【 Azure Databricks ETL編 その2 】
概要
Azure Databricks を使ってみよう! ということで、以下の3ステップで簡単に說明します。
- 【環境準備編】:Azure CLI から Azure Databricks 環境を作成します
- 【抽出変換編】:Databricks から ADLS Gen2 のデータを抽出し、変換します
- 【格納編】:Databricks で ETL されたデータを ADLS Gen2 に格納します

今回は 【抽出変換編】の說明となります。Databricks の Notebook を使用していきます。
- Azure Databricks
- Cluster 作成
- Notebook 作成
- NoteBook 実装
- Blob コンテナのマウント
- Blob からのデータ抽出
- データ変換
- クエリ実行
ローカル環境
- macOS Big Sur 11.3
- python 3.8.3
- Azure CLI 2.28.0
前提条件
- Azure環境がすでに用意されていること(テナント/サブスクリプション)。
- ローカル環境に「azure cli」がインストールされていること。
- Azure Databricks の環境が準備できていること - 前ステップが完了していること
Azure Databricks を使ってみます
この記事 にある「Azure Databricks で Spark クラスターを作成する」ところらへんを参考にしてすすめます
Spark クラスタの作成
-
Azure portal で、前ステップで作成した Databricks サービスに移動し、「ワークスペースの起動」 を選択します
-
Azure Databricks ポータルにリダイレクトされます。 ポータルで [New Cluster] を選択します
-
以下のパラメータでクラスターを作成します
項目 値 Cluster Name db_ituru_cluster01 Cluster Mode Single Node Databrickes Runtime Version 8.3 (includes Apache Spark 3.1.1, Scala 2.12) AutoPilotOprions Terminate after 45 minutes of inactivity Node Type Standard_DS3_v2 (14GB Memory 4Cores) -
パラメータ入力後、「Create Cluster」ボタンを押します。クラスターが作成され、起動します

Notebook の作成
-
Azure Databricks ポータルで [New Notebook] を選択します
-
以下のパラメータで NoteBook を作成します
項目 値 Name ETL_UsageCost_01 Default Language Python Cluster db_ituru_cluster01 -
パラメータ入力後、「Create」ボタンを押します。新規の Notebook 画面が表示されます。

Notebook の実装
この記事 の内容をほぼそのまま活用させていただきました。
Blobコンテナーのマウント
cmd_1
# コンテナーのマウント
# 一度マウントすると、Clusterを停止、変更してもマウント状態が維持されます
# マウントされた状態で再度操作を実行するとエラーが発生するため、マウント状態をチェックする
# Blob Storage情報(データ抽出用)
storage = {
"account": "testaccount",
"container": "cost-data",
"key": "xxxxxxxxxxxxxxxxxxxxxxxxxxxx"
}
# マウント先DBFSディレクトリ(データ抽出用)
mount_point = "/mnt/blob-data"
try:
# マウント状態のチェック
mount_dir = mount_point
if mount_dir[-1] == "/":
mount_dir = mount_dir[:-1]
if len(list(filter(lambda x: x.mountPoint == mount_dir, dbutils.fs.mounts()))) > 0:
print("Already mounted.")
mounted = True
else:
mounted = False
# Blob Storageのマウント
if not mounted:
source = "wasbs://{container}@{account}.blob.core.windows.net".format(**storage)
conf_key = "fs.azure.account.key.{account}.blob.core.windows.net".format(**storage)
mounted = dbutils.fs.mount(
source=source,
mount_point = mount_point,
extra_configs = {conf_key: storage["key"]}
)
except Exception as e:
raise e
"mounted: {}".format(mounted)

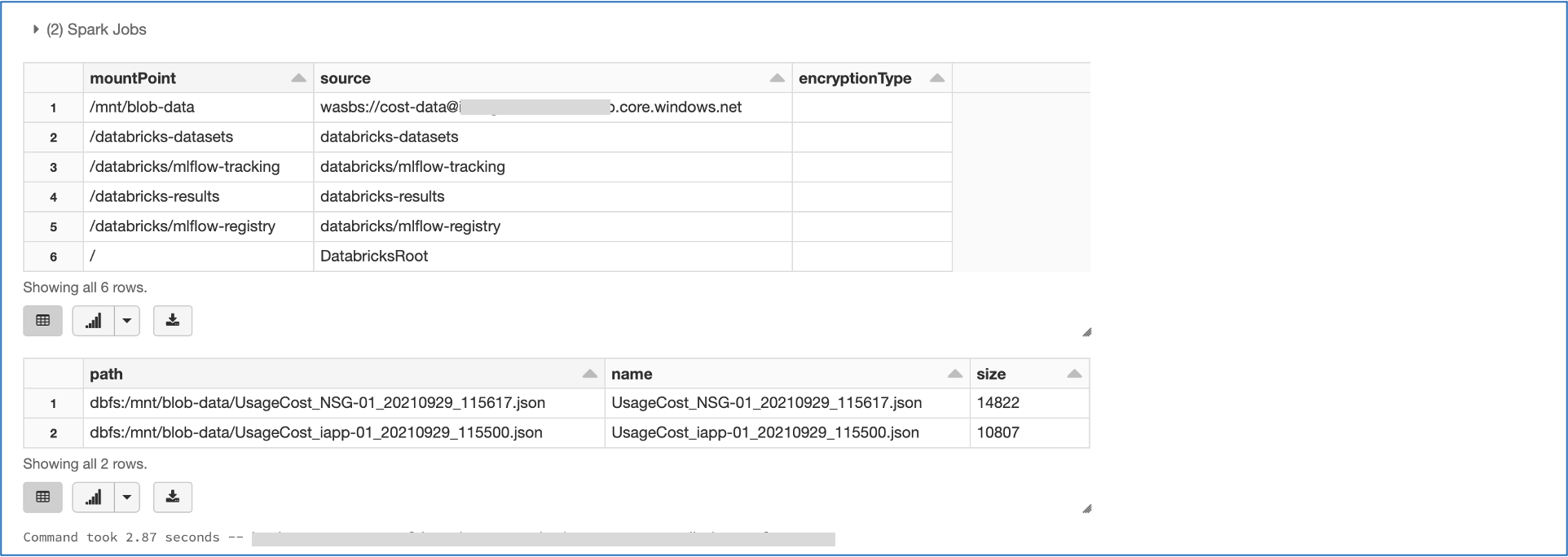
Blob Storageをマウントした ディレクトリ と ファイル の確認
cmd_2
# ディレクトリの確認
display(dbutils.fs.mounts())
# ファイルの確認(ファイルが存在しないとエラーが発生)
# mount_point = "/mnt/{マウント先ディレクトリ}"
display(dbutils.fs.ls(mount_point))
そのファイルの読込(データの抽出)
cmd_3
# Blob から 対象ファイルの読込 --> PySpark Dataframes 型式
# (読み込むファイルの指定をワイルドカードにすると、複数ファイル同時に扱えます)
sdf = spark.read\
.option("multiline", "true").option("header", "false").option("inferSchema", "false")\
.json('/mnt/blob-data/UsageCost_*.json')
display(sdf)

読み込んだデータの変換
cmd_4
import pandas as pd
import datetime
# PySpark Dataframes から Pandas への変換
pdf = sdf.toPandas()
# カラム:Data の型を long型 から datetime型 にデータ変換する
# (クエリ処理で、Dateを範囲指定(Betweem)で行いたいため)
pdf['Date'] = pd.to_datetime(pdf['Date'].astype(str), format='%Y-%m-%d')
# Pandas から PySpark Dataframes への変換
df = spark.createDataFrame(pdf)
display(df)

データのテーブル化
cmd_5
# クエリとして扱うときのテーブルを作成
df.createOrReplaceTempView("tbl_cost01")
クエリの実行
ベタなSQLで、Data=2021-08-15 のデータを取得する
cmd_6_例-1
%sql
SELECT *
From tbl_cost01
Where tbl_cost01.Date='2021-08-15'

cmd_7_例-2
# Data が 2021-08-01 から 2021-03-03 間のデータを取得する
query_02 = """
SELECT *
From tbl_cost01
WHERE tbl_cost01.Date BETWEEN '2021-08-21' AND '2021-08-22'
"""
display(spark.sql(query_02))

cmd_8_例-3
# 日付毎に集計をとり日付の新しい順に取得する
query_03 = """
SELECT tbl_cost01.Date, sum(tbl_cost01.UsageCost) as CostSummary
From tbl_cost01
Group by tbl_cost01.Date
Order by tbl_cost01.Date DESC
"""
display(spark.sql(query_03))

まとめ
Azure Databricksを使うとBlobのなかに貯めていたデータも簡単に分析できるようになるようです
参考記事
以下の記事を参考にさせていただきました。感謝申し上げます
Azure Databricks: 3-1. DBFSにBlob Storageをマウント