IBM Cloud Paks Advent Calendar 2021 7日目です!
Cloud Pakで皆さんとかぶらないようなネタは何か無いものか考えたのですが、なかなか浮かばないものです。
過去の業務経験からネタを出すことにしました。
というわけで、IBM Cloud Pak for Dataでも使える位置情報データを作ります。
#データどうしよう問題
データサイエンスする際に困るのが、「データどうしよう」問題です。
さぁ分析しよう!と盛り上がったはいいものの、
- お客様や関係部署からデータを貰うために調整・申請・承認作業が必要、すぐには貰えない…
- デモやハンズオンなどでデータを作らざるを得ない…
なんてことから結局自前でデータを用意するシーン、ありますよね。
(IBM Cloud Pak for DataのData Virtualizationならそれをだいぶ解決してくれます。
でも、そういう便利機能があっても相手は人間なので多少は用意することもあるよねきっと。ということで。)
その場合、「どんなテストデータをどう作ればいいんだろう?」と考えるのはもちろんですが、特に、IoTや緯度経度が含まれるようなデータ作成は情報が少なかったり用語が多かったりして分かりづらいと思います。
今回は、そんなシーンを想定しPythonを使って位置情報データを作成する方法をざっくりご紹介します。
#位置情報テストデータを生成しよう
##どんなデータを作りましょうか
今回は、千葉県南房総市を対象に、住民が持つスマホの現在位置を擬似的に生成してみます。
具体的には、建築物と国勢調査データを使い、字ごとに、建築物の中にランダムに人口の数だけポイントを生成します。
##準備
###データを探す・ダウンロードする
ゼロからデータを作るのは難しいです。
まずは、国から提供されているデータを利用できるか検討しましょう。
- 国土地理院 基盤地図情報 - https://www.gsi.go.jp/kiban/
- 国土交通省 国土数値情報 - https://nlftp.mlit.go.jp/ksj/index.html
- 総務省 e-Stat 政府統計の総合窓口 - https://www.e-stat.go.jp/
(予算があれば、企業から購入することも可能です。様々な企業が様々なデータを有償で提供しています。)
今回は、国土地理院 基盤地図情報と総務省 e-Stat 政府統計の総合窓口からデータをダウンロードします。
基盤地図情報データは特殊な形式であるため、基盤地図情報ビューアで変換が必要です。
基盤地図情報ビューア:https://fgd.gsi.go.jp/otherdata/tool/FGDV.zip
このビューアはWindows実行形式(exe)しか無いので、MacやLinuxユーザの方はWindowsユーザに相談しましょう。
####基盤地図情報のダウンロード
-
国土地理院 基盤地図情報にアクセスします。

-
画面中段の「基盤地図情報 基本項目」枠にある「ファイル選択へ」をクリックします。

-
「選択方法指定」>「都道府県または市区町村で選択▼」で「千葉県」「南房総市」を選択肢、「選択リストに追加」します。
-
地図上で南房総市を囲う形で矩形がいくつか選択されていることを確認し、左下の「ダウンロードファイル確認へ」をクリックします。

-
「全てチェック」「まとめてダウンロード」をクリックします。

-
ログイン画面が表示されます。画面に従ってユーザ登録し、ログインを済ませてください。(こちら参照)

-
データのダウンロードが始まります。
-
データのダウンロードが終わりましたら、続けて基盤地図情報ビューアをダウンロードしておいてください。
####国勢調査データのダウンロード
-
総務省 e-Stat 政府統計の総合窓口にアクセスします。
-
「地図」をクリックします。

-
一番下の、「>境界データダウンロード」をクリックします。
-
以下の順番でデータを選択していきます。最後だけ右側のアイコンをクリックしてください。ダウンロードできればOKです。
- 小地域
- 国勢調査
- 2015年
- 小地域(町丁・字等別)(JGD2000)
- 世界測地系緯度経度・Shapefile
- 千葉県
- 12234 南房総市

ダウンロードしたファイルをzip展開すると、Shapeファイルと呼ばれるファイルを確認することができます。
Shapeファイルとは、ESRI社が策定したデータフォーマットで、shp/dbfなど複数のファイルから構成されています。
図形情報、属性情報、座標系、空間インデックスなどが定義された相当に古い種類のフォーマット![]() なのですが、未だに位置情報データフォーマットのデファクト・スタンダードとして多く利用されています。
なのですが、未だに位置情報データフォーマットのデファクト・スタンダードとして多く利用されています。
https://www.esrij.com/gis-guide/esri-dataformat/shapefile/
###データの加工
####建築物(基盤地図情報)
- ダウンロードした基盤地図情報ビューアをzip展開>起動します。(ダウンロードしてない人はこちらから)
- ダウンロードした基盤地図情報をzip展開します。FG-GML-***.zipというファイルが10個程度できたはずです。
- メニューから「新規」をクリックし、FG-GML-***.zipというファイルをすべて選択します。

- メニューバー>エクスポート>エクスポート を選択します。

- エクスポートを実行します。その際、以下の設定を行ってください。
- 「変換する要素」で、「建築物[BldA]」のみ選択してください。(他の要素を選択した場合、その分処理に時間がかかります)
- 「直角座標系に変換」チェックボックスを外してください。(緯度経度データが出力されます)

Shapeファイルがエクスポートされました。

###データの確認
Shapeファイルを確認する場合、専用のツールを使うのが簡単です。
QGISというデスクトップアプリケーションがOSSとして公開されていますので、そちらをダウンロードして利用します。
https://qgis.org/ja/site/forusers/download.html
(Macの場合、brew install --cask qgisでもOK)
インストール後、起動して「h27ka12234.shp」「20210101-建築物.shp」の2ファイルをWindowsエクスプローラやMac Finderからアプリ上にドラッグドロップします。(拡張子がshpのファイルのみをドラッグドロップしてください)
下記のような房総半島の南端が表示されればOKです。(色はランダムな色が自動で割り当てられます)
赤い枠は南房総市の大字を、黒い点のようなものは建物を示しています。
建物は南房総市を囲う範囲でデータをダウンロードしたため、館山市などのデータも入ってしまっています。

ようやくデータの下準備ができました。
##pythonによるデータ生成
###ツール
pythonで位置情報を触る時は、まず以下のライブラリを検索、調査しましょう。
それぞれできること/できないことがあるので用途にあわせて使い分けが必要です。
| ライブラリ名 | 説明 | URL |
|---|---|---|
| geopandas | pandasの位置情報扱える版。使い勝手は良く、内部でshapelやfionaを使っている。 | https://geopandas.org/en/stable/# |
| shapely | ジオメトリ(図形)の操作および分析のためのライブラリ。 | https://shapely.readthedocs.io/en/stable/manual.html |
| gdal/ogr | 大抵のことはできる昔からあるスゴいライブラリ。けど、あまり早くないしコーディングスタイルが古い… | https://geopandas.org/en/stable/# |
コレ以外にもfionaとかrasterioなどGIS Python辺りで調査するとそれなりに情報を得ることができます。
(GDAL/OGR触ってると、いい感じにコーディングできるrasterioとか触りたくなるはずです。間違いなく。)
###コード
これだけの量で空間演算を実現できるのは本当に素晴らしいですね。
字ごとに、建築物の中にランダムに人口の数だけポイントを生成しています。
from shapely.geometry import Point
import geopandas as gpd
import random
# 国勢調査データ - 南房総市
census_shp_path = "shps/h27ka12234.shp"
# 南房総市周辺の建築物データ
building_shp_path = "shps/20210101-建築物.shp"
def generate_random_points_in_polygon(count, poly):
"""polyポリゴン内に、ランダムな位置のポイントを生成します
Args:
count (int): 生成するポイント数
poly (shapely.geometry.Polygon): ポイントを生成するための範囲を示すポリゴン
Returns:
array: point(shapely.geometry.Point) generated in polygon.
"""
# 生成したポイントを保管するリスト
points = []
# ポリゴンを囲う矩形(bounds)から、最大最小X,Yを取得
min_x, min_y, max_x, max_y = poly.bounds
i = 0
while i < count:
# ランダムなポイントを生成(最大最小X, Yで範囲指定)
point = Point(random.uniform(min_x, max_x), random.uniform(min_y, max_y))
# 生成したポイントがポリゴン内に含まれる(contain)の場合のみ、リストに保管
if poly.contains(point):
points.append(point)
i += 1
return points
# [国勢調査データの読み込み(文字コード:UTF-8)]
# 字ごとのポリゴンが格納されている。
# JINKO:字ごとの人口、S_NAME:字名、geometry:字を示すポリゴン のみを利用する
census_df = gpd.read_file(census_shp_path).loc[:, ['JINKO', 'S_NAME', 'geometry']]
# [建築物データの読み込み(文字コード:cp932)]
# 建物ごとのポリゴンが格納されている。
# bboxで取得する範囲(bounding box:矩形)を指定することで、取得するデータを絞り込むことができる。
# 今回、建築物は南房総市のみではなく近隣地域も含まれてしまっているので、南房総市を囲う矩形を指定することで
# ある程度件数を絞り込むことができる。
building_df = gpd.read_file(building_shp_path, encoding='cp932', bbox=census_df).loc[:, ['種別', 'geometry']]
# 種別:普通建物や無壁舎(倉庫など)が格納されている。今回は家屋を想定し「普通建物」のみを抽出・利用する
building_df = building_df.query('種別 == "普通建物"')
# [座標系]
# よくわからない人は EPSG:4326 か EPSG:6668 を使えばOK。
# 今回、建築物データがEPSG:6668なので、そちらを利用します。
base_coord = building_df.crs
# 国勢調査データを投影変換しておきます。
# よくわからない人はおまじないくらいに思ってください。
census_df = census_df.to_crs(building_df.crs)
# [南房総市にある建物だけを抽出し、建物がどの字に属するか分類する]
# 建築物と国勢調査データの重なり(overlay)を抽出する。
# ここでは2つのポリゴンが重なっている(intersection: A and B)の箇所。
# overlay operationについては下記参照。
# https://geopandas.org/en/stable/docs/user_guide/set_operations.html
# この処理で
# * 南房総市の字ポリゴンに含まれる建物だけが抽出される
# * 国勢調査データの持っているデータ(字名や人口)が、建築物ポリゴンに格納される
# => どの建築物がどの字に属しているかの情報が格納される
builds_in_census_df = building_df.overlay(census_df, how='intersection')
# [建物内にランダムポイントを生成し、住民が持つスマホの現在位置を生成する]
# 本来は、字ごとに建築物ポリゴンをまとめて1つのポリゴン(マルチポリゴン)として変化させ
# そのマルチポリゴンと字の人口を使ってgenerate_random_points_in_polygon関数を呼び
# ランダムポイントを発生させればよいのだが、今回は建物がそれなりに多いのとマルチポリゴン内にランダムポイントが入るヒット率が低いので
# 処理時間が相当にかかってしまう。
# builds_in_aza_df = builds_in_census_df.dissolve(by='S_NAME')
# points.append(generate_random_points_in_polygon(builds_in_aza_df['JINKO'], builds_in_aza_df))
# よって、今回は違うやり方を実施する。
# 字ごとに
human_points: dict[str, list] = {}
human_points['aza'] = [] # 字名
human_points['geometry'] = [] # 位置
human_points['testdata1'] = [] # テストデータ1: テストデータとして、適当なデータを入れてみる
human_points['testdata2'] = [] # テストデータ2: テストデータとして、適当なデータを入れてみる
for aza in census_df['S_NAME'].unique():
# 国勢調査データから字の人口を取得し
populate_in_aza = census_df.query(f'S_NAME == "{aza}"')['JINKO'].values.tolist()[0]
# 字に含まれる建築物を抽出し
builds_in_aza_df = builds_in_census_df.query(f'S_NAME == "{aza}"')
# 字に含まれる建築物の数を抽出
builds_in_aza_count = len(builds_in_aza_df)
# 字に含まれる建築物ポリゴンを抽出
build_geom_in_aza_list = builds_in_aza_df['geometry'].values
# 字の人口の数だけ…
for c in range(populate_in_aza):
# 乱数を発生させ、字に含まれる建造物をランダムに1つ選択
i = random.randint(0, builds_in_aza_count - 1)
build_geom = build_geom_in_aza_list[i]
# その建造物から1つだけポイントを生成
p = generate_random_points_in_polygon(1, build_geom)[0]
human_points['aza'].append(aza) # 字名
human_points['geometry'].append(p) # 位置
human_points['testdata1'].append(random.randint(0, 100)) # テストデータ1
human_points['testdata2'].append(random.random() * 100) # テストデータ2
# ランダムポイントからDataFrameを作成
human_df = gpd.GeoDataFrame(human_points, crs=base_coord)
# geojsonだとspatial indexがないのでQGISでの表示が激遅です。Shapefileが妥当。
# Shapefileの場合、カラムサイズが10byteまでという制約があるので、カラム名に日本語を使うことはおすすめしない。できればAliasを使ってほしい。
# もしカラム名に日本語を使う場合、文字コードがcp932(Shift_JIS)だと日本語5文字=10byteまで、UTF-8だと1文字が3byte/4byteで定義されることもあるので
# 場合によっては2文字程度しか入らないことを留意すること。
human_df.to_file('result.shp', driver='ESRI Shapefile', encoding='utf-8')
###結果確認

赤枠が南房総市、カラーな点が生成した住民が持つスマホの現在位置、黒い点のようなもの(ズームするとオレンジ)が建築物データです。
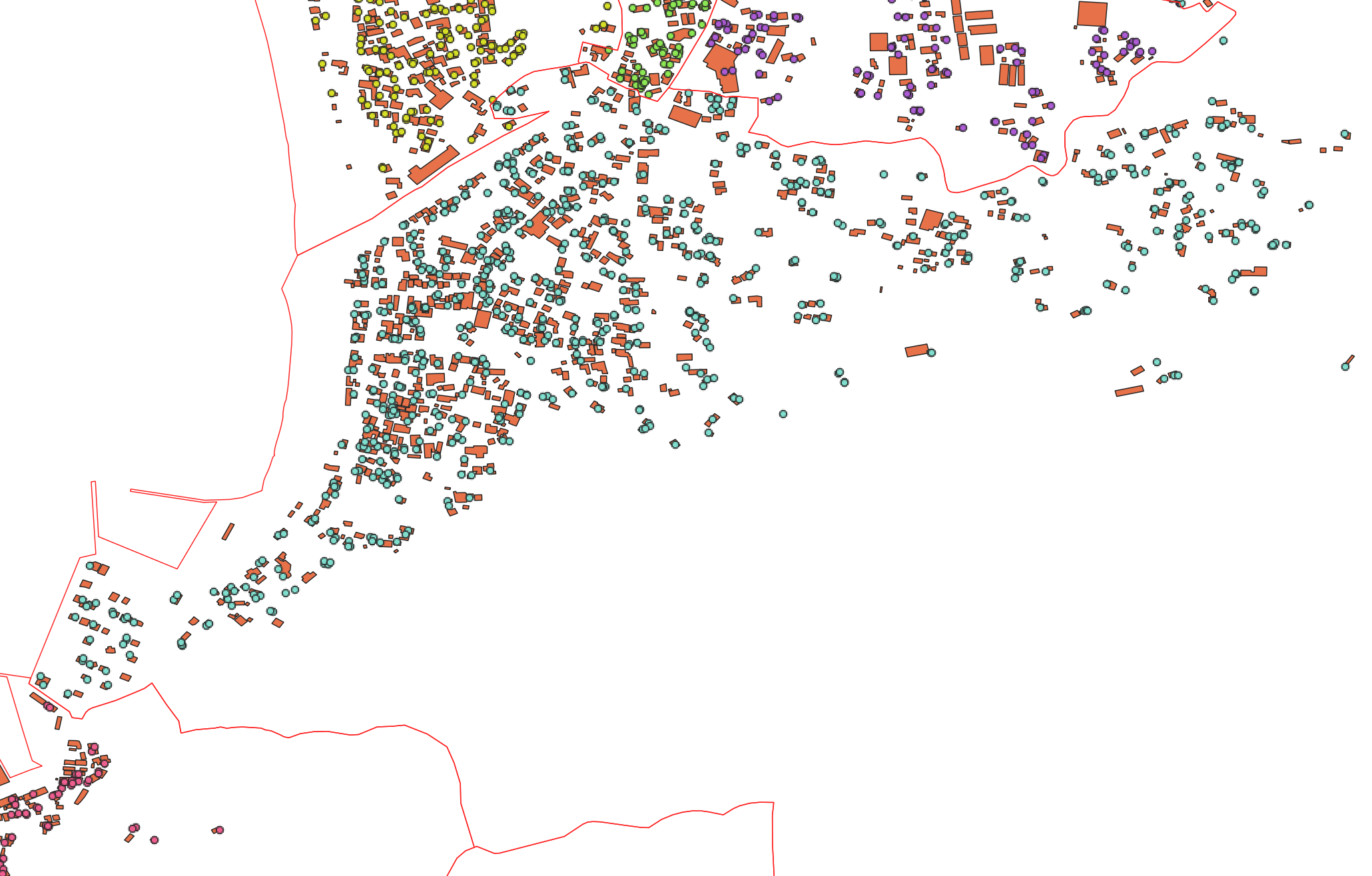
ちゃんと、南房総市内の人がいそうなところにポイントを生成できていますね。
##最後に
生成したデータは商圏分析(例:どこにコンビニ立てる?)や防災計画(例:災害発生時の避難所困難者の抽出)などに利用できます。
ベースはpandasなので、住所からCSVなどと結合して利用することもできます。ぜひお試しください。
geopandasはpandasに位置情報を処理可能な拡張が施された、非常に強力なツールです。
コアな解析処理はGDALやESRI ArcGISに譲ってしまいますが、それでも十分に有用なので、ぜひ使ってみてください。
ちなみに、今回は素のpython+QGISでやってしまいましたが、もちろんWatson Discovery上のjupyter notebookでもコーディング可能です。
その場合はmatplotlibを使ってgeopandasのplot()で途中経過を確認できます。
利用方法については、下記を参照ください。
IBM Developer - Working with geospatial vector data in Python(英語)
あと、本記事では座標系についてはほぼ触れないようにしました。
慣れていない人が位置情報データを扱う場合は、「WGS84, 世界測地系緯度経度、JGD2000, JGD2011」「EPSG:4326, EPSG:6668などと書かれた緯度経度データを使いましょう。(多少誤差はありますが)なんとなく処理はできます。
もし厳密な距離・面積計算をしたかったり、「平面直角座標系」や「UTM」、「日本測地系」などと書かれたデータを目にしてしまった場合は、必ずGISに詳しい方にご相談ください。不用意に触るとハマります。火傷します。
もしくは**位置情報ネタがありましたらぜひご相談ください!**ノリノリでお話させていただきます〜
##参考
書いてるときに見つけたんだけど、この方のまとめの熱量スゴい…
https://qiita.com/c60evaporator/items/78b4148bac6afa4844f9