更新履歴
2021/9/25:Competitionの結果が出たので、結果を追記しました。
2021/9/25:Ruleの内容に誤解があったため修正しました。
初めに
この記事は、2021/6/17~2021/9/4に開催された世界で初めてとなる Data-Centric AI
Competition に参加した際に実施したことを共有するために書いています。
Data-Centricとは、Stanford大学の Andrew Ng先生が提唱している「モデルを改善するためにどのようにデータ(入力xまたはラベルy)を改善するか」に関するアプローチ手法を指します1。本アプローチに関する詳細な説明は注釈2等を参照ください。
今回の Competition では、モデルやモデルのハイパーパラメータは固定されており、全ての参加者が同じモデルを利用することがルールとして決められていました。そのため、参加者が出来るのは与えられたデータに修正を加えることだけです。Kaggle や Signate等に参加した際に実施するようなモデルの改善(利用するアルゴリズムやロスの変更/改造等)は出来ないため、今までのものとは違う新しい Competition となりました。
次の章から、Competitionのルール及びデータ、私が実施したことをコードと共に解説していきたいと思います。
データ
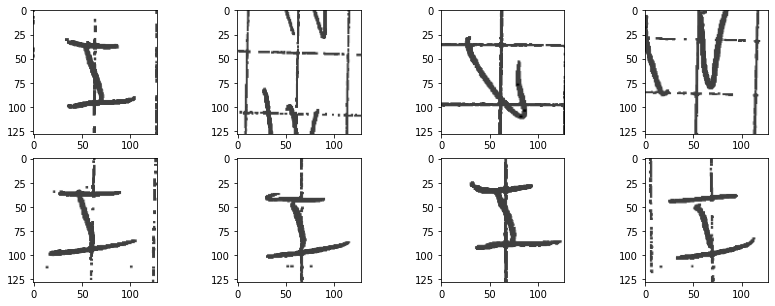
本Competitonでは、主催者である DeepLearning.AI3 及び LANDING.AI4 が用意した新しいデータセットである Roman MNIST を使用しました。ラベルは、i, ii, iii, iv, v, vi, vii, viii, ix, x の10個です。以下がサンプルイメージです。

中には、ノイズが混じっていたり、明らかにラベルミスの画像も存在しており、これらに対処していくことが必要となっていました。ノイズのサンプルイメージは以下の通りです。

また、ラベルミスであったり、識別不能な(どのラベルか正確に判断できない)サンプルイメージは以下の通りです。以下は、左上から右下にかけて順番に i, ii, ... というラベルが付与されていましたが、 iv のラベルに v が入っていたりします。

ルール
今回は新しい形式ではありましたが、複雑なルールではなかったので、意外とすぐに Submit までのパイプラインを作成できた印象です。ルールは大きく以下の5つでした。
- 学習に利用されるアルゴリズムは ResNet50。その他のハイパーパラメータも全て固定。画像の入力サイズは32×32で固定(全画像リサイズされる)。
- 学習に利用するデータは「Train」と「Val」に分けて、Zip形式にして提出。
- 提出回数制限は5回/週まで。
- 画像の枚数は 合計10,000枚まで5。
- 利用できる CodaLab6アカウントは1つ / Team。
少し詳細を記入します。提出する Zipファイルの階層構造は、以下の通りし、Train 配下と Val 配下の画像を合計して 10,000枚以下にします。Train と Val の比率を何対何にするかも参加者が決めないといけません。Submission というフォルダ名は何でもOKです。
Submission/
┗ Submission/
┗ Train/
┠ i/
┃┠ ファイル1
┃┠ ファイル2
┃ :
┠ ii
:
┗ Val/
┠ 以下、Trainと同じ
提出は、CodaLab を利用して実施しました。まずは CodaLab に Zipファイルをアップロードし、その後に主催者側から提供された提出用コードをいくつか実行する流れです。このコードを実行することによって ResNet50 による学習と、ベストモデルを使ったテストデータでの精度評価が実行されます。Submission には、提出名+名前+URL を説明として付与することが必要だったため、私の場合は、Submission_attempt10 + Takashi Tamura + LinkedInのURL のようにしていました。企業として参加しているケースもあったようで、その場合は企業URL を利用していたようです。
テストデータでの評価が完了すると、基本的には毎週月曜日に Leaderboard に Submit した情報が掲載されます。ここでの順位が全てのテストデータでの精度評価結果(最終評価結果)を表しています。
本Competitionは、精度とイノベーティブの2つのカテゴリで最終評価が行われます。それぞれの上位3名が Andrew Ng先生が主催するイベントに招待されます。賞金はありません。
分析に利用した環境
普段から慣れている Kaggle の環境を利用しました。CycleGan を利用したかったので GPU が必須だったからです。Competition のデータを Kaggle のデータセットにアップロードし、Kaggle の Notebook でコーディングをしていきました。
実施したこと及び結果
今回はデータ改善のために大きく4つのことを実施しました。基本的な方針は、分かっている画像のパターン(ノイズ等)を Data Augmentation によって再現し、全てのラベルに均等にそれらのデータを振り分けることです。これら以外にも出来ることはたくさんありましたが、参加したのがコンペ終了3週間前ぐらいだったので、時間の関係上出来ませんでした。
例えば、中にはデータを自分で書いて増やした参加者がいたようでした。確かにデータの中にはプログラムで再現するのが難しいものがありました。私もこの発想はあったのですが、プログラムで出来ないことをしたくなかったので実施していません。
また、手元で ResNet50 を学習させて、その傾向を見るということもしていません。本来は CodaLab から提出した際に混同行列ぐらい出てほしかったのですが、Accuracy しか分からない仕様になっていたので、どのラベルをどれぐらい間違えていたかを知るためには手元で ResNet50 を学習させて計測する必要がありました。これはしたかったのですが、時間の都合上諦めました。
実施したこと
- ミスラベルの修正と識別不能データの除外
- 画像結合(例:i + v → iv)
- Data Augmentation(Albumentation, 自作関数, CycleGan)
- Train : Val 及び Clean data : Noise data の比率調整
①ミスラベルの修正と識別不能データの除外
これは単純に実データを見ながら手作業で実施しました。この際に、Clean と Noise の2カテゴリにデータを分けました。データ数は以下の通りです。差分は混ざっていた識別不能なデータ数です。
| ラベル | 修正/除外前 | 修正/除外後(Clean) | 修正/除外後(Noise) |
|---|---|---|---|
| i | 343 | 272 | 47 |
| ii | 238 | 219 | 7 |
| iii | 265 | 211 | 21 |
| iv | 365 | 322 | 15 |
| v | 315 | 273 | 5 |
| vi | 279 | 249 | 15 |
| vii | 263 | 241 | 6 |
| viii | 270 | 242 | 3 |
| ix | 282 | 248 | 4 |
| x | 260 | 233 | 9 |
この段階で、ノイズには大きく3つのパターンがあると分かったのですが、ノイズデータについてはクラスアンバランスで、ラベルによっては3パターンの内1つのパターンのノイズしかないという状況でした。以下にノイズの例を示します。
1つ目:Dot Noise 数字が部分的に消えており点々になっている。

2つ目:Line Noise 画像に線上のノイズがはいっている。
3つ目:Background Noise 背景に大きくノイズがはいっている。

②画像結合(例:i + v → iv)
次の Augmentation のところで改めて整理しますが、例えば、ラベル i は上下左右反転によって簡単にデータ数を増やすことが出来ます。しかし、vii や viii は上下左右反転が出来ないため、他の手段でデータを増やす必要がありました。そのため、v と ii の画像それぞれから数字の部分だけを抜き出し、画像を結合することでデータ拡張を行いました。以下が数字の部分だけを抜き出すコードです。
def get_object(path):
def sum_with_axis(img, axis):
img_sum = img.sum(axis)
_min = np.where(img_sum != 0)[0][0] - 1
_min = 0 if _min < 0 else _min
_max = len(img_sum) - np.where(img_sum[::-1] != 0)[0][0] - 1
return _min, _max
img_rgb = cv2.imread(path, cv2.IMREAD_COLOR)
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)
_, img_bin = cv2.threshold(img_gray, 50, 255, cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)
img_bin = cv2.medianBlur(img_bin, 3)
min_x, max_x = sum_with_axis(img_bin, 0)
min_y, max_y = sum_with_axis(img_bin, 1)
return img_rgb[min_y:max_y,min_x:max_x]
この関数は、画像のパスを受け取り、画像に写っている数字だけを切り出します。ただし、実装を簡単にするため、画像中にノイズが含まれていないことが前提です。sum_with_axis のところでは、単純に二値化後画像を縦か横に合計し、配列の左から見て 0 と 1 の切り替わる場所(_min)と、配列の右から見て 0 と 1 が切り替わる場所(_max)を抽出しています7。0 が何も写っていないことを、1 が何かが写っていることを表しているので、そこを切り出すことで数字の部分だけにしています。
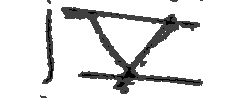
また、この後の画像結合処理には、確率的に単純な結合をするか、間をあけて結合するかを選ぶようにしました。学習データとして提供された画像の中にはなかったのですが、テストデータの例として別途提供されていたデータの中には以下のように i と v の間の距離が遠い画像があったからです。

これは 一般的に利用される Albumentation等の Data Augmentation ライブラリでは実現が難しいため、画像結合の際に、間の距離をあける処理を入れました。これに加え、i と v の上下に横線が引かれているパターンも実装しました。
最終的には、横線を入れていない画像(左)と、横線を入れた画像(中央)と間をあけない画像(右)の3パターンのどれかが作成される仕様にしました。


③Data Augmentation(Albumentation, 自作関数, CycleGan)
②で実装したデータ結合も含めて、以下に実施した Data Augmentation を整理します。
| # | Data Augmentation | 内容 | Clean/ Noise |
対象ラベル |
|---|---|---|---|---|
| 1 | 上下反転 | 上下の反転 | C/N | ix, x |
| 2 | 左右反転 | 左右の反転 | C/N | v |
| 3 | 上下左右反転 | 上下左右の反転 | C/N | i, ii, iii, x |
| 4 | 画像移動/回転等 | AlbumentationのShiftScaleRotate適応 | C/N | ALL |
| 5 | 画像結合 | ②で説明した通り | C | i + i ii + i i + ii v + i v + ii v + iii vi + i vi + ii i + v i + x |
| 6 | 黒の縦/横線追加 | ノイズパターン2つ目(Line Noise)にあたる黒の線追加 | C/N | ALL |
| 7 | 白の横線追加 | ノイズパターン1つ目(Dot Noise)にあたる数字の点々化 | C/N | ALL |
| 8 | ノイズ追加(小) | AlbumentationのCoarseDropout適応 | C/N | ALL |
| 9 | ノイズ追加(大) | 画像の端(上下左右)のどこか1か所以上に数十ピクセルのノイズを配置 | C/N | ALL |
| 10 | CycleGanによる点々ノイズ化 | Clean画像 ⇔ Dot Noise画像をCycleGanで学習 | C ⇒ N | ALL |
| 11 | CycleGanによる背景ノイズ追加 | Clean画像 ⇔ Background Noise画像をCycleGanで学習 | C ⇒ N | ALL |
ここからいくつかの番号について実装を説明します。まずは6と7です。以下にコードを示します。これは単純に黒線を引く関数(add_black_line)と、白線を引く関数(add_white_line)です。白線を引くというのは、つまり数字の黒の部分を消すことを意味しており、数字が点々のようになることを狙っています。実際は、6だけ適応、7だけ適応、6と7両方適応の3パターンを実施しています。
def add_black_line(img, line_width=2, add_x=True, add_y=True):
img = copy.deepcopy(img)
h, w = img.shape[:2]
# 何本の線を引くかを決定する(1 or 2本)
n_x = random.choices([1,2], k=1, weights=[0.7,0.3])[0]
n_y = random.choices([1,2], k=1, weights=[0.7,0.3])[0]
xs = random.sample(list(np.arange(w)), n_x) # 線を引く場所
ys = random.sample(list(np.arange(h)), n_y) # 線を引く場所
if add_x:
for x in xs:
img[:,x-line_width:x+line_width] = img.min()
if add_y:
for y in ys:
img[y-line_width:y+line_width,:] = img.min()
return img
def add_white_line(img, line_width=2):
img = copy.deepcopy(img)
h, w = img.shape[:2]
# 白線を何本引くか決める
n_y = random.choices([10,13,16], k=1)[0]
add_y = random.sample(list(np.arange(h)), n_y) # 線を引く場所
for y in add_y:
img[y-line_width:y+line_width,:] = img.max()
return img
次に10、11の CycleGan の説明をします。CycleGan を利用したモチベーションは、記事に書いた通り、特定のパターンのノイズ(特にBackground Noise)が一部のラベルにしか存在しておらず、残りのラベルに対して、これを作成する必要がありました。黒線のように自作関数として実装することも考えましたが、勉強も兼ねて CycleGan の適用を検討しました。
実際、他の参加者の中には自作関数として実装した方もいたようです。その人は数字以外の部分にランダムで 0 か 255 をセットすることで背景のノイズを再現していました。
CycleGan 実装にあたっては、Kaggle の Bengali.AI Handwritten Grapheme Classification の 1st Place Solution を参考にしました。コードが大変長いので、ここには載せませんが、興味のある方は 私のGithub にコード全体をあげておくので見てください。以下には生成のサンプルを載せます。数エポックで結構それっぽい画像が生成できています。
基本情報
- 学習データ約1万枚(画像の重複多数あり)
- 画像サイズ128×128
- 15エポック
- 1エポック当たり約667枚
- バッチサイズ32
- 1エポック30秒
Background Noise Epoch 0

Background Noise Epoch 3

Dot Noise Epoch 0

Dot Noise Epoch 5

④Train : Val 及び Clean data : Noise data の比率調整
最後に、ここまで準備してきた画像を Cleanデータ と Noiseデータの比率に気を付けながら Train と Val に振り分けます。
Train : Val は 8:2 と 7:3 を試し、Public Leaderboardの結果から 7:3を採用。Train と Val のそれぞれに含める Clean : Noise は、9:1, 8:2, 7:3, 6:4, 5:5 を試した結果、7:3 を採用しました。元々主催者から提供されたデータにおける Clean : Noise は 9.5:0.5 程度なのですが、Public Leaderboard 上は、7:3 が良いように見えました。
最終的な順位は 107/486(Score: 0.80413)でした。このスコアが出たのは、上記全てを実施した結果ではないのですが、だいたい0.79~0.8 を推移していたので、スコアを上げるには別の観点が必要だったようです。残念ではありましたが、約2週間の参加期間しかなかったので、次回は初期の段階から参加してリベンジしたいと思います。ちなみに、1st place score は、0.86570 でした。
まとめと最後に
今回、世界初めてとなるData-Centric AI Competitionに参加し、その際に実施したことを記事にしました。基本的には、時間のある限り Data Augmentation を実装していきました。これは出来るだけ幅広いパターンのデータを学習させ、テスト時における未知のデータ(AIが知らないデータ)を減らそうとしていることを意味します。問題に則した Data Augmentation を実装するというのはよくあることと思いますが、このアプローチは十分有効と思うので、みなさんも是非、思い思いの実装してもらえると嬉しいです。
試したかったもう1つのアプローチは、学習データの中には似た画像も結構あるので、似た画像をクラスタリング等して、各クラスタから複数枚選ぶようなことをすると、無駄に同じ画像を学習する、あるいは、学習データと評価データに似た画像が入ってしまってFitしやすくなってしまう等のことを防ぐことをしたかったです。しかし、単純に画像をK-meansするであったり、Image-Net学習済みモデルの出力をk-meansするという方法では、思ったようにクラスタリングが出来ませんでした。このあたりは別途勉強していきたいと思います。
-
Data-Centricと反対のアプローチをModel-Centricといい、このアプローチでは精度改善のためにより新しいアルゴリズムを利用するといった手法を実施します。 ↩
-
Data-Centricに関する解説資料。MLOps: From Model-Centric to Data-Centric AI ↩
-
Andrew Ng先生がCo-Founderであり、世界中にAIの教育を提供している企業です。Courseの講座が有名です。 ↩
-
Andrew Ng先生がCo-Founderであり、AI技術を実世界に導入することを目標としている企業です。 ↩
-
実際は、9,992枚まででないとエラーとなりました。 ↩
-
機械学習モデルの学習等が実行可能なオープンソースのプラットフォームです。 ↩
-
正確には 1以上 ですが、説明上は 0/1 で表現しています。 ↩