概要
個人を特定できるデータをそのまま公開するわけにはいかないので、その個人毎にユニークなランダム文字列(UUID利用)を付与することにより、データ処理できるようにする方法となります。
ローカル環境
- macOS Monterey 12.1
- python 3.8.3
- Azure CLI 2.28.0
前提条件
- Azure環境がすでに用意されていること(テナント/サブスクリプション)
- ローカル環境に「azure cli」がインストールされていること
- Azure Databricks の Workspace 上で Notebook が稼働できていること。
事前準備
データファイルのアップロード
- 対象の Workspace の Azure Databricks ポータルで [Import & Explorer Data] を選択します
- 「Drop files to upload, or click to browse」に対象のファイルをドラッグ&ドロップします
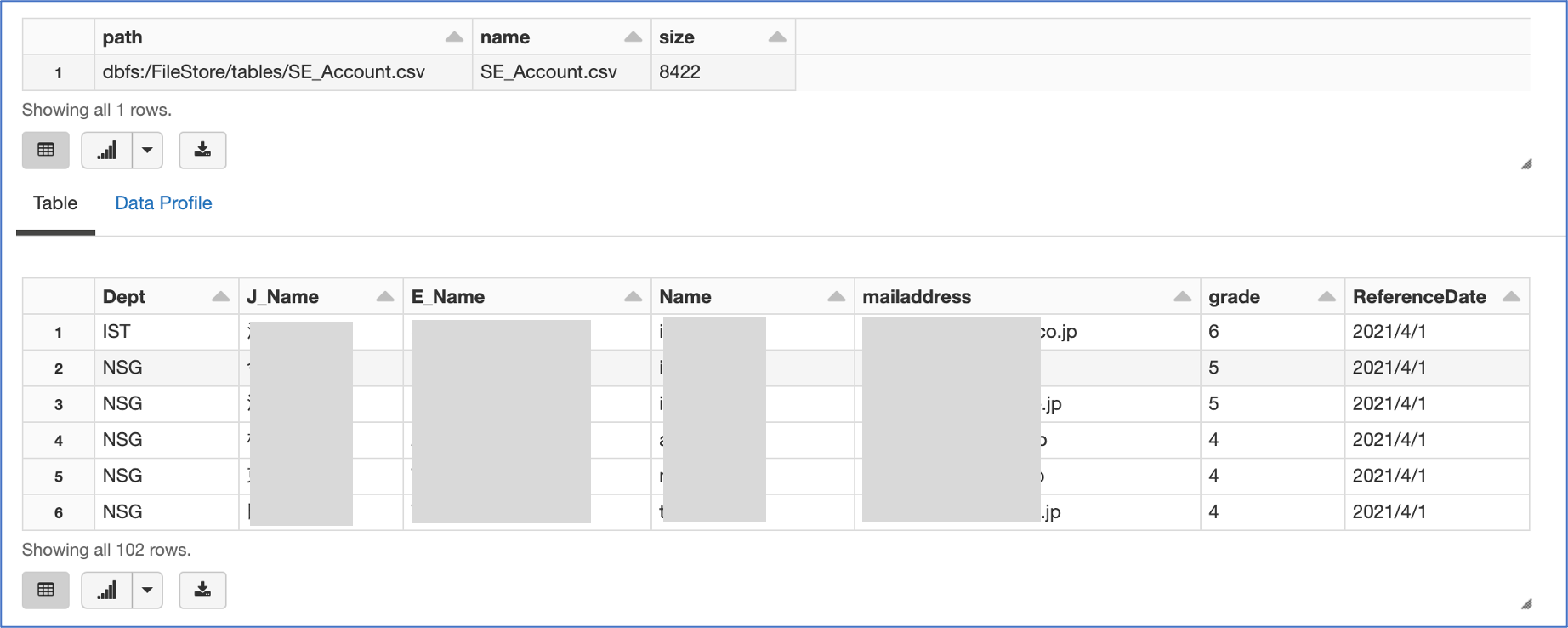
- 「DBFS」タブを選択し、「FileStore - tables」フォルダ配下にドロップしたファイル(SE_Account.csv)を確認することができます
Notebook の実装
対象ファイルの読込(データの抽出)
cmd_1
# 対象データの確認
display(dbutils.fs.ls("/FileStore/tables/"))
# csv型式のデータファイルをDataFrameとして読取る
sdf = spark.read.csv('/FileStore/tables/SE_Account.csv', header='true', inferSchema='true', encoding='utf-8')
display(sdf)
SE毎にユニークなUUIDの付与
cmd_2
import uuid
# PySpark Dataframes から Pandas への変換
pdf = sdf.toPandas()
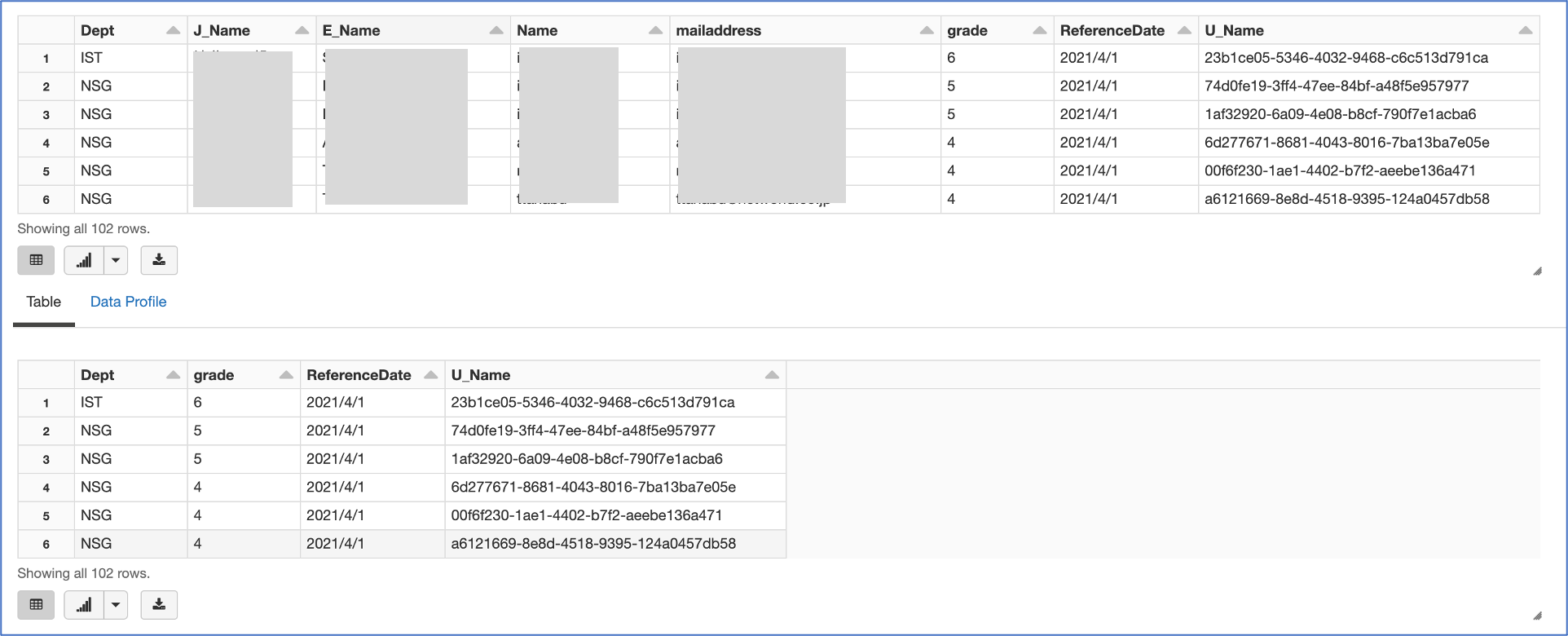
# カラム['U_Name']を新規作成し、UUIDを割り当てる
pdf['U_Name'] = [str(uuid.uuid4()) for x in range(len(pdf))]
display(pdf)
# 不必要なカラムの削除後、Pandas から PySpark Dataframes への変換
df = spark.createDataFrame(pdf.drop(['J_Name', 'E_Name', 'Name', 'mailaddress'], axis = 1))
display(df)
まとめ
データ分析を実施するにあたり、データの匿名性が大事ということに気が付き、今回の記事を記載。ただ、かなり社内よりの内容なので、忘備録のような扱いになってしまいました、、、、、
参考記事
以下の記事を参考にさせていただきました。感謝申し上げます
pandas DataFrameの新しい列にuuidを追加します
Python Random Module: Generate Random Numbers and Data