導入
業務の一環で実行しているスクレイピング。
python + seleniumでツールを作って定時に社内サーバーから自動実行していた。
ある日、設定していた社内サーバーが計画停止。
とりあえずは自分の環境で手動実行してデータは取得したけれど・・・
「技術として汎用性もあるし、これを機にAWS Lambdaへ移動や!」
ということでやってみたのが今回のお話。
前提
- 実行環境:AWS Lambda
- 設定環境1:Windows10
- 設定環境2:debian10(権限設定用リモート環境・WSL2とかでもいけるかも)
- 言語:python3.7
- 追加パッケージ:selenium
コード
AWS Lambdaに配置したソースコードがこちら。
サンプルとしてYahooのプロ野球の順位表から、セ・リーグの順位を抜き出してみた。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
options = Options()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--single-process')
options.add_argument('--disable-dev-shm-usage')
options.add_argument('--lang=ja-JP')
options.add_experimental_option('w3c', True)
options.binary_location = '/opt/headless-chromium'
def test_selenium():
driver = webdriver.Chrome(executable_path="/opt/chromedriver", chrome_options=options)
driver.get('https://baseball.yahoo.co.jp/npb/standings/')
elm = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, ".bb-rankTable__row"))
)
elm = driver.find_element(By.CSS_SELECTOR, '.bb-rankTable')
elm = elm.find_element(By.TAG_NAME, "tbody")
elm = elm.find_elements(By.TAG_NAME, "tr")
for elmitem in elm:
team = elmitem.find_element(By.CSS_SELECTOR, '.bb-rankTable__data--team')
print(team.text)
driver.close()
driver.quit()
def lambda_handler(event, context):
print("セ・リーグ順位")
test_selenium()
結果↓
セ・リーグ順位
ヤクルト
阪神
巨人
広島
中日
DeNA
実施手順
ツールの用意
まず、大前提としてAWS Lambdaはもちろん通常のブラウザが使える環境ではない。
なので、UIが表示されないブラウザ「Headless Chrome」を利用する。
ちなみに「Headless Chrome」は以下の用途で用いられるらしい。
ヘッドレスブラウザは、GUI を持つ必要のない自動テスト環境やサーバー環境にとてもよいツールです。例としては、実際のウェブページに対してなにかテストを実行する、そのページの PDF を生成する、またはただ、そのページがどう表示されるかを検証するなどが挙げられるでしょうか。
ツールのDL
Headless Chrome
まずは上述の「Headless Chrome」を用意する。
以下のURLよりDLする。
https://github.com/adieuadieu/serverless-chrome/releases/download/v1.0.0-55/stable-headless-chromium-amazonlinux-2017-03.zip
ChromeDriver
プログラムでブラウザを動かす為にはドライバーが必要である。「ChromeDriver」を用意する。
以下のURLよりDLする。
https://chromedriver.storage.googleapis.com/2.37/chromedriver_linux64.zip
この時、「Headless Chrome」に対応した「ChromeDriver」を選択する必要がある。(今回は2.37を選択した。)
ツールの権限設定
WindowsでDLした場合、権限の設定が必要になる。
DLしたファイルにLinux上で以下の権限を与える。
$ chmod 755 chromedriver
$ chmod 755 headless-chromium
パッケージの用意
AWS Lambda上でseleniumを動かすためにpythonパッケージを用意する。
(今回はAWS Lambda実行環境に合わせて、念のためLinux環境でパッケージを用意した。)
$ pip install selenium -t python/lib/python3.7/site-packages
ツールのzip化
AWS Lambdaに設定するため、用意したツールをzipで固める。
改定頻度を考え以下の構成でツールを固めた。
- python.zip・・・①
- python/lib/python3.7/site-packages/*
- headless-chromium
- driver.zip・・・②
- chromedriver
AWSでの設定
レイヤーの設定
先ほど用意したツール群はレイヤーとして登録する。
レイヤーを作成することのメリットは多数あるが、一番恩恵を感じたのは
ツール群のサイズが大きいため、コードに含んでしまうとAWS Lambda上のエディタでコード編集が出来なくなる。
という状況を回避することが出来ることかもしれない。
つまり、レイヤーをうまく使うことで効率よく開発をすることが出来、メンテナンス性も向上することが出来るのである。
また、他の関数と共有することも可能であるため「別関数でスクレイピングしたい」という場合には
レイヤーを設定することで簡単に導入することも可能である。
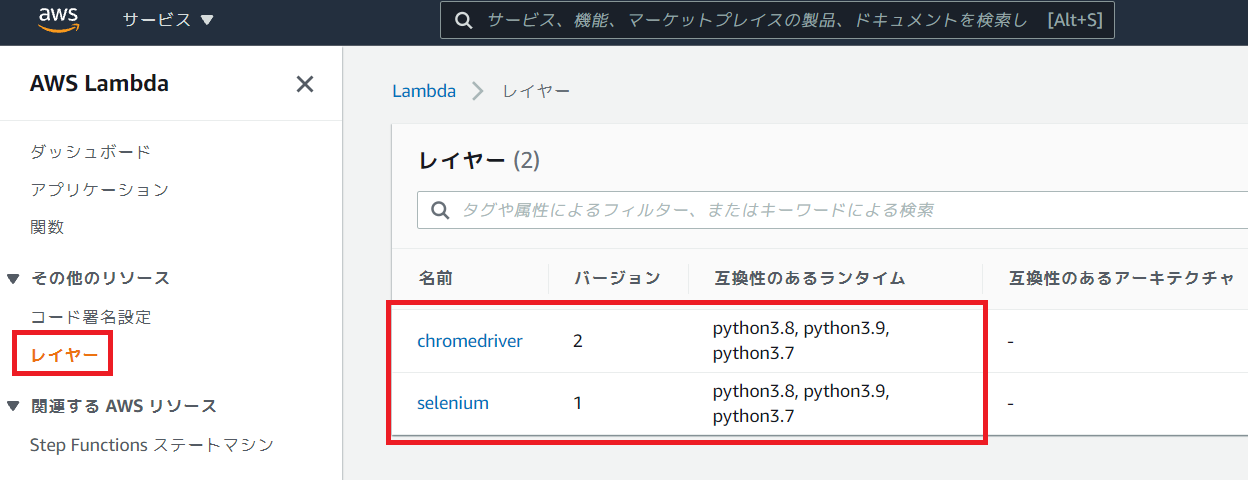
互換性のあるランタイムにはpython3.7を含めること
関数の作成
さて、ここまで終わったらついに関数の作成である。
関数の作成方法は多数の記事があるので割愛させていただく。
- 関数名
- 任意(selenium_testなど)
- ランタイム
- python3.7
- アーキテクチャ
- x86_64(デフォルト)
- アクセス権限等
- (デフォルト)
ランタイムをpython3.7である理由は、現状python3.8以上では動作しないためである。
今後、動くようになった場合は本ドキュメントを更新する。
関数にレイヤーを設定
先ほど作成したレイヤーを関数に設定する。
今時点のUIではコードタブの最下部にて設定が可能である。
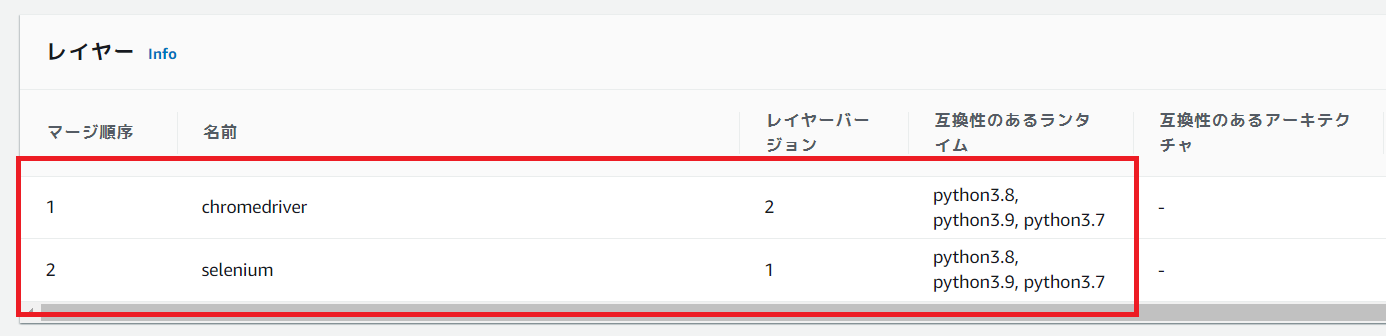
一度設定した後は、この設定を行うだけで他の関数でもseleniumを導入可能である。
関数の設定
設定タブで「メモリ」と「タイムアウト」を調整する。
ヘッドレスブラウザ起動~スクレイピングを内部的に実行するので
普通の関数実行よりもちろん時間はかかるので、調整しなければ99%タイムアウトしてしまう。
コードの実装
後は、最初に示したコードを実行すると同様の結果が得られるはずである。
動かすだけなら基本コードは以下である。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--single-process')
options.add_argument('--disable-dev-shm-usage')
options.binary_location = '/opt/headless-chromium'
def lambda_handler(event, context):
driver = webdriver.Chrome(executable_path="/opt/chromedriver", chrome_options=options)
driver.get('https://baseball.yahoo.co.jp/npb/standings/')
driver.close()
driver.quit()
- オプションについて
-
options.add_argumentで追加しているオプションはヘッドレスブラウザで起動するためのものである。 - レイヤーの参照について
- レイヤーに設定したファイルは
/opt/*で参照する。
ハマりポイント
日本語サイトの表示
ブラウザの設定言語で表示が変わるページは初期設定が英語となっている関係で
意図した結果が得られない場合がある。
その場合はオプションに以下を設定することで日本語で表示をしてもらうことが出来る。
options.add_argument('--lang=ja-JP')
解析時の注意
WebElementを解析する時、w3cがFalseとなっていると
driver.find_element(*)等でページを解析した結果がdict型となっている現象が確認された。
これでは正直解析が出来ないので
options.add_experimental_option('w3c', True)
を明示的に設定し、w3cをTrueにする必要がある。
そうすることで、selenium.webdriver.remote.webelement.WebElementが解析結果として返却され
text等を参照することが出来るようになる。
終わりに
思いつきで始めた実装ではあったが
AWS Lambda上でスクレイピングを行うことが出来れば、
サーバーレスでのテストの自動化等につながると実感することが出来た。
参考文献
先駆者の力を多数借りましたので、この場を借りてお礼申し上げます。