はじめに
GitHub Actions の workflow を実行する際に AI モデルを利用したくなる場面があります。
個人的には、private リポジトリに push した学習メモを定期的に要約し、
Discord へ通知する仕組みを構築中で、その要約処理に AI を活用したいと考えました。
workflow の実行時に外部の API を叩くようにしても良かったのですが、調べてみたところ ai-inference を使って、GitHub Models にある AI モデルを使うのが便利そうでした。
ai-inference とは
GitHub Actions の workflow から GitHub Models カタログにある AI モデルを呼び出すために公式から提供されている action です。
GitHub Models
GitHub 上で様々な AI モデルを使うことができます。
2025年の5月には、API での呼び出しにも対応していました。
利用可能なモデル
以下では、id のみを出力するようにしてしますが、jq でフィルタリングしている箇所を外すと、
rate_limit についての情報や、input/output の token limit などの情報も確認することができます。
$ curl -L \
-H "Accept: application/vnd.github+json" \
-H "X-GitHub-Api-Version: 2022-11-28" \
https://models.github.ai/catalog/models | jq '.[].id'
"openai/gpt-4.1"
"openai/gpt-4.1-mini"
"openai/gpt-4.1-nano"
"openai/gpt-4o"
"openai/gpt-4o-mini"
"openai/gpt-5"
"openai/gpt-5-chat"
"openai/gpt-5-mini"
"openai/gpt-5-nano"
"openai/o1"
"openai/o1-mini"
"openai/o1-preview"
"openai/o3"
"openai/o3-mini"
"openai/o4-mini"
"openai/text-embedding-3-large"
"openai/text-embedding-3-small"
"ai21-labs/ai21-jamba-1.5-large"
"cohere/cohere-command-a"
"cohere/cohere-command-r-08-2024"
"cohere/cohere-command-r-plus-08-2024"
"deepseek/deepseek-r1"
"deepseek/deepseek-r1-0528"
"deepseek/deepseek-v3-0324"
"meta/llama-3.2-11b-vision-instruct"
"meta/llama-3.2-90b-vision-instruct"
"meta/llama-3.3-70b-instruct"
"meta/llama-4-maverick-17b-128e-instruct-fp8"
"meta/llama-4-scout-17b-16e-instruct"
"meta/meta-llama-3.1-405b-instruct"
"meta/meta-llama-3.1-8b-instruct"
"mistral-ai/codestral-2501"
"mistral-ai/ministral-3b"
"mistral-ai/mistral-medium-2505"
"mistral-ai/mistral-small-2503"
"xai/grok-3"
"xai/grok-3-mini"
"microsoft/mai-ds-r1"
"microsoft/phi-4"
"microsoft/phi-4-mini-instruct"
"microsoft/phi-4-mini-reasoning"
"microsoft/phi-4-multimodal-instruct"
"microsoft/phi-4-reasoning"
rate limit
rate_limit は具体的な数値ではなく、tier が返されますが、各 tier の具体的な内容は以下から確認できます。
使用例
基本的に README に書かれている通りにやるだけです。
name: 'AI inference'
on: workflow_dispatch
jobs:
inference:
permissions:
models: read
runs-on: ubuntu-latest
steps:
- name: Test Local Action
id: inference
uses: actions/ai-inference@v2
with:
prompt: 'Hello!'
- name: Print Output
id: output
run: echo "${{ steps.inference.outputs.response }}"
GitHub Model inference API を使うためには、permissions.modelsのread 権限を付与する必要があります。
https://docs.github.com/ja/actions/reference/workflows-and-actions/workflow-syntax#permissions
Generate AI inference responses with GitHub Models. For example, models: read permits an action to use the GitHub Models inference API.
この例では workflow_dispatch を設定しているのでマニュアル実行してみると、以下のようにモデルを使えていることがわかります。
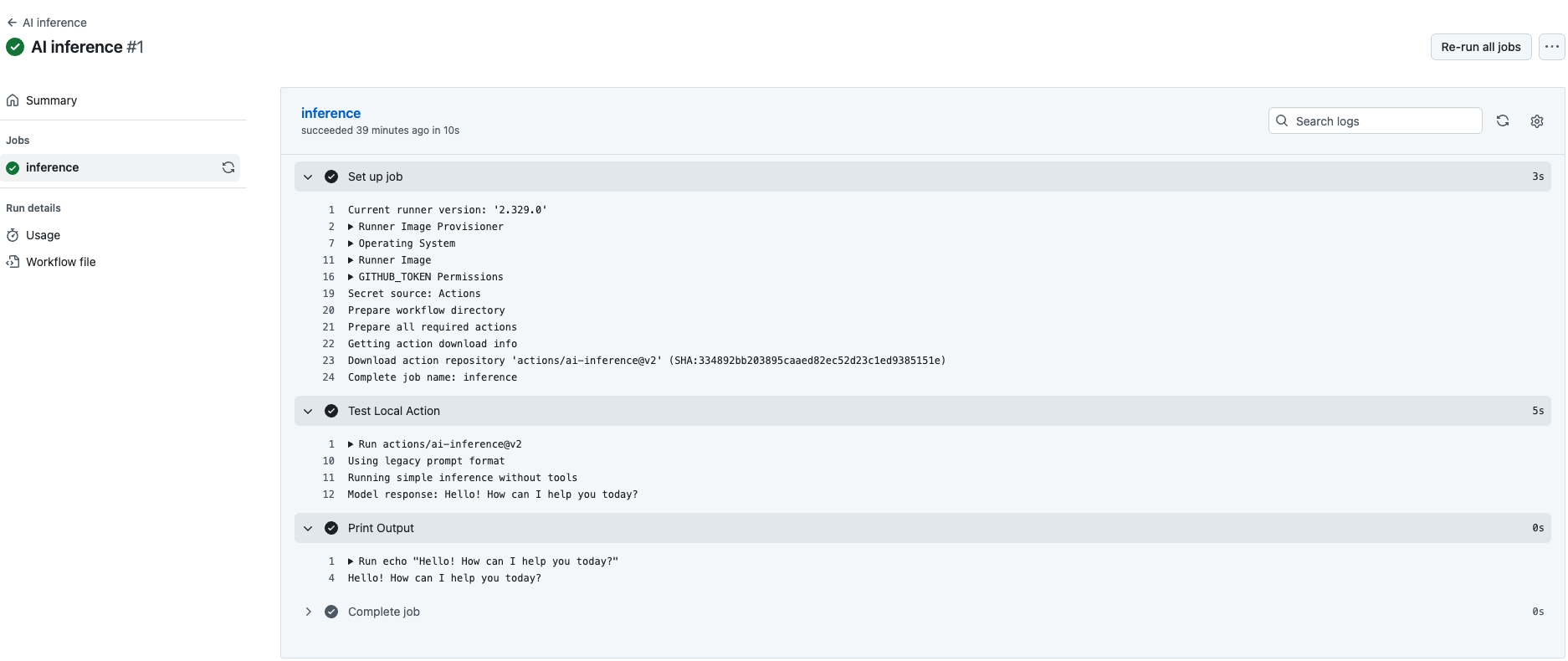
設定
上記のように、特にモデルを指定しなかった場合は、デフォルトで openai/gpt-4o が使われるようになっています。
input の model を明示的に指定すると、利用するモデルを変更することができます。
指定できるのは、利用可能な model に書いた通りです。
例えば、Grok 3 を使う場合は以下のようになります。
name: 'AI inference'
on: workflow_dispatch
jobs:
inference:
permissions:
models: read
runs-on: ubuntu-latest
steps:
- name: Test Local Action
id: inference
uses: actions/ai-inference@v2
with:
+ model: 'xai/grok-3'
prompt: 'Hello!'
- name: Print Output
id: output
run: echo "${{ steps.inference.outputs.response }}"
利用可能なモデルの一覧には openai/gpt-5 が含まれていますが、ai-inference だと parameter の設定がうまくいっておらず、現在は使えないようでした。
そのほかにも input, output に関する option を指定することができます。
max-tokens はデフォルトで 200 に設定されており、かなり小さいので変更しておくといいと思います。