内容
pytorchで勾配計算をしない方法には
- tensorの
.detach()を使って計算グラフを切る- GANのサンプルコードでよく見かける
- with文を使って
torch.no_grad()で囲んで計算グラフを作らない- eval時によく使う
- tensorの
.requires_gradをFalseにセットして勾配計算をしない- fine-tuingするときによく使う
という方法がありますが,どのように違うのかが少しややこしかったので整理してみました.
- notebookはGistにあります.
対象
ここでは以下のような,単純に積和を繰り返しただけの計算を考えます.
y = a * x + b
z = c * y + d
w = e * z + f
計算グラフで描くと以下のようになります.ノードは変数か*か+です.エッジには勾配,つまり$w$に対する各変数$\theta$での微分$\frac{\partial w}{\partial \theta}$を書いてあります.
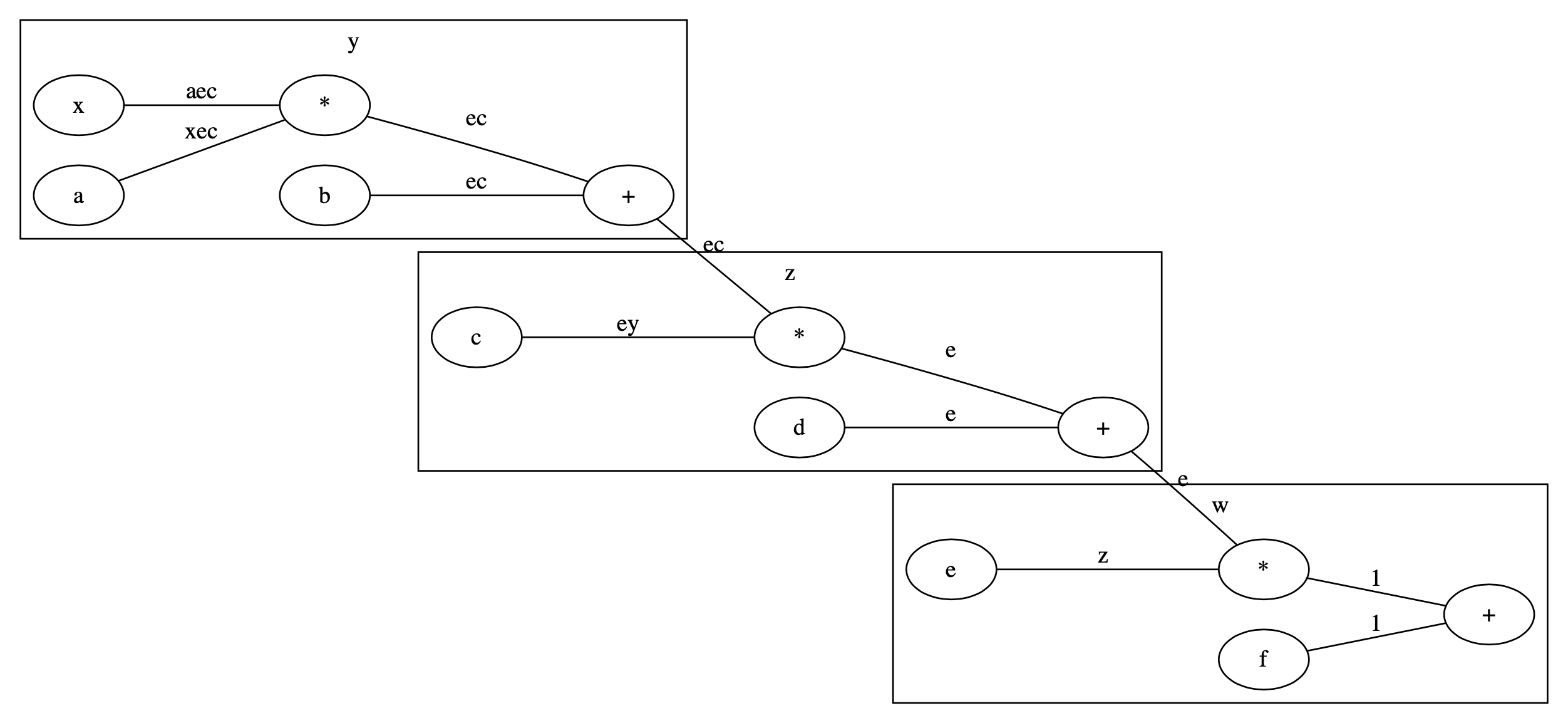
値は適当に決めます.aからfがパラメータ,xが入力とみなします.
import numpy as numpy
import torch
a = torch.tensor(2., requires_grad=True)
b = torch.tensor(3., requires_grad=True)
c = torch.tensor(5., requires_grad=True)
d = torch.tensor(7., requires_grad=True)
e = torch.tensor(11., requires_grad=True)
f = torch.tensor(13., requires_grad=True)
x = torch.tensor(17., requires_grad=True)
params = [a, b, c, d, e, f, x]
print(params)
[tensor(2., requires_grad=True), tensor(3., requires_grad=True), tensor(5., requires_grad=True), tensor(7., requires_grad=True), tensor(11., requires_grad=True), tensor(13., requires_grad=True), tensor(17., requires_grad=True)]
通常のforwardとbackwardの結果
では,普通のforward計算をして,普通のbackwardを計算してみます.
for p in params:
if p.grad:
p.grad.data = torch.tensor(0.0) # zero_gradの代わり
y = a * x + b
z = c * y + d
w = e * z + f
w.backward()
print('y={}, z={}, w={}'.format(y, z, w))
print('f.grad=1:', f.grad)
print('e.grad=z={}:'.format(z.item()), e.grad)
print('d.grad=e={}:'.format(e.item()), d.grad)
print('c.grad=ey={}:'.format(e.item() * y.item()), c.grad)
print('b.grad=ey={}:'.format(e.item() * c.item()), b.grad)
print('a.grad=xey={}:'.format(x.item() * e.item() * c.item()), a.grad)
print('x.grad=aey={}:'.format(a.item() * e.item() * c.item()), x.grad)
出力は以下の通り.
y=37.0, z=192.0, w=2125.0
f.grad=1: tensor(1.)
e.grad=z=192.0: tensor(192.)
d.grad=e=11.0: tensor(11.)
c.grad=ey=407.0: tensor(407.)
b.grad=ey=55.0: tensor(55.)
a.grad=xey=935.0: tensor(935.)
x.grad=aey=110.0: tensor(110.)
期待通り,問題なくすべて計算されています.
detach()でグラフを切る
では.detach()を使って計算グラフを切ってみます.
yをdetach()
まずyで計算グラフを切ってみましょう.図で描くと以下のようになります.yからzへ行くエッジがなくなっています.
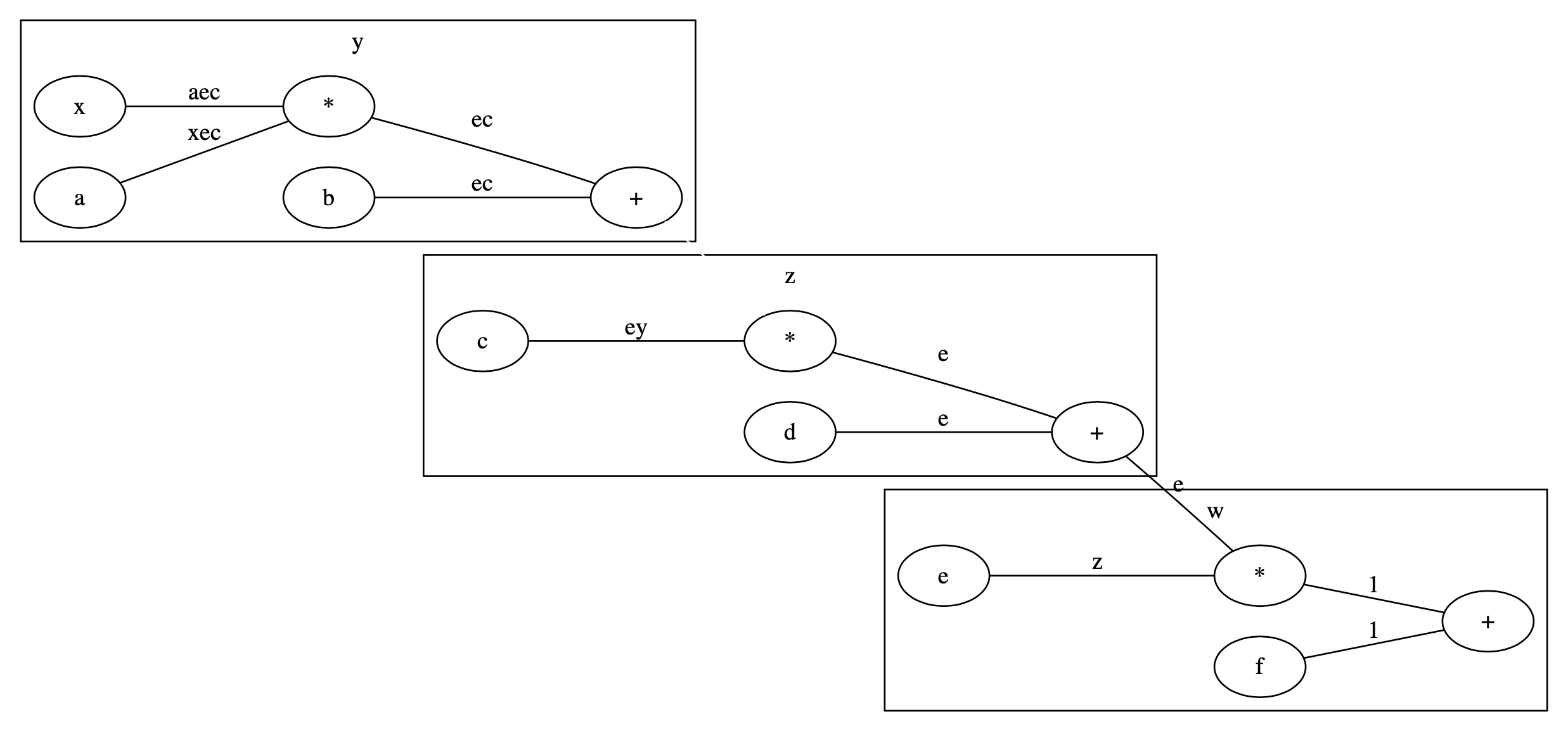
そのためには,y.detach()を使います.
for p in params:
if p.grad:
p.grad.data = torch.tensor(0.0) # zero_grad
y = a * x + b
z = c * y.detach() + d
w = e * z + f
w.backward()
print('y={}, z={}, w={}'.format(y, z, w))
print('f.grad=1:', f.grad)
print('e.grad=z={}:'.format(z.item()), e.grad)
print('d.grad=e={}:'.format(e.item()), d.grad)
print('c.grad=ey={}:'.format(e.item() * y.item()), c.grad)
print('b.grad=ey={}:'.format(e.item() * c.item()), b.grad)
print('a.grad=xey={}:'.format(x.item() * e.item() * c.item()), a.grad)
print('x.grad=aey={}:'.format(a.item() * e.item() * c.item()), x.grad)
出力は以下の通り.
y=37.0, z=192.0, w=2125.0
f.grad=1: tensor(1.)
e.grad=z=192.0: tensor(192.)
d.grad=e=11.0: tensor(11.)
c.grad=ey=407.0: tensor(407.)
b.grad=ey=55.0: tensor(0.)
a.grad=xey=935.0: tensor(0.)
x.grad=aey=110.0: tensor(0.)
cとdまでは勾配が計算されていますが,a, b, xの勾配は計算されていません.
-
y.detach()と積を計算しているcや,和を計算しているdには,yのdetach()は影響しません. -
a, b, xは,y.detach()によってy以降は計算グラフが切れているるので,そもそも勾配計算が実行されません.
zをdetach()
次にzで計算グラフを切ってみましょう図で描くと以下のようになります.zからwへ行くエッジがなくなっています.
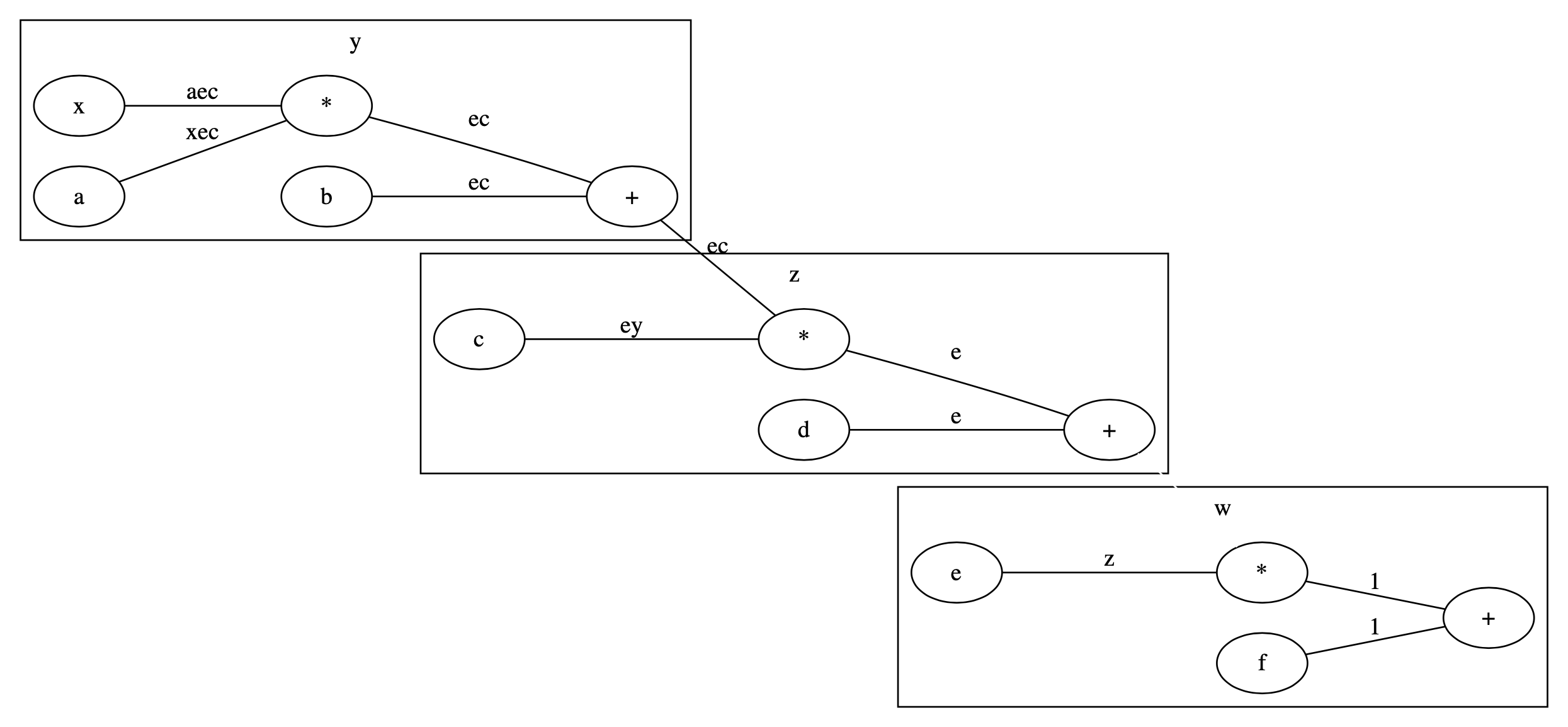
そのためにz.detach()を使います.
for p in params:
if p.grad:
p.grad.data = torch.tensor(0.0) # zero_grad
y = a * x + b
z = c * y + d
w = e * z.detach() + f
w.backward()
print('y={}, z={}, w={}'.format(y, z, w))
print('f.grad=1:', f.grad)
print('e.grad=z={}:'.format(z.item()), e.grad)
print('d.grad=e={}:'.format(e.item()), d.grad)
print('c.grad=ey={}:'.format(e.item() * y.item()), c.grad)
print('b.grad=ey={}:'.format(e.item() * c.item()), b.grad)
print('a.grad=xey={}:'.format(x.item() * e.item() * c.item()), a.grad)
print('x.grad=aey={}:'.format(a.item() * e.item() * c.item()), x.grad)
出力は以下の通り.
y=37.0, z=192.0, w=2125.0
f.grad=1: tensor(1.)
e.grad=z=192.0: tensor(192.)
d.grad=e=11.0: tensor(0.)
c.grad=ey=407.0: tensor(0.)
b.grad=ey=55.0: tensor(0.)
a.grad=xey=935.0: tensor(0.)
x.grad=aey=110.0: tensor(0.)
eとfの勾配は計算されていますが,a, b, c, d, xの勾配は計算されていません.
-
z.detach()と積を計算しているeや,和を計算しているfには,zのdetach()は影響しません. -
c, dは,z.detach()によってz以降は計算グラフが切れているるので,そもそも勾配計算が実行されません. - 計算グラフが切れているので,
a, b, xも勾配計算されません.
with no_grad():で囲む
ではwith文を使ってみます.with no_grad():で囲むと,その部分の計算グラフは作られません.したがって,勾配計算もされなくなります.
yを囲む
まずyの計算部分をwith文で囲んでみます.図で描くと以下のようになります.灰色の網掛け部分が計算グラフを作らない部分です.
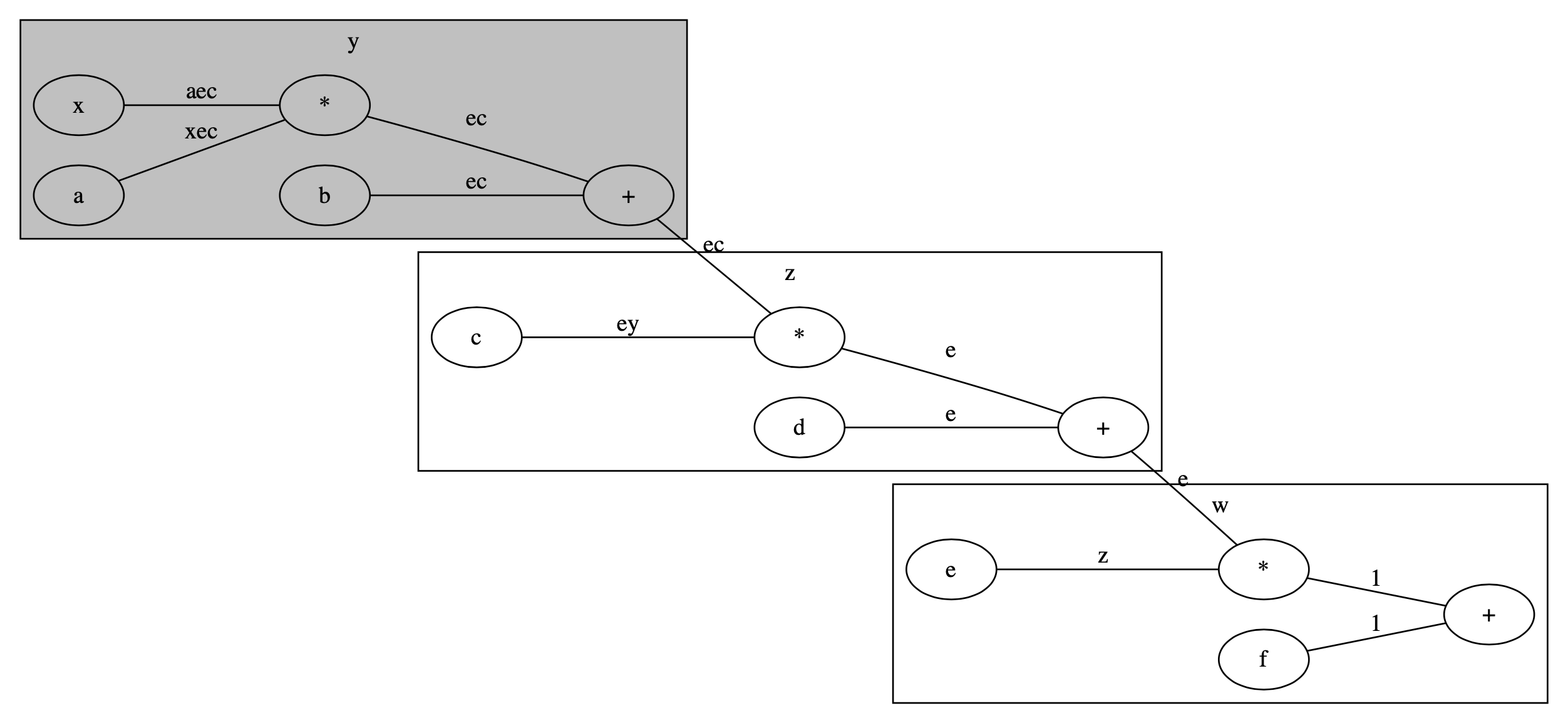
for p in params:
if p.grad:
p.grad.data = torch.tensor(0.0) # zero_grad
with torch.no_grad():
y = a * x + b
z = c * y + d
w = e * z + f
w.backward()
print('y={}, z={}, w={}'.format(y, z, w))
print('f.grad=1:', f.grad)
print('e.grad=z={}:'.format(z.item()), e.grad)
print('d.grad=e={}:'.format(e.item()), d.grad)
print('c.grad=ey={}:'.format(e.item() * y.item()), c.grad)
print('b.grad=ey={}:'.format(e.item() * c.item()), b.grad)
print('a.grad=xey={}:'.format(x.item() * e.item() * c.item()), a.grad)
print('x.grad=aey={}:'.format(a.item() * e.item() * c.item()), x.grad)
出力は以下の通り.
y=37.0, z=192.0, w=2125.0
f.grad=1: tensor(1.)
e.grad=z=192.0: tensor(192.)
d.grad=e=11.0: tensor(11.)
c.grad=ey=407.0: tensor(407.)
b.grad=ey=55.0: tensor(0.)
a.grad=xey=935.0: tensor(0.)
x.grad=aey=110.0: tensor(0.)
cとdまでは勾配が計算されていますが,a, b, xの勾配は計算されていません.
-
yと積を計算しているcや,和を計算しているdには,y作成時の計算グラフは影響しません. -
a, b, xは,y作成時の計算グラフが作られていないため,勾配計算が実行されません.
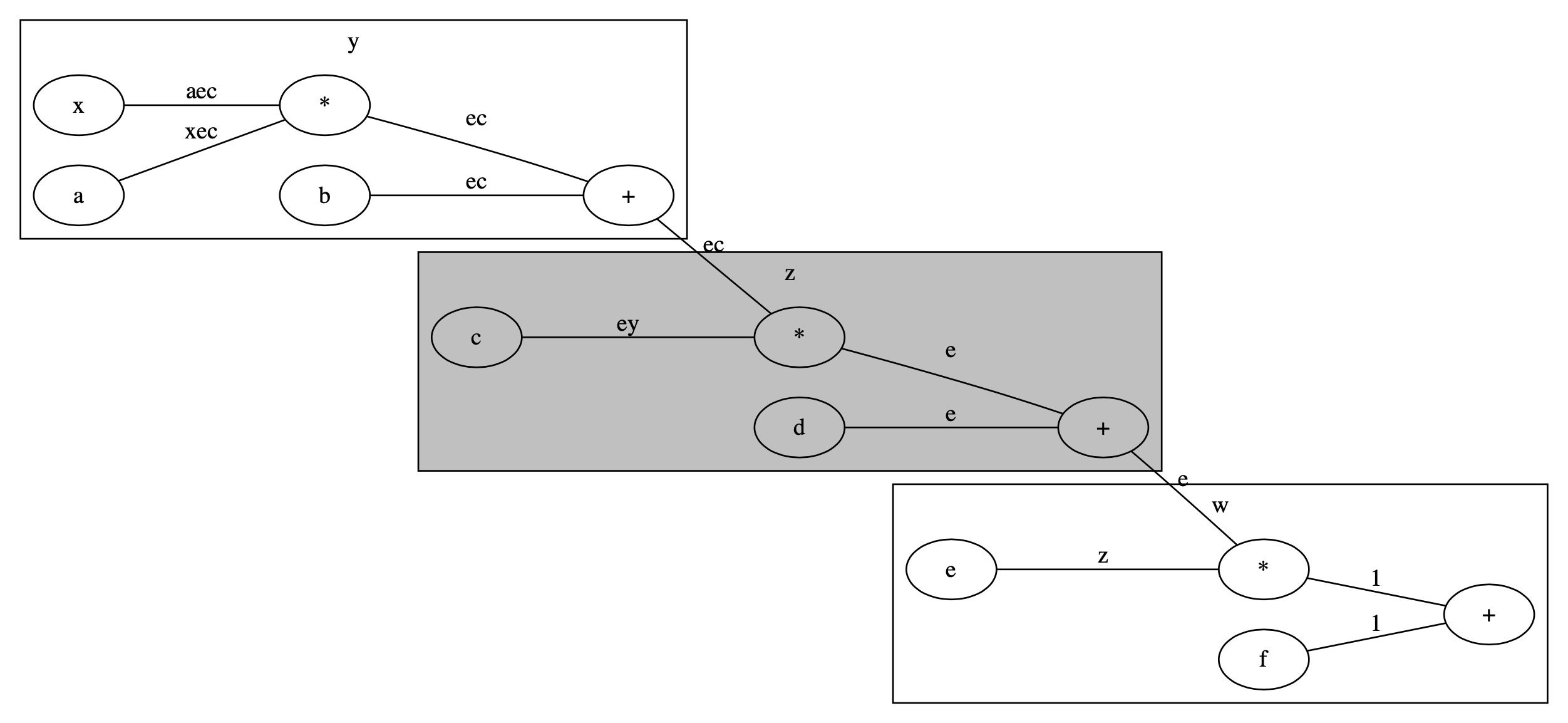
zを囲む
ではzの計算部分を囲んでみます.図で描くと以下のようになります.灰色の網掛け部分が計算グラフを作らない部分です.
for p in params:
if p.grad:
p.grad.data = torch.tensor(0.0) # zero_grad
y = a * x + b
with torch.no_grad():
z = c * y + d
w = e * z + f
w.backward()
print('y={}, z={}, w={}'.format(y, z, w))
print('f.grad=1:', f.grad)
print('e.grad=z={}:'.format(z.item()), e.grad)
print('d.grad=e={}:'.format(e.item()), d.grad)
print('c.grad=ey={}:'.format(e.item() * y.item()), c.grad)
print('b.grad=ey={}:'.format(e.item() * c.item()), b.grad)
print('a.grad=xey={}:'.format(x.item() * e.item() * c.item()), a.grad)
print('x.grad=aey={}:'.format(a.item() * e.item() * c.item()), x.grad)
出力は以下の通り.
y=37.0, z=192.0, w=2125.0
f.grad=1: tensor(1.)
e.grad=z=192.0: tensor(192.)
d.grad=e=11.0: tensor(0.)
c.grad=ey=407.0: tensor(0.)
b.grad=ey=55.0: tensor(0.)
a.grad=xey=935.0: tensor(0.)
x.grad=aey=110.0: tensor(0.)
eとfまでは勾配が計算されていますが,c, d, a, b, xの勾配は計算されていません.
-
zと積を計算しているeや,和を計算しているfには,z作成時の計算グラフは影響しません. -
c, dは,z作成時の計算グラフが作られていないため,勾配計算が実行されません. - 計算グラフが作られていない,つまり計算グラフが切れているので,
a, b, xも勾配計算されません.
.requires_grad = Falseを使う
最後に,tensorの属性requires_gradをFalseに設定してみます.
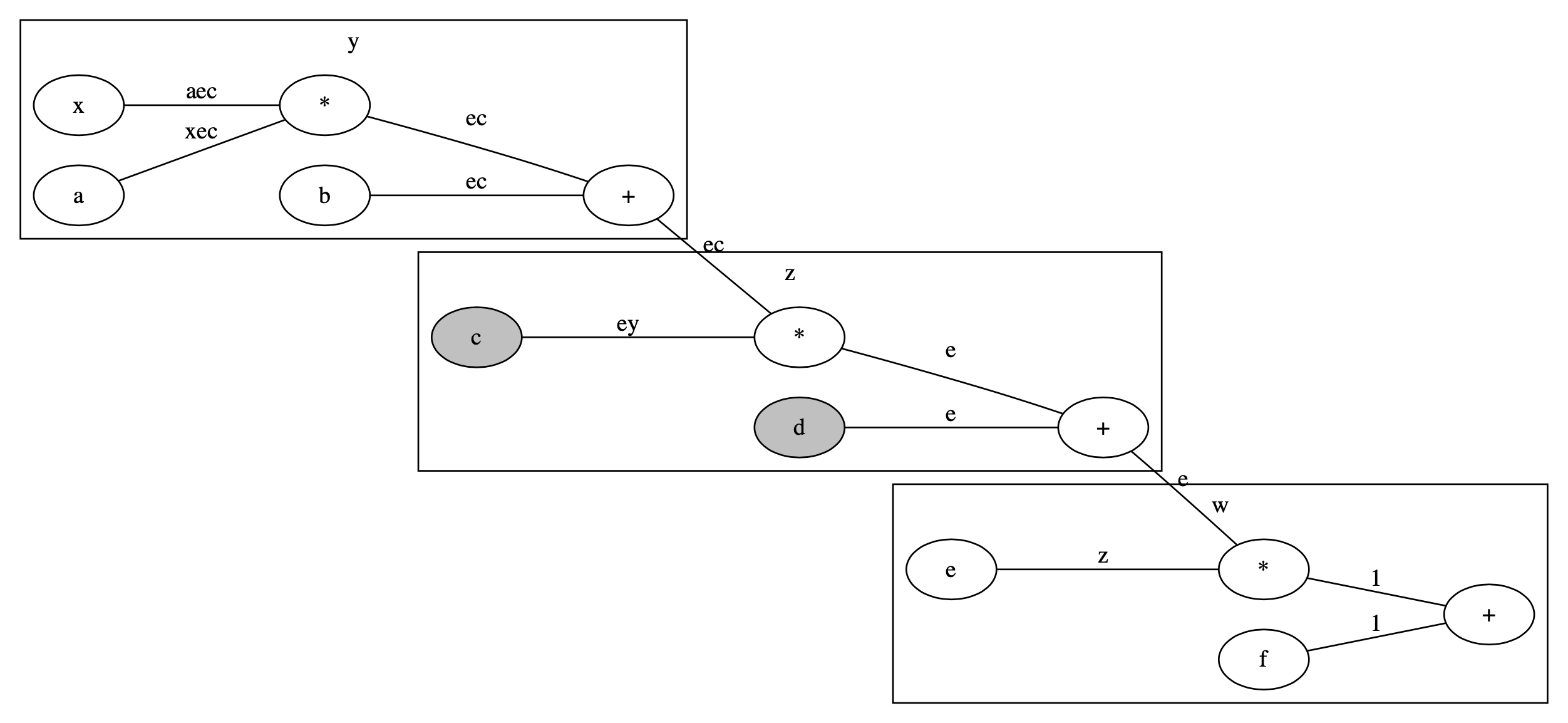
cとdの勾配をFalseに
まずはcとdに対してFalseを設定してみます.
図で描くと以下のようになります.灰色の網掛け部分が勾配計算をしないtensorです.
for p in params:
if p.grad:
p.grad.data = torch.tensor(0.0) # zero_grad
c.requires_grad = False
d.requires_grad = False
y = a * x + b
z = c * y + d
w = e * z + f
w.backward()
print('y={}, z={}, w={}'.format(y, z, w))
print('f.grad=1:', f.grad)
print('e.grad=z={}:'.format(z.item()), e.grad)
print('d.grad=e={}:'.format(e.item()), d.grad)
print('c.grad=ey={}:'.format(e.item() * y.item()), c.grad)
print('b.grad=ey={}:'.format(e.item() * c.item()), b.grad)
print('a.grad=xey={}:'.format(x.item() * e.item() * c.item()), a.grad)
print('x.grad=aey={}:'.format(a.item() * e.item() * c.item()), x.grad)
c.requires_grad = True
d.requires_grad = True
出力は以下の通り.
y=37.0, z=192.0, w=2125.0
f.grad=1: tensor(1.)
e.grad=z=192.0: tensor(192.)
d.grad=e=11.0: tensor(0.)
c.grad=ey=407.0: tensor(0.)
b.grad=ey=55.0: tensor(55.)
a.grad=xey=935.0: tensor(935.)
x.grad=aey=110.0: tensor(110.)
指定したcとdだけ,勾配計算がされていません.
しかしそれよりも下流のa, b, xの勾配は計算されています.つまり計算グラフは切れておらず,指定した変数の勾配計算だけが省略されています.
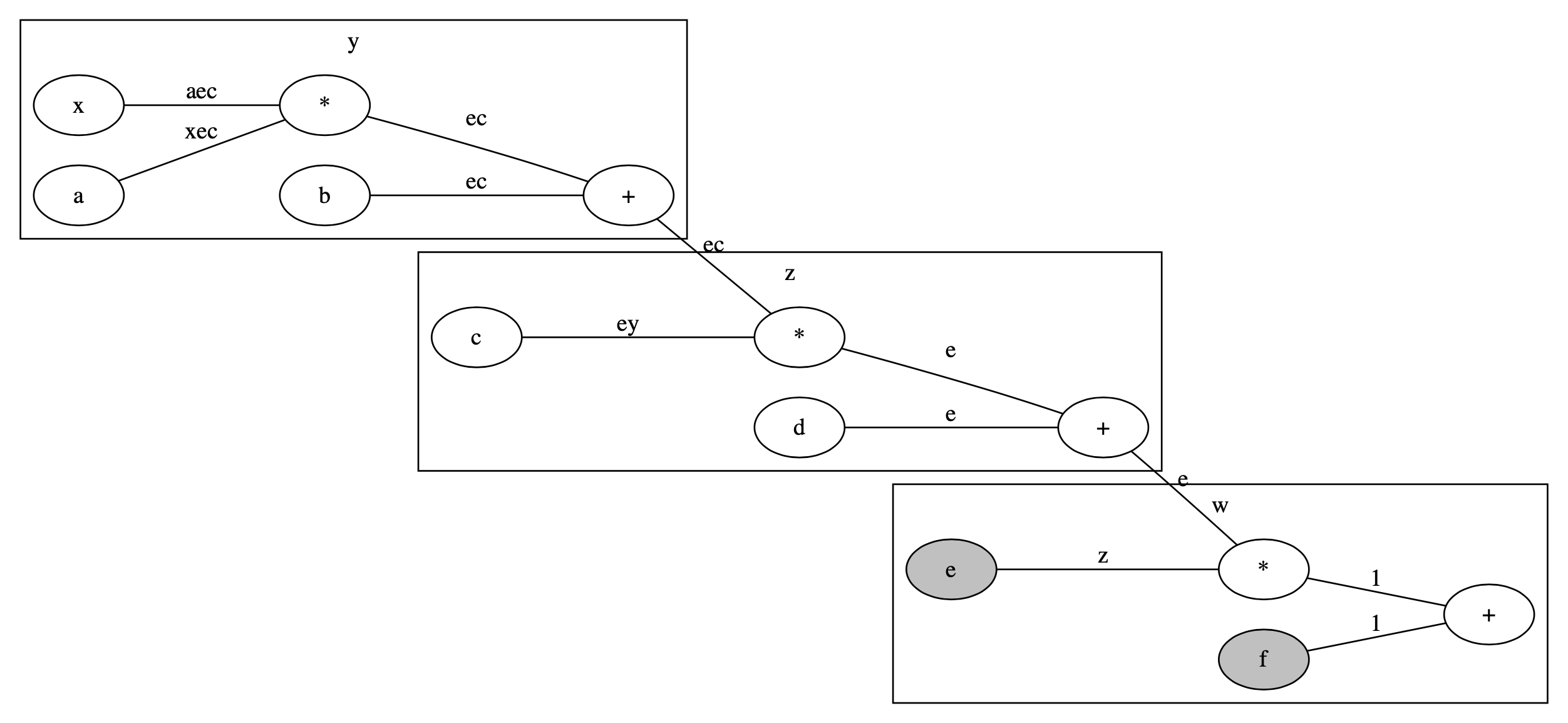
eとfの勾配をFalseに
次にeとfに対してFalseを設定してみます.
図で描くと以下のようになります.灰色の網掛け部分が勾配計算をしないtensorです.
for p in params:
if p.grad:
p.grad.data = torch.tensor(0.0) # zero_grad
e.requires_grad = False
f.requires_grad = False
y = a * x + b
z = c * y + d
w = e * z + f
w.backward()
print('y={}, z={}, w={}'.format(y, z, w))
print('f.grad=1:', f.grad)
print('e.grad=z={}:'.format(z.item()), e.grad)
print('d.grad=e={}:'.format(e.item()), d.grad)
print('c.grad=ey={}:'.format(e.item() * y.item()), c.grad)
print('b.grad=ey={}:'.format(e.item() * c.item()), b.grad)
print('a.grad=xey={}:'.format(x.item() * e.item() * c.item()), a.grad)
print('x.grad=aey={}:'.format(a.item() * e.item() * c.item()), x.grad)
e.requires_grad = True
f.requires_grad = True
出力は以下の通り.
y=37.0, z=192.0, w=2125.0
f.grad=1: tensor(0.)
e.grad=z=192.0: tensor(0.)
d.grad=e=11.0: tensor(11.)
c.grad=ey=407.0: tensor(407.)
b.grad=ey=55.0: tensor(55.)
a.grad=xey=935.0: tensor(935.)
x.grad=aey=110.0: tensor(110.)
指定したeとfだけ,勾配計算がされていません.
しかしそれよりも下流のc, d, a, b, xの勾配は計算されています.つまり計算グラフは切れておらず,指定した変数の勾配計算だけが省略されています.
yの勾配をFalseに
ちなみに中間変数のyに同じことをすると,エラーになります.
for p in params:
if p.grad:
p.grad.data = torch.tensor(0.0) # zero_grad
y = a * x + b
y.requires_grad = False
z = c * y + d
w = e * z + f
w.backward()
print('y={}, z={}, w={}'.format(y, z, w))
print('f.grad=1:', f.grad)
print('e.grad=z={}:'.format(z.item()), e.grad)
print('d.grad=e={}:'.format(e.item()), d.grad)
print('c.grad=ey={}:'.format(e.item() * y.item()), c.grad)
print('b.grad=ey={}:'.format(e.item() * c.item()), b.grad)
print('a.grad=xey={}:'.format(x.item() * e.item() * c.item()), a.grad)
print('x.grad=aey={}:'.format(a.item() * e.item() * c.item()), x.grad)
エラーは次の通り.
RuntimeError Traceback (most recent call last)
/tmp/ipykernel_4781/1215021765.py in <module>
4
5 y = a * x + b
----> 6 y.requires_grad = False
7 z = c * y + d
8 w = e * z + f
RuntimeError: you can only change requires_grad flags of leaf variables. If you want to use a computed variable in a subgraph that doesn't require differentiation use var_no_grad = var.detach().
エラーメッセージの内容は,
y_no_grad = y.detach()
というコードを書け,ということです.
まとめ
- 計算グラフを切るには
detach()かwith no_grad():-
detach()はtensorをコピーする(予想) -
with no_grad():ならコピーは発生しない(予想)
-
-
.requires_grad = Falseは,計算グラフを切らない
整理しようと思ったきっかけ:GAN
GANのサンプルコードがどれも
fake = netG(z)
pred_fake = netD(fake.detach())
というコードで,detach()だけが使われていて,with no_grad()は見かけませんでした.
今回の結論からすると,多分
with torch.no_grad():
fake = netG(z)
pred_fake = netD(fake)
でも結果は同じになるだろうと思います.detachでfakeのコピーを作らず,netGの計算グラフを作らない分だけ効率的かもしれません.試していないので,やってみた方は結果を教えて下さい.
(...でもnetGの計算グラフを通したfakeを後で使うので,このやり方ではfakeを作り直さなければならず,結局非効率ですが.)
追記
with no_grad()を使ったGANのサンプルコードを見かけたので,上の推測は多分あってます.
ただしGANに限って言えば,detach()やwith no_grad()を使って計算グラフを切らなくてもよいので(optimizerが更新するパラメータを設定できるので),detach()やwith no_grad()を使っていないGANのコードも見かけます.
整理しようと思ったきっかけ:pre-train
pre-trainモデルをパラメータを固定(freeze)して使うことはよくありますが,その前後に学習したいモジュールをくっつけても,計算グラフは切れないだろうかと思いました.
h1 = module1(x) # 自分のモデル
h2 = module2(h1) # requires_grad = Falseで,パラメータ固定
y = module3(h2) # 自分のモデル
今回の結果から,問題なく勾配はmodule2を通り抜けてmodule1まで到達することがわかりました.そもそも上で示した計算グラフを見れば,変数をfreezeしても計算グラフは切れないのは当然というのがわかりますが.