概要
リップシンクとは, ゲームのキャラクターなどが口をパクパクさせるやつです.
面白そうなので, なんとなくこれを作ってみました.
リップシンクの手法は軽く調べた限り
- 手動で頑張る
- 音量の大小でテキトーに口動かす
- 映像から口の形を引っこ抜く
- 音から口の形を類推する
があるようです.
今回は一番下の音から口の形を類推させてみました.
モデルの方針
声のデータから口の形≒母音の種類を当てる分類モデルを作ります.
そのために, データセットとして「音声」と「母音の文字」のセットを作ります.
データセットについて
方針としては
- 「音源」と「その音源の文字起こし」のセットを取得
- 「その音源の文字起こし」を仮名に直す
- 「音源」のどの時間に, その仮名を言っているのか割り当てる
「音源」と「その音源の文字起こし」のセットを取得
「音源」と「その音源の文字起こし」の2つがセットになっているデータを片っ端から集めました.
音声素材サイトや研究機関など色々なサイトを参考にしましたが, 中でも日本声優統計学会という同人サークルのサイトが良くまとまっており参考になりました.
「その音源の文字起こし」を仮名に直す
入れた文章をひらがなに変換すれば解決します.
そのために, Mecabと呼ばれる日本語の自然言語処理エンジンを用いました.
MeCabといえども, 多少のふり間違いがあるので, そこは気合でなおします.
「音源」のどの時間に, その仮名を言っているのか割り当てる
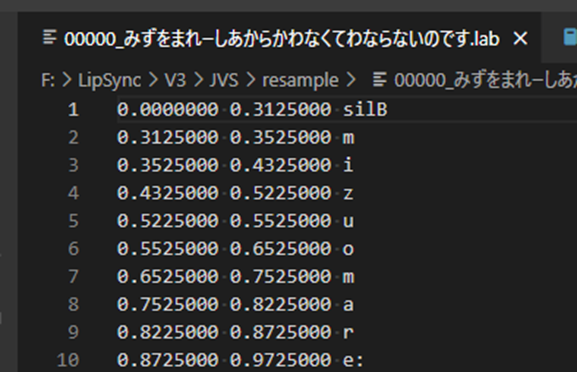
Julisという汎用大語彙連続音声認識エンジンをもちいることで, 「音源」と「仮名データ」を入れることでどのタイミングでどの音が鳴っているか割り当ててくれます.
↓こんな感じ
特徴量と目的変数について
音声データを細く切り, その音声データ加工して特徴量とします.
また, そのときの母音を目的変数とします.
- 特徴量
- メル周波数スペクトル係数
- Zero-crossing rate
- 上記の特徴量の一階/二階の時間微分
- 話者の性別
- 男ならTrue
- 目的変数
- 母音の種類
- 「あいうえおん」の多値分類
- 母音の種類
「メル周波数スペクトル係数」や「Zero-crossing rate」などの見慣れない単語が出てきたと思うので, 解説します.
メル周波数スペクトル係数
メル周波数スペクトル係数は, 以下の3つのステップで計算できます
- フーリエ変換しパワースペクトル取得
- メル変換
- コサイン逆変換して高次成分を無視する
メル変換
心理学的に, 人間にとって高音域は低音域に比べ鈍感らしいです.
その感覚に沿ったスケールに非線形変換をします.
コサイン逆変換して高次成分を無視する
詳しく調べていないのですが, グラフの高波数成分を除去してなめらかにしているのだと思います.
パワースペクトルは波数に対し偶関数なので, 逆フーリエ変換ではなく, コサイン逆変換なのだと思います.
Zero-crossing rate
文字通り, 単位時間あたりに振幅が0を通る回数です.
モデルについて
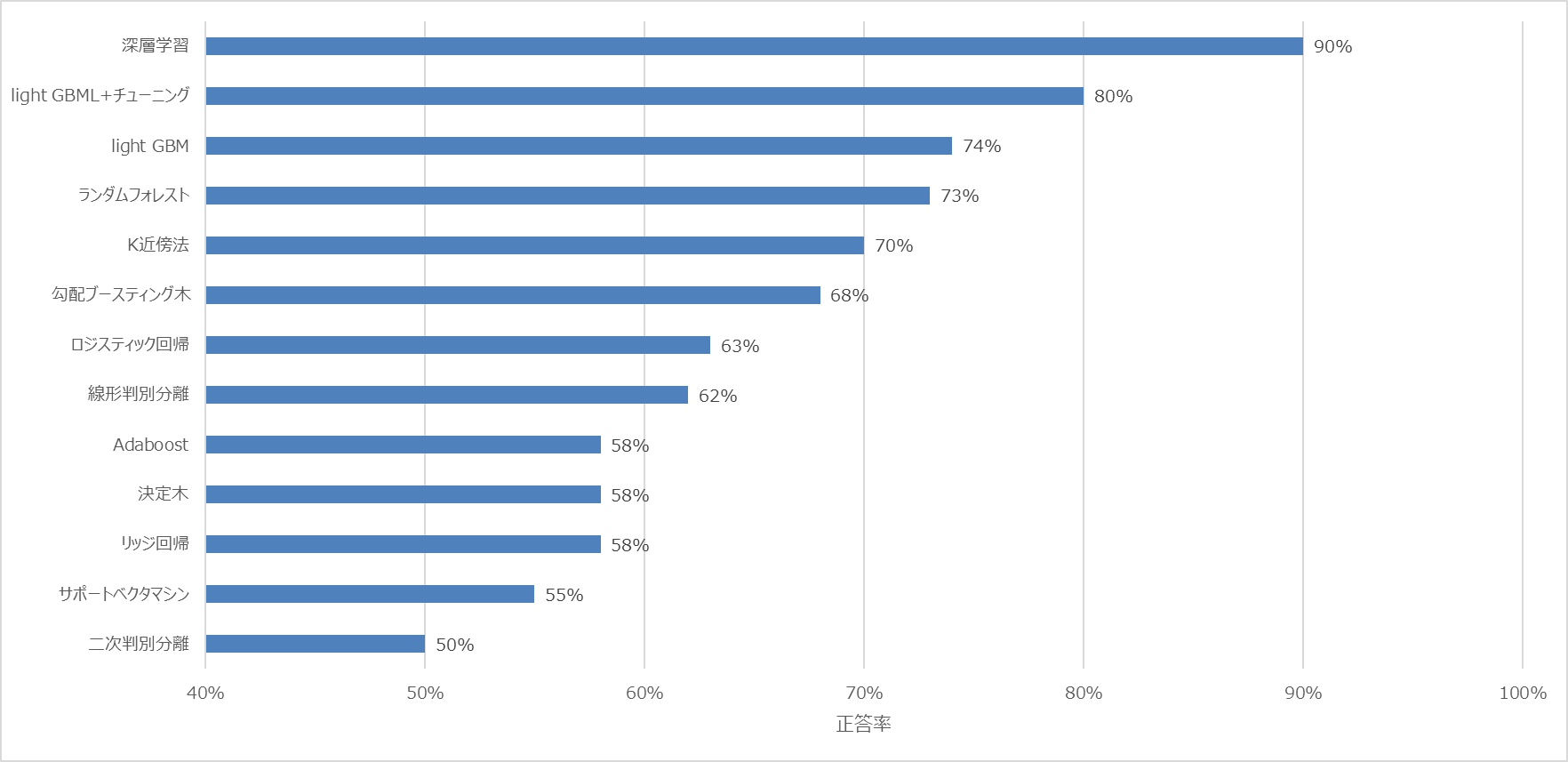
様々なモデルで試したところ, (やっぱり)深層学習が一番正答率が高かったので, 深層学習を採用しました.
マイクによるリアルタイムリップシンク
マイクに入ってきた音にこのモデルをかませることで, リアルタイムにリップシンクさせてみました.
アルゴリズムとしては
- マイクの音声を短時間取得
- 音が閾値より大きければ
- その音をもとに特徴量計算
- モデルから母音を推定
- 各母音に対応する画像を表示
- 音が閾値より小さければ
- 口をつぐんだ画像表示
- 音が閾値より大きければ
- はじめに戻る
といった簡単なものです.
一応コードを載せておきます.
import cv2
import pyaudio
from tensorflow import keras
model = keras.models.load_model("モデルのパス")
char_map = {
0:cv2.imread('./img/n.png'),
1:cv2.imread('./img/a.png'),
2:cv2.imread('./img/i.png'),
3:cv2.imread('./img/u.png'),
4:cv2.imread('./img/e.png'),
5:cv2.imread('./img/o.png'),
}
buffer_size = 2048
sampling_rate = 22050
def audiostart():
audio = pyaudio.PyAudio()
stream = audio.open(
format = pyaudio.paInt16,
rate = sampling_rate,
channels = 1,
input_device_index = 1,
input = True,
frames_per_buffer = buffer_size
)
return audio, stream
def audiostop(audio, stream):
stream.stop_stream()
stream.close()
audio.terminate()
(audio,stream) = audiostart()
is_male=np.ones((3,1),dtype=np.float32)
while True:
try:
y = stream.read(buffer_size)
y = ( np.frombuffer(y, dtype='int16')/10000 ).astype(np.float32)
rms=np.mean( librosa.feature.rms(y) )
if rms<0.01:
itr = 0
else:
# ここにyから特徴量Xを作るコード書く
itr=np.argmax( np.sum(model.predict(X),axis=0) )
# 口の画像表示
cv2.imshow('Video', char_map[itr])
k = cv2.waitKey(1)
if k == 27:#キーボードからESC(27)が入力されたら終了
audiostop(audio,stream)
break
except KeyboardInterrupt:
audiostop(audio,stream)
break