これは何ですか?
Supershipグループ Advent Calendar 2021の11日目の記事になります。
12/11日のアドベントカレンダーです。
腹は減ったけど何が食べたいのか分からない問題
毎日思うことなのですが、何食べようかなと結構悩みます。
悩んでも分からないので毎日同じもの食べたり、似たようなものを食べているような気がします。
いつ何が起こるか分からない人生でいつも無難な選択をしてしまうのは何か勿体無いようにも思います。
とはいえ、意思決定というのはなかなか労力がかかるのでそれを毎日、朝、昼、夜毎回要求されるのは結構酷な話です。
こういう問題を機械学習が解決してくれないだろうかと考えたりします。
自分が好きな料理とそうでもない料理を集めたらそこそこの結果に応えてくれるモデルが作れそうではないでしょうか。
料理の特徴量とは何でしょうか?見た目という意味では画像や動画もありますが、やはり料理の過程を説明しているということで、自然言語で書かれたレシピがより良く特徴を表していると思います。
最近は改めて説明するまでもなく、大規模言語モデルをfine-tuningしてドメインを学習するようなBertやTransformerを中心とした機械学習のモデルが大きな成果をあげています。
何よりもfine-tuningして、それほど学習に多くのリソースを使わなくてもドメインに適応できる可能性が広がったことは私にとっても大変嬉しいことです。
この何が食べたいのかという問題においてもまずはBertを使ったfine-tuningで上手くいかないだろうかと考えることは自然なことです。
よく機械学習では分類のモデルを考えます。ラベルをつけて境界を引いて好きな食べもの、嫌いな食べ物を分けるやり方もありだと思います。
ただ、どのくらい好きか、どのくらい嫌いかを表現できるモデルかというとそこは難しいのではないかと思います。
最近良くConstractive LearningやMetric Learningなど距離を学習するモデルをよく耳にします。同じカテゴリにしたい特徴量のベクトルが近くなるように学習する手法です。この手法では良くcos類似度で距離によって似ている似ていないを表現することが出来ます。
そこで今回はBERTを使ったfine-tuningでレシピを学習して、cos類似度でレシピが自分の好きな料理、食べ物にどれだけ近いかを表現できるモデルを作っていこうと考えました。
レシピが似ているとは?
レシピは文章から構成されています。
つまり文章を特徴量にする方法を考えなくてはなりません。
BERTはToken毎の特徴量は出力出来ますが、文章単位ではありません。
文章単位でBERTの表現力を持った特徴量が使えるにはどうしたら良いでしょうか。
そこでSentence-Bertという論文が2019年に発表されています。
これはBERTの出力の後にPooling層を設けてここでBERTの特徴量を文章単位に埋め込んでいます。そしてこの出力を損失関数に渡して学習を進めます。
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
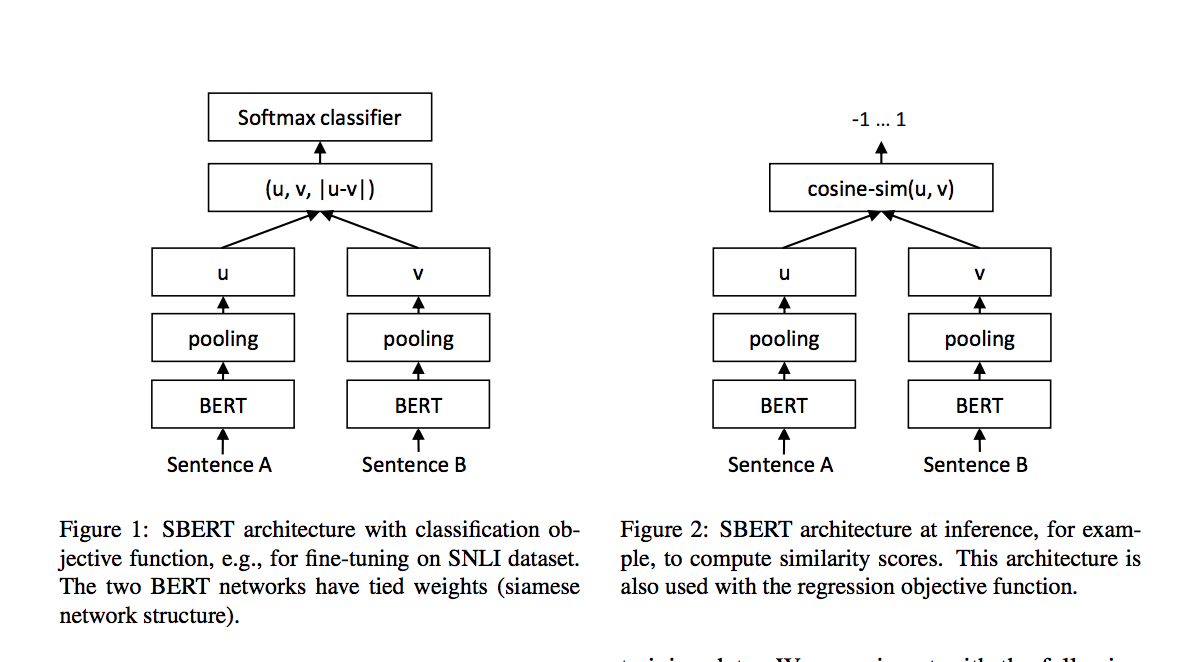
↑この上の図がほぼ全てなのですが、今回使おうとしているのは右のネットワークです。
そして損失関数ではTriplet Lossを使いました。
Triplet LossについてはSentence-bertの論文でも引用されていますが、FaceNetの論文の図が分かり易かったです。FaceNetはコンピュータビジョンの話で自然言語処理ではないですが。
Triplet Lossの学習では特徴量を3つに分けます。
anchor, positive, negativeというデータセットを用意します。
anchorとpositiveのベクトルが近づくように、anchorとnegativeのベクトルが離れうように学習します。
例えば今扱おうとしているレシピであれば、好きなレシピをanchorとpositiveに使って、あまり好きではないレシピをnegativeのデータセットに用意します。
FaceNet: A Unified Embedding for Face Recognition and Clustering
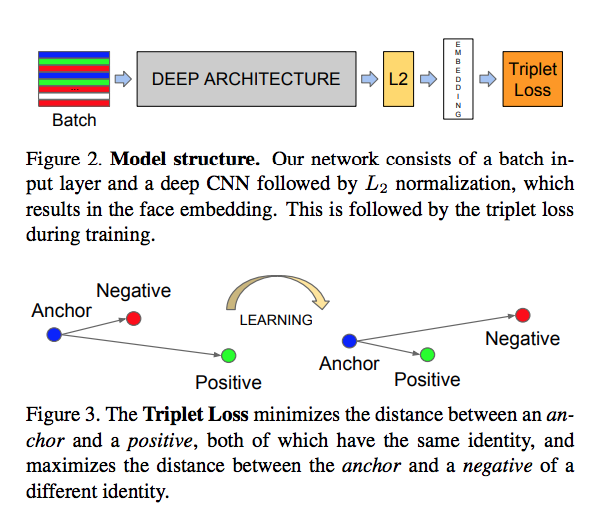
どういうデータが集まれば問題が解決できそうか
ある程度の方針が決まったのでデータを集めようとします。
今回は白ご飯.comとキッコーマンのレシピを使います。
この2つを選んだ理由は特にありません。
白ご飯.comを学習データにしてキッコーマンのレシピで評価します。
どうやってデータを集めるか?
白ご飯.comには8つのカテゴリがあり、そこからanchor, positiveに使うために15レシピずつ、negativeのデータのために15レシピ選んでいます。
あくまで私が好きかどうかが基準で個人的な好みで選んでいます。
好きなレシピのURLをjsonで書き込んでいきます。
↓jsonはこのような感じです
[
"https://www.sirogohan.com/sp/recipe/kayakugohan/",
"https://www.sirogohan.com/sp/recipe/sabagohan/",
"https://www.sirogohan.com/sp/recipe/matutakegohan/",
"https://www.sirogohan.com/sp/recipe/kakigohan/~",
"https://www.sirogohan.com/sp/recipe/edamameumegohan/",
"https://www.sirogohan.com/sp/recipe/daizugohan/",
"https://www.sirogohan.com/sp/recipe/taimesi/",
"https://www.sirogohan.com/sp/recipe/kinokogohan/",
"https://www.sirogohan.com/sp/recipe/gyuugohan/",
# --- 省略 --- #
これをPythonで取得してこのURLをクローリングしていきます。
ということでデータを集めていきます。
データを集める
PythonのScrapyというクローリングのフレームワークを使っていきます。
pythonは3.9です。
プロジェクトを作って、ライブラリをインストールします。
ちなみにソースはgithubで公開予定です
https://github.com/tsukudamayo/what-should-i-eat
git clone https://github.com/tsukudamayo/what-should-i-eat.git
cd what-should-i-eat/
poetry new what_should_i_eat_crawler
cd what_should_i_eat_crawler/
poetry add scrapy beautifulsoup4
poetry shell
scrapy startproject でソースが自動で生成されます
scrapy startproject what_should_i_eat
spiderというディレクトリの中にクローラーとパーサーを書いていきます。
# what-should-i-eat/what_should_i_eat_crawler/what_should_i_eat_crawler/what_should_i_eat/what_should_i_eat/spiders/like_spider.py
import scrapy
class LikeSpider(scrapy.Spider):
name = "like"
def start_requests(self) -> scrapy.Request:
urls = []
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response: scrapy.http.Response):
"""
@url https://www.sirogohan.com/recipe/wahuukare-/
"""
print("url : ", response.url)
cd what_should_i_eat/
parseという関数の下にURLを書いておくとそのURLを1つ選んでscrapy check spider_name でテストできるのでクローラーを全部回さなくていいので便利です。
ScrapyのContractという機能のようでコメントにテスト用のプロパティを書くみたいです。
ちょっと変わっています。
Spiders Contracts - Scrapy 2.5.1 documentation
scrapy check -l
like
* parse
引き続き実装していきます。
# what-should-i-eat/what_should_i_eat_crawler/what_should_i_eat_crawler/what_should_i_eat/what_should_i_eat/spiders/like_spider.py
from typing import Iterable, Dict, List
import scrapy # type: ignore
from bs4 import BeautifulSoup # type: ignore
class LikeSpider(scrapy.Spider):
name = "like"
def start_requests(self) -> Iterable[scrapy.Request]:
urls: List[str] = []
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response: scrapy.http.Response) -> Iterable[Dict]:
"""
@url https://www.sirogohan.com/recipe/wahuukare-/
@returns item 1 1
@scrapes title recipe
"""
item = {}
soup = BeautifulSoup(response.text, "html.parser")
title = soup.title.string
recipe_elements = soup.find("div", class_="howto-block")\
.find_all("p")
recipe_list = [r.text for r in recipe_elements]
recipe = "".join(recipe_list)
print("url : ", response.url)
print("title : ", title)
print("recipe")
print(recipe)
item["title"] = title
item["recipe"] = recipe
yield item
scrapy check like
url : https://www.sirogohan.com/recipe/wahuukare-/
----------------------------------------------------------------------
Ran 0 contracts in 0.757s
OK
scrapy check like
url : https://www.sirogohan.com/recipe/wahuukare-/
title : 和風カレーのレシピ(ルー不使用のあっさり系!):白ごはん.com
recipe
和風カレーの材料は、豚肉に定番の野菜を用意して作ります。しめじや椎茸、えのきなどのきのこ類、いんげん
やグリーンピースなどの青みを入れても美味しく、和風っぽさもアップします。市販のルー代わりに用意するの
は、カレー粉、小麦粉、片栗粉の3種です。※香りづけに生姜とにんにくも使っています。これは生のものがなけ
ればチューブのおろしたものでも代用可です。玉ねぎは5~6㎜幅に、にんじんは小さめの乱切りに、じゃがいも
は少し大きめに切って水にさらしておきます。いんげんは3~4㎝幅に、しめじは石づきを切り落とし、生姜とに
んにくは生のものを使うのであれば粗いみじん切りにしておきます(生姜は短めのせん切りでもOK)。※豚肉は、
こま切れ肉が長いようなら3㎝幅ほどに切り、バラ肉なら3~4㎝幅に切っておきましょう。また、ルー代わりのA
の材料3つも(野菜を煮込むタイミングでもいいので)容器に水100mlと混ぜ合わせておきます。カレー粉、小麦粉、片栗粉を合わせ、はじめに半分強くらいの水を入れてよく練ってから、後から残りの水を加えて混ぜる、こ
うするとダマになりにくいです(箸でも混ぜやすいです)。
..
----------------------------------------------------------------------
Ran 2 contracts in 0.867s
OK
一つのURLに対して実行出来ることが確認できたのでURLのリストを作ります。
ここは自動で作成すると自分の好きな食べ物嫌いな食べ物を選んでいるのか分からないので手動で選んでjsonに書き込んでいきます。
カテゴリーが8つあるのでanchor, pos, negにそれぞれ15ずつ選んでレシピを入れていきます。
anchor, posには好きな食べ物、negには嫌いな食べ物を入れていきます。
好きな食べ物を210レシピ、嫌いな食べ物を105レシピ集めます。(各カテゴリから15レシピずつ)
それでは集めます。
だいたい240レシピで3~4時間ほどかかりました。
だいたい画像の見た目だけで選んでいたので、もしこのモデルの精度がよかったらただの食わず嫌いじゃないかと思ったのですが、あれこれ考えるときりがないのでそのまま進めます。
集めました。
好きな食べものと嫌いな食べものに分けてjsonファイルを作りました。
これをもとにクローリングしていこうと思います。
まずファイルからURLを読み込んでクローリング出来るようにします。
サーバーの負荷がかからないようにリクエストの間隔を3秒にしておきます。
# settings.py
# --- 省略 ---
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
# CONCURRENT_REQUESTS_PER_DOMAIN = 16
# CONCURRENT_REQUESTS_PER_IP = 16
# --- 省略 ---
ファイルにアクセスするためにPROJECT_ROOTを設定
# settings.py
import os
# --- 省略 ---
PROJECT_ROOT = os.path.abspath(os.path.dirname(__file__))
PROJECT_ROOTに設定したディレクトリにinputというディレクトリを作ってlikes.jsonとdislikes.jsonを配置します。
ファイルを読み込めるようにソースを書き換えます。
# what-should-i-eat/what_should_i_eat_crawler/what_should_i_eat_crawler/what_should_i_eat/what_should_i_eat/spiders/like_spider.py
import json
import os
from typing import Iterable, Dict, List
import scrapy # type: ignore
from bs4 import BeautifulSoup # type: ignore
from what_should_i_eat import settings
DATA_DIR = settings.PROJECT_ROOT
LIKE_FILE = os.path.join(DATA_DIR, "input", "likes.json")
DISLIKE_FILE = os.path.join(DATA_DIR, "input", "dislikes.json")
class LikeSpider(scrapy.Spider):
name = "like"
def start_requests(self) -> Iterable[scrapy.Request]:
dataset = [LIKE_FILE, DISLIKE_FILE]
functions = [self.parse_likes, self.parse_dislikes]
urls: List[str] = []
for d, f in zip(dataset, functions):
with open(d) as r:
data = json.load(r)
urls = data
for url in urls:
yield scrapy.Request(url=url, callback=f)
def parse_likes(self, response: scrapy.http.Response) -> Iterable[Dict]:
"""
@url https://www.sirogohan.com/recipe/wahuukare-/
@returns item 1 1
@scrapes title recipe category
"""
item = self.fetch_title_and_recipe(response)
item["category"] = "like"
yield item
def parse_dislikes(self, response: scrapy.http.Response) -> Iterable[Dict]:
"""
@url https://www.sirogohan.com/sp/recipe/kabochagohan/
@returns item 1 1
@scrapes title recipe category
"""
item = self.fetch_title_and_recipe(response)
item["category"] = "dislike"
yield item
def fetch_title_and_recipe(self, response: scrapy.http.Response) -> Dict:
item = {}
soup = BeautifulSoup(response.text, "html.parser")
title = soup.title.string
recipe_elements = soup.find("div", class_="howto-block")\
.find_all("p")
recipe_list = [r.text for r in recipe_elements]
recipe = "".join(recipe_list)
print("url : ", response.url)
print("title : ", title)
print("recipe")
print(recipe)
item["title"] = title
item["recipe"] = recipe
return item
そしてテストします。
scrapy check like
url : https://www.sirogohan.com/sp/recipe/kabochagohan/
title : かぼちゃの炊き込みご飯のレシピ/作り方:白ごはん.com
recipe
まず、かぼちゃの下ごしらえの前に、米3合を研いで炊飯器の内釜にセットし、2合強くらいの水を加え、30分
〜1時間ほど置いて浸水させます(←後から調味料を加えるので、その分を考えてはじめに加える水を少なめに
します)。かぼちゃは、種をスプーンで軽く取り除いてから1/4個のかぼちゃをさらに半分に切ります。かぼち
ゃの切り口をまな板に付け、ぐらつかないよう手でしっかりと押さえて切りましょう。続けて、かぼちゃの皮
にイボや色の変わった硬い皮の部分があれば、ピーラーや包丁で薄く削り落とします。※硬いものを切る時は、
包丁の刃先よりも持ち手に近い刃元の方が力が伝わりやすいので、真ん中から刃元に近い部分で切るとよいで
す。
..url : https://www.sirogohan.com/recipe/wahuukare-/
title : 和風カレーのレシピ(ルー不使用のあっさり系!):白ごはん.com
recipe
和風カレーの材料は、豚肉に定番の野菜を用意して作ります。しめじや椎茸、えのきなどのきのこ類、いんげ
んやグリーンピースなどの青みを入れても美味しく、和風っぽさもアップします。市販のルー代わりに用意す
るのは、カレー粉、小麦粉、片栗粉の3種です。※香りづけに生姜とにんにくも使っています。これは生のもの
がなければチューブのおろしたものでも代用可です。玉ねぎは5~6㎜幅に、にんじんは小さめの乱切りに、じ
ゃがいもは少し大きめに切って水にさらしておきます。いんげんは3~4㎝幅に、しめじは石づきを切り落とし
、生姜とにんにくは生のものを使うのであれば粗いみじん切りにしておきます(生姜は短めのせん切りでもOK)
。※豚肉は、こま切れ肉が長いようなら3㎝幅ほどに切り、バラ肉なら3~4㎝幅に切っておきましょう。また、
ルー代わりのAの材料3つも(野菜を煮込むタイミングでもいいので)容器に水100mlと混ぜ合わせておきます
。カレー粉、小麦粉、片栗粉を合わせ、はじめに半分強くらいの水を入れてよく練ってから、後から残りの水
を加えて混ぜる、こうするとダマになりにくいです(箸でも混ぜやすいです)。
..
----------------------------------------------------------------------
Ran 4 contracts in 11.616s
OK
実際にクローリングをしていきます。
settings.pyのpipelinesの設定のコメントアウトを外します。
# settings.py
# --- 省略 ---
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'what_should_i_eat.pipelines.WhatShouldIEatPipeline': 300,
}
# --- 省略 ---
最終的にキッコーマンのSpiderも作りました。
# kikkoman_spider.py
from typing import Iterable, List, Dict
import scrapy # type: ignore
from bs4 import BeautifulSoup # type: ignore
class KikkomanSpider(scrapy.Spider):
name = "kikkoman"
def start_requests(self) -> Iterable[scrapy.Request]:
for n in range(1015, 2015):
url = f"https://www.kikkoman.co.jp/homecook/search/recipe/0000{str(n)}/index.html"
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response: scrapy.http.Response) -> Dict:
"""
@url https://www.kikkoman.co.jp/homecook/search/recipe/00001014/index.html
@returns item 1 1
@scrapes title recipe category
"""
item = {}
soup = BeautifulSoup(response.text, "html.parser")
title = soup.title.string
recipe_elements = soup.find_all("span", class_="instruction")
recipe_list = [r.text for r in recipe_elements]
recipe = "".join(recipe_list)
print("url : ", response.url)
print("title : ", title)
print("recipe : ", recipe)
item["title"] = title
item["recipe"] = recipe
item["category"] = "eval"
return item
pipelines.pyはこうなりました。
# pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import os
from typing import Dict
import scrapy # type: ignore
from what_should_i_eat import settings
OUTPUT_DIR = os.path.join(settings.PROJECT_ROOT, "input")
class WhatShouldIEatPipeline:
def process_item(self, item: Dict, spider: scrapy.Spider) -> None:
adapter = ItemAdapter(item)
print("adapter")
print(adapter)
if adapter["category"] == "like":
self.output_csv("likes_recipe.tsv", adapter)
elif adapter["category"] == "dislike":
self.output_csv("dislikes_recipe.tsv", adapter)
elif adapter["category"] == "eval":
self.output_csv("eval.tsv", adapter)
else:
raise NotImplementedError("Error adapter.get(category)")
return None
def output_csv(self, filename: str, adapter: ItemAdapter) -> None:
filepath = os.path.join(OUTPUT_DIR, filename)
print("filepath : ", filepath)
with open(filepath, "a", encoding="utf-8") as w:
w.write(adapter["title"] + "\t" + adapter["recipe"])
w.write("\n")
return None
学習
クローリングで学習データが出来たので機械学習をやっていきます
GCPのVertex AI Workbenchを使って学習していきます。
必要なライブラリをインストールしていきます。
pytorchやnumpy, pandas, scikit-learnなどはあらかじめインストールされていました。
pip install transformers fugashi ipadic sentence_transformers
ライブラリ import
from typing import List, Dict, Optional
import numpy as np
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
import torch
from torch import Tensor
import torch.nn as nn
from torch.utils.data import DataLoader
import transformers
transformers.BertTokenizer = transformers.BertJapaneseTokenizer
from sentence_transformers import SentenceTransformer
from sentence_transformers import models
from sentence_transformers.losses import TripletDistanceMetric, TripletLoss
from sentence_transformers.evaluation import TripletEvaluator
from sentence_transformers.readers import TripletReader
from sentence_transformers.datasets import SentencesDataset
嫌いな食べ物データを読み込みます。
df_dislike = pd.read_csv(
"../input/dislikes_recipe.ts v",
delimiter="\t",
header=None,
names=["title", "recipe"],
)
df_dislike = df_dislike.dropna()
好きな食べ物データも読み込みます。
df_like = pd.read_csv(
"../input/likes_recipe.tsv",
delimiter="\t",
header=None,
names=["title", "recipe"],
)
df_like = df_like.dropna()
データをシャッフルします。
df_like_sample = df_like.sample(frac=1, random_state=SEED)
df_dislike_sample = df_dislike.sample(frac=1, random_state=SEED)
anchor, pos, negにデータを分けます。
anchor_sample = df_like_sample[:100]
pos_sample = df_like_sample[100:]
neg_sample = df_dislike_sample[:100]
anchor_caption = anchor_sample["recipe"].values
pos_caption = pos_sample["recipe"].values
neg_caption = neg_sample["recipe"].values
triplet_train_dataset = pd.DataFrame({
"anchor": anchor_caption,
"pos": pos_caption,
"neg": neg_caption,
}).reset_index()
triplet_train_dataset.to_csv(
"train.tsv",
sep="\t",
index=False,
)
学習データができたので学習していこうと思います。
transformer = models.Transformer("cl-tohoku/bert-base-japanese-whole-word-masking")
pooling = models.Pooling(
transformer.get_word_embedding_dimension(),
pooling_mode_mean_tokens=True,
)
model = SentenceTransformer(modules=[transformer, pooling])
triplet_reader = TripletReader(".")
train_dataset = SentencesDataset(
triplet_reader.get_examples("train.tsv"),
model=model,
)
BATCH_SIZE = 4
NUM_EPOCH = 5
EVAL_STEPS = 1000
WARMUP_STEPS = int(len(train_dataset) // BATCH_SIZE * 0.1)
train_dataloader = DataLoader(
train_dataset,
shuffle=False,
batch_size=BATCH_SIZE,
)
train_loss = TripletLoss(
model=model,
distance_metric=TripletDistanceMetric.EUCLIDEAN,
triplet_margin=1,
)
model.fit(
train_objectives=[(train_dataloader, train_loss)],
epochs=NUM_EPOCH,
evaluation_steps=EVAL_STEPS,
warmup_steps=WARMUP_STEPS,
output_path="./sbert",
)
ここでTransformerはそのままのTransformerです。
ちょっと説明がいるとすれば、PoolingとTriplet Lossなのですが、コードを見るとなんとなくわかります。
ソースは↓です。
https://github.com/UKPLab/sentence-transformers
# Pooling.py
def forward(self, features: Dict[str, Tensor]):
token_embeddings = features['token_embeddings']
attention_mask = features['attention_mask']
## Pooling strategy
output_vectors = []
if self.pooling_mode_cls_token:
cls_token = features.get('cls_token_embeddings', token_embeddings[:, 0]) # Take first token by default
output_vectors.append(cls_token)
if self.pooling_mode_max_tokens:
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
token_embeddings[input_mask_expanded == 0] = -1e9 # Set padding tokens to large negative value
max_over_time = torch.max(token_embeddings, 1)[0]
output_vectors.append(max_over_time)
if self.pooling_mode_mean_tokens or self.pooling_mode_mean_sqrt_len_tokens:
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
#If tokens are weighted (by WordWeights layer), feature 'token_weights_sum' will be present
if 'token_weights_sum' in features:
sum_mask = features['token_weights_sum'].unsqueeze(-1).expand(sum_embeddings.size())
else:
sum_mask = input_mask_expanded.sum(1)
sum_mask = torch.clamp(sum_mask, min=1e-9)
if self.pooling_mode_mean_tokens:
output_vectors.append(sum_embeddings / sum_mask)
if self.pooling_mode_mean_sqrt_len_tokens:
output_vectors.append(sum_embeddings / torch.sqrt(sum_mask))
output_vector = torch.cat(output_vectors, 1)
features.update({'sentence_embedding': output_vector})
return features
Pooling.pyのforwardの関数だけ抜粋しています。
Poolingもいくつかの方法を試したと論文で言っていて、tokenをmax,meanでPoolingするか最初のトークンを取得するか、全部盛りにするか試して、平均が一番よかったようなので私も平均でPoolingしています。
if self.pooling_mode_mean_tokensのところが平均でPoolingしているところです。
token_embeddingをsumして1次元にしてmaskの数で割って平均しています。
torch.clampは1e-9以下にならないようにして学習が進まなくなるのを避けているのだと思います。
# TripletLoss.py
import torch
from torch import nn, Tensor
from typing import Union, Tuple, List, Iterable, Dict
import torch.nn.functional as F
from enum import Enum
from ..SentenceTransformer import SentenceTransformer
class TripletDistanceMetric(Enum):
"""
The metric for the triplet loss
"""
COSINE = lambda x, y: 1 - F.cosine_similarity(x, y)
EUCLIDEAN = lambda x, y: F.pairwise_distance(x, y, p=2)
MANHATTAN = lambda x, y: F.pairwise_distance(x, y, p=1)
class TripletLoss(nn.Module):
"""
This class implements triplet loss. Given a triplet of (anchor, positive, negative),
the loss minimizes the distance between anchor and positive while it maximizes the distance
between anchor and negative. It compute the following loss function:
loss = max(||anchor - positive|| - ||anchor - negative|| + margin, 0).
Margin is an important hyperparameter and needs to be tuned respectively.
For further details, see: https://en.wikipedia.org/wiki/Triplet_loss
:param model: SentenceTransformerModel
:param distance_metric: Function to compute distance between two embeddings. The class TripletDistanceMetric contains common distance metrices that can be used.
:param triplet_margin: The negative should be at least this much further away from the anchor than the positive.
Example::
from sentence_transformers import SentenceTransformer, SentencesDataset, LoggingHandler, losses
from sentence_transformers.readers import InputExample
model = SentenceTransformer('distilbert-base-nli-mean-tokens')
train_examples = [InputExample(texts=['Anchor 1', 'Positive 1', 'Negative 1']),
InputExample(texts=['Anchor 2', 'Positive 2', 'Negative 2'])]
train_dataset = SentencesDataset(train_examples, model)
train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=train_batch_size)
train_loss = losses.TripletLoss(model=model)
"""
def __init__(self, model: SentenceTransformer, distance_metric=TripletDistanceMetric.EUCLIDEAN, triplet_margin: float = 5):
super(TripletLoss, self).__init__()
self.model = model
self.distance_metric = distance_metric
self.triplet_margin = triplet_margin
def get_config_dict(self):
distance_metric_name = self.distance_metric.__name__
for name, value in vars(TripletDistanceMetric).items():
if value == self.distance_metric:
distance_metric_name = "TripletDistanceMetric.{}".format(name)
break
return {'distance_metric': distance_metric_name, 'triplet_margin': self.triplet_margin}
def forward(self, sentence_features: Iterable[Dict[str, Tensor]], labels: Tensor):
reps = [self.model(sentence_feature)['sentence_embedding'] for sentence_feature in sentence_features]
rep_anchor, rep_pos, rep_neg = reps
distance_pos = self.distance_metric(rep_anchor, rep_pos)
distance_neg = self.distance_metric(rep_anchor, rep_neg)
losses = F.relu(distance_pos - distance_neg + self.triplet_margin)
return losses.mean()
処理はforwardのところでTransformerとPoolingを通ったsentenceをembeddingした特徴量がposとnegに分けられて、posはanchorと近づくように、negはanchorと離れるように設計されているのが分かります。
学習が終わりました。
評価
今回はanchorのデータセットと評価用のキッコーマンのデータセットの類似度を測ってキッコーマンのデータセットから好きなレシピが見つけられるかを確かめたいと思います。
# Eval Dataset
sbert = SentenceTransformer("sbert/")
# キッコーマンのレシピをクローリングしたデータ
eval_df = pd.read_csv(
"../input/eval.tsv",
delimiter="\t",
header=None,
names=["title", "recipe"],
)
# anchorとキッコーマンのレシピの類似度を測る
train_anchor_vectors = sbert.encode(train_anchor_caption)
eval_vectors = sbert.encode(eval_caption)
嫌いな食べ物(スコアの下位)好きな食べ物(スコアの上位)5つを抽出しました。
score = [cosine_similarity([e], train_anchor_vectors).mean() for e in eval_vectors]
eval_df["score"] = score
eval_df.sort_values("score", ascending=False)

私の好き嫌いを誰もしらないと思うのでコメントしておきます。
嫌いなもの5位
ワインクーラー?
酒やないか!!!
学習データにないからな...(酒は好きです)
嫌いなもの4位
パエリア?
食ったことないな...
チャーハンは好きですよ
まあ食べたいt思ったことはないけど、嫌いってことはないようなきがする
嫌いなもの3位
白玉冷やし汁粉?
ぜんざいは好きです...
嫌いなもの2位
ハンバーグステーキ?
めちゃめちゃ好きです!
嫌いなもの1位
赤飯
そうです!私は赤飯が大嫌いです!
好きなもの5位
きのこうどん
麺類はたいがい好きです!
好きなもの4位
ごちそうちらし寿司
ちらし寿司もそうだけど、ごちそうって書いてるから好きでしょう
好きなもの3位
中華鶏がゆ
まあ確かに好きです、サムゲタンみたいなのかな
好きなもの2位
さつまいもの甘煮
確かにこれは美味しい
好きなもの1位
きのこ入り野菜の酢の物...
嫌いじゃないけど1位が地味すぎる...
もっとすき焼きとかトンカツとか唐揚げ、カレー、ラーメンあたりが入ってくるかと思っていましたが
まだまだ改良の余地がありそうです
データもまだまだ取れるので、手法とともに改良していきたいと思います(誰が興味あんねん!)