はじめに
Kinesis Client Library(以下、KCL) は、AWS Kinesis Data Stream に流れるデータ(レコード)を受信して処理を行うコンシューマアプリケーションを実装するためのAWS謹製のライブラリです。
Kinesisのレコードを処理するには、
- Kinesisストリームからレコードを取得して処理するアプリケーション。EC2などの上で常駐させます。
- Kinesisストリームをイベントソースとする Lambda 関数。
のいずれかの方法がありますが、KCL は前者の場合に使用します。
KCL はKinesisストリームからレコードを取得し、レコードプロセッサ と呼ばれるレコードを処理するためのハンドラを呼び出します。
アプリケーションの開発者はこの レコードプロセッサ に処理を実装するだけで良く、レコードの取得、どのレコードまで処理したかの状態、Kinesisストリームのシャード増減を自動的に管理してくれます。
ただ、レコードプロセッサ がどのタイミングで呼び出されるのか、レコードプロセッサ がエラーを返したときにどのような挙動になるのか、と言ったことが分かりづらく、ここを誤るとKinesisストリームにレコードが滞留したり、レコードが意図せず破棄されてしまう可能性があります。
この記事では、AWS Kinesis Data Streamsの公式ガイド には明記されていない事項を補足しながら、KCLを使ったアプリケーションの実装方法を解説します。
なお、KCL は Java、JavaScript(Node.js)、Python、.NET、Ruby の各言語向けにライブラリが提供されていますが、この記事では Java 向けのライブラリ(1.x系 のインターフェースv2。詳細は後述)を扱います。
Kinesis Client Libraryとは
KCLの機能
レコードの取得
通常、Kinesisストリームからレコードを取得するには、対象のストリームからシャードを取得し、シャード内のレコードを走査するためのイテレータを取得し、イテレータをループする、と言ったステップが必要です。
(詳細は Kinesis Data Streams API および AWS SDK for Java を使用したコンシューマーの開発 参照)
KCL はこの手順を自動的に行い、レコードを取得してくれます。
レコードの処理位置の管理
Kinesisストリームはその名の通りストリームであるため、キューとは異なり取得したレコードを削除したりすることはできません。一定の時間が経過するまで、レコードはストリーム内に残り続けます。
そのため、アプリケーションがストリーム内のレコードをどこまで処理したかを覚えておかないと、アプリケーションを停止/再起動した場合などにストリーム内のレコードを最初からすべて処理しなおす(TRIM_HORIZON)、あるいはアプリケーション停止中に流入したレコードをすべて破棄する(LATEST)ことになってしまいます。
KCL はどのレコードまで処理したかを記録し、アプリケーションの停止/再起動時にはまだ処理していないレコードから処理を再開してくれます。
シャード増減への追従
Kinesisストリームをスケールさせるにはシャード数を増やしますが、前述のように自前でレコードの取得処理を実装すると、シャードが増えた(減った)ことを検知する仕組みも自前で実装しなければならなくなります。
KCL は、Kinesisストリームのシャードの増減を検知して、新たにOPENしたシャードの処理を自動的に開始してくれます。
シャードの並列処理
Kinesisストリームでは、同じパーティションキーを持つレコードは必ず同じシャードに流れることが保証されます。
(パーティションキーには、例えば「注文番号」のようなレコードの一意な識別子を設定します)
つまり、関連性のあるレコードが複数のシャードに散らばることはないので、各シャードは完全に独立して並列処理することができます。(と言うより、そうしないとシャードを増やす意味がありません)
KCL では、検知したシャードごとにそれぞれ別スレッドで並列処理してくれます。
マルチプロセスによる分散処理
KCL アプリケーションは、通常は1つのプロセスで対象のKinesisストリームのすべてのシャードを受け持ちますが、シャード数が大量になってくるとそれだけ並列度が上がり、1つのプロセスでは処理しきれなくなる可能性があります。
その場合は、同じKinesisストリームに対して、複数のKCLアプリケーション(のプロセス)を起動してプロセス間で負荷分散することができます。
KCL for Javaのバージョン
KCL for Java には、現在以下のバージョンがあります。
この記事で扱うのは、「モジュールバージョン 1.x のインターフェースバージョン v2」 です。
| モジュールバージョン | インターフェースバージョン | パッケージ | 備考 |
|---|---|---|---|
| 1.x [GitHub] | v1 | com.amazonaws.services.kinesis.clientlibrary.interfaces |
「オリジナルインターフェース」とも呼ぶ |
| 〃 | v2 | com.amazonaws.services.kinesis.clientlibrary.interfaces.v2 |
この記事で扱うバージョンはこれです |
| 2.x [GitHub] | - | software.amazon.kinesis |
拡張ファンアウトを利用するにはこのバージョンを利用する必要あり |
モジュールバージョン 1.x のインターフェースバージョン v1 と v2 の違いはわずかで、
- レコードプロセッサ のメソッドシグネチャが異なる。(v2 のほうが詳細な情報を受け取れる)
- KCLアプリケーションの停止時に、安全に レコードプロセッサ を終了させることができる。
の2点です。
モジュールバージョン 1.x と 2.x では、レコードプロセッサ を実装すると言う利用方法自体に大きな違いはないものの、APIは一新されており互換性はありません。
KCLの概念
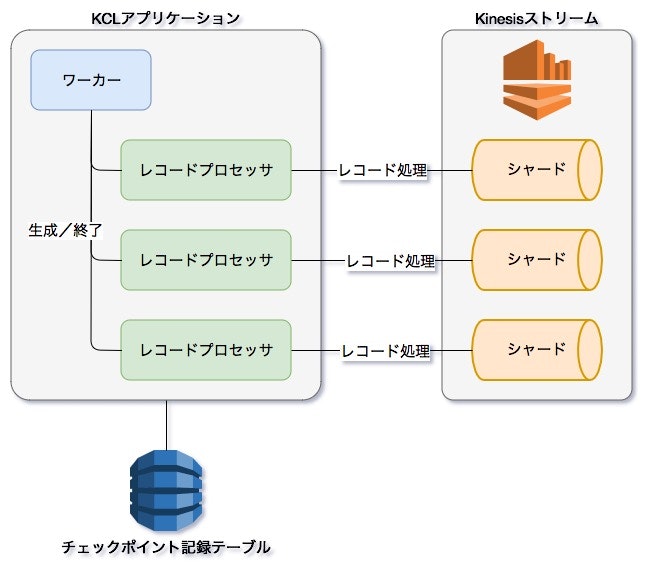
レコードプロセッサ
Kinesisストリームを流れるレコードを処理するためのハンドラです。
基底インターフェースで「初期化処理」「レコード処理」「終了処理」の3つのメソッドが規定されており、アプリケーション開発者はこの3つのメソッドを実装する必要があります。
レコードプロセッサ は、KCLアプリケーション内で Kinesisストリームのシャードと1対1で対応するようにインスタンス化され、各シャードを流れるレコードの処理を受け持ちます。
チェックポイント
Kinesisストリーム内(正確にはシャード内)のレコードをどこまで処理したかを示します。
チェックポイントは自動的には記録されず、アプリケーション開発者が レコードプロセッサ の中で適宜記録する必要があります。(チェックポイントを記録するためのコンポーネントを チェックポインター と呼びます)
チェックポイント は DynamoDB に記録されます。
KCLアプリケーションを実行すると、KCL によって自動的に DynamoDB にテーブルが作成されます。
ワーカー
Kinesisストリームのシャード数に応じて、レコードプロセッサのライフサイクル管理(生成/終了)を行います。
アプリケーション開発者は、必要なパラメタ(どのKinesisストリームを処理するのか、など)を与えて ワーカー を生成・起動する必要があります。
ワーカー はKCLアプリケーション内で1つだけ存在します。
KCLアプリケーションの実装
KCL を利用したアプリケーションを開発するには、以下のステップが必要です。
- レコードプロセッサ および レコードプロセッサファクトリ を実装する。
- ワーカー を生成し、起動する。
- (任意)ワーカー を安全に停止する。
サンプルコード
GitHub に サンプルコード(Java/Scala/Kotlin) を公開しています。
また、AWS公式からも サンプルコード(Java) が公開されています。
レコードプロセッサの実装
まずは Kinesisレコードを処理するための レコードプロセッサ を実装します。
なお、レコードプロセッサはスレッドセーフです。レコードプロセッサの各メソッドが複数のスレッドから呼び出されることはありません。
よって、レコードプロセッサはインスタンス変数として必要な情報を持つことができます。
-
インターフェース
com.amazonaws.services.kinesis.clientlibrary.interfaces.v2.IRecordProcessorを implements します。 -
初期処理メソッド
void initialize(InitializationInput)を実装します。- レコードの処理で必要となるリソースがあれば、ここで初期化しておきます。
- パラメタの
InitializationInputからは、このレコードプロセッサが受け持つシャードのIDなどを取得できるので、必要であればインスタンス変数で保持しておきます。
-
レコード処理メソッド
void processRecords(ProcessRecordsInput)を実装します。- Kinesisストリームから受信したレコードを処理します。
- パラメタの
ProcessRecordsInputから、受信したレコードのリストを取得できます。 - レコードの処理に成功したら、
ProcessRecordsInput#getCheckpointer()で取得できる チェックポインター を使ってチェックポイントを記録します。- チェックポイントは DynamoDB に記録されるため、高負荷時にはキャパシティ不足などによる例外が発生する可能性があります。チェックポイントを確実に記録するために例外発生時にはリトライするべきです。
- KCLアプリケーションを停止/再開した場合など、同じレコードが複数回処理される可能性があることを考慮する必要があります。つまり、レコードの処理は冪等になるようにするべきです。
-
終了処理メソッド
void shutdown(ShutdownInput)を実装します。- #processRecords() の処理が終わるまでこのメソッドは呼び出されないことに注意が必要です。
- 初期処理で確保したリソースなどを開放します。
-
ShutdownInput#getShutdownReason()で返される終了理由がTERMINATEの場合のにみ、チェックポイントを記録します。- チェックポイントは DynamoDB に記録されるため、高負荷時にはキャパシティ不足などによる例外が発生する可能性があります。チェックポイントを確実に記録するために例外発生時にはリトライするべきです。
public class ExampleRecordProcessor implements IRecordProcessor {
private final String tableName;
ExampleRecordProcessor(String tableName) {
this.tableName = tableName;
}
private String shardId;
private AmazonDynamoDB dynamoDB;
private Table table;
@Override
public void initialize(InitializationInput initializationInput) {
shardId = initializationInput.getShardId();
// Initialize any resources for #processRecords().
dynamoDB = AmazonDynamoDBClientBuilder.defaultClient();
table = new Table(dynamoDB, tableName);
}
@Override
public void processRecords(ProcessRecordsInput processRecordsInput) {
// Processing incoming records.
retry(() -> {
processRecordsInput.getRecords().forEach(record -> {
System.out.println(record);
});
});
// Record checkpoint if all incoming records processed successfully.
recordCheckpoint(processRecordsInput.getCheckpointer());
}
@Override
public void shutdown(ShutdownInput shutdownInput) {
// Record checkpoint at closing shard if shutdown reason is TERMINATE.
if (shutdownInput.getShutdownReason() == ShutdownReason.TERMINATE) {
recordCheckpoint(shutdownInput.getCheckpointer());
}
// Cleanup initialized resources.
Optional.ofNullable(dynamoDB).ifPresent(AmazonDynamoDB::shutdown);
}
private void recordCheckpoint(IRecordProcessorCheckpointer checkpointer) {
retry(() -> {
try {
checkpointer.checkpoint();
} catch (Throwable e) {
throw new RuntimeException("Record checkpoint failed.", e);
}
});
}
private void retry(Runnable f) {
try {
f.run();
} catch (Throwable e) {
System.out.println(String.format("An error occurred %s. That will be retry...", e.getMessage()));
try {
Thread.sleep(3000);
} catch (InterruptedException e2) {
e2.printStackTrace();
}
retry(f);
}
}
レコードプロセッサファクトリの実装
次にレコードプロセッサを生成するために使用する レコードプロセッサファクトリ を実装します。
ワーカー はこのファクトリを使って、レコードプロセッサを生成します。
-
インターフェース
com.amazonaws.services.kinesis.clientlibrary.interfaces.v2. IRecordProcessorFactoryをimplementsします。 -
レコードプロセッサ生成メソッド
IRecordProcessor createProcessor()を実装します。- 上記で実装した レコードプロセッサ のインスタンスを生成して返します。
public class ExampleRecordProcessorFactory implements IRecordProcessorFactory {
private final String tableName;
ExampleRecordProcessorFactory(String tableName) {
this.tableName = tableName;
}
@Override
public IRecordProcessor createProcessor() {
return new ExampleRecordProcessor(tableName);
}
}
ワーカーの生成と起動
最後にKCLアプリケーションのエントリーポイント(Mainクラス)から、ワーカー を生成して起動します。
-
ワーカー の生成には
com.amazonaws.services.kinesis.clientlibrary.lib.worker.Worker.Builderを使用します。- 上記で実装した レコードプロセッサファクトリ を渡します。
- このワーカーが対象とするKinesisストリームなどを指定します。
-
#build()でワーカーを生成します。
-
KCL によって自動的に作成される、チェックポイントを記録するための DynamoDBテーブル の読み取り/書き込みキャパシティは、デフォルトで
10になります。
変更したい場合はKinesisClientLibConfigurationで指定できます。 -
Worker#run()生成した ワーカー を起動します。
public class App {
public static void main(String... args) {
// Create a Worker.
final Worker worker = new Worker.Builder()
.recordProcessorFactory(
new ExampleRecordProcessorFactory("examples-table")
)
.config(
new KinesisClientLibConfiguration(
"kcl-java-example",
"kcl-sample",
DefaultAWSCredentialsProviderChain.getInstance(),
generateWorkerId()
).withRegionName("us-east-1")
.withInitialLeaseTableReadCapacity(1)
.withInitialLeaseTableWriteCapacity(1)
)
.build();
// Start the worker.
worker.run();
}
private static String generateWorkerId() {
try {
return InetAddress.getLocalHost().getCanonicalHostName() + ":" + UUID.randomUUID();
} catch (UnknownHostException e) {
throw new RuntimeException("Could not generate worker ID.", e);
}
}
}
(任意)ワーカーの安全な停止
起動した ワーカー を安全に停止(処理中にレコードがあれば、その処理が終わってチェックポイントを記録してから停止)するには、Worker#startGracefulShutdown() を呼び出します。
通常は Java VM のシャットダウンフック(Runtime#addShutdownHook())から呼び出すことで、KCLアプリケーションのJVMプロセスの終了時に ワーカー を安全に停止させることができます。
final Worker worker = ...;
// Shutdown worker gracefully using shutdown hook.
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
try {
worker.startGracefulShutdown().get();
} catch (Throwable e) {
e.printStackTrace();
}
}));
レコードプロセッサの安全な停止
ワーカー を安全に停止させる場合は、レコードプロセッサも安全に終了するように実装する必要があります。
-
レコードプロセッサ にインターフェース
com.amazonaws.services.kinesis.clientlibrary.interfaces.v2.IShutdownNotificationAwareを追加でimplementsします。 -
終了要求メソッド
void shutdownRequested(IRecordProcessorCheckpointer)を実装します。- #processRecords() の処理が終わるまでこのメソッドは呼び出されないことに注意が必要です。
- チェックポイントを記録します。
- このメソッドのあと、前述の終了処理メソッド
#shutdown()も呼び出されますが、終了理由がZOMBIEになるため、このメソッド内でチェックポイントを記録しなければなりません。 - チェックポイントは DynamoDB に記録されるため、高負荷時にはキャパシティ不足などによる例外が発生する可能性があります。チェックポイントを確実に記録するために例外発生時にはリトライするべきです。
- このメソッドのあと、前述の終了処理メソッド
public class ExampleRecordProcessor implements IRecordProcessor, IShutdownNotificationAware {
:
@Override
public void shutdownRequested(IRecordProcessorCheckpointer checkpointer) {
// Record checkpoint at graceful shutdown.
recordCheckpoint(checkpointer);
}
}
レコードプロセッサのライフサイクル
レコードプロセッサの状態遷移
- CosumerStatesのJavaDoc から引用。
+-------------------+
| Waiting on Parent | +------------------+
+----+ Shard | | Shutdown |
| | | +--------------------+ Notification |
| +----------+--------+ | Shutdown: | Requested |
| | Success | Requested +-+-------+--------+
| | | | |
| +------+-------------+ | | | Shutdown:
| | Initializing +-----+ | | Requested
| | | | | |
| | +-----+-------+ | |
| +---------+----------+ | | Shutdown: | +-----+-------------+
| | Success | | Terminated | | Shutdown |
| | | | Zombie | | Notification +-------------+
| +------+-------------+ | | | | Complete | |
| | Processing +--+ | | ++-----------+------+ |
| +---+ | | | | | |
| | | +----------+ | | | Shutdown: |
| | +------+-------------+ | \ / | Requested |
| | | | \/ +--------------------+
| | | | ||
| | Success | | || Shutdown:
| +----------+ | || Terminated
| | || Zombie
| | ||
| | ||
| | +---++--------------+
| | | Shutting Down |
| +-----------+ |
| | |
| +--------+----------+
| |
| | Shutdown:
| | All Reasons
| |
| |
| Shutdown: +--------+----------+
| All Reasons | Shutdown |
+-------------------------------------------------------+ Complete |
| |
+-------------------+
レコードプロセッサの各メソッドが呼び出されるタイミング
| 1.ワーカー起動時 | 2.レコード受信時 | 3.シャードCLOSE時(※1) | 4.シャードOPEN時(※1) | 5.ワーカーの安全な停止時 | |
|---|---|---|---|---|---|
IRecordProcessor#initialize() |
① リソースの確保など | - | - | ① リソースの確保など | - |
IRecordProcessor#processRecords() |
- | ① 受信レコードの処理 ② チェックポイントの記録 |
- | - | - |
IRecordProcessor#shutdown()(※2) |
- | - | ① reason=TERMINATE チェックポイントの記録 |
- | ② reason=ZOMBIE
|
IShutdownNotificationAware#shutdownRequested()(※2) |
- | - | - | - | ① チェックポイントの記録 |
- ※1 Kinesisストリームのシャード数を増減した場合、既存シャードがCLOSEされた後、新たにシャードがOPENされます。
つまり、既存シャードに対応していたレコードプロセッサの#shutdown()が呼ばれ、新しいシャードに対応するレコードプロセッサの#initialize()が呼ばれます。 - ※2
#processRecords()が実行中の場合、#shutdown()および#shutdownRequested()は実行中の#processRecords()の処理が終わるまで呼び出されません。
エラー処理
レコードプロセッサのエラーハンドリング
レコードプロセッサで実装する各メソッドから例外をスローした場合の挙動は以下の通りです。
|メソッド|例外スロー時の挙動|
|----|----|----|
|IRecordProcessor#initialize()|正常にリターンするまで繰り返し呼び出され続けます。|
|IRecordProcessor#processRecords()|エラーログが出力され、引数で渡された レコードはスキップ されます。|
|IRecordProcessor#shutdown()|正常にリターンするまで繰り返し呼び出され続けます。|
|IShutdownNotificationAware#shutdownRequested()|正常にリターンするまで繰り返し呼び出され続けます。|
レコードの処理でエラーになった場合にスキップしたくない場合
レコードプロセッサ のレコード処理(#processRecords())でエラーが発生した場合、KCL の基本的な考え方では当該レコードはスキップして、次のレコードに処理が進みます。
アプリケーションの要件でレコードをスキップさせたくない場合(レコードを必ず順序通りに処理しなければならない、など)は、KCL には仕組みが用意されていないため、独自に工夫して実装する必要があります。
-
#processRecords()でエラーが発生した場合に、リターンしたり例外をスローせずに、処理をリトライし続けるようにします。- エラーが一時的なもの(AWSの一時的な瞬断など)であれば、リトライによって自動的に回復されます。
- エラーが恒久的なもの(想定外のレコードなど)であれば、自動的には回復されずリトライし続けます。
-
リトライし続ける状態に陥った場合は、それ以上レコードが進まなくなる(レコードが滞留する)ので、アプリケーションを改修するなどして当該レコードを処理する必要があります。
-
リトライ状態になったKCLアプリケーションを停止する際、ワーカー が安全に停止するように実装されていると、当該レコードプロセッサは
#processRecords()でリトライし続けているために#shutdownRequested()および#shutdown()は呼び出されず、終了待ち状態になりますが、シャットダウンフックのタイムアウトによってJVMが強制的に終了します。
(つまり、当該レコードプロセッサはチェックポイントが記録されず、次回、エラーになったレコードから再処理されることになります)
KCLアプリケーションの運用
ロギング
KCL から出力されるログは、以下のロガーで制御できます。
| ロガー | 説明 |
|---|---|
com.amazonaws.services.kinesis.clientlibrary |
通常は INFO。KCLのデバッグログを出力したい場合は DEBUG。 |
com.amazonaws.services.kinesis.clientlibrary.lib.worker.Worker |
INFO以下にすると Sleeping... と言うログが出続けて邪魔なので、WARN にしておくと良い。 |
チェックポイントテーブルの管理
-
チェックポイントを記録するための DynamoDBテーブル の読み取り/書き込みキャパシティは、そのままでは初期値(デフォルト
10)固定になりますが、Kinesisストリームを流れるレコードが増えるにつれてシャードを増やしていくとチェックポイントテーブルへのアクセス頻度も多くなり、キャパシティが不足してくる可能性があります。
キャパシティが不足するとチェックポイントの記録でエラーが発生するようになるため、キャパシティを増やす必要があります。
キャパシティが不足するたびに手動でキャパシティを増やす運用とするか、オートスケールするようにしておきます。 -
チェックポイントテーブルは自動的には削除されないので、KCLアプリケーションを廃止したらチェックポイントテーブルを手動で削除する必要があります。
参考文献
-
AWS公式ガイド
- Java での Kinesis Client Library コンシューマーの開発・・・KCL for Javaの使い方の説明。
- 状態の追跡・・・チェックポイントテーブルの各項目の説明。
- リシャーディング、拡張、並列処理・・・Kinesisストリームのシャード数を変更した場合の挙動の説明。
- 重複レコードの処理 - コンシューマーの再試行・・・KCLアプリケーションで同一レコードが複数回処理される可能性があることの説明。
- Amazon Kinesis Data Streams の障害からの復旧・・・KCLアプリケーションのエラー処理の説明。
- Kinesis Client Library 2.x の拡張ファンアウトを使用して Java でコンシューマーを開発する・・・Kinesisの拡張ファンアウトを使う方法の説明。
-
(BDT403) Best Practices for Building Real-time Streaming Applications with Amazon Kinesis ・・・P15からKCLアプリケーションの実装上の注意点などの解説がある。