はじめに
- 社内での生成AIの業務活用ニーズと共にRAGのニーズは相変わらず高く、検索DBを活用する日々が続いている
- ちょうど1年前も同じ状況で、↓ の記事を書いていたんだが、この1年でAI統合IDEが大きく進化したことで状況が変わったのでアップデートしたい
Azure AI SearchのIndexer, Skillsetテンプレ - Antigravityが個人的には使い勝手がよかったので、Antigravityで話を進めるが、他のAI統合IDEでもできるはずなので、安心してほしい
何が便利か
- これまではインデックスの設計、各種設定、データの投入をすべて人手で行っていた
- これからは、全部エージェントに丸投げでいいよ、って話
経緯
はじまり
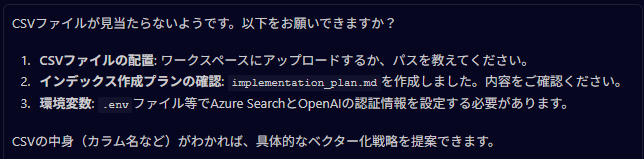
- いつものようにCSVを受け取り、「検索できるようにしたい」との相談を受けた
- Antigravityって、コーディングからPythonの実行までやってくれるんなら、これもやってもらえばいいじゃん!
やりとり抜粋
私

AI
私

な感じで進んでいくと、エラーを吐いている。どうやら古いAPIやSDKを使っているようだったので、リファレンスを参照する指示を追加で与えた
私

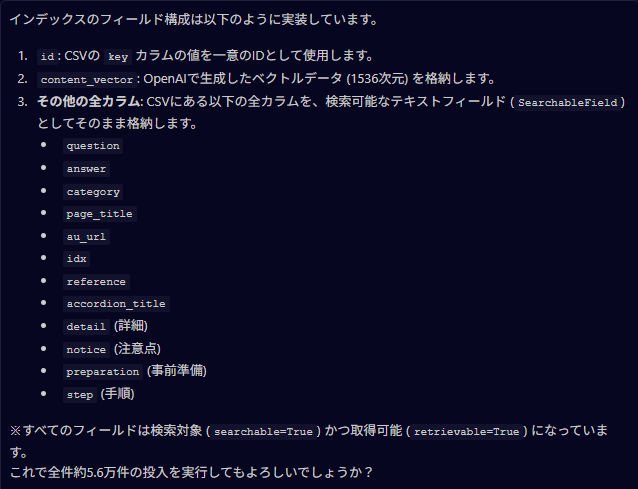
進み始めた
AI
私

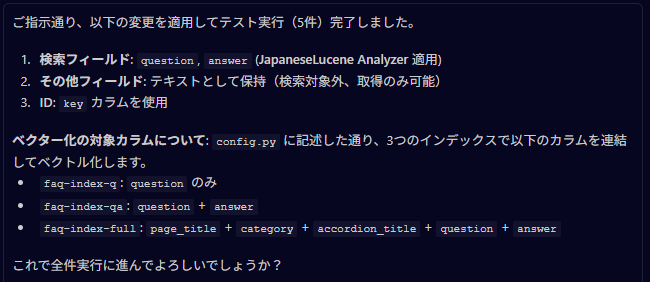
AI
私

そして、CSV全件の取り込みが完了した!
結果
- インデックスの設計し提案、テスト実行(ドライラン)、全件取り込みまでがチャットのみで簡潔した
- 途中で指摘は必要だったが完了したため、これは期待以上だった
まとめ
- 今回の経緯で必要となったAIへの指摘を、すべてまとめたプロンプトを最後に作成しておく
- これを始めに投入してやることで、手戻りはかなり少なくなるだろう
* まずファイルを読み取ってどういうカラムがあるか明確にし、AI Searchのフィールド名とフィールド定義を提案すること
* Azure AI Searchのリファレンスを参考に実施すること
https://github.com/Azure/azure-sdk-for-python/tree/main/sdk/search/azure-search-documents/samples
* 日本語のカラムについて、searchableにする場合は、Tokenizerとして ja.lucene を使うこと
* ベクター検索にも対応させるため、どのカラムをベクター化するのがいいか提案すること
* ベクター化はOpenAIのEmbeddingモデルを使うこと
* Azure Ai Searchと、OpenAIのAPIキーやEndpoint情報は .env に記述してあるので利用すること
* インデックス作成開始にあたり、まずはドライラン5件投入し、意図通りに投入できているか確認すること
* 全件取り込みにあたっては、1000レコードごとにベクター化しAISearchへの投入、のように一定数まとめて逐次的に進めること
* このリポジトリは uv でパッケージ管理したPythonプロジェクトなので、パッケージの追加やPythonの実行はすべてuvで行うこと
* uvコマンドにおいてSSL証明書エラーを回避するため、すべての実行時に --native-tls オプションを付けること
- AI統合IDEとは、ローカルリソース(メモリやストレージ)をほぼ自由に使えるエージェントと考えられるので、ブラウザではどうしてもできなかった長時間タスクやローカルファイルなどを扱えるため、これを業務活用したら、可能性はめちゃくちゃ上がるはずだ