を計算して、データに対して設定した分布の更新を繰り返し改善していきます(更新後の分布が事後分布)。今回のケースでは事後分布は選択によって得られる報酬の期待値の分布になります。
また、上のケースでは報酬は有り・無しの2択(0 or 1)で分布はベルヌーイ分布となるため、その共役事前分布としてアルゴリズム内にベータ分布が現れています。
共役事前分布 : 計算上の利便性のために事前分布と事後分布が同じ関数型を持つように設計された分布のこと。
性能評価シミュレーション
開発環境
- python 3.6.5
- numpy 1.16.4
- matplotlib 3.1.0
プログラムのについて
作成したプログラムはgithubに上げています。
https://github.com/t-yoshitake/bandit-sim
計算条件
モデル
Web広告のケースを想定し、広告のクリックイベントを報酬として設定しました。
広告は表示された場合、潜在的なある確率(CTR, Click Through Rate)でユーザーにクリックされるとします。
また、シミュレーションに用いる広告のCTRは指数分布に従って生成しています。
アルゴリズム比較
作成した広告モデルに対してランダムなサンプリング、$\epsilon$-greedy法、UCB方策、トンプソンサンプリングのシミュレーションを行い、報酬の推移、累積報酬を手法ごとに比較しました。
$\epsilon$-greedy法については$\epsilon$値が0.3, 0.6の場合について計算を行いました。
結果・考察
以下の条件でシミュレーションを行いました。
- 広告数: 200
- 広告の平均CTR: 0.08
- 総選択数: 10000回
- 試行回数: 5000回
シミュレーションに用いた広告CTRのヒストグラム図は以下のようになります。

横軸が広告のCTR、縦軸が広告数です。多数の広告はほとんどクリックされずほんの一部だけがCTRが高いという状況を想定して指数分布から生成しました。
下図が選択過程における報酬の推移図です。
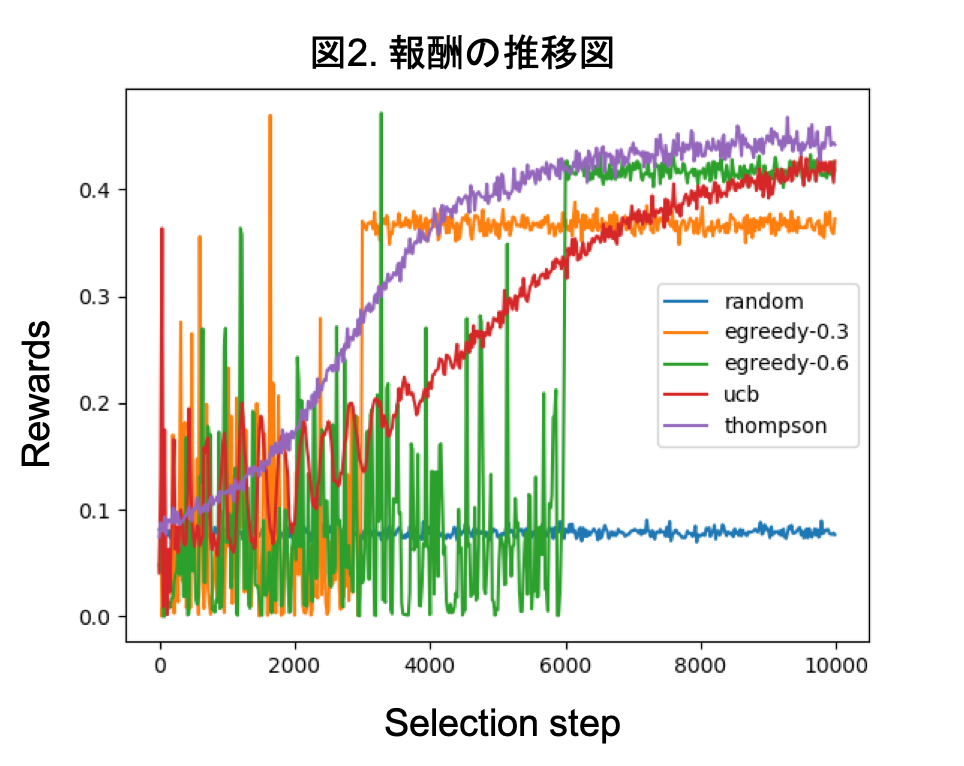
横軸が選択ステップ、縦軸が報酬です。図の結果は各試行の結果を平均したものです。
この図からランダムサンプリングでは報酬が一番低くなっていることがわかります。$\epsilon$-greedy法に関してはそれぞれ設定した$\epsilon$値に応じて報酬の変動が大きい期間があり、その後比較的高い報酬で一定しています。図からは$\epsilon$値が0.6のほうが0.3の場合よりも探索後の期間の報酬が高くなっています。これは0.6の場合のほうが広告の探索に多くの期間を費やしており、各広告のCTRをより正確に見積もれているためです。
一方UCB方策とトンプソンサンプリングについては早い段階で報酬が増加しており全体的に高い報酬を得られています。
次に各アルゴリズムについて累積報酬の平均と標準偏差を計算し、図示したものが下図になります。
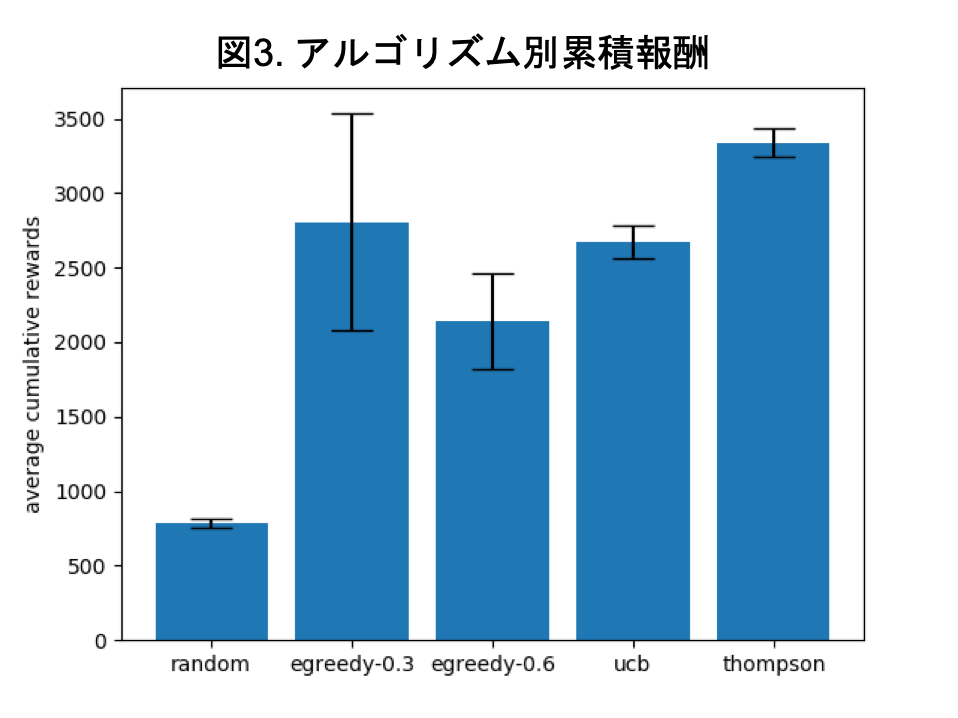
$\epsilon$-greedy法の2つについては他のよりも標準偏差が大きく、報酬が不安定であることがわかります。また、$\epsilon$値の違いで結果に大きな違いが出ているので、$\epsilon$値の設定にも敏感であることがわかります。
全体を比較するとトンプソンサンプリングの平均累積報酬が最も高くなりました。また、標準偏差もトンプソンサンプリングの場合かなり小さく、安定して高い報酬を得られたことがわかります。
この図から今回のシミュレーションのケースではトンプソンサンプリングがベストな方策アルゴリズムであると言えます。
終わりに
- 今回扱ったバンディット問題は非常に単純なものでしたが、より複雑なモデルを対象としたバンディット問題もいろいろと考えられています。その辺りは今後学習していきたいと思います。
参考
- バンディット問題全般について
- バンディット問題の理論とアルゴリズム 本田淳也・中村篤啓祥
- ベイズ統計について
- ベイズ推論による機械学習入門 須山敦志・杉山将
- https://to-kei.net/bayes/bayes-theorem/