グーグルニュースは関心があるキーワードや文章で検索すると、関連度順とリリース日時順で整理して100件の記事を表示してくれます。
食品のヒット商品出現の経緯を探るために、ヒットした食品に関係しそうなキーワードや文章で検索して過去のニュースを調査して、それらのニュースリリース時の関心の上昇度をグーグルトレンドで確認することで、ヒットに至る経緯を探ることができそうです。新たなヒットにつながる話題を捕まえるにも使えそうです。
前報告ではPythonでグーグルニュースのRSSをパースする方法(feedparser)を紹介しました。
Pythonでグーグルニュースをスクレイピングして、Rで編集。
しかし、この方法では今年2019年10月頃からsummaryのテキストがtitleのテキストと同じになってしまっています。
そこで、今回はグーグルニュースの検索結果ページの記事情報をBeautiful Soupを用いて取得するスクリプトを紹介します。
記事情報が整理されて提供されていたfeedparserと違い、検索結果のウェブページから記事情報のある場所を探して、タグや要素・属性で取り出す情報を指定する必要があります。
ここではGoogle Ghromeで取り出したい記事情報を探す方法と、得られたページ構造の情報からライブラリrequestsとBeautful Soupを用いて記事情報を取り出すスクリプトを紹介します。
1. Google Chromeによる検索結果ページでの記事情報の解析
検索ワードは今年2019年の新語・流行語大賞トップテンに選ばれた「タピる」を使いました。下図のような検索結果が表示されます。
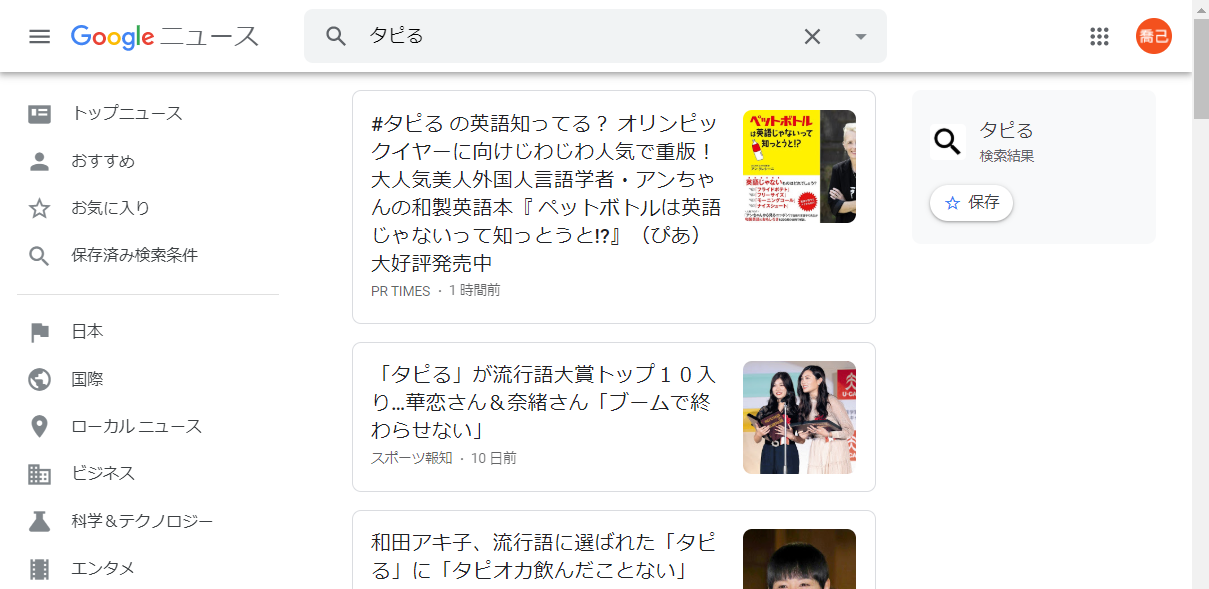
このページの構造を調べるために、カーソルを記事のタイトルに置いて右クリックで表示されたメニューの一番下の「検証」をクリックします。
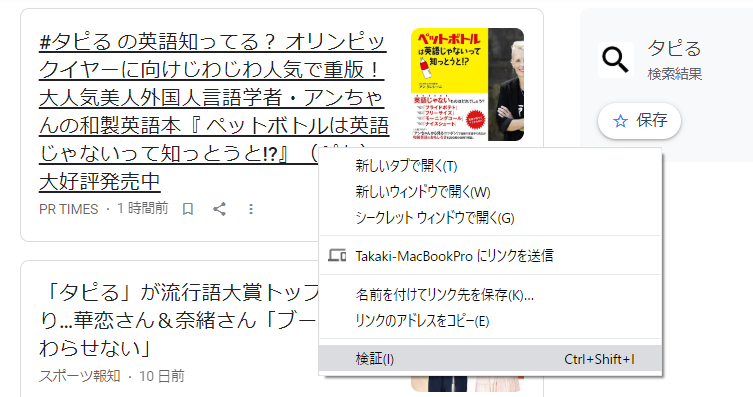
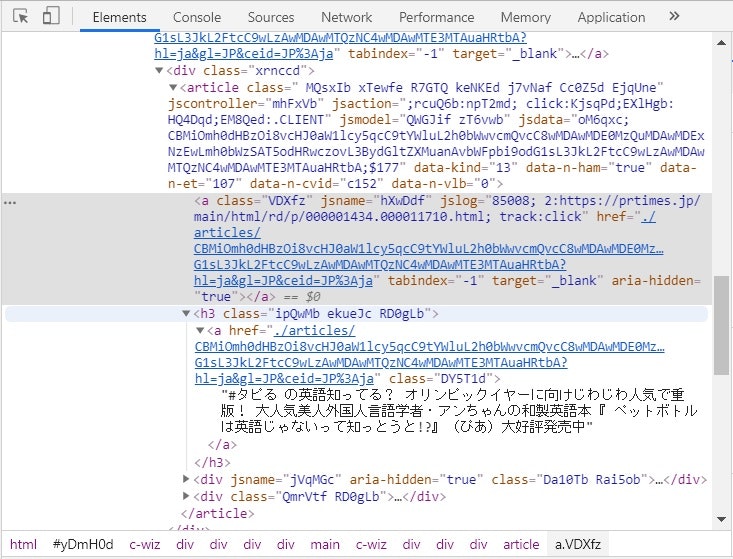
右上にHTMLページのelement構成が表示されます。このウインドウから記事情報の場所を特定して、情報の取得に必要なタグと属性などを把握します。
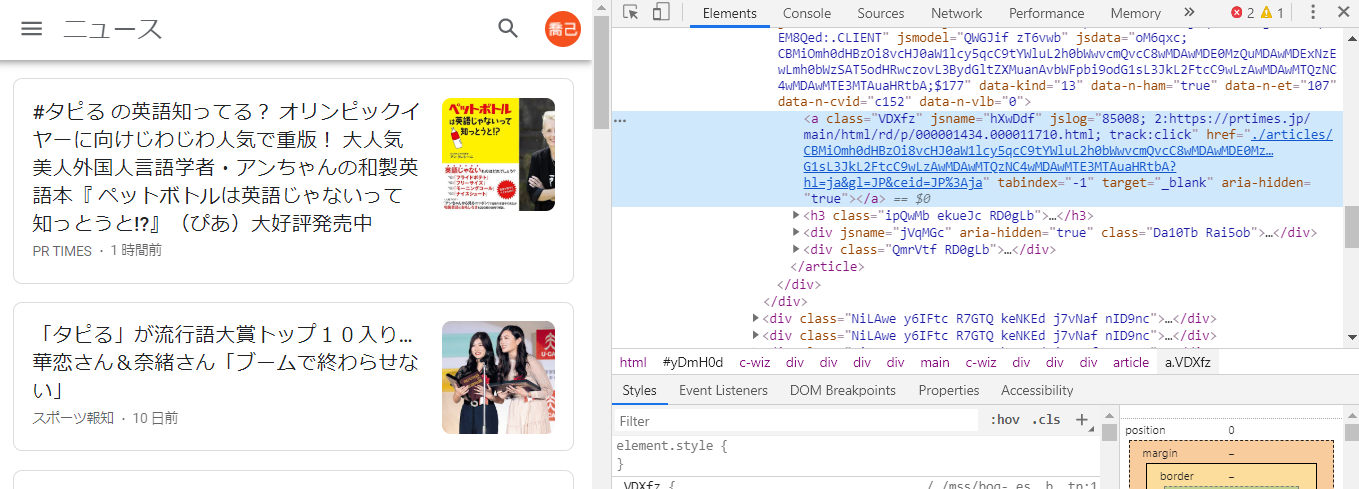
表示されたHTMLのコードを見ると、尻込みしてしまいますが、必要な情報はこの水色のゾーンの付近に必ずありますから、丹念にしつこく探すことがポイントです。
水色ゾーンのすぐ下の
の▶をクリックするとその下層が開いて、タイトルのテキスト "#タピる の英語知ってる?・・・" が表示されました。
水色ゾーンの付近に最初の記事の情報が記載されていることを確認できました。
では、この記事の情報が記載されている上位のタグを見つけるためにグレー部分の上でグルーピングタグの"div"(divタグについては文末参考を参照)を探すと、
▼<div class="xrnccd"
があります、この下層に欲しい記事情報がありそうですのでこのタグを識別するclassの"xrnccd"をbeautiful Soupのセレクターとして大雑把に100件前後の記事の情報を選びます。下記スクリプトで検索された全ての記事情報をarticlesに代入することができます。
articles = soup.select(".xrnccd")次に各記事のtitle, summary, 元記事のurl, リリース年月日が記載されている部分を探して取得します。
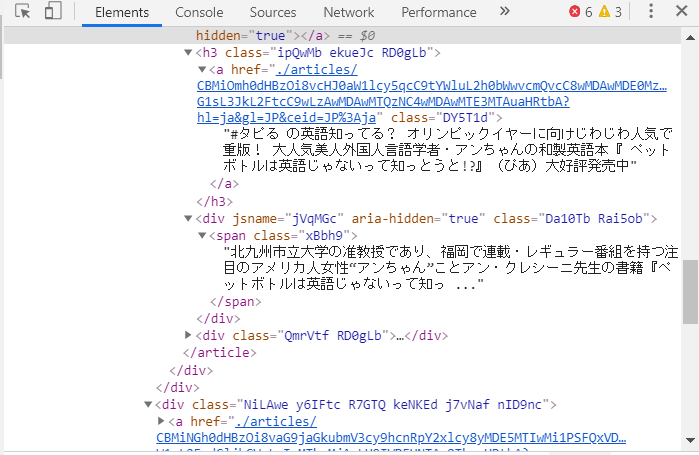
title のテキスト"#タピるの英語・・・"は水色ゾーンのすぐ下にありましたので、
それぞれの記事のオブジェクトをentryとすると
title = entry.find("h3").textsummaryは
のすぐ下の
の▶をクリックすると下層が開いて
<span class=・・・
の直下に記事の最初の数行のテキストが表示されました。検索結果のウェブページには表示されていないのですが、こんなところに隠されていました。これをsummaryとしました。
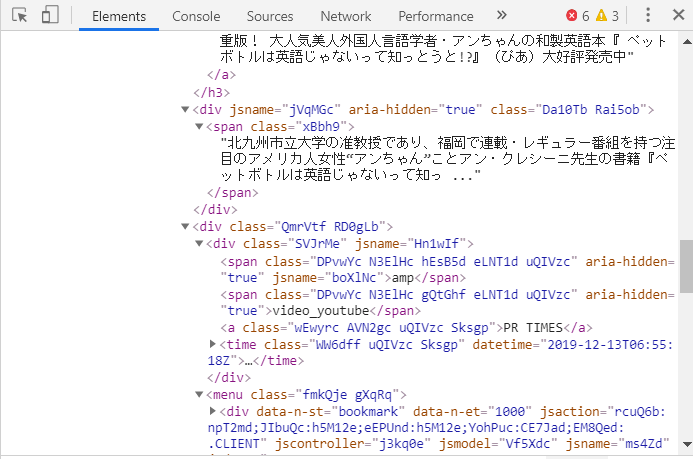
このテキストを取得するスクリプトは
summary = entry.find("span").textです。記事のリリース年月日情報はすぐ下の<div class="Qmr・・・の▶をクリックして下層を開けると"<time class= "の直下に "datetime=2019-12-13・・"がありました。
このdatetimeを取得するスクリプトは
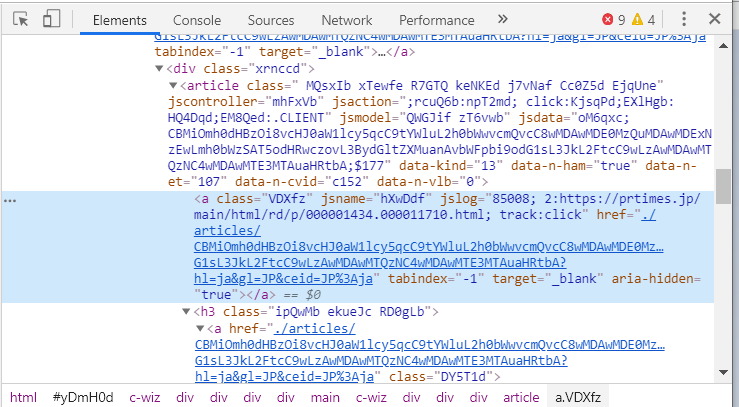
time_elm = entry.find("time")です。最後に、記事ページのurlですが、これは、検証で水色がかった部分にあります。記事のタイトルにリンク先情報が置いてあるということです。
<a class="VDXfz" jsname="hXuDdf" jslog="85008; 2:https://prtimes.jp/main/thml/rd/p/000001434.000011710.html;
のhttps://~の部分です。以下の2つのスクリプトを使いました。
url_elm = entry.find("a")
url_elm = entry.find("a", class_= "VDXfz")
url_elm = entry.find("article")
link = url_elm.get("jslog")それでは通しでスクリプトを紹介します。
取得した情報の不要な端の文字はlstrip(),rstrip()を使い削除します。
リリース年月日情報の無い場合は、例外処理で変わりに"0000-00-00"を代入しています。
取得した情報はライブラリpandasでデータフレームに変換して、csvファイルに保存します。2.グーグルニュースの検索結果のスクレイピングスクリプト
環境
Windows10
Python 3.6.2スクリプト
google_news# 必要なライブラリの呼び出し import pandas as pd #スクレイピング結果をデータフレーム形式でcvsファイルに保存するため import pprint #データフレームの一部を表示するため from bs4 import BeautifulSoup #取得したWebページの情報の解析と抽出 import requests #Webページの情報の取得 import urllib #キーワードのurlエンコード取得 # 検索ワード「タピる」を文字変換して検索結果ページのurlの間に挿入 s = "タピる" s_quote = urllib.parse.quote(s) url_b4 = 'https://news.google.com/search?q=' + s_quote + '&hl=ja&gl=JP&ceid=JP%3Aja' # 検索結果ページの情報を取得 res = requests.get(url_b4) soup = BeautifulSoup(res.content, "html.parser") # すべての記事部の情報を選択 articles = soup.select(".xrnccd") # 各記事の情報をfor ~ enumerate分で繰り返し取得してリストに代入 news = list() #代入のための空のリストを作成 for i, entry in enumerate(articles, 1): title = entry.find("h3").text summary = entry.find("span").text summary = title + "。" + summary #url_elm = entry.find("a")を下記に変更 url_elm = entry.find("article") link = url_elm.get("jslog") link = link.lstrip("85008; 2:") #左端削除 link = link.rstrip("; track:click") #右端削除 time_elm = entry.find("time") try: #例外処理 ymd = time_elm.get("datetime") except AttributeError: ymd = "0000-00-00" ymd = ymd[0:10] ymd = ymd.replace("-", "/") #置換 sortkey = ymd[0:4] + ymd[5:7] + ymd[8:10] #年月日でのソート用 tmp = { #辞書型で格納 "title": title, "summary": summary, "link": link, "published": ymd, "sortkey": sortkey } news.append(tmp) #各記事の情報をリストに追加 #データフレームに変換してcsvファイルで保存 news_df = pd.DataFrame(news) pprint.pprint(news_df.head()) #最初の5行を表示してデータ確認 filename = s + ".csv" news_df.to_csv(filename, encoding='utf-8-sig', index=False)グーグルニュース検索のスクリプトは以下の記事に利用しています。
データサイエンスで食のヒットの種を見つけだそう! (1) - ローソンのバスチー ヒットの秘密
食のヒットの種を見つけだそう! (2) - 2019年6月~8月は「完全食」と「天気の子レシピ」
食のヒットの種を見つけだそう! (3) - 2019年9月はタピオカティーに続く台湾発の食 、特に「チーズティー」
食のヒットの種を見つけだそう! - 2019年10月はスイートポテトパイ
参考: