はじめに
- Azure OpenAIを利用してRAGをやるときに、Azure AI Searchを利用される方は多いと思いますが、DBにデータを取り込むIndexerやSkillsetを利用しようとすると、すべての人がハマると思うので、この記事に沿ってやれば即使える、というテンプレを書きたいと思います
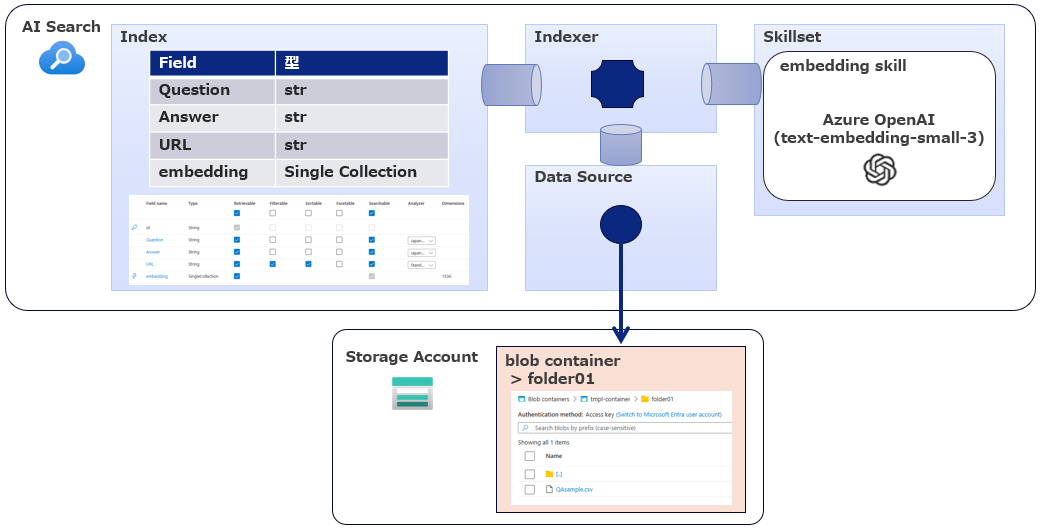
今回作る構成
- BlobにCSVデータを格納してIndexerを実行したら、Answer列の情報がベクター化されてDBに格納されます
- Q&A形式のCSVですが汎用性高く、いろいろな場面に適用できると思います
テンプレ解説
csv データ形式
- FAQや、特定のトピックに関する情報を想定し、以下の形式をテンプレとして扱います
- これをCSVとして保存しましょう
- 文字コードはUTF-8必須なので注意すること
| Question | Answer | URL |
|---|---|---|
| 営業時間は何時から何時までですか? | 当店は午前9時から午後9時まで営業しております。 | https://example.com/hours |
| メニューにビーガン対応の料理はありますか? | はい、ビーガン対応の料理としてサラダやビーガンパスタをご用意しています。 | https://example.com/vegan-menu |
| Wi-Fiは利用できますか? | はい、無料Wi-Fiをご利用いただけます。店内でパスワードをご確認ください。 | https://example.com/wifi |
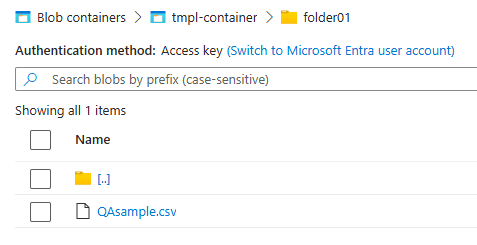
Azure blobに格納
- Azure blobを作成したら、適当にフォルダを作って格納しよう
Azure AI Search
- 以下の順に作っていきます
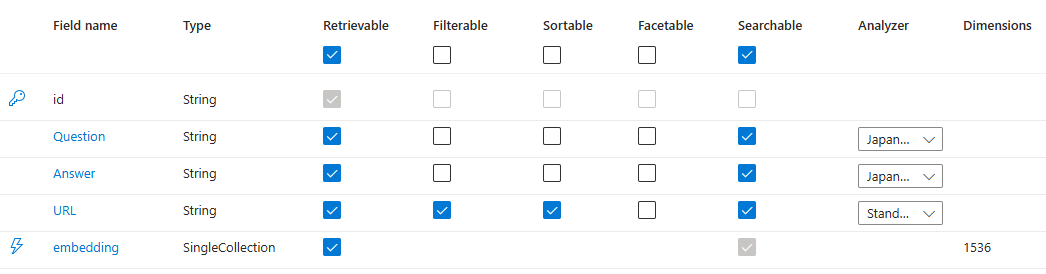
Index
- 今回のCSVのタイトルと、フィールド名は、しっかりと合わせます
- URL行は、ソートやフィルタもできるようにチェックつけてますが、そこはお好みで
- ベクター用にembeddingというフィールドも作ること
- embedding というフィールド名はSkillsetでも利用するので、もし変更する場合は、Skillset作成の際に留意すること!
データソース
- 先ほど作ったBlobのフォルダをしっかり指定しよう

Skillset
- Skillsetを作成しようとすると、いきなりJSONの記入を求められて、大抵ここで途方にくれます
- なので、即貼り付けて使えるテンプレを共有します!JSONを以下のテンプレに置き換えて、以下3点だけ気を付けて保存しよう
- 事前にAzure OpenAIインスタンスは作成し、text-embedding-small-3 のモデルデプロイも終わっているものとします
- xxxxxxxの箇所は、自分のOpenAIの情報に書き換えること
- inputsのAnswerは、CSVのタイトルと合わせること!本テンプレでは、Answer列をベクター化します
{
"name": "embedding-skill",
"description": "",
"skills": [
{
"@odata.type": "#Microsoft.Skills.Text.AzureOpenAIEmbeddingSkill",
"name": "#1",
"description": "Connects a deployed embedding model.",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/Answer",
"inputs": []
}
],
"outputs": [
{
"name": "embedding",
"targetName": "embedding"
}
],
"resourceUri": "https://xxxxxxxxxxxxxxxxxxxxxxxxxxxx.openai.azure.com",
"deploymentId": "text-embedding-3-small",
"apiKey": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"modelName": "text-embedding-3-small",
"dimensions": 1536
}
]
}
Indexer
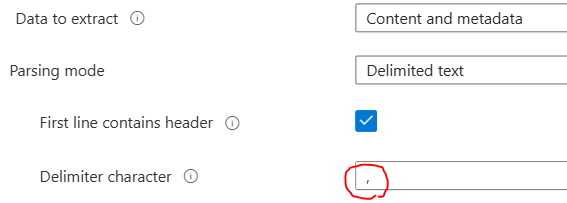
- 設定するIndexやデータソース、Skillsetは上記で作成したものを指定するだけなので、迷いはないはず
- 注意点はCSVに合わせた以下4項目だけ
- デリミタには、カンマ( , )をちゃんと設定しましょう
- そして、JSONでの編集ボタンから、以下のように、ベクターデータのフィールドを追記します
GUIだけで設定できると思わせて、JSON編集必須とは、なんてこった!
"outputFieldMappings": [
],
↓
"outputFieldMappings": [
{
"sourceFieldName": "/document/embedding",
"targetFieldName": "embedding",
"mappingFunction": null
}
],
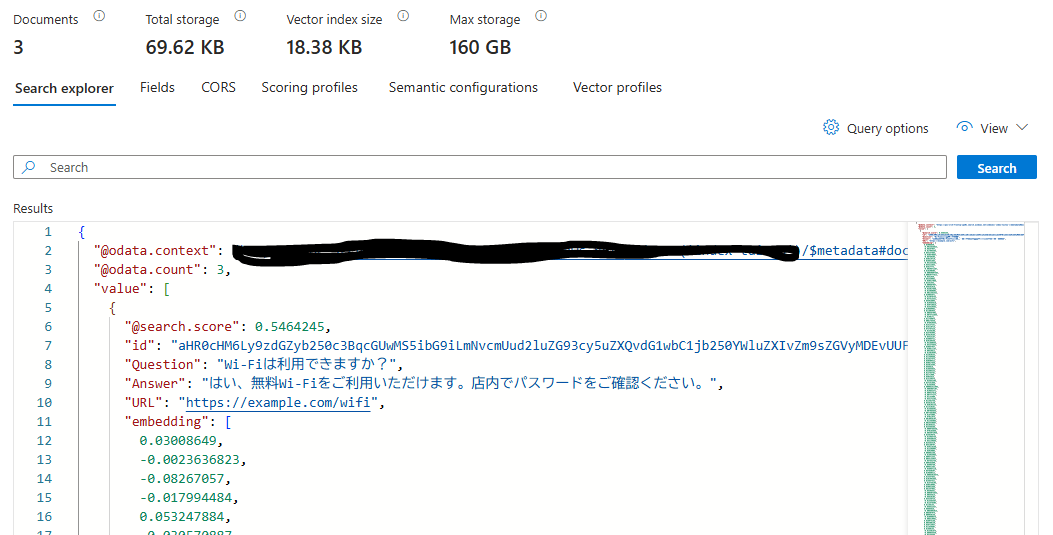
Indexerを動かしてデータを取り込む!

- データの様子
おわりに
- このテンプレを利用して、AI Searchのハッピーライフを過ごしていただければと思います