AWSのkinesisについて学んだ事をまとめます。
kinesisの概要やベストプラクティス、豆知識取得のためにどうぞ。
1 kinesisとは
AWS kinesisには大きく分けて3つの機能があります。
- Amazon Kinesis Data Streams
- Amazon Kinesis Data Firehose
どちらもコンピュータから送られてくるログやイベントデータ等の大量のデータを高速に別のサービスに転送するためのサービス。
違いや使い分けについてはコチラのサイトで詳しく解説されていました。
https://dev.classmethod.jp/cloud/aws/difference-between-kinesis-streams-and-kinesis-firehose/
一言で言うなら
Amazon Kinesis Data Streamsのほうが速い。
Amazon Kinesis Data Firehoseのほうが設定が少なくて実装が楽。
って感じです。 - Amazon Kinesis Data Analytics
コンピュータやAmazon Kinesis Data Streams、Amazon Kinesis Data Firehoseから送信されてくるデータをSQLを使って処理できるサービス。
今回はこのうちのAmazon Kinesis Data Streamsについて詳しく説明します。
2 Amazon Kinesis Data Streamsとは
最近、IOTが発達してセンサを通じて大量のデータを収集することができるようになってきました。この収集されたデータは一度保存され、解析してその後のマーケティング等に活かされますが、この収集したデータを保存する部分は一見簡単そうに見えますが、送られてくるデータが膨大なのでそれらを制御するためにはハードウェアの性能面で考えることが多く、実は非常に難しいらしいです。
これを解決してくれるのがAmazon Kinesis Data Streamsです。
Amazon Kinesis Data Streamsはセンサ等のコンピュータかから送られてくるデータを別のサービスまで届けるためのサービスです。
下の図はAmazon Kinesis Data Streamsの処理の流れを記載したものです。
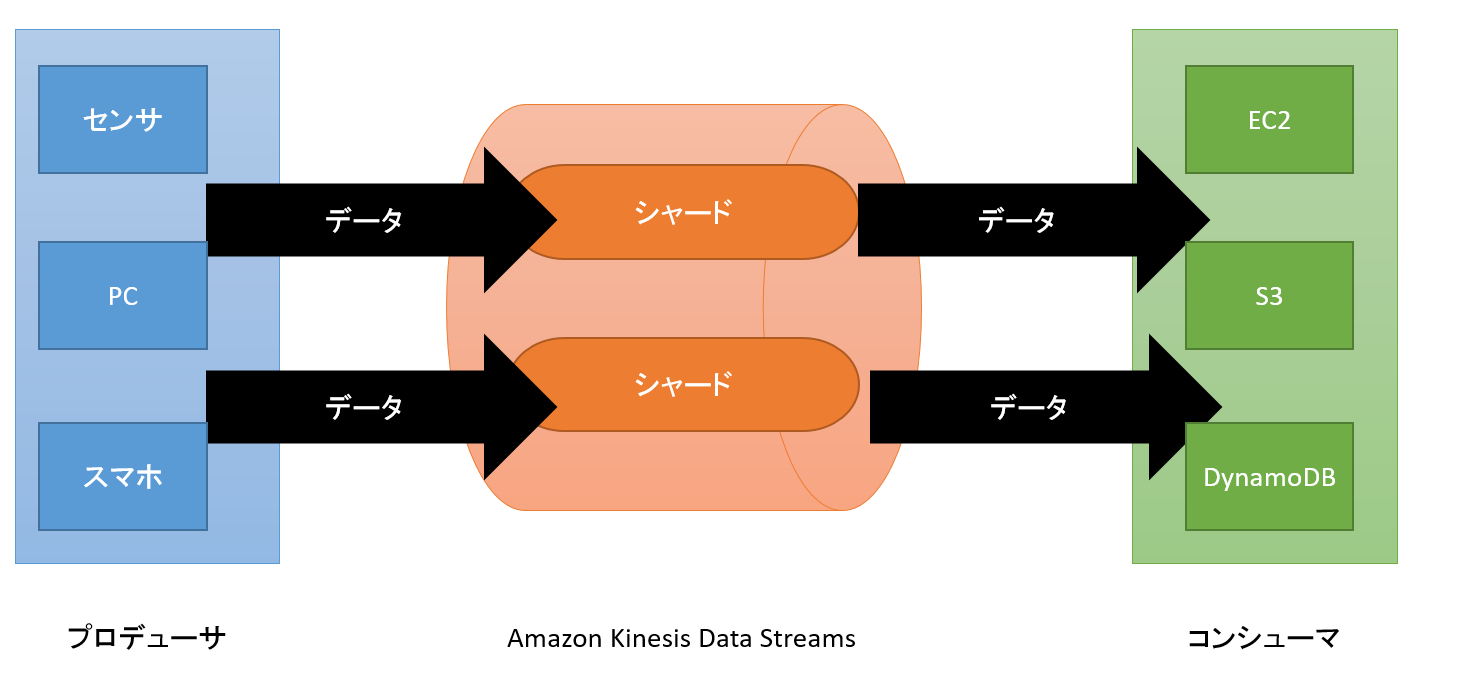
- プロデューサ
Amazon Kinesis Data Streamsにデータを送信するもの。
センサやPC,スマホ等が該当すします。 - Amazon Kinesis Data Streams
プロデューサからデータを受け取って管理し、コンシューマへ受け渡すもの。
シャードと呼ばれるもので構成されます。 - コンシューマ
Amazon Kinesis Data Streamsへデータを受け取るリクエストを送信してデータを取得し、処理を行う。
Amazon Kinesis Data Streamsに送信されたデータはすべてパーティションキーによってシャードに割り当てられ、シーケンス番号が振られます。そしてコンシューマからのリクエストに応じてシャードに入っているデータをコンシューマに送信します。
この役割を見るとキューと同じような働きをしていることが分かります。
確かにこの役割ならキューっぽいなと思いましたが、キューとは少し違う点があります。(AWSのキューサービスであるSQSとの比較になります)
- データの削除
キューからデータを取り出した際、処理が完了すれば取り出したデータは削除し、キューの先頭は別のデータになりますが、Amazon Kinesis Data Streamsでは一度取り出したデータも削除せずに保持し続けます。保持する期間は設定で変えられますがデフォルト24時間、最大7日です。
コンシューマがデータを取得する際に取得する範囲を指定して最新のデータを取得します。データを一時的に保管するキャッシュのような働きをしていることになります。
つまり、複数のアプリケーションで同じデータを参照したり時間がたってから再度同じデータを参照するということが可能になります。 - 拡張性
Amazon Kinesis Data Streamsでは送信されてくるデータの量に応じてシャードをauto Scallingすることが可能です。
ただし、シャードの数は一度に2倍にまでしか増やせません。
現在1つで4つに増やしたいなら1⇒2⇒4と段階を踏む必要があります。
他にも色々差はありますが、命令などの単純なメッセージを大量に、簡単に処理したいならSQS、センサなどのコンピュータから取得したデータを変換して高速に処理したいならAmazon Kinesis Data Streamsという使い分けになるかと思います。
3 CLIから動かしてみる
3.1 Amazon Kinesis Data Streams作成
今回はシャードを1つに指定して作成します。
aws kinesis create-stream --stream-name myKinesis --shard-count 1
作成が完了するまでに少し時間がかかります。
作成の進捗状況は下記のコマンドで確認できます。
aws kinesis describe-stream --stream-name myKinesis
{
"StreamDescription": {
"KeyId": null,
"EncryptionType": "NONE",
"StreamStatus": "CREATING",
"StreamName": "myKinesis",
"Shards": [],
"StreamARN": "arn:aws:kinesis:ap-northeast-1:[AWSアカウント名]:stream/myKinesis",
"EnhancedMonitoring": [
{
"ShardLevelMetrics": []
}
],
"StreamCreationTimestamp": 1535294220.0,
"RetentionPeriodHours": 24
}
}
StreamStatus": "CREATING
となっているところから作成中であることが分かります。これがACTIVEになれば使用可能です。
3.2 シャードにデータを送信
プロデューサの役割の部分をCLIから実行します。
aws kinesis put-record --stream-name myKinesis --partition-key 1 --data test1
aws kinesis put-record --stream-name myKinesis --partition-key 1 --data test2
aws kinesis put-record --stream-name myKinesis --partition-key 1 --data test3
aws kinesis put-record --stream-name myKinesis --partition-key 1 --data test4
aws kinesis put-record --stream-name myKinesis --partition-key 1 --data test5
aws kinesis put-record --stream-name myKinesis --partition-key 1 --data test6
1つでは面白くないので6つデータを送信しました。
今回はシャードは1つしかないのでパーティションIDは全て固定にしています。
3.3 シャードからデータを取得
Amazon Kinesis Data Streamsからデータを取り出すにはまずシャードからイテレータを取得し、そのイテレータを使用してデータを取得します。
まず、イテレータを取得するには下記のコマンドをたたきます。
aws kinesis get-shard-iterator --shard-id shardId-000000000000 --shard-iterator-type TRIM_HORIZON --stream-name myKinesis
{
"ShardIterator": "AAAAAAAAAAEzWKGdMB5IsMccYVqjI8Gc3Uscb8QEr16kvDkQLwP0ie9tXvxzFap+/RHYReSWMirhhkF5uAlGZB7y11zGYeXvfDM5J6xtUCO1KN//6byM9358Swjc7GgajNLTUeogmYvfc2Kv5tr8nMkH7jYSNX/72YeqPzIbg/paHrgJ4s0pq384c4Sm5pZ1CbqN1L+/cNR2DvNwPKoGfMUKXWvq5uTN"
}
- shard-id
3.1でシャードを作成した際に表示されるものです。 - shard-iterator-type
イテレータの取得方法(=取得するデータの選択)です。
今回はTRIM_HORIZONを指定しているので最も古いデータ、つまり最初に送信したデータを取得できるハズです。
| shard-iterator-type | データの選択方法 |
|---|---|
| AT_SEQUENCE_NUMBER | あるシーケンス番号 |
| AFTER_SEQUENCE_NUMBER | あるシーケンス番号の後 |
| TRIM_HORIZON | 最も古いレコード |
| LATEST | 最も新しいレコード |
| AT_TIMESTAMP | 指定したタイムスタンプ |
次に、取得したイテレータを使用してデータを取得します。
取得には先ほど取得したイテレータを指定します。
aws kinesis get-records --shard-iterator AAAAAAAAAAEzWKGdMB5IsMccYVqjI8Gc3Uscb8QEr16kvDkQLwP0ie9tXvxzFap+/RHYReSWMirhhkF5uAlGZB7y11zGYeXvfDM5J6xtUCO1KN//6byM9358Swjc7GgajNLTUeogmYvfc2Kv5tr8nMkH7jYSNX/72YeqPzIbg/paHrgJ4s0pq384c4Sm5pZ1CbqN1L+/cNR2DvNwPKoGfMUKXWvq5uTN
{
"Records": [
{
"Data": "dGVzdDE=",
"PartitionKey": "1",
"ApproximateArrivalTimestamp": 1535294570.285,
"SequenceNumber": "49587668589917956789172803442841175182217281049410404354"
},
{
"Data": "dGVzdDI=",
"PartitionKey": "1",
"ApproximateArrivalTimestamp": 1535294570.609,
"SequenceNumber": "49587668589917956789172803442842384108036895747304587266"
},
{
"Data": "dGVzdDM=",
"PartitionKey": "1",
"ApproximateArrivalTimestamp": 1535294570.946,
"SequenceNumber": "49587668589917956789172803442843593033856510376479293442"
},
{
"Data": "dGVzdDQ=",
"PartitionKey": "1",
"ApproximateArrivalTimestamp": 1535294571.296,
"SequenceNumber": "49587668589917956789172803442844801959676125005653999618"
},
{
"Data": "dGVzdDU=",
"PartitionKey": "1",
"ApproximateArrivalTimestamp": 1535294571.634,
"SequenceNumber": "49587668589917956789172803442846010885495739703548182530"
},
{
"Data": "dGVzdDY=",
"PartitionKey": "1",
"ApproximateArrivalTimestamp": 1535294571.974,
"SequenceNumber": "49587668589917956789172803442847219811315354332722888706"
}
],
"NextShardIterator": "AAAAAAAAAAEnpgqTc/Nrj4KalazIdRKsGWSm2TXpU5VF3oDdWYhGOUruuUAciH7Tp8blZaDo5IR2DcqnJJLg8ZK2lRvjpQYUs3w6NHp1JLUXYW1r23NmA302g9bs24uB/NVZiG1cn4gby4F4VAZF/R8S2TzpBQ1b8yM48MyQ1ciB0wv+cTr9WW/E1KIyYCnLEoCjVG5xvrqIapK+rtRceeaIBaohci6b",
"MillisBehindLatest": 0
}
Dataの部分が3.2で登録したtest1~test6です。
別の文字列が表示されているのはこの文字データがBase64でエンコードされているのにCLIではBase64でのデコードに対応していなくて文字化けしているからです。
https://www.base64decode.org/
でデコードしてみると上からtest1~test6が取得できていることが書くんできました。
イテレータの取得部分の他のshard-iterator-typeも試してみます。
3.3.1 AT_SEQUENCE_NUMBER
shard-iterator-typeでAT_SEQUENCE_NUMBERを選択した場合、
--starting-sequence-numberでシーケンス番号を指定する必要があります。今回は上記のコマンドで確認したtest6のシーケンス番号を使用しています。
aws kinesis get-shard-iterator \
> --shard-id shardId-000000000000 \
> --shard-iterator-type AT_SEQUENCE_NUMBER \
> --starting-sequence-number 49587668589917956789172803442847219811315354332722888706 \
> --stream-name myKinesis
aws kinesis get-records --shard-iterator AAAAAAAAAAFDecRqc9xwLrMgT3p5w6BYtQbgnZ9DT+6pbDPS5h+PC/rYsDnh18IgYsp1P1B5/7wSth2aNAYdlxzFTk/dOksSLqzDguhwQRReXSbx84HzenWEEtSVMbxhZhyQTBkWHiVDHI0cImB68VpfvD/t8XWB19eGTX/rhMEA95WPo9lYvfgDbtwEqvVo7C/BUjPrKOwdSvN7413zek3berarZGB/
{
"Records": [
{
"Data": "dGVzdDY=",
"PartitionKey": "1",
"ApproximateArrivalTimestamp": 1535294571.974,
"SequenceNumber": "49587668589917956789172803442847219811315354332722888706"
}
],
"NextShardIterator": "AAAAAAAAAAFdLvQy3u8K8lNN48+Tm98iigVQw+zryw3qiWsXNgYxYNc2pCkiUUL82FikKaVPXJu7VCfWRhIE9LSGq9IWgez/Y1fuNsE3n1PklGKLPviU2TVDQKNX0yd719mcxn1C3/HdHcwltKRVU5Vq+e/UhG/Jc/JKbgAGJX7PXOdQaVs/0vOtAFs7nonF66wGtzj0WSecKAIj04Gs94VCC+KZlOso",
"MillisBehindLatest": 0
}
取得できた「dGVzdDY=」をデコードするとtest6でしたのでOKです。
3.3.2 AFTER_SEQUENCE_NUMBER
指定したシーケンス番号より後ろのデータを取得します。
今回はtest5のシーケンスを指定しました。
aws kinesis get-shard-iterator \
> --shard-id shardId-000000000000 \
> --shard-iterator-type AFTER_SEQUENCE_NUMBER \
> --starting-sequence-number 49587668589917956789172803442846010885495739703548182530 \
> --stream-name myKinesis
{
"ShardIterator": "AAAAAAAAAAFT6p+3tJmPenVZGq7zSiMyDgLxKaaaVlKIirbJACeWyZEFMsGCgp0rZ4Bd0JJPg0Tq3vaFEgHKuco4hwD8ceEnIzmav+zD7j2apORI4SnrP/hMk4rcdJqBGeUI5NTvArWj4RZZdBq7Rim/InT1JFoHuJEj3hz/Q648yf0V9U/IhGFY0JeE7/q8/NbhWa/9VoawMzpJL1oifdqxs3u/9HFJ"
}
test6の1件のみ取得できました。どうやら「<=」ではなくて「<」のようですね。
試しにtest4のシーケンス番号で再取得したところ、test5とtest6が取得できました。
3.3.3 LATEST
aws kinesis get-shard-iterator \
> --shard-id shardId-000000000000 \
> --shard-iterator-type LATEST \
> --stream-name myKinesis
{
"ShardIterator": "AAAAAAAAAAGZ0WyWxGIfp5nt7S/u8/QMtMGUB572kQKQ0Z05DgmntfXxDBOzkEtx21Hwzon8hkeUskKzQc+VXB20sr6HptV7PoL42b24uPYvO7VLtNFN7PxQvkC4yDZ8MyIrtqZPvIb2J+c7x7kNQfDoOoZ+zWzqdF0RKqMFUv6XqKNsIu9dkgw8gVQkZds8i1TmnnSVogSsSHOKFF71RL+/mHG79jzW"
}
ws kinesis get-records --shard-iterator AAAAAAAAAAGZ0WyWxGIfp5nt7S/u8/QMtMGUB572kQKQ0Z05DgmntfXxDBOzkEtx21Hwzon8hkeUskKzQc+VXB20sr6HptV7PoL42b24uPYvO7VLtNFN7PxQvkC4yDZ8MyIrtqZPvIb2J+c7x7kNQfDoOoZ+zWzqdF0RKqMFUv6XqKNsIu9dkgw8gVQkZds8i1TmnnSVogSsSHOKFF71RL+/mHG79jzW
{
"Records": [],
"NextShardIterator": "AAAAAAAAAAFpTCYWQp1BHiAn31vL7VRa961mOzKcxrOWwRohkk1qWwxRwS31rJMOsrecMbNSDt+jUl4x/7rwknia0puoQN+1OlN/TP2zRLy9MxVYKwdEVvfa3AefvacSwJRIdUw55ThPjDbYHXcv5eoFrLYXuF8Tx7P/UXeCoxPgHnrjNKFm85yBqVRzEtQ/0oyXpozBtRle5ZRt0vugI4FaHEKmql8F",
"MillisBehindLatest": 0
}
・・・最も新しいデータを取得するのでtest6が返ってくると思っていましたが、空のレコードが返されました。
どうやらこれはイテレータ作成後に登録されたデータを取得できるようです。
再度test7のデータを登録してすぐに取得してみます。
aws kinesis put-record --stream-name myKinesis --partition-key 1 --data test
{
"ShardId": "shardId-000000000000",
"SequenceNumber": "49587668589917956789172803446554995300073657925510365186"
}
[ec2-user@ip-172-31-46-179 ~]$ aws kinesis get-records --shard-iterator AAAAAAAAAAHCuFdM4uajLL1mQfq3Q6rzzthfjeRIqZPCS8uGUGtQmG7XHPBonkLd84y/NH4qNkxNw4CmNr++atrAtNuizv/R0Og0vzNb6vFMFY4BZxVMYJMe+f/uDucPVgoc+Fe7949Zrdoz5UhPFcgivmhGTYHOAMyVQv53ZW6C1veudzrOmwZLWOiZJeMexLjLY3ZmG+LhBlM5jeN8cFTTUb
{
"Records": [
{
"Data": "dGVzdDc=",
"PartitionKey": "1",
"ApproximateArrivalTimestamp": 1535298005.259,
"SequenceNumber": "49587668589917956789172803446554995300073657925510365186"
}
],
"NextShardIterator": "AAAAAAAAAAFrcL8UAgxv0zr7GU3HTlmPJN7ct9yjiALTZUbTn9AwJbskyLw2AVODFjw+BhMcsapClDEx05JFTiAmpdyjwF6kwrtSGyUoEsTg7bpqBz8FVPF6qsfjAp9p9rrim8qSFbsg3M0wg14PPdZUw6+dIcZwS+sWnIiJeD73qc66o0X+DIJcXZWQFp4g+PLrHsGJYhXFHezTk9FnpAXwAT",
"MillisBehindLatest": 0
}
次に一番新しいputデータのみ取得なのかイテレータ作成後のputしたすべてのデータなのかを確かめるために再度test8,test9を登録して取得します。
aws kinesis put-record --stream-name myKinesis --partition-key 1 --data test8
{
"ShardId": "shardId-000000000000",
"SequenceNumber": "49587668589917956789172803446556204225893276128097861634"
}
[ec2-user@ip-172-31-46-179 ~]$ aws kinesis put-record --stream-name myKinesis --partition-key 1 --data test9
{
"ShardId": "shardId-000000000000",
"SequenceNumber": "49587668589917956789172803446557413151712890757272567810"
}
[ec2-user@ip-172-31-46-179 ~]$ aws kinesis get-records --shard-iterator AAAAAAAAAAHCuFdM4uajLL1mQfq3Q6rzzthfjeRIqZPCS8uGUGtQmG7XHPBonkLd84y/NH4qNkxNw4CmNr++atrAtNuizv/R0Og0vzNb6vFMFY4BZxVMYJMe+f/uDucPVgoc+Fe7949Zrdoz5UhPFcgivmhGTYHOAMyVQv53ZW6C1veudzrOmwZLWOiZJeMexLjLY3ZmG+LhBlM5jeN8cFTTUb
{
"Records": [
{
"Data": "dGVzdDc=",
"PartitionKey": "1",
"ApproximateArrivalTimestamp": 1535298005.259,
"SequenceNumber": "49587668589917956789172803446554995300073657925510365186"
},
{
"Data": "dGVzdDg=",
"PartitionKey": "1",
"ApproximateArrivalTimestamp": 1535298057.158,
"SequenceNumber": "49587668589917956789172803446556204225893276128097861634"
},
{
"Data": "dGVzdDk=",
"PartitionKey": "1",
"ApproximateArrivalTimestamp": 1535298057.511,
"SequenceNumber": "49587668589917956789172803446557413151712890757272567810"
}
],
"NextShardIterator": "AAAAAAAAAAFUdQEYAJlATCR29tR8KwFoR+g2E1Ob76fC9BYpvDTG36jTznu43K+Ih2gUGkCPqgXewV6l5pVusIqx66FmLdnodiD7Z9ApPWLIoKbR60tYDLAY89NIFS6wGR5+uBbXnWDSjPiPujW/2BSkHin6ejJ3349/jSIS8vIJnVec+rOlDom2Ju3t8oEbNq/kCmCNg8uJs720GZjDA1emHs",
"MillisBehindLatest": 0
}
test7,test8,test9の3つが取得できたことからイテレータ作成後登録されたすべてのデータを取得するようです。
3.3.4 AT_TIMESTAMP
最後にタイムスタンプを指定して取得する方法も検証します。
aws kinesis get-shard-iterator \
> --shard-id shardId-000000000000 \
> --shard-iterator-type AT_TIMESTAMP \
> --timestamp 1535298057.000 \
> --stream-name myKinesis
{
"ShardIterator": "AAAAAAAAAAFyDCXfppx0RgwhyjDQmpqDfac1AkAxTzp/6hO6MrUic+qVY40YqkPfB22UFxWzI1TkdIrHSDlTEEuvHtMsrFtncVMp38yC6o9DsjA8PSPzFvOtdtet1aU+qBLigMDTghhs3pV5n1gYk+mGcRz0I+h07rDGu6fniS9X6azY8jiU1f/XXihlMYXcTUn4wTT3Jny8onJVXRDcufCpfQK9czmV4bFvhfXBrdn9/qv6iWv6Eg=="
}
aws kinesis get-records --shard-iterator AAAAAAAAAAFyDCXfppx0RgwhyjDQmpqDfac1AkAxTzp/6hO6MrUic+qVY40YqkPfB22UFxWzI1TkdIrHSDlTEEuvHtMsrFtncVMp38yC6o9DsjA8PSPzFvOtdtet1aU+qBLigMDTghhs3pV5n1gYk+mGcRz0I+h07rDGu6fniS9X6azY8jiU1f/XXihlMYXcTUn4wTT3Jny8onJVXRDcufCpfQK9czmV4bFvhfXBrdn9/qv6iWv6Eg==
{
"Records": [
{
"Data": "dGVzdDg=",
"PartitionKey": "1",
"ApproximateArrivalTimestamp": 1535298057.158,
"SequenceNumber": "49587668589917956789172803446556204225893276128097861634"
},
{
"Data": "dGVzdDk=",
"PartitionKey": "1",
"ApproximateArrivalTimestamp": 1535298057.511,
"SequenceNumber": "49587668589917956789172803446557413151712890757272567810"
},
{
"Data": "dGVzdDEw",
"PartitionKey": "1",
"ApproximateArrivalTimestamp": 1535298159.77,
"SequenceNumber": "49587668589917956789172803446558622077532512395833901058"
}
],
"NextShardIterator": "AAAAAAAAAAHA3J8ih9fTSCchEetKnzqKeTXCK9b4RwE9zKMujqZMlGTvK7hps5FftFYQU+X07UEZkFkyGECq4h57BTGkr1gyuH38aCKJ/DnWkjtc3lkUQ65HD6Yt/bKhDmZ14J741Tw/Zz+p7bba+5oT3QS2REJy1chlKaJD4p/sHw0SfqOzc/rg3oj7sKjR121WNSAt0LR778S1h+mE+5vnV/igqZ7a",
"MillisBehindLatest": 0
}
タイムスタンプをtest8とtest9の間に指定しました。
結果としてtest8,9,10が取得できているので想定通りです。
ちなみに、test8のタイムスタンプ1535298057.158に対して1535298057.159でイテレータを取得したところ、test8も取得できてしまいました。
1535298057.168でも1535298057.268でも1535298057.500でもtest8は取得できてしまいました。
閾値がどこにあるのかはわかりませんが、少しくらいなら指定したタイムスタンプより前でも取得できてしまうようです。
4 ベストプラクティス
最後に、Amazon Kinesis Data Streamsを使用する上でのベストプラクティスを紹介します。
4.1 パーティションキー戦略
Amazon Kinesis Data Streamsでは複数のシャードを用意して処理を分散することができますが、
どのシャードを使用するのか決定するのはプロデューサが発行するパーティションキーです。
上記のCLIの例ではシャードに送信するデータのパーティションキーはすべて固定で1にしていました。
もしシャードを複数用意したとしてもこのような設定をしてしまうと結局すべてのデータが1つのシャードに集中してしまうことになります。
実際は固定値で設定せずにきちんとばらけるように設定する必要がありますが、分け方には2つの考え方があります。
ホットシャード回避のために広範囲にパーティションキーを確保する
パーティションキーに偏りがあり、データが集中してしまったシャードをホットシャードといいます。
このホットシャードの発生を防ぐためにパーティションキーを広範囲の値を持つようにする、タイムスタンプなどを使ってランダムなキーを生成するという工夫をする考え方
データに対応したシャードを設定
例えばこのセンサから取得したデータは全てこのシャードに送信するようにするなど、データをより有意義に使用できるようにパーティションキーを設定する方法。そのシャードに入っているデータがどこから取得したのかわかるのでその後のデータ分析がやりやすくなったりする。
4.2 適切なシャード数の設定
ストリームが処理できるデータ容量はシャードの数に比例します。なのでプロディーサが送信してくるデータの量やコンシューマが読み取るデータの量を考慮してシャード数を設定する必要があります。
シャードの1つ当たりのスペックは以下のように設定されています。
- 書き込み(プロデューサからデータを受け取る) 1MB/秒
- 読み込み(コンシューマがデータを読み取る) 2MB/秒
つまり、プロデューサが1秒間に10MBのデータを送ってくる場合はシャードは最低でも10個は用意しておく必要があります。
また、コンシューマが1秒に10MBのデータを読み込むならシャードは最低5個は用意する必要があるわけです。
予期せぬデータ量の増加に備えてシャードは余分に用意しておくことが推奨されています。
4.3 重複データの削除
プロデューサからストリームへのデータ送信は成功したけどストリームからプロデューサへの成功通知が送信できなかったりするとプロデューサは同じデータを再送しようとするのでストリームに同じデータが登録される可能性があります。
これを防ぐためにデータにプライマリキーを持たせてコンシューマで重複を削除するという手法が推奨されています。
4.4 プロデューサ・コンシューマの起動順序
ベストプラクティスからは少し離れてしまいますが、コンシューマがイテレータを取得する際の設定項目であるデータの取得範囲(shard-iterator-type)がLATESTである場合はコンシューマアプリケーションを起動してからプロデューサアプリケーションを起動する必要があります。
逆に。shard-iterator-typeがTRIM_HORIZONならば先にプロデューサを起動します。