はじめに
まず初めに私はプログラミングのド素人ですのでPythonの勉強がてらWebスクレイピングに挑戦してみました。
なのですごく当たり前の様な記事になってしまいますが、
私同様に初めたての人が同じところで躓いてほしくないなという思いから記事にしました。
またスクレイピングに関しては警察沙汰になっている事例もあるそうなのでお気を付けください・・・。
ざっくりとした内容
CSVから建物の名前を取得しその建物名でグーグル検索を行いヒットした住所をCSVに吐き出します。
CSVはこんなかんじで・・・

グーグル検索は下記の様な検索結果が表れた時だけ住所を取得してきます。
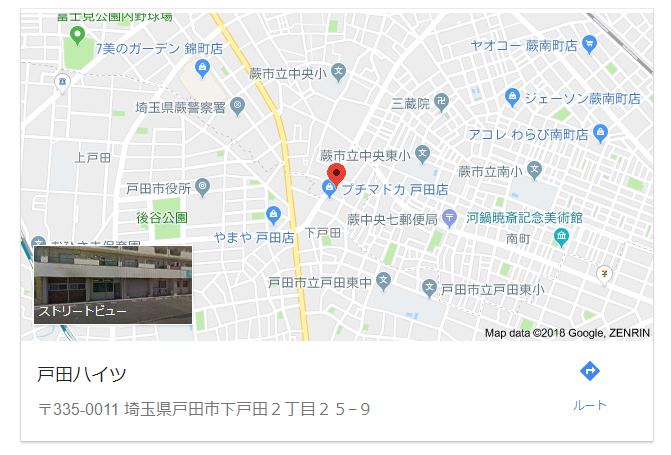
そのためよくある名前の建物だとこの多数表示される結果になるため住所が引っ張ってこれません。
開発環境
PCスペック:Wind10 Pro(64Bit) メモリ8G
使用ソフト:WinPython-64Bit-3.4.4.2
Spyder(Python3.4)
WinPython Command Prompt.exe
※なぜだか最新版のWinPythonを使用するとSpyderが起動しませんでした。
フォーラムを見ているとWin10だと最新版だと動かないとかなんとか・・・
そのためちょっと古いバージョンを使用しています。
要はWinPythonを使いました。
コード
import requests
import re
from bs4 import BeautifulSoup
import csv
import time
import pandas as pd
buken = list()
for file in csv.reader(open(r"CSVがおいてあるパス"),delimiter=','):
buken.append(file[1])
i = 0
ID = list()
for aa in buken:
target_url = "http://www.google.co.jp/search?hl=jp&gl=JP&num=10&q=" + buken[i]
r = requests.get(target_url)
time.sleep(10)
soup = BeautifulSoup(r.text, 'html.parser')
for a in soup.find_all("b",text=re.compile("〒")):
ID.append([buken[i]+","+a.string])
i = i + 1
print(str(i) + "件目")
df = pd.DataFrame(ID)
df.to_csv(r"CSVを吐き出す先のパス", index=False, header=False, sep="\t")
コードの解説
import requests
import re
from bs4 import BeautifulSoup
import csv
import time
import pandas as pd
言わずもがなの使用するパッケージ?のインポートです
BerutifulSoupのみなぜfrom bs4と記述しているのかわからないまま使っています。
次の場所でCSVからスクレイピング対象データを取り込むためCSVもインポートします。
buken = list()
bukenというリストの作成です・・・。
for file in csv.reader(open(r"CSVがおいてあるパス"),delimiter=','):
buken.append(file[1])
CSVを開き建物名を片っ端からbukenのリストに叩き込んでいきます。
ここでcsvのパッケージを使っていきます。
"CSVが置いてあるパス"の前にrが単発で置いてあるのには訳があり
\t等々のエスケープシーケンスがありファイルパスが万が一それに該当するとエラーになる・・・というのを回避するおまじないです。
エスケープシーケンスについてはこちらを・・・
https://www.javadrive.jp/python/string/index2.html
for aa in buken:
target_url = "http://www.google.co.jp/search?hl=jp&gl=JP&num=10&q=" + buken[i]
r = requests.get(target_url)
time.sleep(10)
soup = BeautifulSoup(r.text, 'html.parser')
for a in soup.find_all("b",text=re.compile("〒")):
ID.append([buken[i]+","+a.string])
i = i + 1
print(str(i) + "件目")
今回のキモの部分です
まずtarget_urlにてグーグル検索のURL+建物の名前をセットします。
このtarget_urlを使用しrequests.get(target_url)にて検索結果のレスポンスオブジェクトを取得します。
試しにrをプリントすると【Response [200]】このように表示されます。
恐らく404とか帰ってきたらNotFoundとかという意味でしょうか・・・。詳しい人教えてください・・・。
続いて連続アクセスをするとDos攻撃になりかねないのでtime.sleepで10秒待ちます。
そしてsoup = Beautifulsoup(r.text,('html.parser')でHTMLタグが付いている情報に変換します。
次のfor分でsoupに格納したタグ付きの情報から必要な項目だけ抜き出していきます。
ここでだいぶはまりました
グーグルクロームの開発者ツールで見えるタグとsoupで取得したタグが全然違った・・・。
欲しかった情報のタグが全く違うタグが付いていました。
なんで・・・?
そのため開発者ツールで見たタグではなく一度soupで取得したタグからsoup.find_allをかけることをお勧めします。
find等の使い方はこちらの記事が大変参考になります。
PythonとBeautiful Soupでスクレイピング
今回であれば検索結果の地図付きの画像の部分のタグがBタグから始まり絶対に〒という文字から始まるためそこの部分を抜き出すように設定しました。
あとは配列のIDに格納して次の物件名に移るだけです。
df = pd.DataFrame(ID)
df.to_csv(r"CSVを吐き出す先のパス", index=False, header=False, sep="\t")
そして最後にPandasを使ってCSVにまとめて書き込んでいきます。
ここでIDの中身は [物件名,住所]となっているのでそのままCSVに書き込むだけです。
本当は物件名、住所を別リストに格納したのちPandasで合体をさせたかったのですが、どう頑張ってもできなかった(やり方が恐らく悪いだけ)ため
IDのリストに突っ込む際に強制的にCSVデータとなるようにしてしまいました。
df.to_csvにてCSVを作成しつつpd.DataFrame(ID)で作成したデータをCSVに書き込んでいきます。
indexもヘッダーも不要だったのでここではFalseとしました。
sepについてはなぜかタブを指定することによりエディターで正常にCSVとして認識されるように・・・。
ここについては後日もうちょっと調べてみたいと思っています。
もともとカンマ区切りでデータを持っていたせい・・・?
あとがき
上記の物はfor文でいくつも物件の住所を取得できるように設定していますが、当の本人は全く法律系の知識がないため
1件しか取得していません。複数動かしたらどういう負荷を与えてしまうのか怖くて試せていません・・・。
理論上は動くはず・・・。動かなかったらごめんなさい。
しかしクロームのコンソールで見るタグとBeautifulsoupで取得した内容が違ったのには本当に焦りました。
コンソール上ではこれで確かにfindかけられるのに・・・!って動かした途端null・・・・
初めて使う技術はこまめにprintしなきゃいけないなって思いました。
色々とあれなところはあると思いますので是非ともお詳しい方に添削していただきたいですっ・・・!
何卒よろしくお願い致します・・・。