はじめに
実案件でDynamoDB StreamsをKinesis Client Library (以下KCL) で処理する機会がありましたので、KCLが実際にどういう挙動をするのか、それを踏まえてどのような実装にしたのか紹介したいと思います。

今回やりたかったこと
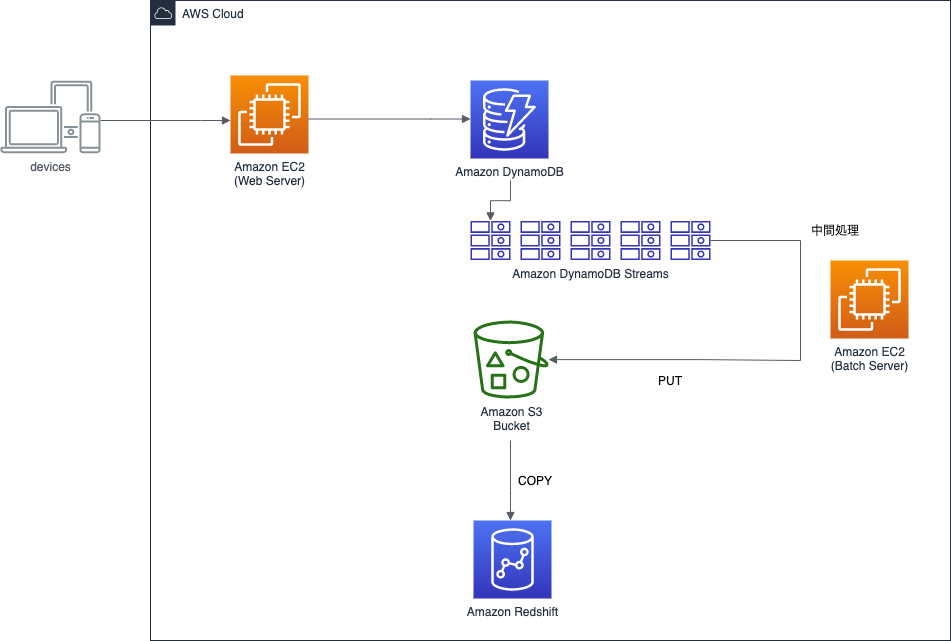
BookLive!のある機能ではDynamoDBを使用しています。
このDynamoDBのデータを、データ追加後できるだけ早いタイミングでRedshiftに転送する必要が出てきました。
現状のテーブル形式を踏まえ様々な検討をした結果、DynamoDB Streamsを設定し、追加されていくデータをいわゆるストリームとして扱うことでRedshiftに持っていくことが最善策という結論に至りました。
また、DynamoDB Streamsの取得方法は公式が推奨しているKCLを使う方法で行うことにしました。
注意点
- KCLを使用するコンシューマアプリケーションは基本的にEC2インスタンスに常駐させる場合が多いと思います。しかし、今回はバッチ風(定期的な実行/クローズ)に処理するので、定石からは少し外れている部分があります。
- DynamoDBのキャパシティモードはオンデマンドに設定しているため、本記事ではキャパシティを考慮する話は出てきません。
本記事の関連技術
- JDK11 (Amazon Coretto 11)
- DynamoDB Streams
- Kinesis Client Library (KCL)
- aws-sdk-java
dependencies {
implementation 'com.amazonaws:aws-java-sdk-dynamodb:1.11.833'
implementation 'com.amazonaws:aws-java-sdk-kinesis:1.11.839'
}
dependencies {
implementation 'com.amazonaws:dynamodb-streams-kinesis-adapter:1.5.2'
}
DynamoDB StreamsとKCL
DynamoDB Streamsについて
特徴
- DynamoDBに書き込まれた後、データは非常に低レイテンシーな間隔でストリームに追加される
- シャードは自動でスケーリングしてくれる
- また、特定のシャードが使われ続けるわけではなく、適度に新しいシャードが作られていく
- ストリームは追加後24時間保持される
- ストリームの設定はいつでも追加・削除可能
- ただし、ストリームの設定が追加された後にDynamoDBに追加されたデータのみバッファリングされる
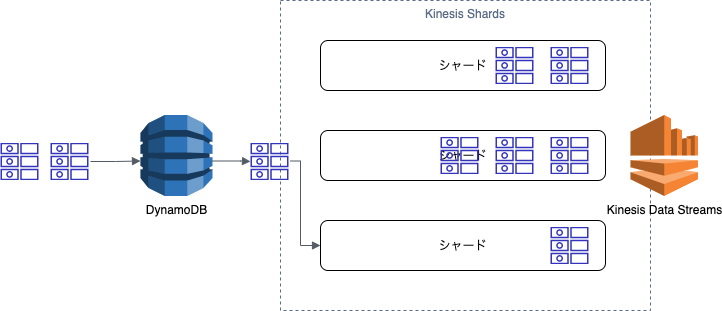
イメージ
あたかもKinesis Data Streamsのようにストリームをバッファリングしてくれます(以下の図のKinesis Shards部分をDynamoDB Streamsとして捉えることが可能です)。
KCLを直接使用することはできませんが、Kinesis Adapterを通して、Kinesis Data Streamsからストリームを取得するのと同等の方法でDynamoDB Streamsを取得することが可能です。
以下の図はあくまでも個人的なイメージであることに注意してください。
Kinesis Client Library (KCL) について
そもそもKinesisとは
ここでは触れませんが、参考記事を掲載しておきます。
特徴
- Kinesis Data Streamsを処理するためのコンシューマアプリケーション用オープンソースライブラリ
- コンシューマとはバッファリングされたストリームを取得して処理する側のこと
- 逆に追加する側はプロデューサー
- Kinesis Data Streamsを扱う上で必要な、どのシャードのどのレコードまで取得したかを記録する処理を、DynamoDBを使用して自動化してくれる
- シャードからのレコード取得もしてくれるため、開発者は基本的にレコードを取得した後の処理を実装するだけで良い
KCLの用語
以下の内容はDynamoDB Streamsを扱う場合においても同義です(Kinesis Data StreamsをDynamoDB Streamsに読み替えられます)。
- Shard(シャード)
- Kinesis Data Streamsのデータを分散バッファリングする本体
- 公式のFAQによると「シャードとは、Amazon Kinesis データストリームの基本的なスループットの単位」と記載されている
- Lease(リース)
- Kinesis Data Streamsのシャードからレコードを取得できるようになっている状態のこと
- Workerにシャードが貸し出されるという意味合いで用いられていそう(内部では、複数のWorkerから同じシャードが取得されないようになっている)
-
Leaseテーブル
- Leaseの状態(Workerとシャードのマッピング)やチェックポイントを記録するDynamoDBテーブル
- 存在しなければ、KCLが自動で作ってくれる
- そのため、アプリケーションが動作するEC2インスタンスにDynamoDBテーブルを作成する権限が必要
- もしくは、Primary Keyを
leaseKey::Stringに設定したDynamoDBテーブルを自前で作っても良い- 当社では、AWSのリソースをTerraformで管理していることもあり、この方法を採用
- この場合、テーブル名がそのままKinesisアプリケーション名となる
- LeaseKey
- Kinesis Data StreamsのシャードID
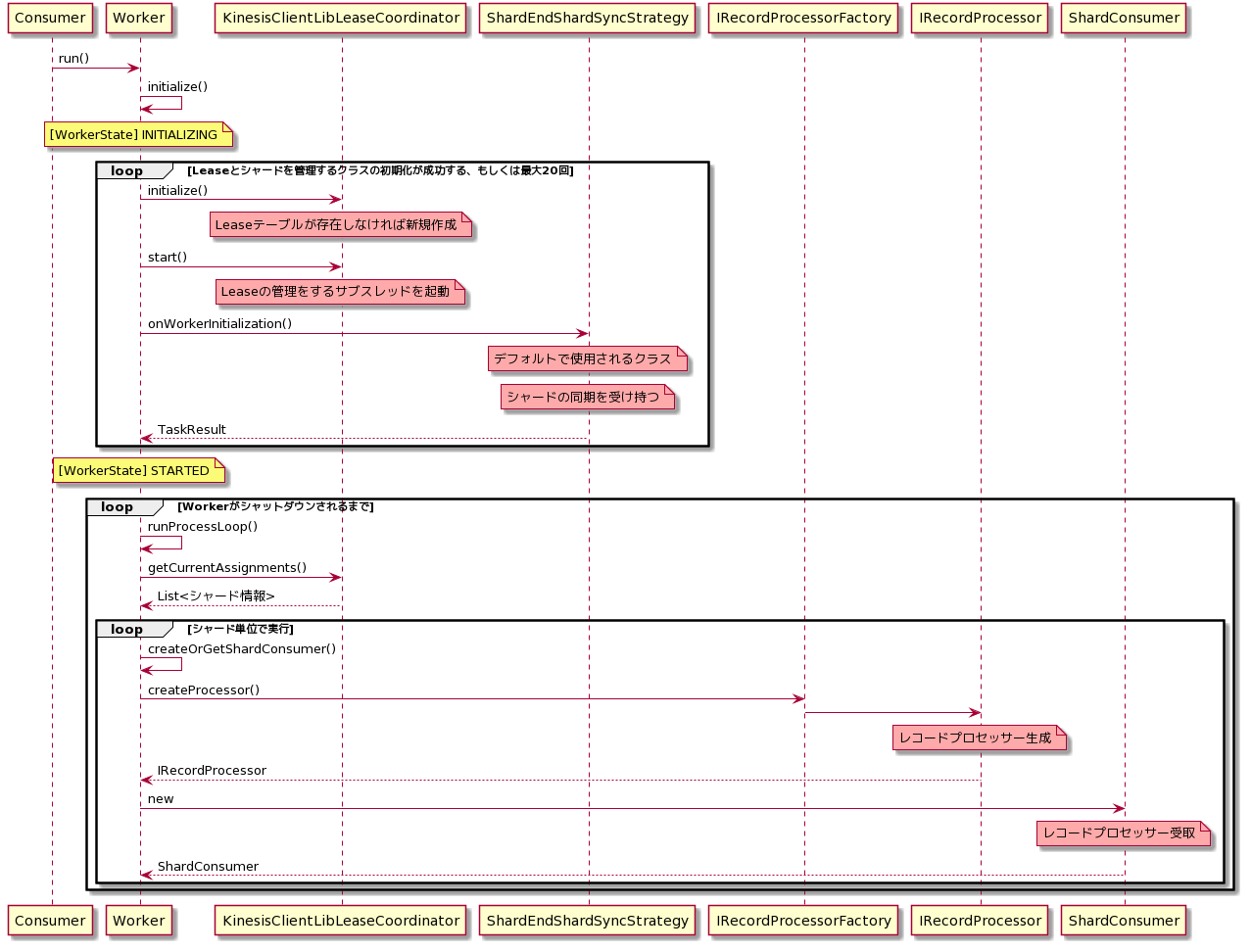
KCLのロジック(簡易版)
()がついているものはメソッドで、重要な箇所のみ抽出して記載しています。
Consumerは、Workerインスタンスを作成しrun()を呼び出す自分で実装する部分となります。
■レコードプロセッサーが生成されるまで
デーモンかバッチか
runProcessLoop()が実行されるループは、実行中のWorkerインスタンスに対して、シャットダウンがリクエストされ、シャットダウンが完了するまで無限ループする作りとなっています。
つまり、
- Workerの
run()メソッドをコンシューマアプリケーションのメインスレッドで実行した場合、基本的にデーモンのように半永久的に動作し続けます - 一方で、今回目的としている定期的に開始/終了を伴うバッチ風に動作させるためには、サブスレッドを作成し、そちらにWorkerインスタンスを渡してあげる必要があります。また、一定時間後にメインスレッドからWorkerに対してシャットダウンリクエストを送ることで、Workerを終了させることができます。
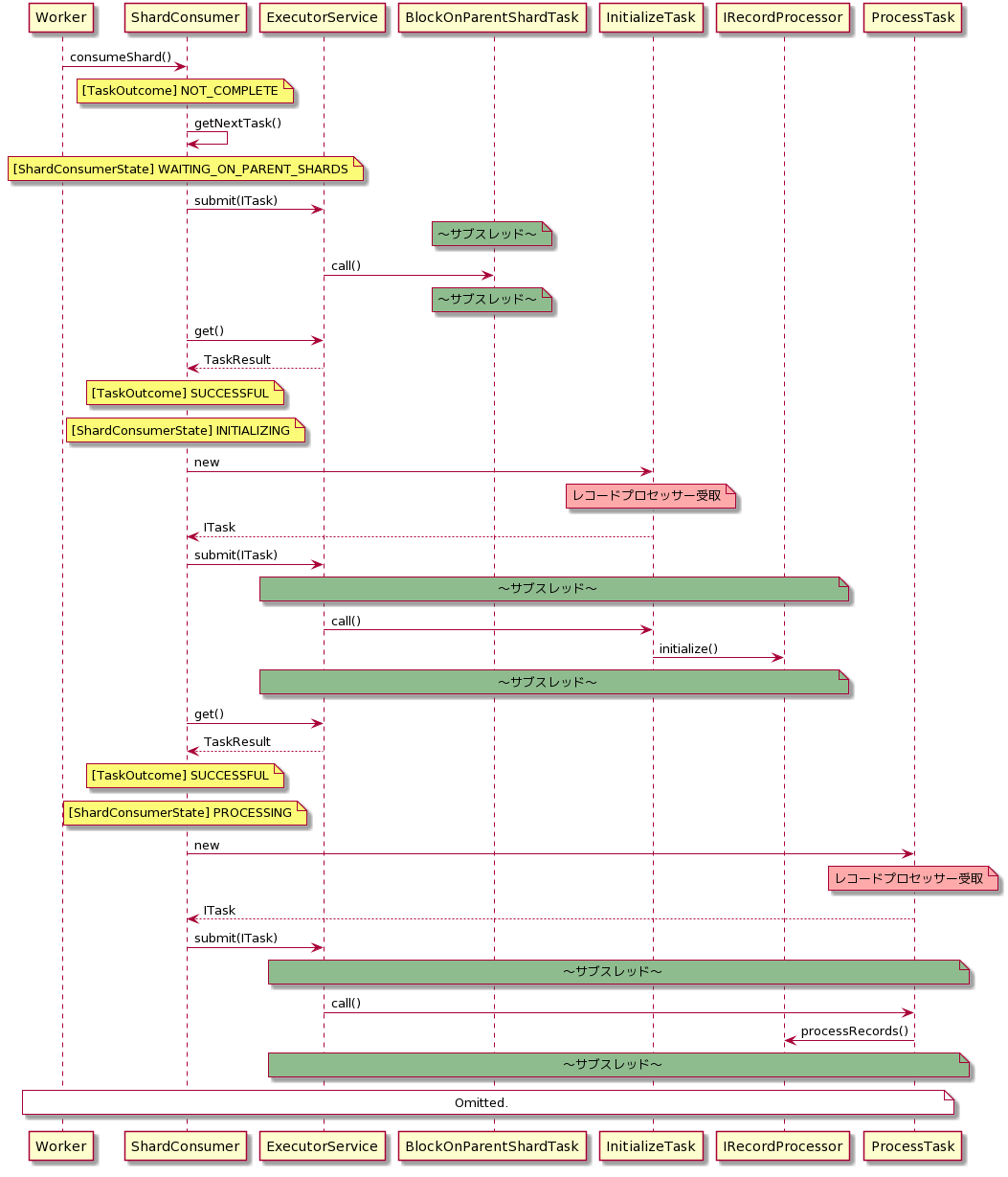
■レコードプロセッサー本体の処理
以下は、上のシーケンス図のWorkerがShardConsumerインスタンスを生成した後の処理になります。
なお、この処理は上のシーケンス図でいうところの[シャード単位で実行]のloop内で実行されます。
RuntimeExceptionを含むExceptionはKCLに握り潰される
IRecordProcessorインターフェースを実装するいわゆるレコードプロセッサー内で発生する例外は全て握り潰されます。
言い換えると、レコードプロセッサー内でどんな例外が発生してもアプリケーションは異常終了しません。
この弊害はチェックポイントの記録時に起きます。
シーケンス図を見れば分かるようにIRecordProcessorの各メソッドはそれぞれサブスレッド上で実行されます。
また、そのスレッド内で発生した例外は先に記載した通り、KCLによって無視されます。
つまり、processRecords()で例外が発生してもスレッドはあたかも正常終了したかのように扱われるということです。
ちなみに、checkpointはprocessRecords()に渡される時点で、そのシャードリースの最新シーケンスと決まっています。
このシーケンスがshutdown()時にも渡されるため、processRecords()のスレッドが異常終了したときのshutdown()時にcheckpointを記録すると、処理に失敗したはずのストリームは欠損してしまいます。
KCLの仕様を踏まえたコンシューマアプリケーションの実装
実際の実装とは違いますが、ロジックの基本形だけ伝わるように書いています。
(抜き出しながら記載していったので、そのままでは実行できないかもしれません。)
StreamsAdapter
- エントリーポイントのクラス
- 実行/終了を伴うバッチ処理をするため、サブスレッドでWorkerを実行しています(例では5分間有効)
- 30秒おきにShardReadWriteLockから各シャードの処理ステータスをチェックし、1つでもExceptionが発生していれば(ShardProcessStatusがFAILURE)、即座にシャットダウンを実行しています
import com.amazonaws.auth.AWSCredentialsProvider;
import com.amazonaws.auth.InstanceProfileCredentialsProvider;
import com.amazonaws.regions.Regions;
import com.amazonaws.services.cloudwatch.AmazonCloudWatch;
import com.amazonaws.services.cloudwatch.AmazonCloudWatchClientBuilder;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDB;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClientBuilder;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBStreams;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBStreamsClientBuilder;
import com.amazonaws.services.dynamodbv2.streamsadapter.AmazonDynamoDBStreamsAdapterClient;
import com.amazonaws.services.dynamodbv2.streamsadapter.StreamsWorkerFactory;
import com.amazonaws.services.kinesis.clientlibrary.interfaces.v2.IRecordProcessorFactory;
import com.amazonaws.services.kinesis.clientlibrary.lib.worker.InitialPositionInStream;
import com.amazonaws.services.kinesis.clientlibrary.lib.worker.KinesisClientLibConfiguration;
import com.amazonaws.services.kinesis.clientlibrary.lib.worker.Worker;
import software.amazon.awssdk.regions.Region;
import software.amazon.awssdk.services.s3.S3Client;
import java.util.Map;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class StreamsAdapter {
private static final String tableName = "tableName";
private static final String appName = "appName";
private static final String workerId = "workerId";
private static final AWSCredentialsProvider credentialsProvider = new InstanceProfileCredentialsProvider(true);
public static void main(String... args) {
// RecordProcessFactory
S3Client s3Client = S3Client.builder().region(Region.AP_NORTHEAST_1).build();
ShardReadWriteLock shardReadWriteLock = new ShardReadWriteLock();
IRecordProcessorFactory factory = new RecordProcessorFactory(s3Client, shardReadWriteLock);
// DynamoDB
AmazonDynamoDB dynamoDB = AmazonDynamoDBClientBuilder.standard().withRegion(Regions.AP_NORTHEAST_1).build();
String streamArn = dynamoDB.describeTable(tableName).getTable().getLatestStreamArn();
// DynamoDB Streams
AmazonDynamoDBStreams streams = AmazonDynamoDBStreamsClientBuilder.standard()
.withRegion(Regions.AP_NORTHEAST_1).build();
AmazonDynamoDBStreamsAdapterClient adapterClient = new AmazonDynamoDBStreamsAdapterClient(streams);
// KCL Configuration
KinesisClientLibConfiguration kclConfig = new KinesisClientLibConfiguration(appName, streamArn, credentialsProvider, workerId)
.withInitialPositionInStream(InitialPositionInStream.TRIM_HORIZON);
// CloudWatch
AmazonCloudWatch cloudWatch = AmazonCloudWatchClientBuilder.standard().withRegion(Regions.AP_NORTHEAST_1).build();
// KCL Worker
Worker worker = StreamsWorkerFactory.createDynamoDbStreamsWorker(factory, kclConfig, adapterClient, dynamoDB, cloudWatch);
System.out.println("Starting stream processing...");
ExecutorService es = Executors.newSingleThreadExecutor();
es.execute(worker);
try {
// Enable RecordProcessor for 5 minutes.
// Check for exception every 30 seconds.
boolean allSucceed = true;
for (int i = 0; i < 10; i++) {
Thread.sleep(30000);
if (shardReadWriteLock.existsFailure()) {
allSucceed = false;
break;
}
}
worker.startGracefulShutdown().get();
if (!allSucceed) {
throw new RuntimeException("Caught exception in processRecords().");
}
} catch (InterruptedException | ExecutionException ex) {
ex.printStackTrace();
throw new RuntimeException("Failed to process record of DynamoDB Streams via KCL.");
} finally {
es.shutdownNow();
}
System.out.println("Completed stream processing");
}
}
RecordProcessorFactory
import com.amazonaws.services.kinesis.clientlibrary.interfaces.v2.IRecordProcessor;
import com.amazonaws.services.kinesis.clientlibrary.interfaces.v2.IRecordProcessorFactory;
import software.amazon.awssdk.services.s3.S3Client;
public class RecordProcessorFactory implements IRecordProcessorFactory {
private S3Client s3Client;
private ShardReadWriteLock shardReadWriteLock;
public RecordProcessorFactory(S3Client s3Client, ShardReadWriteLock shardReadWriteLock) {
this.s3Client = s3Client;
this.shardReadWriteLock = shardReadWriteLock;
}
@Override
public IRecordProcessor createProcessor() {
return new RecordProcessor(s3Client, shardReadWriteLock);
}
}
RecordProcessor
- 分かりやすさのため、processRecords()は受け取ったストリームをS3にPUTするだけの処理にしています
- processRecords()で発生したExceptionとRuntimeExceptionはKCLによって握り潰されるため、全体の処理をExceptionで囲み、例外発生時はメインスレッドから渡されてきたShardReadWriteLockにステータスFAILUREを設定しています
- 一度processRecords()が失敗しても2回目以降呼ばれる可能性があるため、対象のシャードでExceptionが一度でも発生していれば、処理をそれ以上進めないためにスレッドを即座に終了させるようにしています
- processRecords()の冒頭
- シャットダウン時は必ずcheckpointを記録する必要があるため、processRecords()で例外が発生した際に、その時点で取得しているレコード情報を全てログに吐き出すようにしています
- 仕方なく手運用でリカバリを想定していますが、もっといい方法があれば教えてください
import com.amazonaws.services.dynamodbv2.streamsadapter.model.RecordAdapter;
import com.amazonaws.services.kinesis.clientlibrary.exceptions.InvalidStateException;
import com.amazonaws.services.kinesis.clientlibrary.exceptions.ShutdownException;
import com.amazonaws.services.kinesis.clientlibrary.interfaces.IRecordProcessorCheckpointer;
import com.amazonaws.services.kinesis.clientlibrary.interfaces.v2.IRecordProcessor;
import com.amazonaws.services.kinesis.clientlibrary.interfaces.v2.IShutdownNotificationAware;
import com.amazonaws.services.kinesis.clientlibrary.lib.worker.ShutdownReason;
import com.amazonaws.services.kinesis.clientlibrary.types.InitializationInput;
import com.amazonaws.services.kinesis.clientlibrary.types.ProcessRecordsInput;
import com.amazonaws.services.kinesis.clientlibrary.types.ShutdownInput;
import com.amazonaws.services.kinesis.model.Record;
import software.amazon.awssdk.awscore.exception.AwsServiceException;
import software.amazon.awssdk.core.exception.SdkClientException;
import software.amazon.awssdk.core.sync.RequestBody;
import software.amazon.awssdk.services.s3.S3Client;
import software.amazon.awssdk.services.s3.model.PutObjectRequest;
import java.util.Objects;
import java.util.Optional;
public class RecordProcessor implements IRecordProcessor, IShutdownNotificationAware {
private final String bucket = "bucket";
private final String objectKey = "objectKey";
private S3Client s3Client;
private ShardReadWriteLock shardReadWriteLock;
private String shardId;
public RecordProcessor(S3Client s3Client, ShardReadWriteLock shardReadWriteLock) {
this.s3Client = s3Client;
this.shardReadWriteLock = shardReadWriteLock;
}
@Override
public void initialize(InitializationInput initializationInput) {
shardId = initializationInput.getShardId();
}
@Override
public void processRecords(ProcessRecordsInput processRecordsInput) {
Optional<ShardReadWriteLock.ShardProcessStatus> status = shardReadWriteLock.read(shardId);
if (!Objects.isNull(status) && status.equals(ShardReadWriteLock.ShardProcessStatus.FAILURE)) {
throw new RuntimeException("Shard " + shardId + " have failed.");
}
shardReadWriteLock.write(shardId, ShardReadWriteLock.ShardProcessStatus.INITIALIZE);
try {
for (Record record : processRecordsInput.getRecords()) {
if (record instanceof RecordAdapter) {
com.amazonaws.services.dynamodbv2.model.Record streamRecord = ((RecordAdapter) record)
.getInternalObject();
if (!streamRecord.getEventName().equals("INSERT")) {
continue;
}
s3Client.putObject(PutObjectRequest.builder().bucket(bucket).key(objectKey).build(),
RequestBody.fromString(String.valueOf(streamRecord)));
}
}
shardReadWriteLock.write(shardId, ShardReadWriteLock.ShardProcessStatus.SUCCESS);
} catch (Exception ex) {
shardReadWriteLock.write(shardId, ShardReadWriteLock.ShardProcessStatus.FAILURE);
processRecordsInput.getRecords().forEach(s -> System.err.println(((RecordAdapter) s).getInternalObject()));
ex.printStackTrace();
throw new RuntimeException("Caught exception in process on shard " + shardId);
}
}
@Override
public void shutdown(ShutdownInput shutdownInput) {
if (shutdownInput.getShutdownReason() == ShutdownReason.TERMINATE) {
try {
shutdownInput.getCheckpointer().checkpoint();
} catch (InvalidStateException | ShutdownException ex) {
ex.printStackTrace();
}
}
}
@Override
public void shutdownRequested(IRecordProcessorCheckpointer checkpointer) {
try {
checkpointer.checkpoint();
} catch (InvalidStateException | ShutdownException ex) {
ex.printStackTrace();
}
}
}
ShardReadWriteLock
- マルチスレッドのデザインパターンであるReadWriteLockパターンを採用しています
- shardsProcessStatusはKeyがシャードID、ValueがShardProcessStatusのMapで、これの読み込み/書き込み時にLockをかけるように実装しています
- INITIALIZE: processRecords()の処理開始時に付与
- SUCCESS: processRecords()の処理が正常終了したときに付与
- FAILURE: processRecords()の処理で例外が発生したときに付与
import java.util.HashMap;
import java.util.Map;
import java.util.Optional;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
public class ShardReadWriteLock {
public enum ShardProcessStatus {
INITIALIZE,
SUCCESS,
FAILURE;
}
private Map<String, ShardProcessStatus> shardsProcessStatus = new HashMap<>();
private final ReadWriteLock lock = new ReentrantReadWriteLock();
private final Lock readLock = lock.readLock();
private final Lock writeLock = lock.writeLock();
public Optional<ShardProcessStatus> read(String shardId) {
readLock.lock();
try {
return Optional.ofNullable(shardsProcessStatus.get(shardId));
} finally {
readLock.unlock();
}
}
/**
* FAILUREステータスが存在するか全Shardをチェックする
*/
public boolean existsFailure() {
readLock.lock();
try {
boolean exists = false;
for (Map.Entry<String, ShardProcessStatus> entry : shardsProcessStatus.entrySet()) {
if (entry.getValue().equals(ShardProcessStatus.FAILURE)) {
exists = true;
break;
}
}
return exists;
} finally {
readLock.unlock();
}
}
public void write(String shardId, ShardProcessStatus status) {
writeLock.lock();
shardsProcessStatus.put(shardId, status);
writeLock.unlock();
}
}
まとめ
KCLでバッチ風に処理するのは非常に難しかったです。
外部のスレッドから各シャードの処理状況を監視することで、エラーを検知と処理中断をできるようにしました。
processRecords()がどのように呼ばれるのか、例外がどう扱われるのかを知るために、KCLの処理をシーケンス図にまとめました。
コンシューマアプリケーションをデーモンとして実行される方やKinesis Data Streamsをお使いになる方にも参考になればと思います。
課題としては、processRecords()の処理で例外が発生した際に、レコードをログに吐いて手運用するような実装になっている点です。
参考
- 完成したプログラム: DynamoDB ストリーム Kinesis Adapter
- awsdocs/aws-doc-sdk-examples
- [詳説] Kinesis Client Library for Java によるコンシューマアプリケーションの実装
変更
2020/09/15
ReadLockができていなかったので、ソースコードを修正
KCLの仕様を踏まえたコンシューマアプリケーションの実装のソースコードに修正を加えました。
ShardReadWriteLockクラスのRead Lockができていない実装になっていました。
また、それに伴い同クラスのread()メソッドを呼び出す、StreamsAdapterクラスとRecordProcessorクラスにも変更を加えています。