概要
インターンでお世話になっている企業の社内PCで定期実行されていたスクレイピングを、AWSLambdaに移行した話です。参考程度に見ていただければありがたいです。
この記事ではAWS LambdaでPythonスクレイピングした内容をメール送信する、という一連の処理をAmazon Cloud Watch Eventsを用いて定期実行させます。最終的にServerless Frameworkを用いてデプロイするところまで紹介します。
開発環境
MacOS Mojave 10.14.4
Python3.7
Serverless Framework 1.45.1
Docker 18.09.2(必須というわけではないです)
手順
1. インストール
まずはこの記事を参考に、serverless-chromium、chromedriver、seleniumのインストールを行いました。
[AWS Lambda上のheadless chromeをPythonで動かす]
(https://qiita.com/nabehide/items/754eb7b7e9fff9a1047d)
serverless-chromiumとchromedriverは普通にインストールすればよいのですが、seleniumはpipでインストールするため、インストールする環境をAmazon Linux2に合わせなければならないそうです。私はMacを利用してるので、この記事のようにDockerを使用しました。
2. AWS Lamdaで動くか確認
1 でインストールしたファイル、ライブラリ等がAWS Lamda上で動くか一旦確認したいと思います。
Lambdaにアップロードするファイル(上の記事を参考にさせていただきました)
from selenium import webdriver
def lambda_handler(event, context):
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--disable-gpu")
options.add_argument("--window-size=1280x1696")
options.add_argument("--disable-application-cache")
options.add_argument("--disable-infobars")
options.add_argument("--no-sandbox")
options.add_argument("--hide-scrollbars")
options.add_argument("--enable-logging")
options.add_argument("--log-level=0")
options.add_argument("--single-process")
options.add_argument("--ignore-certificate-errors")
options.add_argument("--homedir=/tmp")
options.binary_location = "/opt/headless/python/bin/headless-chromium"#PATH
driver = webdriver.Chrome(
executable_path="/opt/headless/python/bin/chromedriver",#PATH
options=options
)
driver.get("https://qiita.com/")
title = driver.title
driver.close()
return title
容量の大きなファイル、ライブラリ等はAWS LambdaのLayersにアップロードします(headless-chromium, chromedriver)
先ほどインストールしたファイルをこのように配置してheadlessフォルダを圧縮します。(headless.zipを作成)
headless──python──bin
├── chromedriver
└── headless-chromium
同じようにselenium.zipを作成しておきます。
selenium──python
├── selenium
├── selenium-3.141.0.dist-info
├── urllib3
└── urllib3-1.25.3.dist-info
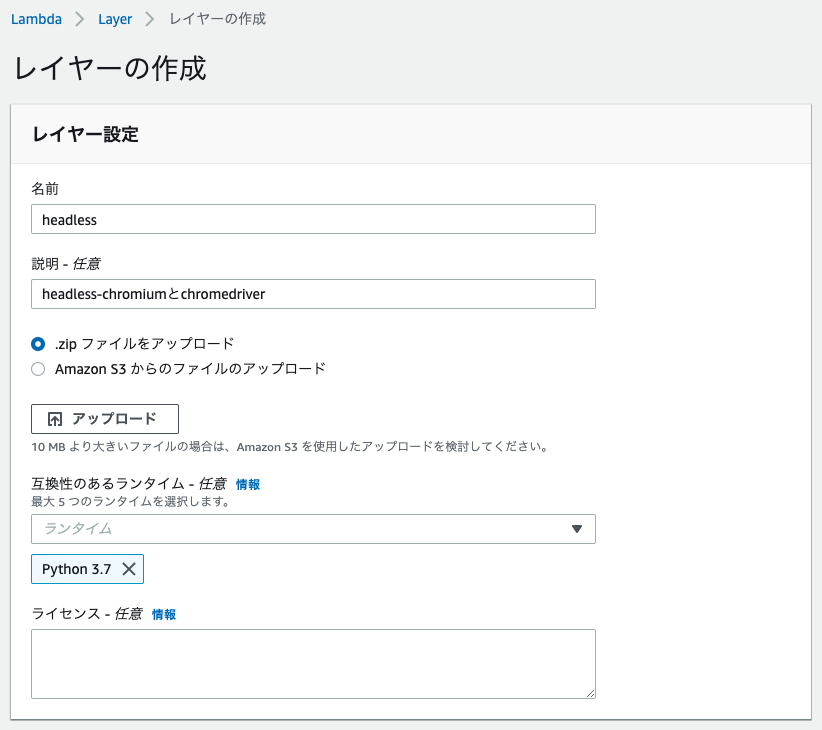
続いてAWS->Lambda->Layersからレイヤーの作成を選択します。
画像はheadless.zipをアップロードするところです。selenium.zipも同じようにアップロードしてレイヤーを作成してください。私はseleniumという名前で作成しました。10MBより大きいファイルの場合はS3を使用してアップロードした方がよさそうですが、とりあえずアップロードすることはできました。
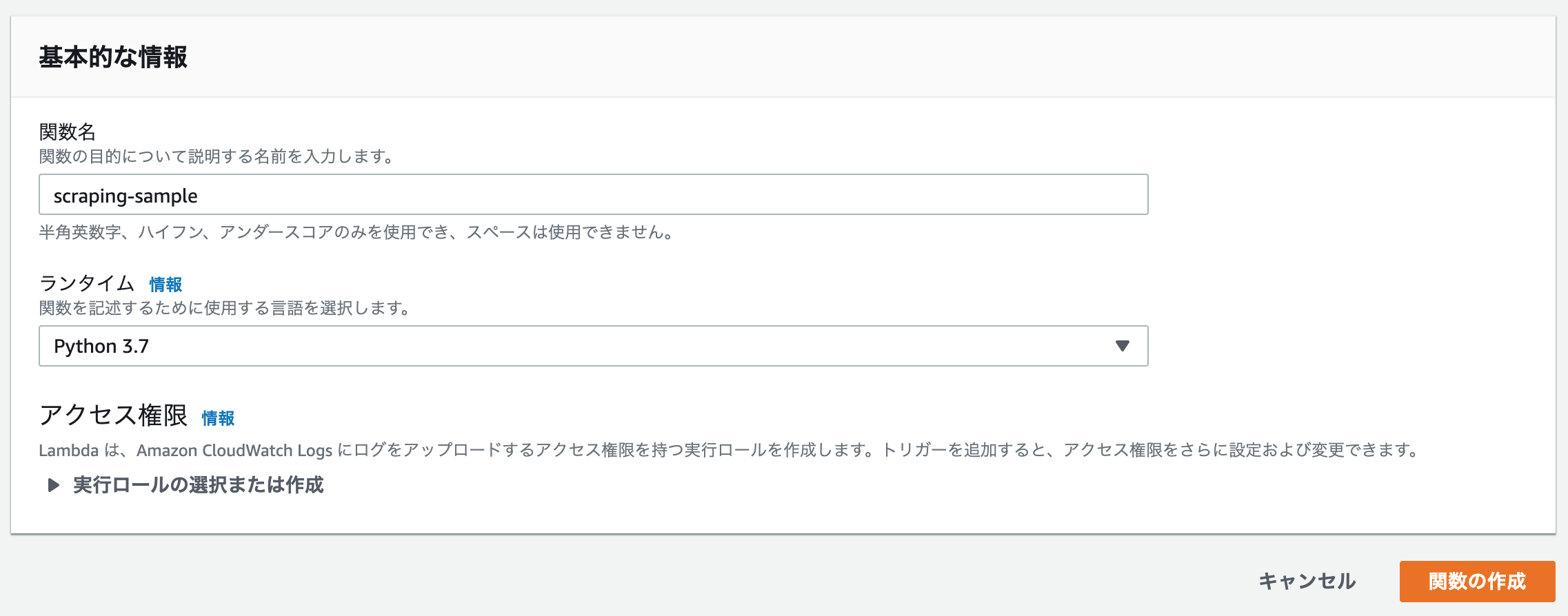
それでは関数を作成していきましょう。AWS->Lambda->関数->関数の作成 と進みます。
私は下のように設定しました。アクセス権限については自分の好みで設定してください。今回は何も設定せずに関数の作成をします。
 「関数の作成」をしたあと、Layersを設定します。Layersを選択して画面下の方で「レイヤーの追加」ボタンを押します。
「関数の作成」をしたあと、Layersを設定します。Layersを選択して画面下の方で「レイヤーの追加」ボタンを押します。
 先ほど作成した2つのレイヤーを追加するとLayersが(2)に変わりました。
先ほど作成した2つのレイヤーを追加するとLayersが(2)に変わりました。
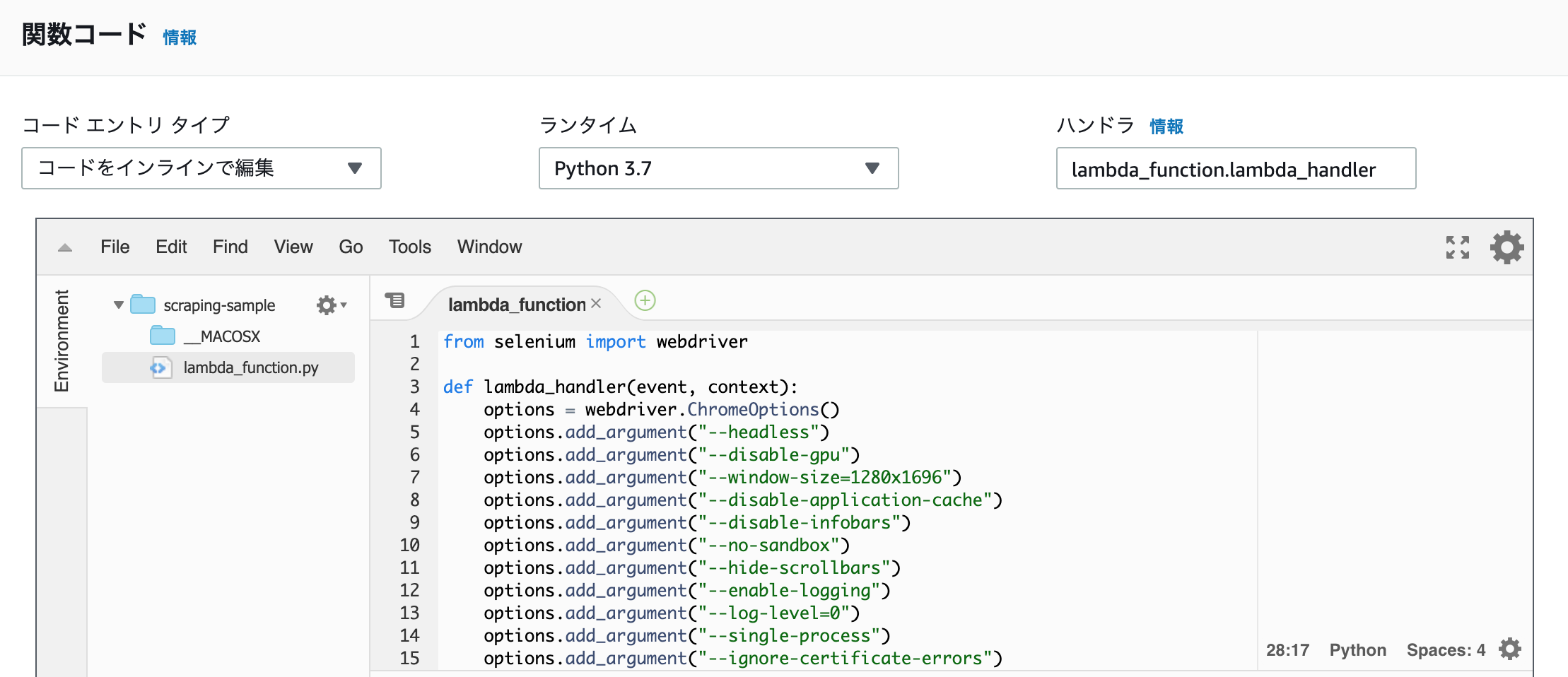
次に「関数コード」を設定します。lambda_function.pyのコードをコピペ、またはzipファイルにしてアップロードしてください。
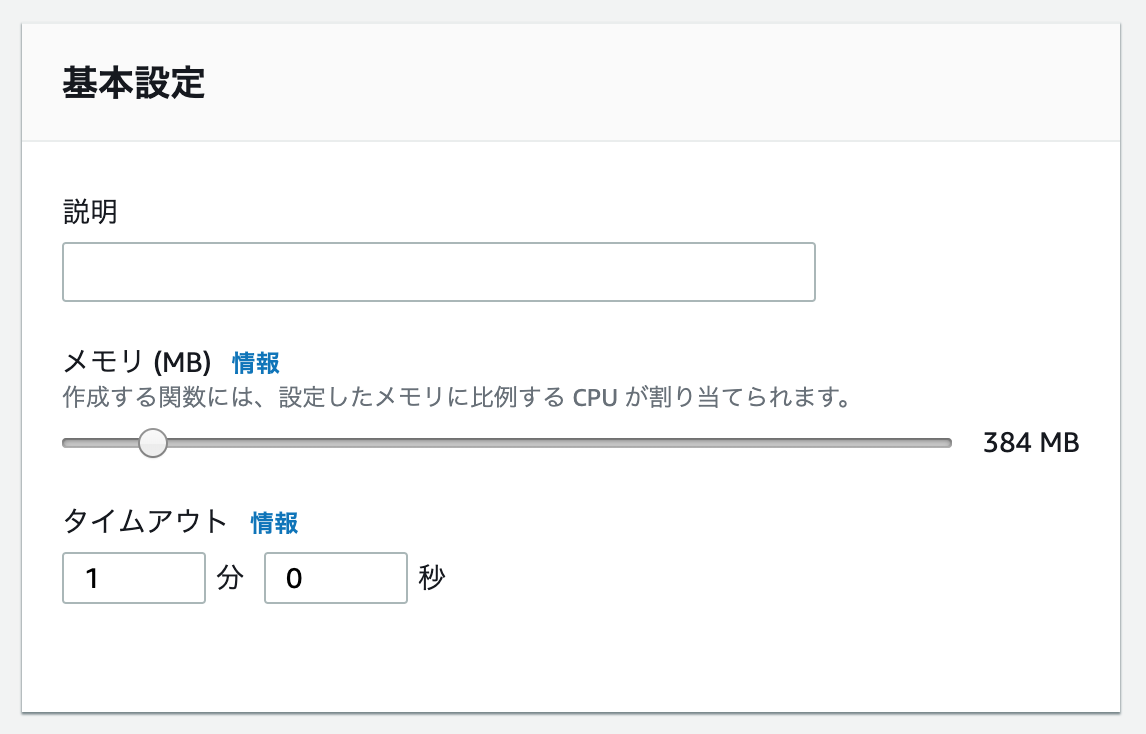
また、メモリとタイムアウトに余裕を持たせます。
変更を保存してテストを実行します。画面上部に「テスト」があるので選択し、テストイベントの設定をします。今回は適当にイベントテンプレートを「Hello World」、イベント名を「test1」としました。「作成」してもう一度「テスト」を選択すると関数を実行することができます。
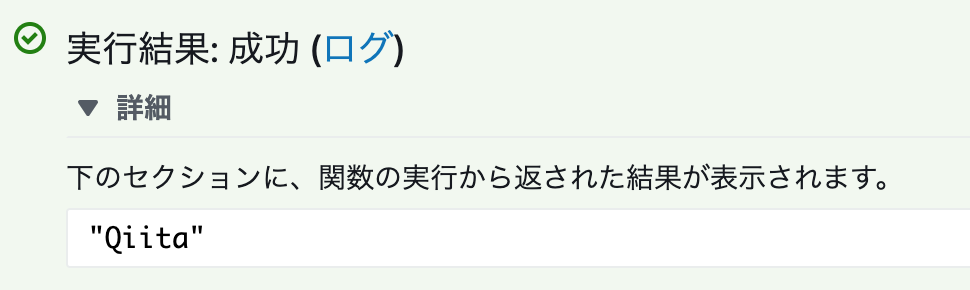
成功しました。
3. 実際のコードを書く
2で動くことを確認できたので、実際使用するコードを準備します。
ある程度コードを削っています。
# coding:utf-8
import time
import datetime
import mail
import chrome_scraping as sc
def lambda_handler(event, context):
url_seicho = [
"http://www-gpo3.mext.go.jp/kanpo/seicho_iken.asp",
"http://www-gpo3.mext.go.jp/kanpo/seicho_shiryo.asp"
]
to_email = "xxxxxxxx@example.com,yyyyyyyy@example.com" # 送信先のメールアドレス
date = get_today_japanese()
text_iken = sc.search(date, url_seicho[0])
text_shiryo = sc.search(date, url_seicho[1])
if text_iken[0] == [] and text_shiryo[0] == []:
title = '更新された調達情報はありません'
body = '更新された調達情報はありません'
mail.send(title, body, to_email)
else:
for index in range(len(text_iken[0])):
title = '「意見招請」の調達情報 (' + text_iken[0][index] + ')'
body = text_iken[1][index].replace("\n", '<br>')
mail.send(title, body, to_email)
for index in range(len(text_shiryo[0])):
title = '「資料提供招請」の調達情報 (' + text_shiryo[0][index] + ')'
body = text_shiryo[1][index].replace("\n", '<br>')
mail.send(title, body, to_email)
def get_today_japanese():
now = datetime.datetime.today()
today = str(now.strftime("年{}月{}日".format(now.month, now.day))) # 1と11を区別するため「年」を入れる
return today
# coding:utf-8
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
def search(date, url):
driver = open_browser(url)
# 今日の更新を取得
today_tr_index = []
tr_list = driver.find_elements_by_css_selector('form table tbody tr')
for index in range(len(tr_list)):
if date in tr_list[index].find_element_by_css_selector('td').text: #今日の更新があるとき
today_tr_index.append(index)
title_list = []
body_list = []
for index in today_tr_index:
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "FormR"))
)
except:
print('エラーが発生しました')
targets = driver.find_elements_by_css_selector('form table tbody td:nth-child(4)')
a_tag = targets[index].find_element_by_css_selector('a')
title_list.append(a_tag.text)
a_tag.click()
child_element = driver.find_element_by_id('FormR')
body_list.append(child_element.text)
driver.back()
driver.quit()
return [title_list, body_list]
def open_browser(url):
# ブラウザを開く
options = webdriver.ChromeOptions()
options.binary_location = "/opt/python/bin/headless-chromium"
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--single-process")
options.add_argument("--disable-gpu")
options.add_argument("--window-size=1280x1696")
options.add_argument("--disable-application-cache")
options.add_argument("--disable-infobars")
options.add_argument("--hide-scrollbars")
options.add_argument("--enable-logging")
options.add_argument("--log-level=0")
options.add_argument("--ignore-certificate-errors")
options.add_argument("--homedir=/tmp")
driver = webdriver.Chrome(
executable_path="/opt/python/bin/chromedriver",
options=options
)
driver.get(url)
return driver
from email import message
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
import smtplib
def send(subject, data, to_email):
smtp_host = '' # ホスト
smtp_port = # ポート
from_email = '' # 送信元のアドレス
username = '' # mailのアドレス
password = '' # mailのパスワード
tls = False
enable_starttls_auto = True
# メールの内容を作成
msg = MIMEMultipart('alternative')
msg.attach(MIMEText(data, 'html'))
msg['Subject'] = subject
msg['From'] = from_email
msg['To'] = to_email
# メールサーバーへアクセス
server = smtplib.SMTP(smtp_host, smtp_port)
server.ehlo()
server.starttls()
server.ehlo()
server.login(username, password)
sendToList = to_email.split(',')
server.sendmail(from_email, sendToList, msg.as_string())
server.quit()
4.Serverless Frameworkでデプロイ
2では手動でAWSの設定をしましたが、一発で簡単にデプロイできる「Serverless Framework」を教わりました。設定を記述したymlファイルさえあればコマンド一発でデプロイできるため、再現性も高くて非常に有用だと思います。
 https://serverless.com/
https://serverless.com/
まずはAWSアカウントの設定を行います。Serverless Frameworkを利用するのにAdministratorAccessのポリシーが必要になるので作成しましょう。
マネージメントコンソールのIAMへアクセスします。 ダッシュボードから「ユーザー」へ移動し、「ユーザを追加」を押します。

あとは、そのまま進んでユーザーを作成してください。ユーザーのアクセスキーとシークレットアクセスキーが必要になりますので、控えてください。
次にServerless Frameworkのインストールをします。
(serverlessはslsと書くこともできます。)
$ npm install -g serverless
$ sls -v
1.45.1
aws credential登録します。
$ sls config credentials --provider aws --key XXXXXXXXXXXXEXAMPLE --secret XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXEXAMPLEKEY
Serverless: Setting up AWS...
Serverless: Saving your AWS profile in "~/.aws/credentials"...
Serverless: Success! Your AWS access keys were stored under the "default" profile.
アプリを作成したいディレクトリで以下のコマンドを入力します。
(-t テンプレート -p アプリ名)
$ sls create -t aws-python3 -p sample-app
sample-app以下に先ほど作成したファイル(lambda_function.py, chrome_scraping.py, mail.py)を置きます。
あとはserverless.ymlを書いて、AWSの設定をします。
service: procurement-information
provider:
name: aws
runtime: python3.7
stage: pro
region: ap-northeast-1
memorySize: 400
timeout: 60
cfLogs: true
layers:
headless:
path: headless
description: chromedriver and headless-chromium
compatibleRuntimes:
- python3.7
selenium:
path: selenium
description: selenium and urllib3
compatibleRuntimes:
- python3.7
functions:
scraping:
handler: lambda_function.lambda_handler
layers:
- {Ref: HeadlessLambdaLayer}
- {Ref: SeleniumLambdaLayer}
events:
- schedule: cron(0 0 * * ? *) #UTC
私はこのように設定しました。設定の詳細については公式のドキュメントや他の記事等を見ていただけたらと思います。
Amazon CloudWatch Eventsで定期実行させるための設定は以下の部分です。
functions:
events:
- schedule: cron(0 0 * * ? *)
これでスクレイピングが日本時間午前9時に定期実行されるようになりました。
設定できたらあとは以下のコマンドでデプロイするだけです。
$ sls deploy
5.おわりに
初めて学んだことがたくさんあり、おかしなところや間違えているところもあると思います。
質問等がございましたら、コメントしていただけると幸いです。