Lambda
awsが提供するサーバーレスにコードを実行できるコンピューティングサービスです。
リクエスト数い応じてスケーリングする機能もあり環境構築や負荷分散、メンテナンスの必要もありません。
料金は実行した時間に応じて支払うため、コードを実行していない時間帯は課金されません。つまりサーバーの維持費がかかりません。
これはお得。
まずは必要なライブラリをインストール
Lambdaはサーバーを使わないため、直接接続して必要なライブラリをインストールすることができません。代わりにあらかじめインストールしたLinux環境に適応したライブラリをLambdaにアップロードすることで使用できるようになります。
今回使用するSeleniumも同じ方法でアップロードしていきます。
まずはどこかの環境にSeleniumとWebdriverをインストールする必要があり
・DockerでPython環境を立ち上げてインストールする
・Cloud9を使用する
という方法があるのですが、今回はより素早く容易にできるCloud9を採用させていただいてます。
Cloud9
ブラウザからコードを実行できるサービスです。
Cloud9と入力して移動。
環境名はpython_for_lambdaにし、それ以外は全てデフォルトで環境を作成。
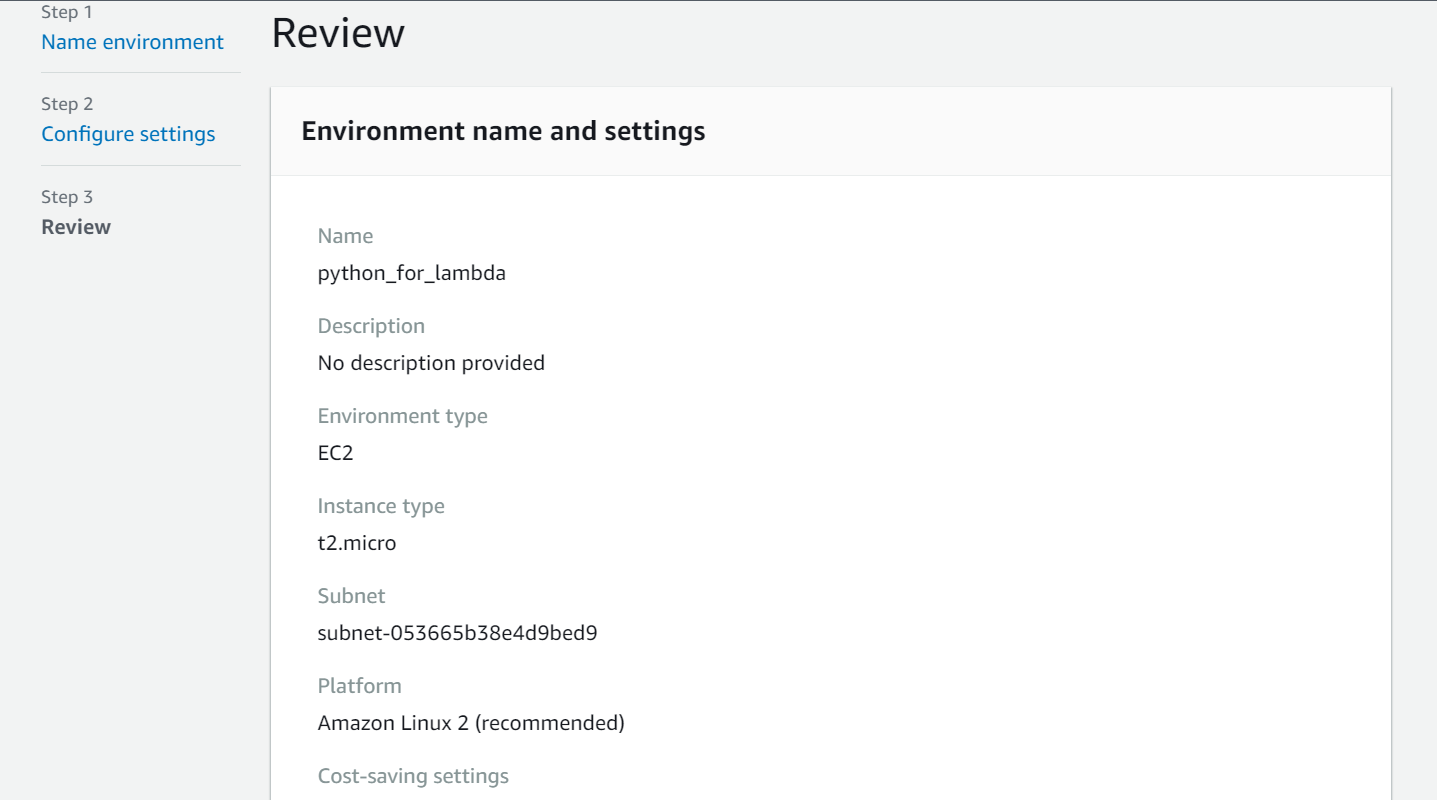
なんとこれだけでpythonが実行できる環境ができてしまいます。
$ python -V
Python 3.7.9
早速seleniumをインストール
インストール先はpython/lib/python3.7/site-packagesというディレクトリを指定。
$ pip install selenium -t python/lib/python3.7/site-packages
Collecting selenium
Using cached https://files.pythonhosted.org/packages/80/d6/4294f0b4bce4e17190289f9d0613b0a44e5dd6a7f5ca98459853/selenium-3.141.0-py2.py3-none-any.whl
Collecting urllib3 (from selenium)
Using cached https://files.pythonhosted.org/packages/f5/71/45d36a8df6861b2c017f3d094538c0fb98fa61d4dc43e69b9/urllib3-1.26.2-py2.py3-none-any.whl
Installing collected packages: urllib3, selenium
Successfully installed selenium-3.141.0 urllib3-1.26.2
続いてchrome類をインストールしていきます。
ヘッドレスでの運用を考えているためchromedriverとheadless-chromiumをインストールしていきます。
$ mkdir -p headless/python/bin
# 保存するディレクトリをあらかじめ作成
$ cd headless/python/bin
$ curl -SL https://github.com/adieuadieu/serverless-chrome/releases/download/v1.0.0-37/stable-headless-chromium-amazonlinux-2017-03.zip > headless-chromium.zip
# headless-chromiumをインストール
$ unzip -o headless-chromium.zip -d .
$ rm headless-chromium.zip
# ファイルを展開してzipを削除
$ curl -SL https://chromedriver.storage.googleapis.com/2.37/chromedriver_linux64.zip > chromedriver.zip
# chromedriverをインストール
$ unzip -o chromedriver.zip -d .
$ rm chromedriver.zip
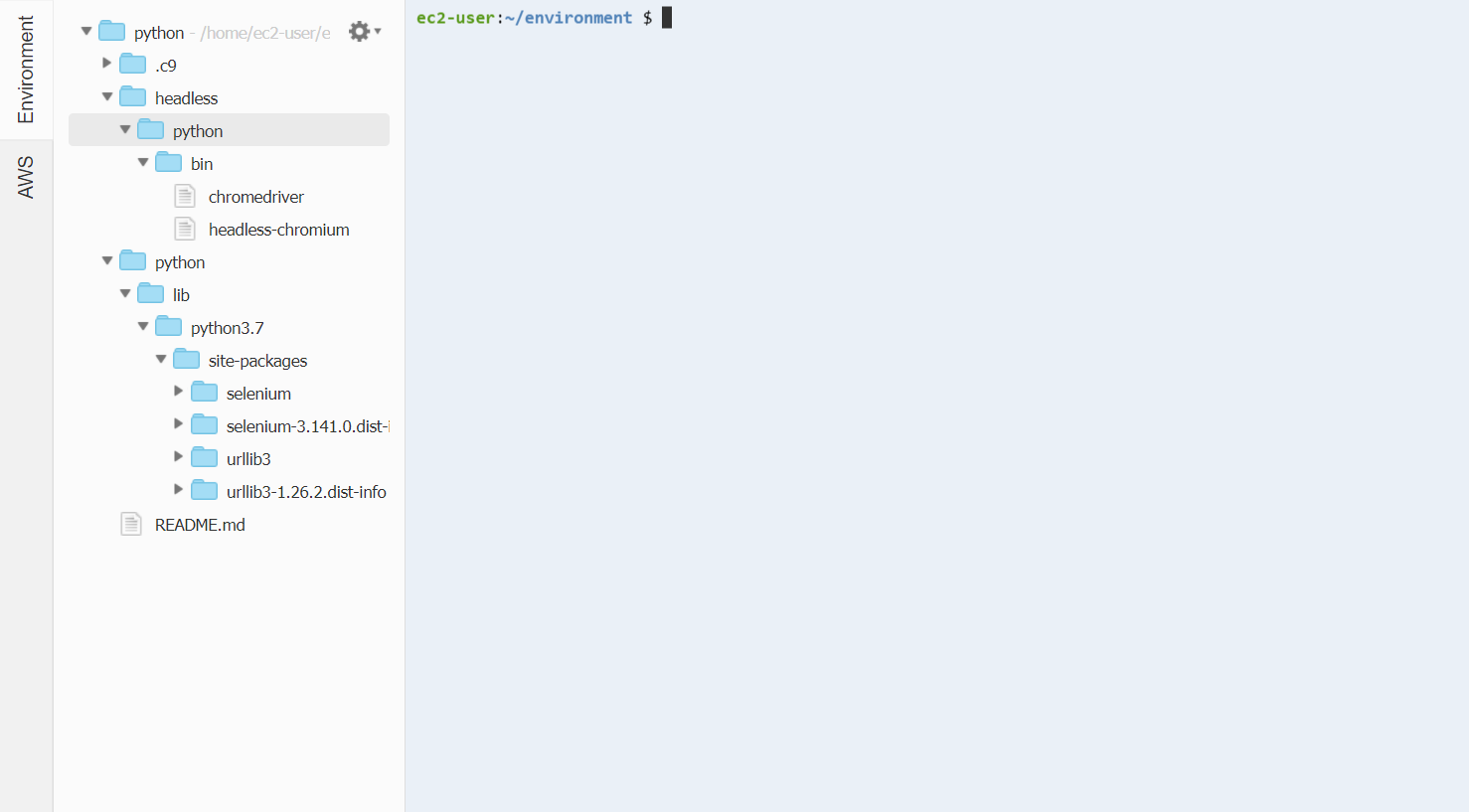
それぞれ左クリックでDownloadを選択しzipでダウンロード。
selenium: python配下
chromedriver,headless-chromium: headless配下
headless
┗ python
┗ bin
┣ chromedriver
┗ headless-chromium
python
┗ lib
┗ python3.7
┗ site-packages
┣ selenium
┣ selenium-3.141.0.dist-info
┣ urllib3
┗ urllib3-1.26.2.dist-info
Seleniumやchromedriverをすでに使っている方はもうPC内に存在しているかもしれませんが、Linux環境に対応したバージョンでないとLambdaにアップロードした際に実行できなくなってしまうため、Linux環境であるcloud9上でインストールしたものを使うことをおすすめします。
※自分はWindows上でインストールしたchromedriverを使ってみましたがダメでした
Lambda
必要ライブラリをインストールできたのでこれはLambdaに上げていきます。
レイヤーにアップロード
まずはLambdaへ移動。
コンソールからレイヤーを選択。
このレイヤーは関数を実行するために必要なライブラリやコンテンツをアーカイブとして保存しコード実行時に使用できます。
先ほどインストールしたseleniumとheadlessファイルをアップしていきましょう。
| レイヤー名 | ファイル | |
|---|---|---|
| chromedriver, headless-chromium | headless | headless.zip |
| selenium | selenium | python.zip |
なおランタイムはpython3.7に設定します。
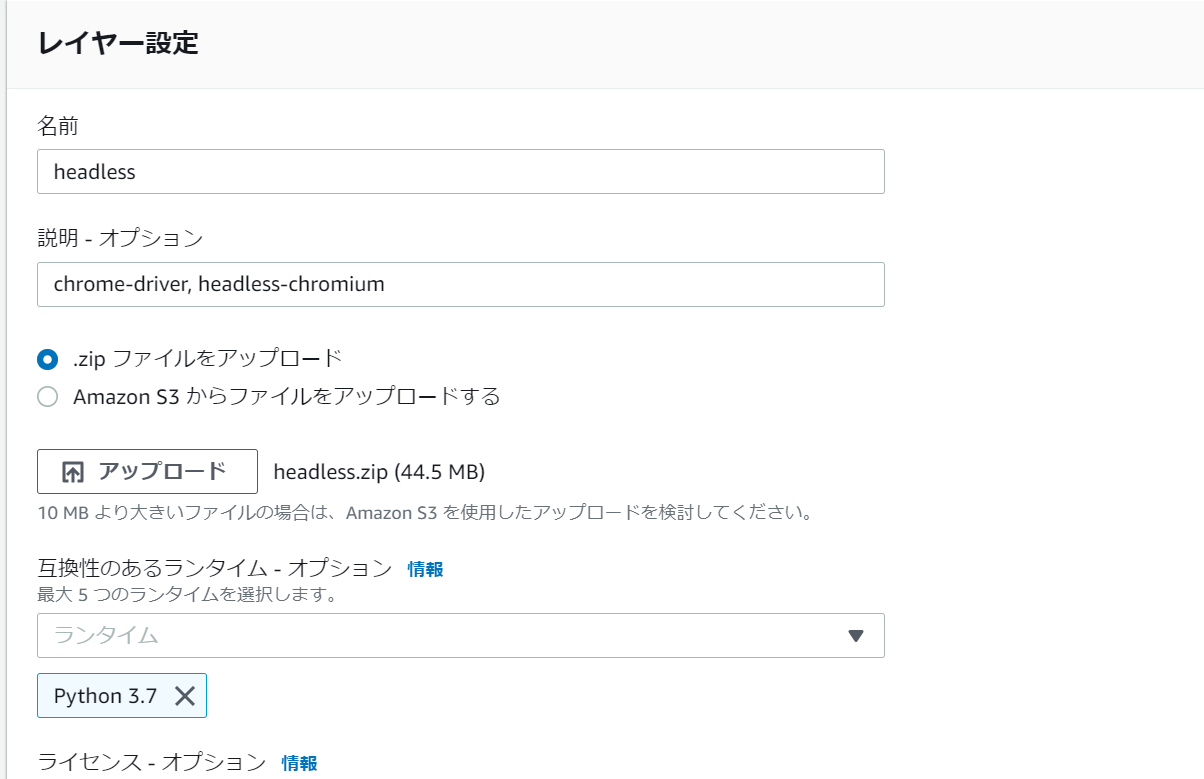
関数作成とレイヤーの追加
続いて関数の作成を行います。
コードは後ほど記述するのでまずは関数の型み作成していきましょう。
ダッシュボードの関数を作成を選択。
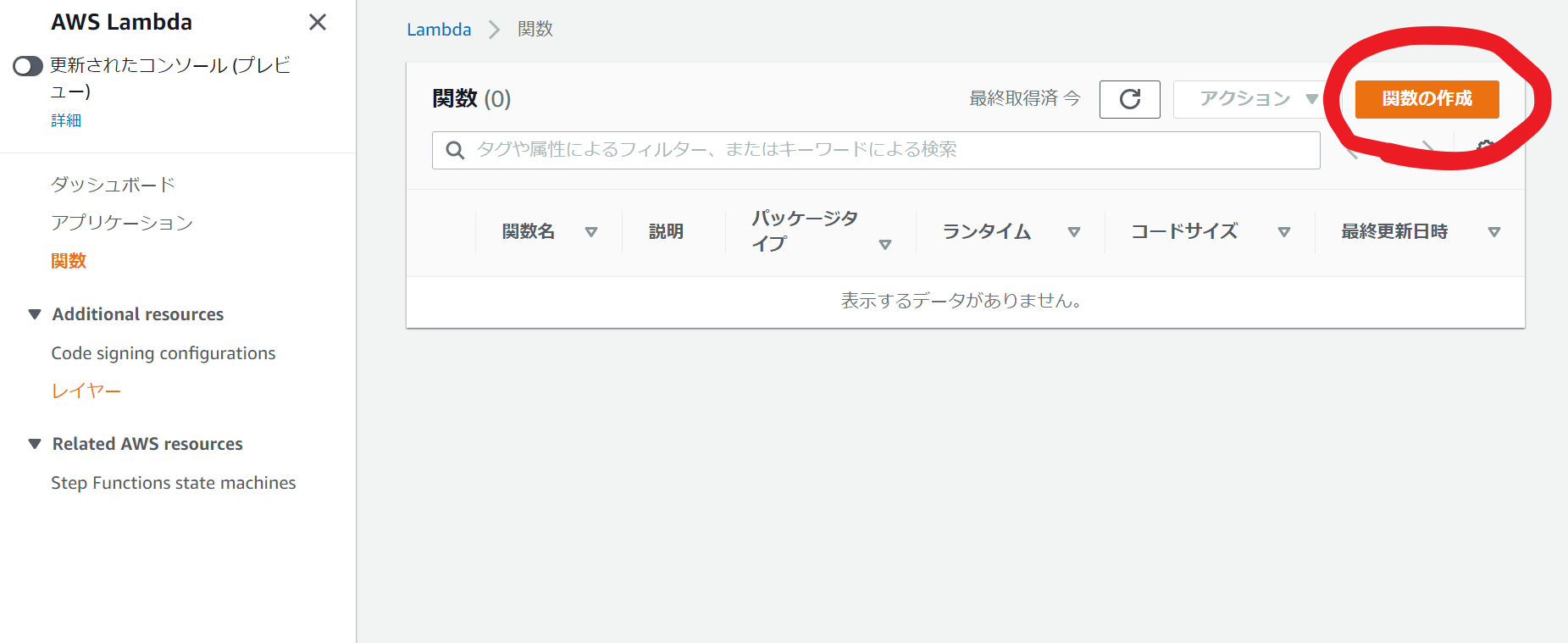
関数名はlambda_function_for_headless_chrome,ランタイムはpython3.7で作成。
これでpythonを実行する環境が整いました。
次に先ほど作成したレイヤーをこの関数に追加します。
Layersをクリックしレイヤーの追加を選択。
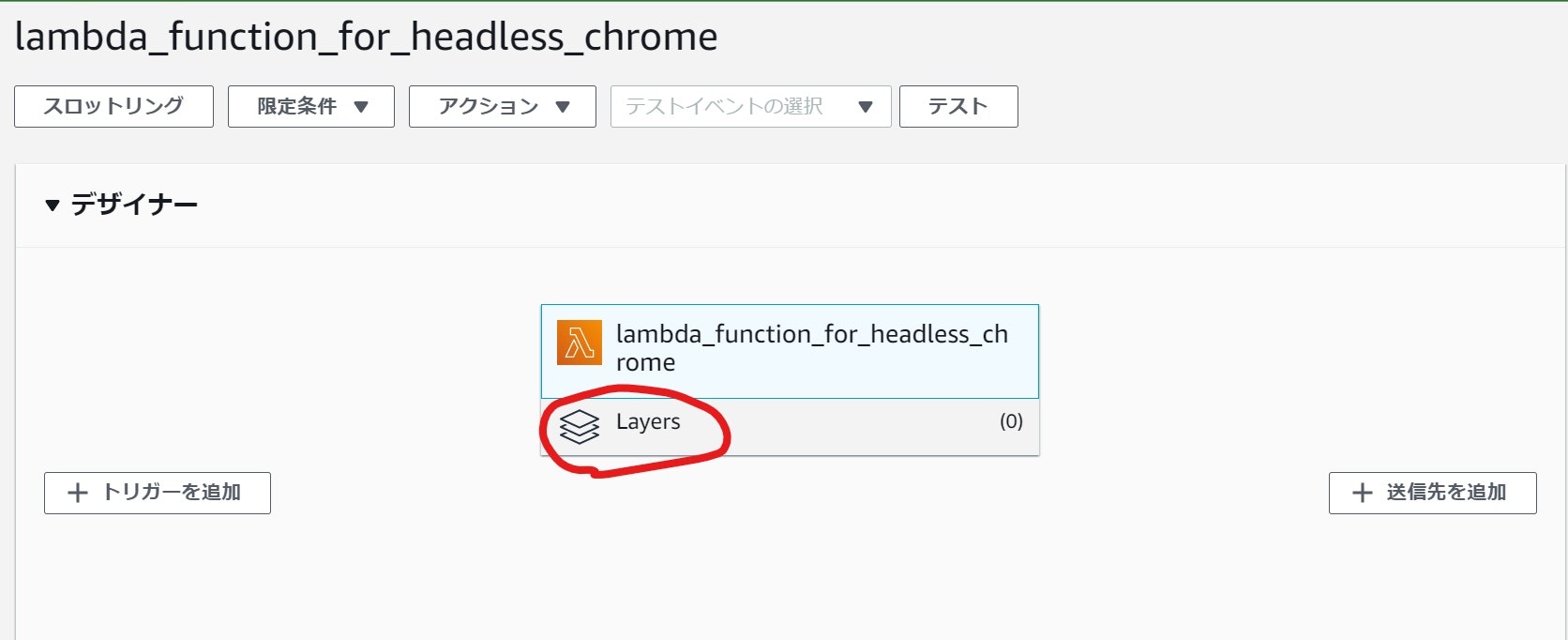
カスタムレイヤーからそれぞれheadlessとseleniumレイヤーを追加して下さい。
最終的にLayersが(2)になっていればレイヤー追加完了です。
関数の実行
それではpythonでseleniumを実行していきましょう。
関数から関数コードにすでに存在するコードを以下のように書き換えます。
# python配下自動でimport
from selenium import webdriver
def lambda_handler(event, context):
URL = "https://news.yahoo.co.jp/"
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--disable-gpu")
options.add_argument("--hide-scrollbars")
options.add_argument("--single-process")
options.add_argument("--ignore-certificate-errors")
options.add_argument("--window-size=880x996")
options.add_argument("--no-sandbox")
options.add_argument("--homedir=/tmp")
options.binary_location = "/opt/python/bin/headless-chromium"
#ブラウザの定義
browser = webdriver.Chrome(
"/opt/python/bin/chromedriver",
options=options
)
browser.get(URL)
title = browser.title
browser.close()
return title
ここで注意が必要なのはchromedriverのPATHの記載です。
opt配下に指定してありますがこれはLambdaレイヤーにアップロードされたフォルダは自動的にopt配下に保存されるためです。
それではSeleniumのPATHはというと特に必要はありません。
Lambdaレイヤーでは
・python配下
・python/lib/python3.x(使用するバージョン)/site-packages配下
のいずれかであれば自動的にファイルを読み込んでくれます。
そのため今回は特にPATHを指定することなくimportコマンドが実行できます。
基本設定を変更
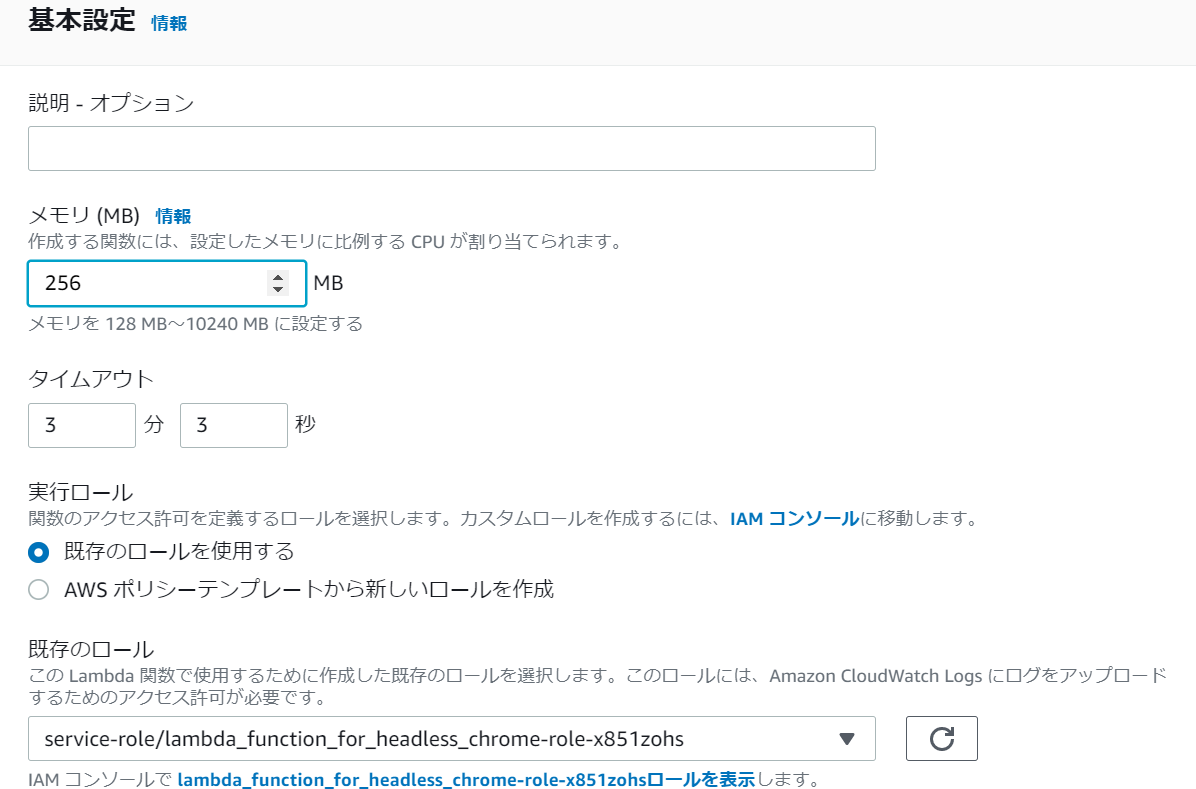
最後に基本設定を少しいじります。
というのもSeleniumでの実行処理は通常のプログラムに比べて実行時間が長くなるので既存の設定だとタイムアウトになってしまう可能性が高いです。
そのためタイムアウトを長めにとる必要があります。
また実行メモリも128MBだと足りなかったため256MBに変更してからテストを実行します。
テストを実行
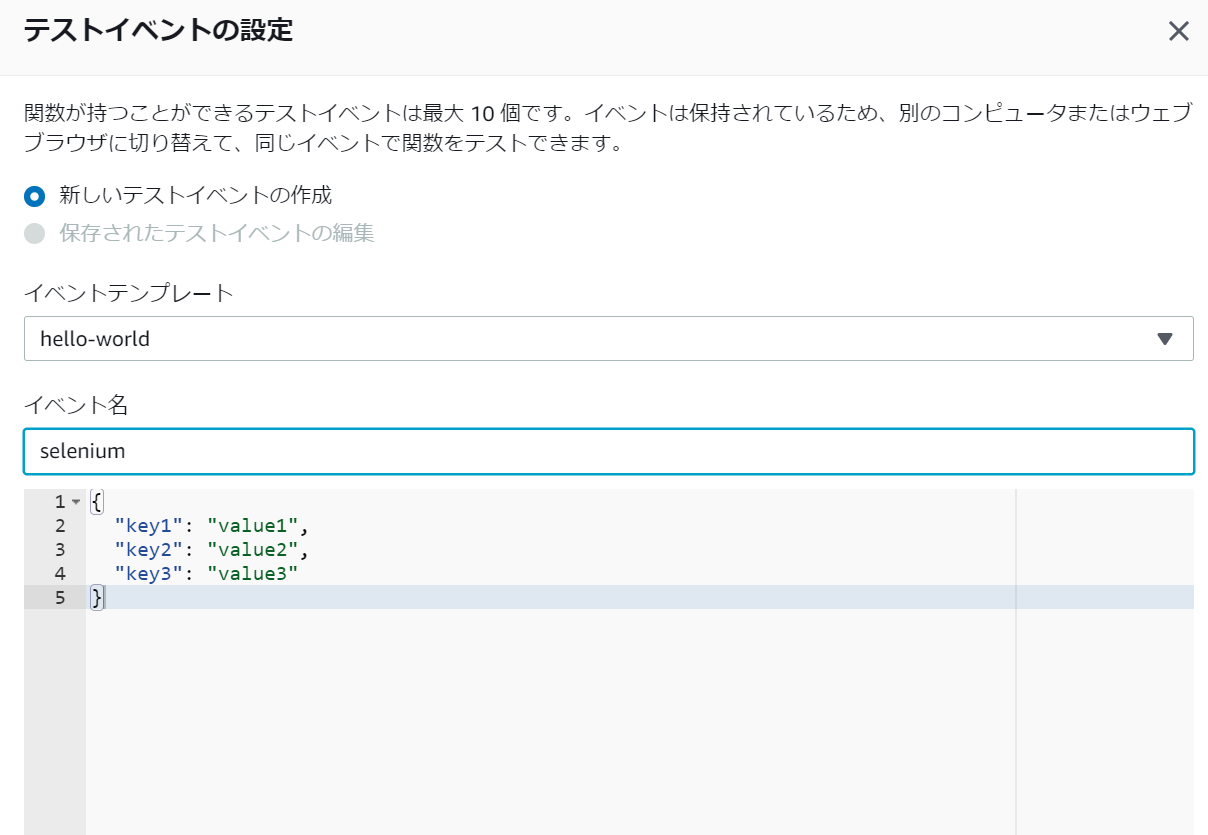
それではテストを作成してコードを実行していきましょう。
テストをクリックし関数名を入力、それ以外はデフォルトで作成します。
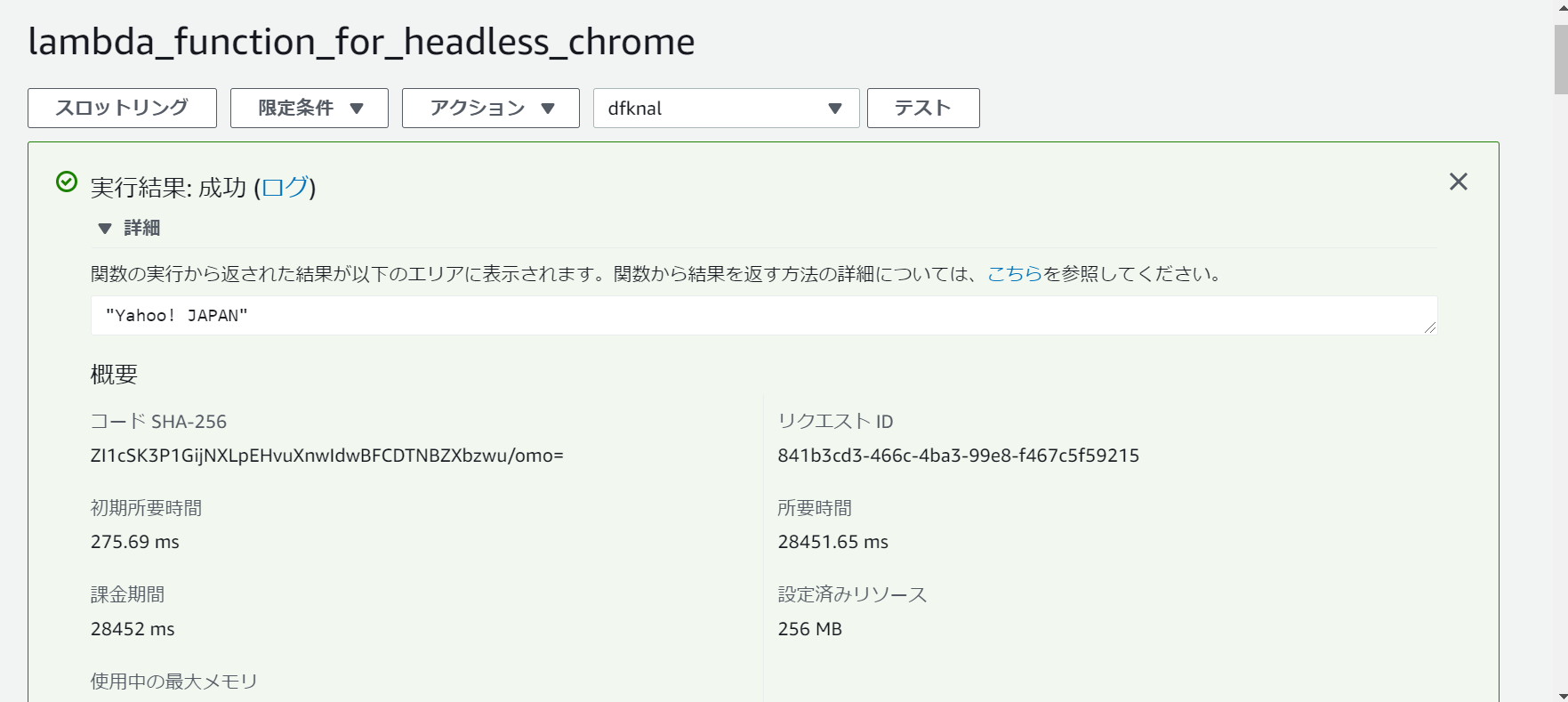
作成し終わったらテストをもう一度クリックし実行!
しばらく待機画面が流れたあとこのようになれば成功です。
次は本番のコードを書いてより実用的な定期処理を実装していきます。
上手くいかない場合
上手くいかない場合はこちらを参照してみて下さい。
'lambda_function': No module named 'selenium' が出るとき
chromedriver' executable may have wrong permissions.が出る場合
参考にさせていただいた記事
[AWS LambdaでPythonスクレイピングを定期実行させる]
(https://qiita.com/eisu26/items/be7a75edf7a798f17f11)