STM32Cube.AIは、STのAIエコシステムに含まれるSTM32Cube拡張パッケージです。
マイコンの初期化コード自動生成ツール「STM32CubeMX」の機能を拡張して、学習済みニューラル・ネットワークを自動変換し、ユーザのプロジェクトに統合できるように最適化されたライブラリを生成します。また、PCとSTM32マイコンの両方でニューラル・ネットワーク・モデルを検証し、STM32マイコンでのパフォーマンスを測定する方法を提供するため、ユーザがこのためにCコードを自作する必要はありません。
前回の記事では、STM32Cube.AIとそのワークフローの基本的な特長を概説しました。今回は、STM32Cube.AIの先進機能をより詳しく紹介します。取り上げるトピックは以下の通りです。
- ランタイム・サポート:Cube.AIとTensorFlow Liteの比較
- 量子化のサポート
- グラフ・フローとメモリ・レイアウトの最適化
- リロケータブル・バイナリ・モデルのサポート
ランタイム・サポート:Cube.AIとTensorFlow Liteの比較
STM32Cube.AIは、Cube.AIとTensorFlow Liteの2種類のランタイムをサポートしています。デフォルト・ランタイムのCube.AIは、STM32マイコン向けに高度に最適化された機械学習ライブラリです。TensorFlow Lite for Microcontrollerは、マイコンやメモリが数キロバイトしかない製品などで機械学習モデルを実行するためにGoogleによって開発されたもので、マイコン・ベースのアプリケーションで広く使用されています。
STM32Cube.AIでは、TensorFlow Lite for Microcontrollersランタイム(TFLm)と関連TFLiteモデルを含むSTM32 IDEプロジェクトを生成し、すぐに使用することができます。
TensorFlow Liteは、複数のプロジェクトで共通のフレームワークを使用したい場合に適したランタイムです。
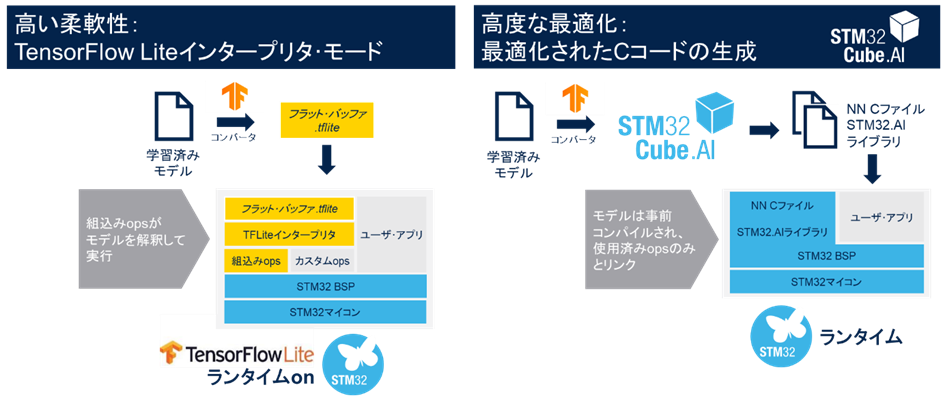
どちらのランタイムも、リソースに制約のあるプロジェクトに合わせてマイコンを適応させるように設計されていますが、Cube.AIは、とりわけSTM32マイコンの独自アーキテクチャ向けに最適化されています。TensorFlow Liteがプラットフォーム間の移植性をより重視しているのに対し、Cube.AIは演算速度とメモリ使用量の高い要件を持つアプリケーションをターゲットにしています。
次の表は、リファレンス用の学習済みニューラル・ネットワーク・モデルに基づいて、2つのランタイムのパフォーマンスを比較したものです。STM32マイコンの推論時間とメモリ使用量を評価指標としています。

表からわかるように、同一モデルで比較した場合、Cube.AIランタイムはTFLiteランタイムと比較してFlashメモリ使用量が約20%、RAM使用量が約8%少なくなっています。さらに、TFLiteランタイムの2倍近いスピードで実行されています。なお、STM32U585マイコンとSTM32H723マイコンの最大周波数は、それぞれ160MHzと550MHzです。
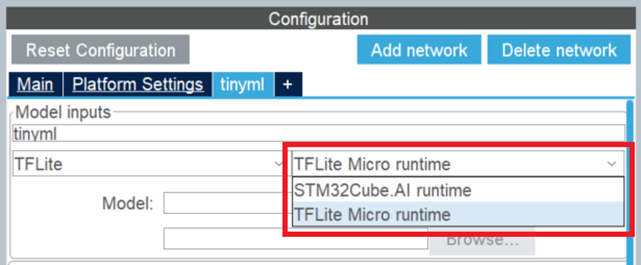
TFLiteモデルでは、STM32Cube.AIのネットワーク設定で、ユーザが2つのランタイムからいずれかを選択可能です。
量子化のサポート
量子化は、広く使用されている最適化手法で、32bitの浮動小数点モデルをビット数の少ない整数モデルに圧縮します。これにより、わずかな精度低下で、ストレージ・サイズと実行時のピーク・メモリ使用量を減らし、CPU / MCUの推論時間と消費電力を改善することができます。量子化モデルでは、一部またはすべてのテンソル演算を、浮動小数点値ではなく整数で実行します。マイコンのようなリソース制約の厳しいランタイム環境に対応するためには、量子化に加えて、枝刈り(プルーニング)や重みの圧縮など、各種最適化手法が重要です。
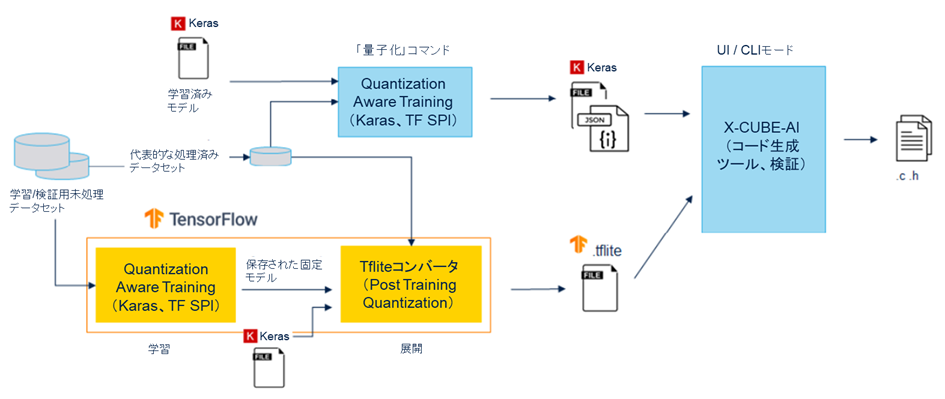
量子化には、Post Training Quantization(PTQ)とQuantization Aware Training(QAT)という2つの手法があります。PTQは比較的実装が簡単で、限られた代表的なデータセットでの学習済みモデルの量子化が可能です。QATは学習中に実行され、多くの場合、モデル精度が高くなります。
STM32Cube.AIは、以下2つの方法で、両方の量子化手法を直接 / 間接的にサポートします。
-
STM32Cube.AIは、PTQ / QATプロセスいずれの場合で生成された量子化TensorFlow Liteモデルで使用できます。この場合、量子化はTensorFlow Liteフレームワークにより実行され、主に「TFLiteコンバータ」ユーティリティ経由でTensorFlow Liteファイルがエクスポートされています。
-
コマンド・ライン・インタフェース(CLI)にも、学習済みKerasモデルの各種量子化スキームを備えた内部PTQプロセスが統合されています。TFLiteコンバータ・ユーティリティを使用するPTQと比べると、より多くの量子化スキームを提供するため、実行時間と精度において高い性能を期待できます。
次の表は、STM32マイコンで量子化モデルを展開した場合のメリットを、元の浮動小数点モデルと比較したものです。ベンチマーク・モデルとしてFD-MobileNetを使用し、12のレイヤ、145kのパラメータ、24MのMACC演算、224 x 224 x 3の入力次元を使用しました。

表からも明らかですが、量子化モデルはFlashメモリ使用量を約1/4削減し、約3倍の実行速度を実現する一方で、精度低下はわずか0.7ポイントでした。なお、STM32H7マイコン(動作周波数400MHz)を使用しています。また、FP-AI-VISION1のv1.1.0およびSTM32Cube.AI v5.0.0で測定されたデータであり、各種ライブラリは随時アップデートされています。
X-Cube-AIパッケージをインストールしている場合は、次のパスから、Cube.AIのCLIを使用する量子化手法のチュートリアルを見ることができます。
C:\Users\username\STM32Cube\Repository\Packs\STMicroelectronics\X-CUBE-AI\version\Documentation\quantization.html
チュートリアルの最後には、簡単なハンズオン・サンプル「Quantize a MNIST model(MNISTモデルの量子化)」も含まれているので、是非アクセスしてみてください。
グラフ・フローとメモリ・レイアウトの最適化
STM32Cube.AIは、量子化手法に加えて、Cコード生成ツールのオプティマイザ・エンジンにより、推論演算時間に対するメモリ使用量(RAMおよびROM)の最適化に貢献します。これは、いくつかのデータセットレス・アプローチに基づいているため、圧縮および最適化アルゴリズムを適用するための、学習済みの有効なデータセットやテスト・データセットは不要です。
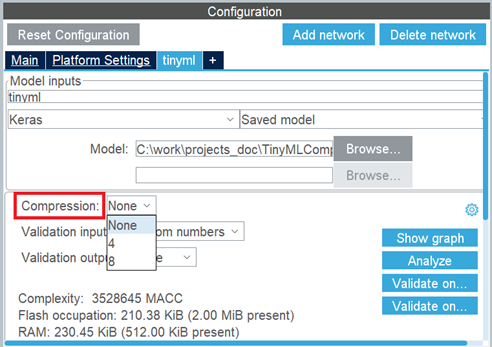
1つ目のアプローチは重み / バイアスの圧縮で、K-meansクラスタリング・アルゴリズムを適用します。この圧縮アルゴリズムは全結合層のみに適用されます。迅速な圧縮プロセスがメリットですが、全体的な精度に影響を与える可能性もあります。生成されたCモデルの「検証」プロセスは、発生したエラーを評価するための緩和策として提供されています。
次の図に示すように、この圧縮はSTM32Cube.AIのネットワーク設定で有効化できます。
 |
2つ目のアプローチは融合演算で、層のマージによりデータ配置と関連する演算カーネルを最適化します。一部のレイヤ(「ドロップアウト」、「リシェイプ」など)は、変換または最適化の途中で除外され、その他のレイヤ(非線形層や、畳み込み層の後のプーリング層など)は前のレイヤと融合されます。結果として、多くの場合、変換後のネットワークは層が少なくなるため、メモリ内のデータ・スループット削減につながります。
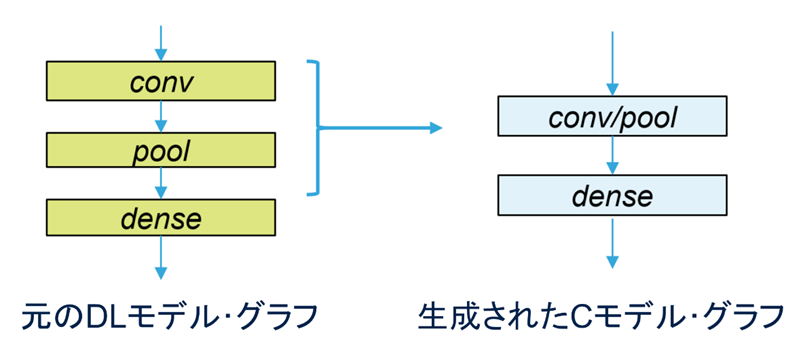
最後のアプローチは、アクティベーション・メモリの最適化です。R/Wチャンクは、一時的な隠れ層の値(アクティベーション演算子の出力)を保管するために定義され、推論関数によって使用されるスクラッチ・バッファと見なすことができます。アクティベーション・メモリは異なる層にわたって再利用されるので、アクティベーション・バッファ・サイズは、連続する2層の最大メモリ要件によって定義されます。
リロケータブル・バイナリ・モデルのサポート
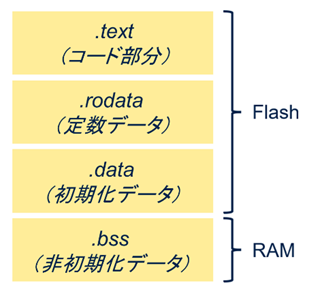
リロケータブルではないアプローチ(いわゆる「静的」アプローチ)とは、生成されたNNモデルのCファイルがコンパイルされて、エンド・ユーザのアプリケーション・スタックと静的にリンクされるケースです。次の図に示すように、ニューラル・ネットワーク部分とユーザ・アプリケーションを含むすべてのオブジェクトが、データ・タイプ別に異なるセクションにリンクされています。この場合、ユーザが関数の一部を更新するには、ファームウェア全体をアップデートする必要があります。
 |
対照的に、リロケータブル・バイナリ・モデルの場合、バイナリ・オブジェクトはSTM32マイコンのメモリ・サブシステムのどこにでもインストールして実行できます。オブジェクトには、生成されたNNモデルの Cファイル(必要なフォワード・カーネル関数と重みを含む)のコンパイル版が含まれます。ここでの最大の目標は、再生成とエンド・ユーザ・ファームウェアのFlash書き込みなしで、AIベースのアプリケーションを柔軟にアップグレードできるようにすることです。
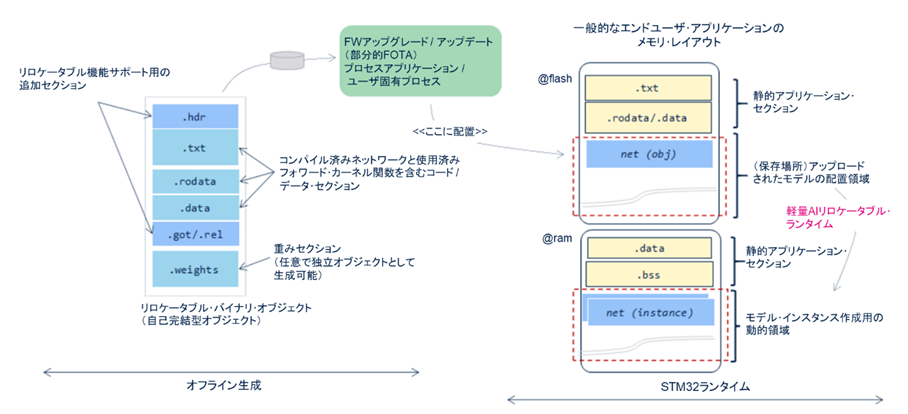
生成されるバイナリ・オブジェクトは軽量のプラグインで、任意のアドレスから実行でき、メモリ内の任意の場所にデータを格納できます(位置独立データ)。STM32Cube.AIは、シンプルかつ効率的なAIリロケータブル・ランタイムであり、インスタンス化して使用可能です。STM32ファームウェアには、複雑でリソース消費量の多いArm® Cortex®-Mマイコン向けのダイナミック・リンカーは組み込まれておらず、生成済みオブジェクトは自己完結型エンティティなので、実行時に外部のシンボルや関数は必要ありません。
下図の左側に示すニューラル・ネットワークのリロケータブル・バイナリ・オブジェクトは、自己完結型で、エンド・ユーザ・アプリケーション内の独立した領域に配置されます。STM32Cube.AIのリロケータブル・ランタイムからインスタンス化し、動的にリンクすることができます。そのため、AIモデルの変更時にユーザが更新する必要があるのは、バイナリのこの部分だけです。また、柔軟性をさらに高めるため、ニューラル・ネットワークの重みを別オブジェクトとして生成することも可能です。
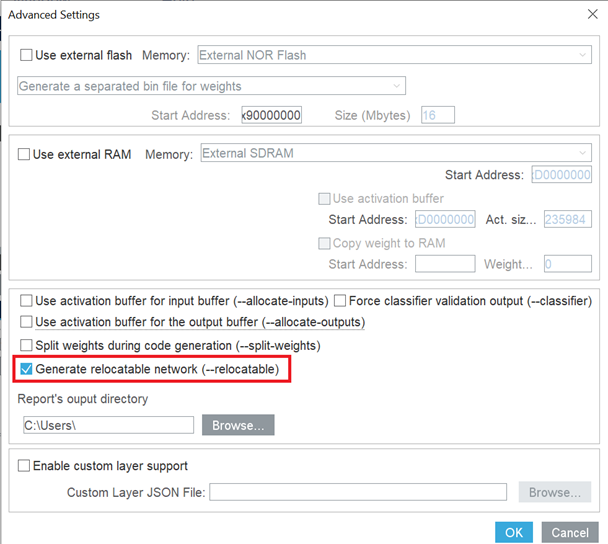
次の図に示すように、STM32Cube.AIの詳細設定でリロケータブル・ネットワークを有効化することができます。
STのAIエコシステムの主要ツールであるSTM32Cube.AIは、基本的なものから高度なものまで、さまざまな機能を備えています。これにより、ユーザが高度に最適化された柔軟なAIアプリケーションを簡単に作成できるようにサポートします。