iSCSI接続で1VMDK20万IOPS超えられる人コメントでやり方かコツを教えてください!まじで頼みます。
RDMを使わず1VMDKでIOPSの最大値を目指してみました。
参考にしたURLのメモ
Round Robin
https://kb.vmware.com/kb/2098075
PVSCSI
https://kb.vmware.com/kb/2102530
遅延ACK無効
https://kb.vmware.com/kb/2080851
vNICのバッファサイズ
https://kb.vmware.com/kb/2080532
その他参照したURL
https://www.codyhosterman.com/2017/02/understanding-vmware-esxi-queuing-and-the-flasharray/
http://it-stories.com/?p=191
https://communities.vmware.com/thread/479030
https://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/techpaper/vmware-perfbest-practices-vsphere6-0-white-paper.pdf
https://www.cisco.com/c/ja_jp/products/collateral/hyperconverged-infrastructure/hyperflex-hx-series/whitepaper_c11-738817.html
後日追記
あれこれ設定したら1VM上の1VMDKで壁だった10万IOPSを超えることができました。
いきなり結果 - データコアのマネジメントコンソールより
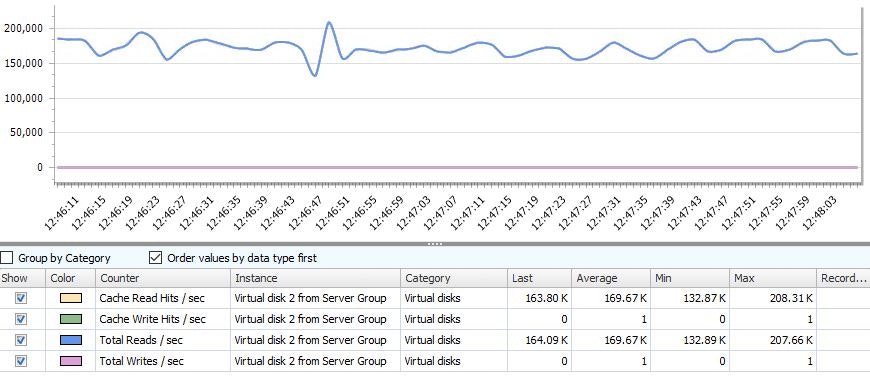 ***平均で17万、ピークで20万強出ていますね。***
***平均で17万、ピークで20万強出ていますね。***
iometer 4K random read100%

これでも応答時間は1ミリ秒を下回っているのでなかなか良好です。
CrystalDiskMark

スループットは4パス ラウンドロビンのフルレート出ていますね。
CrystalDiskMark 6.0.0 x64 (C) 2007-2017 hiyohiyo
Crystal Dew World : https://crystalmark.info/
- MB/s = 1,000,000 bytes/s [SATA/600 = 600,000,000 bytes/s]
- KB = 1000 bytes, KiB = 1024 bytes
| Sequential Read (Q= 32,T= 1) : | 4458.309 MB/s |
|---|---|
| Sequential Write (Q= 32,T= 1) : | 3100.686 MB/s |
| Random Read 4KiB (Q= 8,T= 8) : | 662.199 MB/s [ 161669.7 IOPS] |
| Random Write 4KiB (Q= 8,T= 8) : | 314.600 MB/s [ 76806.6 IOPS] |
| Random Read 4KiB (Q= 32,T= 1) : | 442.647 MB/s [ 108068.1 IOPS] |
| Random Write 4KiB (Q= 32,T= 1) : | 297.136 MB/s [ 72543.0 IOPS] |
| Random Read 4KiB (Q= 1,T= 1) : | 56.166 MB/s [ 13712.4 IOPS] |
| Random Write 4KiB (Q= 1,T= 1) : | 34.035 MB/s [ 8309.3 IOPS] |
Test : 1024 MiB [E: 0.1% (0.1/98.0 GiB)] (x5) [Interval=5 sec]
Date : 2017/12/26 12:15:03
OS : Windows Server 2016 Datacenter (Full installation) [10.0 Build 14393] (x64)
施した設定
ここからが本題です。
ESXi
esxcli system module parameters set -m iscsi_vmk -p iscsivmk_LunQDepth=8192
esxcli system module parameters set -m iscsi_vmk -p iscsivmk_LunQDepth=1024
(ESXTOP→dで見たら1024だった。これが上限っぽい)再起動が必要。
esxcli storage core device set -d naa.60030d9041e136071afe834c98970dd2 -O 8192
esxcli storage core device set -d naa.60030d9041e136071afe834c98970dd2 -m 8192
Device Max Queue Depth: 8192
No of outstanding IOs with competing worlds: 8192
対象データストアのQDを最大にしてみる。
esxcli storage nmp satp rule add -V DataCore -M "Virtual Disk" -s VMW_SATP_ALUA -c tpgs_on -P VMW_PSP_RR
データコアディスクがラウンドロビンになるようあらかじめカスタムルールを作っておく。
(本当はリスキャンしてマウントする前に打っておく)
for i in `esxcfg-scsidevs -c |awk '{print $1}' | grep naa.60030d9`; do esxcli storage nmp psp roundrobin deviceconfig set --type=iops --iops=1 --device=$i; done
ラウンドロビンを1iopsごとに変更する。ESXiでマルチパスで使う時の王道設定。

iSCSI initiator用のVMkernelを4個作って4パスでラウンドロビンしています。
esxcfg-advcfg -s 1 /Disk/ReqCallThreshold
これを設定したら性能が下がったが、レスポンスタイムの改善は見られなかった。
iSCSIイニシエーターで遅延ACK無効化する(詳細の一番下の方にある)
2018/01さらに追記
ESXi設定
esxcli system settings advanced set -o /Net/CoalesceDefaultOn -i 0
設定パラメータに追加(おまじない)
numa.nodeAffinity = 1
データコアサーバ(iSCSIターゲット)仮想マシン
CPU予約:100%、メモリ予約:100%、待ち時間感度:高
SCSIコントローラを3分割(最大値の4個使用して、1つはCドライブ用にLSI Logic SAS、残り3つはPVSCSI)
1コントローラあたりSATA SSDx2つをRDM、計6個のSSD
メモリサイズがNUMAノードにおさまる範囲に再指定
2018/01さらに追記
ESXi設定
ethernetX.coalescingScheme = "disabled"
待ち時間感度:高 にしてれば自動で無効になるっぽい。いらないかも。
データコアサーバ(iSCSIターゲット) ゲストOS(Windows)の設定
REG ADD HKLM\SYSTEM\CurrentControlSet\services\pvscsi\Parameters\Device /v DriverParameter /t REG_SZ /d "RequestRingPages=32,MaxQueueDepth=254"
VMXNET3のSmall Rx Buffersを8192に設定 (とりあえず最大値)
VMXNET3のRx Ring #1を4096に設定
DataCore HVSAN設定
Front End(Target)ポートのMax outstanding target commands:8192(最大値)に設定
ワークロードVM
CPU予約:100%、メモリ予約:100%、待ち時間感度:高
ベンチマーク対象ディスクはPVSCSI 1:0
REG ADD HKLM\SYSTEM\CurrentControlSet\services\pvscsi\Parameters\Device /v DriverParameter /t REG_SZ /d "RequestRingPages=32,MaxQueueDepth=254"
まとめ
全部デフォルトで使用していた時はいつも8~9万で頭打ちをしていたので、倍の性能が出るようになりました!
さらに追記
RDM SATA SSD x6 → VMDirectPath NVMe x1
データコアサーバのバックエンドディスクをNVMeのVMDirectPath I/O(PCIeパススルー)接続に変更したら簡単にもっと性能が出ました。
分かっちゃいたけどSSDがどんなに束になってもNVMeには敵わない。一騎当千NVMe!!
比較用画像を置いておきますね。
SSD x6

VNMe x1

さらに
ワークロード(ベンチマークを動かす)VMのPVSCSIコントローラをわけて仮想ディスク数を2個や3個増やして、ゲストOS上で記憶域プールで繋いでも、ダイナミックディスクにしてストライプしても、それぞれドライブレターを振ってワーカーを分けてみてもこれ以上性能は変わりませんでした。