機械学習やディープ・ラーニングのネットワークは、センサなどで取得したデータを堅牢性の高い手法で解析することができ、IoT機器の価値を大幅に向上させる技術として注目されています。ディープ・エッジAIによってアルゴリズム・サイズの縮小が進み、センサの周辺で演算を実行できるようになりました。IoTの急速な成長に伴い、産業機器(Industry 4.0)、コンスーマ機器、ビル管理、ヘルスケア、農業など、さまざまな市場でさらなる価値を提供するため、最適化された処理機能のニーズが高まっています。
一方で、システムの演算能力やメモリ、消費電力に制約がある組込み機器にAIモデルを移植する場合、さまざまな技術的課題も発生します。マイクロコントローラ(マイコン)はコスト・パフォーマンスが高く、特定の市場セグメントに特化しており、低消費電力で迅速な開発が可能であるため、組込みアプリケーションに最適です。しかし、Arm® Cortex®-Mを使用した組込みシステム開発では、より高性能のアプリケーション・プロセッサを使用する場合と異なるスキルが求められます。
STマイクロエレクトロニクス(以下ST)は、機器メーカーが最高の製品を最短期間で設計できるよう、包括的なAI開発エコシステムを提供しています。開発エコシステムには、開発ボードや開発ツールに加え、STM32マイコン / マイクロプロセッサで実行されるサンプル・コードも含まれています。そのため、サンプル・コードをもとに新機能を迅速に実装可能です。また、開発ツールを使用することで、テストやベンチマーキングを繰り返し、ニューラル・ネットワークをはじめとする最適化された機械学習モデルの移植を簡単に実現できます。
STが提供するAI開発ツール「STM32Cube.AI」は、広く使用されているマイコンの初期化コード自動生成ツール「STM32CubeMX」の拡張パッケージで、STM32マイコンへの組込みAI実装をサポートします。あらゆるSTM32 Nucleoボードに対応するコード生成や、IAR Embedded Workbench®、MDK-ARM、STM32CubeIDE(GCCコンパイラ)との互換性など、STM32CubeMXの機能を任意のOS(Windows、Linux、Mac OS)で利用できます。

STM32CubeMXは、パラメータの制約条件を動的に検証することで、ペリフェラルとミドルウェアの機能モードを自動的に設定します。また、最適なパラメータでクロック・ツリーを自動的に初期化し、動的に検証します。
また、STM32Cube.AIは、STM32Cube開発エコシステムに統合されているため、幅広いSTM32マイコンに効率的にAIモデルを移植できるだけでなく、類似モデルが他のマイコン製品に適している場合は、STM32マイコンの製品ポートフォリオ全体で簡単に移行できます。
STM32Cube.AIでは、学習済みAIアルゴリズムの自動変換機能や、生成された最適化済みライブラリをユーザ・プロジェクトに統合できるため、手作業でコードを作成する必要がなくなります。また、ディープ・ラーニング・ソリューションを幅広いSTM32マイコンに組み込んで、インテリジェントな機能を追加することもできます。
STM32Cube.AIは、Keras、TensorFlow™ Liteなどの各種ディープ・ラーニング・フレームワークに対応しており、PyTorch™、Microsoft® Cognitive Toolkit、MATLAB®など、ONNX標準フォーマットにエクスポートできるあらゆるフレームワークに対応しています。
また、Isolation Forest、Support Vector Machine(SVM)、K平均法など、広範なMLオープンソース・ライブラリであるScikit-Learnに含まれる標準的な機械学習アルゴリズムをサポートしています。

学習済みモデルをSTM32CubeMXにロードしてAIランタイムを選択するだけで、STM32Cube.AIによって自動的にモデルが分析され、モデルの適切な保管と実行に必要な最小容量が表示されます。ユーザは使用可能なSTM32マイコン / マイクロプロセッサのリストから、プロジェクト要件に最適な製品を選択することができます。
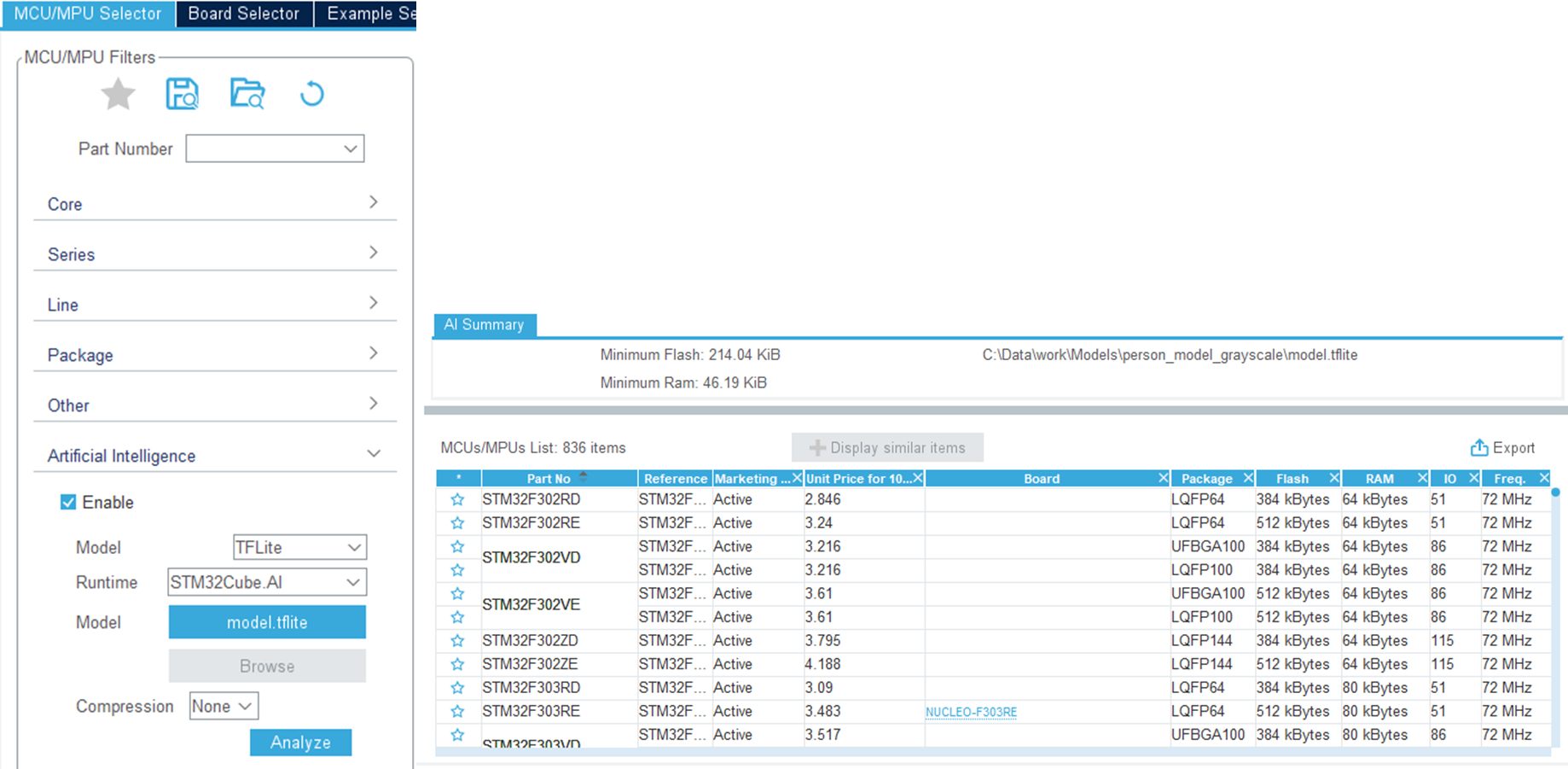
最適なマイコンを選択すると、最適なマイコン設定が自動的に指定された開発ボードを直接選択することができます。1つまたは複数のAI / MLモデルを選択してツールで分析すると、総合的なモデルの複雑さとRAM / Flashの容量が評価されます。また、モデルをグラフィカルに表示することも可能で、各レイヤを表示して、どこにモデルの複雑さがあるかを確認することができます。KerasおよびTensorFlow™ Liteニューラル・ネットワークでは、8bitの量子化モデルがサポートされています。また、カスタム・レイヤでツールを拡張すると、ユーザ定義レイヤを含むモデルの追加とベンチマーキングが可能です。
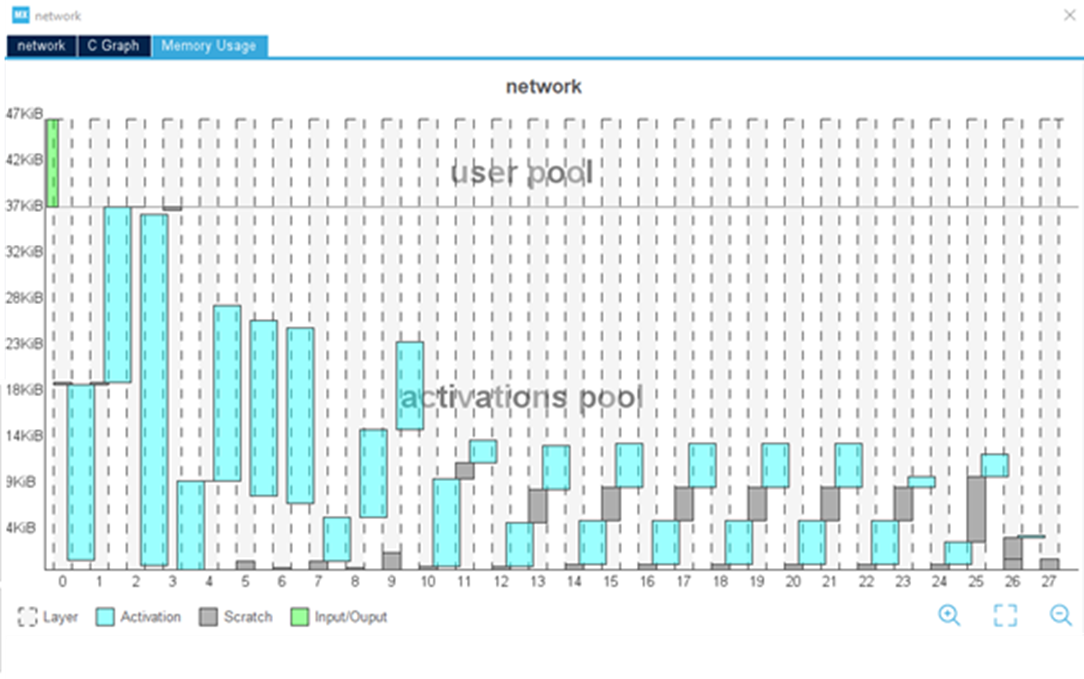
STM32Cube.AIを活用してモデルを最適化することで、より大規模なニューラル・ネットワークもマイコンに移植できます。グラフィカル・ユーザ・インタフェース(GUI)は、生成されたコード内で使用されるバッファの全体像表示や、モデル実装時のメモリ容量を最小化するための入出力とアクティベーション・バッファ間のメモリ・オーバーレイなど、複数の最適化オプションを備えています。
STM32Cube.AIは、外部メモリの使用をサポートしており、異なるメモリ領域間で簡単に重みを分割できます。複数のアレイにモデルを格納した後で、モデルの重みの一部を内部メモリにマッピングし、残りを外部Flashメモリにマッピングして、アクティベーション・バッファを外部RAMにマッピングすることができます。
また、開発期間の短縮を目的に設計されているため、開発者はデスクトップ上でモデルを検証して迅速にベンチマーキングしたり、製品上での検証によって、最終的なモデル性能を量子化の影響を含めて測定したりできます。検証プロセスの最後に、元のモデルとSTM32モデルでの精度およびエラーをまとめた比較表が生成され、オプションで、レイヤごとの複雑さを示すレポートと、実行中に測定された推論時間が提供されます。
ニューラル・ネットワーク・コンパイラは、効率とメモリ容量の観点から最適化したコードを生成します。レイヤとカーネルは、STM32マイコンで動作し、その製品機能を活用するように設計されています。すべての設定を選択した後、STM32Cube.AIによってアプリケーション・テンプレートが生成されるため、ユーザは任意のIDEで、アプリケーション専用コードに直接統合可能です。その後、STM32CubeMX、STM32CubeMonitor、STM32CubeMonPower、STM32CubeMonRF、STM32CubeMonUCPD、およびその他多数のパートナー・ツールを含む開発ツールを使用して、AIアルゴリズムを利用する最終アプリケーションを設計できます。
STM32Cube.AIは、複数のプロジェクトにまたがる共通フレームワークを必要とする開発者向けに、TensorFlow Liteランタイムもサポートしています。これは、ユーザ・インタフェースから、STM32Cube.AIの代わりに選択できますが、STM32向けのランタイム最適化レベルは低いため、性能が低下する場合があります。
STM32Cube.AIは、高品質な開発を実現する長期サポートと優れた信頼性を提供します。最新のAIフレームワークとの互換性は、メジャー・アップデートで定期的に更新されます。
STM32Cube.AIは、GUIだけでなくコマンド・ラインとしても提供されており、DevOpsフローに簡単に統合できるため、あらゆるAI開発領域の定期的な検証を確実に実行できます。さらに、導入後チェックを備えたAutoMLフローを構築することで、分析 / 検証機能を利用して、ユース・ケースの対象となるメモリ / 推論時間 / 精度の制約に対応する正しいモデルを識別可能です。
ライブラリは再配置可能なモデルとして導入できるため、現場で継続的にモデルをアップデートできます。そのため、ファームウェアを完全にアップグレードせずに、モデルのトポロジと重みを簡単にアップデートすることができます。製品のアップデートは簡略化されており、Over The Airモデル更新(または部分的なFOTA:Firmware Over The Air)によってディープ・エッジAIの最新状態が維持され、現場で発生した変更がすべて反映されます。アップグレードの場合は、モデル / ソフトウェア・アップデートによって新機能が追加されます。
STM32マイコンを使用する開発者は、さまざまなAI機能を活用できます。詳細については、STのウェブサイトをご覧ください。