今回の目標
13で頓挫していた機械学習にリベンジします。
ここから本編
このシリーズでは以下の方法で機械学習を行っていました。
なおここでスコアとは、自分の駒の数から相手の駒の数を引いた数字のことです。
- 次のターンで自分のスコアが最大または2番目または3番目になるところへランダムで置く。
- たまたま勝てた試合のデータを集め、どんな状況でどんな手を選んだか学習する。
ここではスコアではなく、前回求めた評価値によって重みづけられたスコア(以降評価スコアと呼ぶ)を使い学習させたいと思います。求めた評価値が1handを前提とするものであるため1handしか行いません。
また、13以前の機械学習の反省点として挙がっていた、
- 未来の戦況を説明変数として使う
- ターン数と現在の戦況を説明変数とする
- 各箇所に置いた後の情報全てを説明変数として使う
- プレイヤー役にはランダムで打ち返してもらう
- 機械学習のパラメータは総当たりで調べる
のうち、ランダム以外を行いたいと思います。
ランダムを行わない理由として、いままでcsvファイルでのデータ保存を行っていなかったためコンピュータとプレイヤー役に分ける必要がありましたが、今はその必要がなくなり黒も白も同時に学習が進められるようになったためです。
ヘッダファイル
親クラスは今まで通りで変更ありません。
t_evaが前回求めた評価値、nhand_evacustomが今回の学習のため用意した関数です。historyは試合履歴を保存するものです。bw_scoreは試合後のスコアを保存します。
# ifndef osero_learn_h
# define osero_learn_h
# include <unordered_map>
# include <string>
# include "osero.h"
class osero_learn : public osero{
private:
const double t_eva[64] = {
1.0, -0.6, 0.6, 0.4, 0.4, 0.6, -0.6, 1.0,
-0.6, -0.8, 0.0, 0.0, 0.0, 0.0, -0.8, -0.6,
0.6, 0.0, 0.8, 0.6, 0.6, 0.8, 0.0, 0.6,
0.4, 0.0, 0.6, 0.0, 0.0, 0.6, 0.0, 0.4,
0.4, 0.0, 0.6, 0.0, 0.0, 0.6, 0.0, 0.4,
0.6, 0.0, 0.8, 0.6, 0.6, 0.8, 0.0, 0.6,
-0.6, -0.8, 0.0, 0.0, 0.0, 0.0, -0.8, -0.6,
1.0, -0.6, 0.6, 0.4, 0.4, 0.6, -0.6, 1.0
};
void nhand_evacustom(int * line, int * col);
void count_last(void);
double cal_evascore(BOARD * now, int turn);
public:
osero_learn();
~osero_learn();
void play(void);
int bw_score[2];
int turn_num;
std::unordered_map<std::string, double> history[60];
};
# endif
ソースファイル
count_last
試合結果を変数内に保存するだけです。
void osero_learn::count_last(void){
int black, white;
black = popcount(this -> bw[0]);
white = popcount(this -> bw[1]);
this -> bw_score[0] = black;
this -> bw_score[1] = white;
}
cal_evascore
その時の、調べたい側の評価スコアを計算します。
「1 - turn」をすることで、turnが1の時は0、0の時は1が得られ相手のターンを表せます。
double osero_learn::cal_evascore(BOARD * now, int turn){
int my = turn;
int opp = 1 - turn;
int i = 0;
double evascore = 0.0;
BOARD place = 1;
while (place){
if (place & now[my]){
evascore += this -> t_eva[i];
}else if (place & now[opp]){
evascore -= this -> t_eva[i];
}
i++;
place = place << 1;
}
return evascore;
}
nhand_evacustom
かなり長くなってしまいましたが、やっていることとしては以前の機械学習の時と大差ありません。
評価スコアが最大になる場所、2番目になる場所、3番目になる場所を探しその中からランダムに置く場所を選んでいます。
また、それぞれの評価スコアを保存し、ついでに相手の評価スコアやその時のターン数、実際にどこを選んだかといった情報もついでに保存します。
最後に、置ける場所が1か所しかなかった場合は何もしませんが、2か所以上であった場合はランダムでどこに置くか選びます(1か所も置けなかった場合、そもそもこの関数は呼ばれません)。
変数の説明をします。
- history ヘッダファイルにもあった、試合の履歴保存用の変数。
- turn_num 現在のターン数。
- i, j 行と列を表す。
- score 一時的な評価スコア保存変数。
- top_score, sec_score, thr_score それぞれ次のターンで自分の評価スコアが最大になる場所、2番目になる場所、3番目になる場所に置いた時の自分の評価スコア。
- opp_score それぞれ次のターンで自分の評価スコアが最大になる場所、2番目になる場所、3番目になる場所に置いた時の相手の評価スコア。
- line_ans, col_ans 次のターンで自分の評価スコアが最大になる場所、2番目になる場所、3番目になる場所の行と列を保存しておく配列。
- num 置ける場所がいくつ見つかったか。1、2、3のどれかが入り、3以上の場合は3となる。
- place 盤面をすべて見る用の変数。
- board_leaf 現在の盤面をコピーするための変数。
void osero_learn::nhand_evacustom(int * line, int * col){
int i = 0, j = 0;
double score = 0.0;
double top_score = -100, sec_score = top_score, thr_score = top_score;
double opp_score[3];
int line_ans[3], col_ans[3];
int num = 0;
BOARD place = 1;
BOARD board_leaf[2];
while (place){
if (this -> check(this -> bw, i, j, this -> turn)){
board_leaf[0] = this -> bw[0];
board_leaf[1] = this -> bw[1];
put(board_leaf, i, j, this -> turn);
score = this -> cal_evascore(board_leaf, INT(this -> turn));
if (score > top_score){
thr_score = sec_score;
sec_score = top_score;
top_score = score;
this -> history[this -> turn_num]["my_thr_score"] = thr_score;
this -> history[this -> turn_num]["my_sec_score"] = sec_score;
this -> history[this -> turn_num]["my_top_score"] = top_score;
opp_score[2] = opp_score[1];
opp_score[1] = opp_score[0];
opp_score[0] = cal_evascore(board_leaf, INT(!(this -> turn)));
this -> history[this -> turn_num]["opp_thr_score"] = opp_score[2];
this -> history[this -> turn_num]["opp_sec_score"] = opp_score[1];
this -> history[this -> turn_num]["opp_top_score"] = opp_score[0];
line_ans[2] = line_ans[1];
col_ans[2] = col_ans[1];
line_ans[1] = line_ans[0];
col_ans[1] = col_ans[0];
line_ans[0] = i;
col_ans[0] = j;
num = 1;
}else if (score > sec_score){
thr_score = sec_score;
sec_score = score;
this -> history[this -> turn_num]["my_thr_score"] = thr_score;
this -> history[this -> turn_num]["my_sec_score"] = sec_score;
opp_score[2] = opp_score[1];
opp_score[1] = cal_evascore(board_leaf, INT(!(this -> turn)));
this -> history[this -> turn_num]["opp_thr_score"] = opp_score[2];
this -> history[this -> turn_num]["opp_sec_score"] = opp_score[1];
line_ans[2] = line_ans[1];
col_ans[2] = col_ans[1];
line_ans[1] = i;
col_ans[1] = j;
num = 2;
}else if (score > thr_score){
thr_score = score;
this -> history[this -> turn_num]["my_thr_score"] = thr_score;
opp_score[2] = cal_evascore(board_leaf, INT(!(this -> turn)));
this -> history[this -> turn_num]["opp_thr_score"] = opp_score[2];
line_ans[2] = i;
col_ans[2] = j;
num = 3;
}
}
i++;
if (i == 8) i = 0, j++;
place = place << 1;
}
this -> history[this -> turn_num]["put_place"] = 0;
if (num == 1) {
;
}else{
int put_place = rand() % num;
this -> history[this -> turn_num]["put_place"] = put_place;
line_ans[0] = line_ans[put_place];
col_ans[0] = col_ans[put_place];
}
this -> history[this -> turn_num]["num"] = num;
*line = line_ans[0];
*col = col_ans[0];
}
play
今までのプログラムとほぼ同じです。
現在のターンやその時の各人のスコアを記録しています。
void osero_learn::play(void){
bool can = true, old_can = true;
int line, col;
srand(this -> srand_num);
// this -> printb();
this -> turn_num = 0;
while((can = this -> check_all()) || old_can){
if (can){
this -> history[turn_num]["turn"] = INT(this -> turn);
this -> history[turn_num]["my_score"]
= this -> cal_evascore(this -> bw, INT(this -> turn));
this -> history[turn_num]["opp_score"]
= this -> cal_evascore(this -> bw, INT(!(this -> turn)));
this -> nhand_evacustom(&line, &col);
this -> put(this -> bw, line, col, this -> turn);
// this -> printb();
turn_num++;
}
this -> turn = !(this -> turn);
old_can = can;
}
this -> count_last();
}
実行ファイル
短いので一気に載せます。
一万回試合を行い、それぞれの履歴をcsvファイルに出力しているだけです。
# include <string>
# include "osero_learn.h"
const int PLAY_NUM = 10000;
int main(void){
int i, j;
osero_learn * run = new osero_learn();
FILE * datap;
std::string data;
datap = fopen("data.csv", "w");
data = "turn_num,turn,num,put_place,my_score,opp_score,";
data += "my_top_score,my_sec_score,my_thr_score,";
data += "opp_top_score,opp_sec_score,opp_thr_score,";
data += "last_black_score,last_white_score";
fprintf(datap, "%s\n", data.c_str());
for (i = 0; i < PLAY_NUM; i++){
run -> srand_num = i;
run -> reset();
run -> play();
for (j = 0; j < run -> turn_num; j++){
fprintf(
datap,
"%d,%d,%d,%d,%lf,%lf,%lf,%lf,%lf,%lf,%lf,%lf,%d,%d\n",
j,
INT(run -> history[j]["turn"]),
INT(run -> history[j]["num"]),
INT(run -> history[j]["put_place"]),
run -> history[j]["my_score"],
run -> history[j]["opp_score"],
run -> history[j]["my_top_score"],
run -> history[j]["my_sec_score"],
run -> history[j]["my_thr_score"],
run -> history[j]["opp_top_score"],
run -> history[j]["opp_sec_score"],
run -> history[j]["opp_thr_score"],
run -> bw_score[0],
run -> bw_score[1]
);
}
}
delete run;
fclose(datap);
return 0;
}
機械学習
機械学習のパラメータ総当たりで実験するため、以下のプログラムを作成しました。
拡張子をpyとしていますが、ipynbを使いました。
まず3手以上見つかったデータを集め、黒が勝った試合のうち黒のターン、白が勝った試合のうち白のターンをそれぞれdf_bとdf_wに入れています。
import pandas as pd
df = pd.read_csv("data.csv")
df = df.query("num == 3")
df_b = df.query("turn == 0")
df_b = df_b.query("last_black_score > last_white_score")
df_w = df.query("turn == 1")
df_w = df_b.query("last_white_score > last_black_score")
その後、まず黒の学習用データを整えます。
turn(今どちらのターンなのか)、num(選べる場所の数)、put_place(最終的に選んだ場所)、last_black_score(最終的な黒の駒数)、last_white_score(最終的な白の駒数)は学習に関係ない、またはその時点では知りえない情報なので説明変数から省きます。
そして正解データをput_placeとし、訓練用データとテスト用データに分けました。
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
import numpy as np
x = df_b.drop(["turn", "num", "put_place", "last_black_score", "last_white_score"], axis=1)
y = df_b["put_place"]
x_train, x_test, y_train, y_test = train_test_split(
x,
y,
test_size=0.3,
random_state=0
)
そして総当たりで調べるため、以下のプログラムを書きました。
with open("learn_data_black.csv", "w") as file:
file.write("criterion,splitter,max_features,max_depth,min_samples_split,")
file.write("min_samples_leaf,max_leaf_nodes,train_score,test_score\n")
for criterion in ["entropy", "gini"]:
for splitter in ["best", "random"]:
for max_features in [i for i in range(0, 9 + 1)]:
for max_depth in [i for i in range(1, 41)]:
for min_samples_split in np.arange(0.001, 0.01, 0.001):
for min_samples_leaf in [i for i in range(1, 101)]:
for max_leaf_nodes in [i for i in range(2, 501)]:
if max_features == 0:
max_features = None
model = DecisionTreeClassifier(\
criterion=criterion,
splitter=splitter,
max_features=max_features,
max_depth=max_depth,
min_samples_split=min_samples_split,
min_samples_leaf=min_samples_leaf,
max_leaf_nodes=max_leaf_nodes,
random_state=0
)
model.fit(x_train, y_train)
train_score = model.score(x_train, y_train)
test_score = model.score(x_test, y_test)
file.write("%s,%s," % (criterion, splitter))
if max_features:
file.write("%d," % max_features)
else:
file.write("None,")
file.write(\
"%d,%f,%d,%d,%f,%f\n" % (\
max_depth,
min_samples_split,
min_samples_leaf,
max_leaf_nodes,
train_score,
test_score
)
)
が、さすがに2x2x10x40x10x100x499の約8億回学習は無謀でしたのでまずは各パラメータごとに調べることにします。
criterion
random_stateは0で、これとcriterion以外のパラメータは全てデフォルト値で学習させます。
for criterion in ["entropy", "gini"]:
model = DecisionTreeClassifier(criterion=criterion, random_state=0)
model.fit(x_train, y_train)
print("%s:" % criterion)
print("train score:\t%f" % model.score(x_train, y_train))
print("test score:\t%f" % model.score(x_test, y_test))
実行結果。
entropy:
train score: 0.831784
test score: 0.341225
gini:
train score: 0.831784
test score: 0.344908
以前と同様、あまり変わらない結果に。
giniの方が若干高い数値でした。
とはいえ約0.33という結果なのでほぼ学習していないですね。
splitter
for splitter in ["best", "random"]:
model = DecisionTreeClassifier(splitter=splitter, random_state=0)
model.fit(x_train, y_train)
print("%s:" % splitter)
print("train score:\t%f" % model.score(x_train, y_train))
print("test score:\t%f" % model.score(x_test, y_test))
best:
train score: 0.831784
test score: 0.344908
random:
train score: 0.831784
test score: 0.340056
こちらもあまり変わらず、わずかにbestが勝る結果でした。
あまり学習していない結果も変わらず。
max_features
plot関数を定義したうえで学習させました。
import matplotlib.pyplot as plt
def plot(x, y_train, y_test, xlabel, ylabel, title, save_dir):
fig = plt.figure(figsize=(10, 10))
plt.plot(x, y_train, label="train score")
plt.plot(x, y_test, label="test score")
plt.legend()
plt.xlabel(xlabel)
plt.ylabel(ylabel)
plt.title(title)
plt.plot()
plt.savefig(save_dir % title)
plt.clf()
plt.close()
x_data = [i for i in range(9 + 1)]
y_train_data = []
y_test_data = []
for max_features in x_data:
if max_features:
pass
else:
max_features = None
model = DecisionTreeClassifier(max_features=max_features, random_state=0)
model.fit(x_train, y_train)
y_train_data.append(model.score(x_train, y_train))
y_test_data.append(model.score(x_test, y_test))
plot(
x_data,
y_train_data,
y_test_data,
"max_features",
"accuracy",
"accuracy for each max_features",
"fig/%s"
)
学習結果。

まさかの横ばい。
さらに、どの数値においても正解率0.33程度。
max_depth
これ以降のプログラムは、上のmax_featuresで使用したものと同様なので結果のみ載せます。

トレーニングデータでの正解率は向上しているものの、テストデータの方はさっぱり。
途中から正解率が一定になっているのは以前も予測した通り「これ以上潜っても意味のない点」が存在すると考えました。
min_samples_split
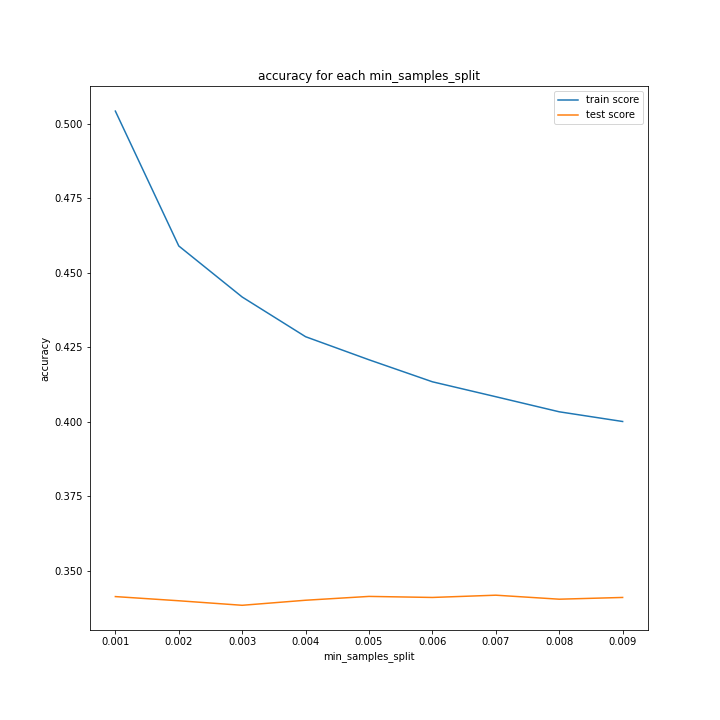
min_samples_leaf

max_leaf_nodes

まとめ
結局どんなパラメータでも正解率0.33を抜け出せないので、そもそも方針自体が間違っているのではないかと考えました。
違う方法での学習を考えてみた方がよさそうです。
フルバージョン
24フォルダに入っています。
data.csv(対戦データ)は重すぎて入りませんでした。
次回は
違うアプローチで機械学習を行おうと思います。