グーグルニュースは関心があるキーワードや文章で検索すると、関連度順とリリース日時順で整理して100件の記事を表示してくれます。
食品のヒット商品出現の経緯を探るために、ヒットした食品に関係しそうなキーワードや文章で検索して過去のニュースを調査して、それらのニュースリリース時の関心の上昇度をグーグルトレンドで確認することで、ヒットに至る経緯を探ることができそうです。
今春にローソンから発売された「バスチー」は発売後4か月で1,900万個売れた大ヒット商品となりました。そこで、「バスチー」の由来となった「バスクチーズケーキ」でグーグルニュースをプログラムで自動的に検索、編集してデータ化することを検討しました。

こちらも参照ください。
データサイエンスで食のヒットの種を見つけ出そう(1) ーローソン バスチー ヒットの秘密 ー
これまで、Rをベースに統計解析用にプログラミングをしてきましたが、ウェブ情報の取得や機械学習を広く利用する場合にはPythonを使い始めています。 Rでグーグルニュースのウェブページをスクレイピングしていましたが、PythonでグーグルニュースのRSSをパースする方法を知りこちらを使うようになりました。
グーグルニュースをキーワードで自動的にPythonで取得して、Rで集計するプログラムを紹介します。
Pythonのコーディングは下記の記事を参考にしました。とても丁寧で分かり易く書かれています。
【Python】Googleニュースをスクレイピングする
注) 今年2019年10月頃からfeedparserからの情報取得ではsummaryとtitleのテキストが同じになってしまっていますので、検索結果ページから直接スクレイピングするスクリプトを投稿しましたので、こちらもご覧ください。
Pythonでグーグルニュースの検索結果をスクレイピング (2) Beautiful Soupを使う
環境
Windows10
Python3.6.5
R3.6.1
Pythonでグーグルニュースを取得
グーグルニュースの情報取得のためにfeedparserをコマンドプロンプトでpipを用いてインストール
$ pip install feedparser
ライブラリのインポート
import feedparser
import urllib
import json
import pprint
グーグルニュースを検索ワードで検索するためのURLを作成する。
今回は検索ワードは今春に発売されて大ヒットしたローソンの「バスチー」の元となった「バスクチーズケーキ」にします。
s = 'バスクチーズケーキ'
# 検索ワードをURLエンコードに変換
s_quote = urllib.parse.quote(s)
# グーグルニュース検索のURLの間に挟む
url = "https://news.google.com/news/rss/search/section/q/" + s_quote + "/" + s_quote + "?ned=jp&hl=ja&gl=JP"
urlをfeedparserでパースする
d = feedparser.parse(url)
news = list()
ニュース記事リストを、for文で繰り返し各記事のtitle、summary, link, published,sortkeyを取得
for i, entry in enumerate(d.entries, 1):
p = entry.published_parsed
sortkey = "%04d%02d%02d%02d%02d%02d" % (p.tm_year, p.tm_mon, p.tm_mday, p.tm_hour, p.tm_min, p.tm_sec)
tmp = {
"no": i,
"title": entry.title,
"summary": entry.summary,
"link": entry.link,
"published": entry.published,
"sortkey": sortkey
}
news.append(tmp)
取得したニュースの最初の2件を表示してみる
pprint.pprint(news[0:2])
以下の実行結果が表示されました。
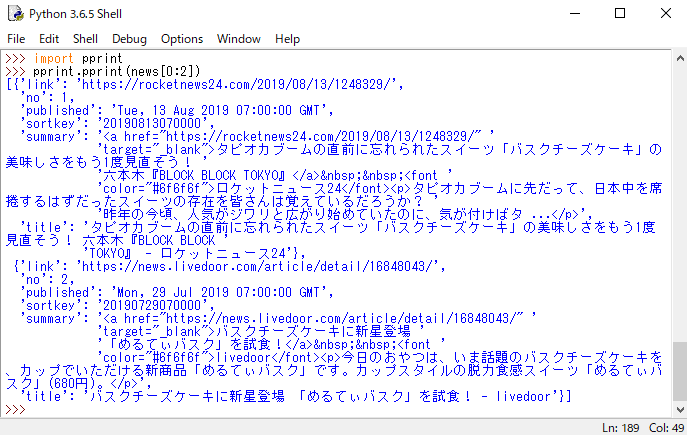
項目のsummaryに'<a href="http://・・"とニュースのリンク先が記載されているので、これを削除したり、項目の順番を変えたり、日時順にソートするために、手慣れているRにデータを渡します。
json形式で保存
PythonからRへのデータの受け渡しにはjson形式のファイルを使うと簡単で便利です。
with open('news.json', 'w') as f:
json.dump(news, f)
Rでjsonファイルをcsvファイルに変換
パッケージのインストール
install.packages("jsonlite") #json形式のデータを扱う
install.packages("formattable") #データフレームをHTMLに表示
パッケージを読み込む
library(jsonlite)
library(formattable)
json形式のファイルを読み込んで、データを編集
news <- fromJSON("news.json")
項目summaryから不要な文字を除きます。
項目summaryには、ニュースのリンク先のURL他のHTML由来の不要な文字が含まれているのでこれをgsub()を使って除きます。
(rownum <- nrow(news)) #次のfor文設定のためにニュース件数を代入
for (i in 1:rownum){
dev <- strsplit(news[i, 3], ">") #分割
dev.c <- dev[[1]]
summary <- paste(dev.c[2], dev.c[6]) #必要な文章を結合
summary <- gsub("</a", "。", summary) # "</a"を除く
summary <- gsub("</p", "。", summary) # "</p"を除く
news[i, 3] <- summary #修正した文章を戻す
}
リリース日時でニュースを降順にソート
項目sortkeyを使います
sortlist <- order(news$sortkey, decreasing=TRUE)
news.sort <- news[sortlist,]
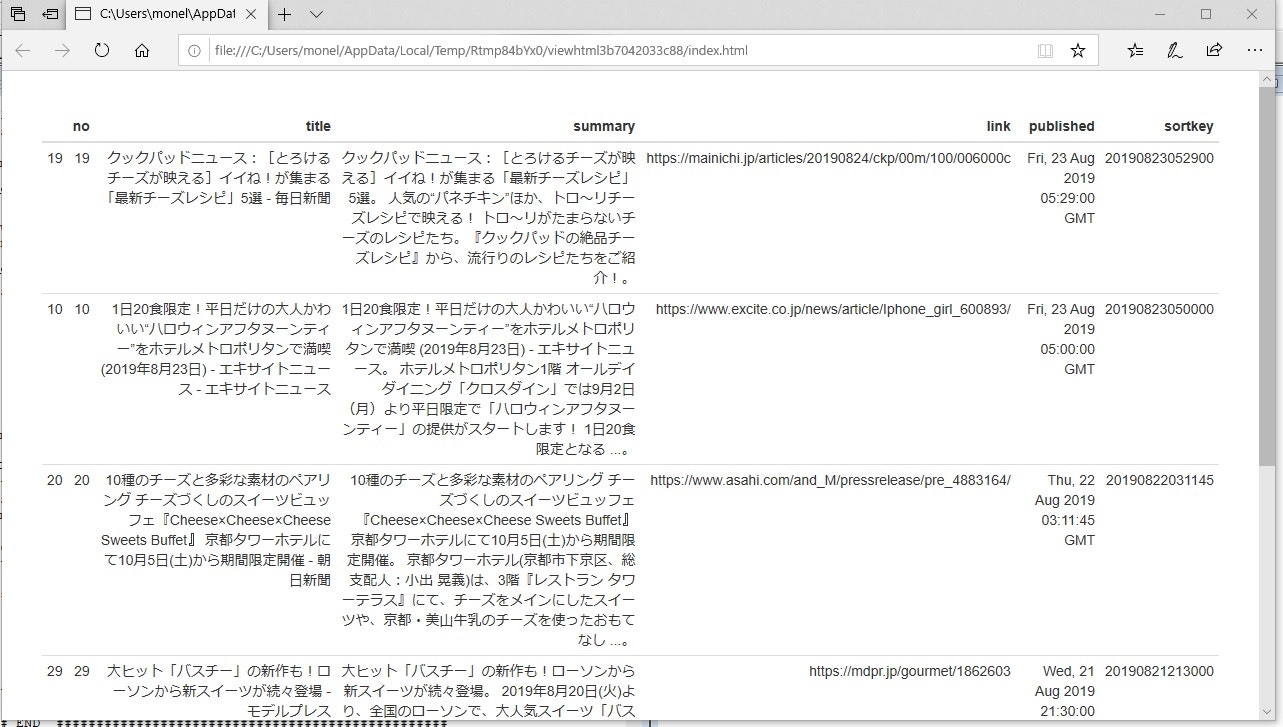
初めの6件のニュースをHTMLに表示
formattable::formattable(head(news.sort))
実行結果
csvファイルで保存
## csvファイルで保存
write.csv(news.sort, "バスクチーズケーキのグーグルニュース.csv")
以上
ある期間に絞りたいときも、同じくsortkeyを使えばできます。