この記事について
この記事は「JavaScriptの概念たち (前編)」の続きです。本来は1つの記事なのですが、あまりにも長くなりすぎたので分割しました。
17. Prototype Chain
JavaScriptには2つの特徴があります。1つは「全てがオブジェクト」でもう1つは「prototypeベースの言語だということ」です。
const hoge = {
a: "hogehoge"
};
console.log(hoge instanceof Object); // -> true
const fuga = [1, 2, 3];
console.log(fuga instanceof Object); // -> true
const piyo = new Map([[1, 'one'], [2, 'two']]);
console.log(piyo instanceof Object); // -> true
配列とかMapとかも全部、内部的にはオブジェクトなんですね。
さて、実は全てのオブジェクトにはprototypeというプロパティが存在しています。日本語に訳すと「原型」という感じですね。このprototypeがclassの継承のような役割を果たします。
prototypeの役割を明らかにするために少し実験を行ってみます。
// Arrayのprototypeにhogeメソッドを定義すると...
Array.prototype.hoge = function(){
console.log(this);
}
const foo = [1, 2, 3];
// 全てのArrayから呼び出せるようになる
foo.hoge(); // -> [1, 2, 3]
fooにhoge()メソッドを定義していなかったにも関わらずhoge()が呼び出せてしまいます。これがprototypeの力です。
配列fooを定義した時に、同時にfoo.__proto__という内部プロパティにArray.prototypeへの参照がセットされます。そしてfoo.hoge()が呼び出されるとまずfoo自身のプロパティにhogeが存在するかが確認され、なければ次にfoo.__proto__.hogeが存在するかを確認します。今回はfoo.__proto__.hoge()が実行されたというわけです。
同じようにObject.prototype.hogeを定義してみます。
Object.prototype.hoge = function(){
console.log(this);
}
const foo = [1, 2, 3];
foo.hoge(); // -> [1, 2, 3]
const bar = new Map([[1, 'one'], [2, 'two']]);
bar.hoge(); // -> Map(2) {1 => "one", 2 => "two"}
今度はfoo.__proto__.hogeが存在しません。すると次にfoo.__proto__.__proto__.hogeを確認します。このように、呼び出したメソッドが存在しなければ見つかるまで親のprototypeをさかのぼり続けます。これがprototypeチェーンの仕組みです。
ArrayもMapもオブジェクトの子供なのでprototypeチェーンをさかのぼった結果Object.prototype.hogeが実行されたというわけです。
もっとも、今はclass構文があるのでprototypeを直接触るようなコードを書くことはほぼ無いと思います。
基本的に全てのオブジェクトがObject.prototypeへと繋がっているのですが、Object.create(null)を使用することで__proto__などの内部プロパティなども一切持たない完全に無のオブジェクトを作成することができます。
const hoge = {};
const fuga = Object.create(null);
console.log(hoge);
console.log(fuga);
上のhogeは__proto__を持っていますが下のfugaは何も持っていないことがわかります。

Mapが無かった頃はこの何もプロパティを持たないオブジェクトをMapの代わりに用いていたそうですが、今は本物のMapがある (#24で解説) のであまり出番はなさそうです。
コラム:ラッパーオブジェクト
JavaScriptは全てがオブジェクトという話の例に配列やMapをあげたのですが、実はプリミティブな文字列などもオブジェクトのように扱うことができます。
console.log(true.toString()); // -> "true"
console.log('hoge'.toUpperCase()); // -> "HOGE"
これはプリミティブの要素にアクセスしようとすると内部的にラッパーオブジェクトに自動で変換されるためです。
true.toString()は実際にはnew Boolean(true).toStringのように処理されます。
この辺りの変換は自動でやってくれるので深く考える必要はありません。わざわざnew Boolean()などを書く必要はないということだけ覚えておけば良いでしょう。
18. Object.create & Object.assign
Object.createはprototypeオブジェクトの継承を行うために使用されます。class構文と同等のことが関数で実行できるというわけですね。ES5時代には無かったことからわかるように、JavaScriptのclassは見た目がclassっぽいだけで、実際にはclassを使わなくても同等のことができるのです。
個人的にはclassを使った方が読みやすいと思います。
例えば#14のようにHogeを継承したFugaを書く場合は以下のようになります。
function Hoge(){
this.name = 'NoName';
}
Hoge.prototype.sayHello = function(){
return `Hello! I am ${this.name}!`;
}
function Fuga(){
Hoge.call(this); // class構文ではsuper()を使う
}
Fuga.prototype = Object.create(Hoge.prototype);
Fuga.prototype.constructor = Fuga;
const fuga = new Fuga();
console.log(fuga.sayHello()); // -> "Hello! I am NoName!"
Object.assignは複数のオブジェクトを結合してくれる関数です。
prototypeを結合して多重継承(mixin)のように使用したり、第一引数を{}にしてオブジェクトをコピーする用途で多用されていました。今はスプレッド演算子を使用します。
const obj1 = { hoge: 'hoge' };
const obj2 = obj1 // これだと参照渡しになる
const obj3 = Object.assign({}, obj1); // 新しいオブジェクトを作成し、それにobj1の内容をコピーする
const obj4 = {...obj1}; // 今はスプレッド演算子を使う
obj1.hoge = 'fuga';
console.log(obj1.hoge); // -> "fuga"
console.log(obj2.hoge); // -> "fuga"
console.log(obj3.hoge); // -> "hoge"
console.log(obj4.hoge); // -> "hoge"
19. Array.prototypeの便利な関数たち
Array.prototypeには配列操作のための便利な関数が色々用意されています。#17で述べたように、prototypeにある関数はどのArrayオブジェクトからでも呼び出せます。
配列をスタックやキューのように使う
スタックとはいわゆるLIFO型のデータ格納方式です。この記事の#1で出てきたコールスタックもスタックの一種で、後から入った関数が先に処理されていましたね。
配列をスタックのように使用するにはpush()とpop()を使用します。
const stack = [];
stack.push(1);
stack.push(2);
stack.push(3);
console.log(stack); // -> [1, 2, 3]
while( stack.length > 0 ){
console.log(stack.pop()); // -> 3 2 1
} // 後ろから出てくる
キューはFIFO型のデータ格納方式です。こっちはpush()とshift()を使用します。
const queue = [];
queue.push(1);
queue.push(2);
queue.push(3);
console.log(queue); // -> [1, 2, 3]
while( queue.length > 0 ){
console.log(queue.shift()); // -> 1 2 3
} // 前から出てくる
push()は配列の後ろに新しい要素を突っ込んでくれる関数でしたが、配列の前に要素を突っ込むためのunshift()という関数もあります。
sort
配列をソートしたい場合はsort()という関数を使用します。ただし若干動作に癖があって、全ての要素は内部的にStringに変換され、辞書順でソートされてしまいます。
const arr = [1, 10, 5, 30];
arr.sort(); // 引数無しの場合"1", "10", "5", "30"が辞書順になるようにソートされる
console.log(arr); // -> [1, 10, 30, 5] (元の型がStringに変換される訳では無い)
arr.sort( (a,b) => (a-b) ); // 数字の大小などでソートする場合は自分で比較関数を書く
console.log(arr); // -> [1, 5, 10, 30]
比較関数をうまく使うことでオブジェクトのソートなどを自由に行うことができます。
const items = [
{ name: 'watace', value: 100 },
{ name: 'hoge', value: 90 },
{ name: 'fuga', value: 110}
];
// nameの辞書順でソート
items.sort( (a,b) => {
if(a.name < b.name) return -1; // 負の数字が返ってこればa<bと判定される
if(a.name > b.name) return 1; // 正の数字だとa>bと判定される
return 0; // 0の場合の順序は保証されない
});
console.log(items);
// -> [{name: "fuga", value: 110}, {name: "hoge", value: 90}, {name: "watace", value: 100}]
// valueの大小でソート
items.sort( ( a, b ) => ( a.value - b.value ) );
console.log(items);
// -> [{name: "hoge", value: 90}, {name: "watace", value: 100}, {name: "fuga", value: 110}]
map
map()は配列の各要素を変形して新しい配列を生成する関数です。元の配列は変化させません。
const arr = [1, 2, 3];
const newArr = arr.map( x => x * 2 );
console.log(arr); // -> [1, 2, 3]
console.log(newArr); // -> [2, 4, 6]
個人的にはデータからReactのコンポーネントを作るときに使っています。
const data = [
{ name: 'watace', value: 100 },
{ name: 'hoge', value: 90 },
{ name: 'fuga', value: 110 }
];
const CardList = (props) => (
<div>
{data.map( (item, index) => (
<Card name={item.name} value={item.value} key={index} />
)
);}
</div>
);
reduce
reduce()は配列の全ての要素を1回ずつ見ていって最後に1つの値を返す場合の処理を簡単にかける関数です。例えば合計を返したり、最大値を返したりします。
const arr = [1, 2, 3];
const sum = arr.reduce( (acc, cur) => ( acc + cur ) );
console.log(sum); // -> 6
const max = arr.reduce( (acc, cur) => Math.max(acc, cur) );
console.log(max); // -> 3
引数の関数に渡される値は(前回の戻り値, 今回の値, 今のインデックス, 元の配列)です。
他に単語の出現回数を調べたりすることもできます。
const arr = [
'文章が1行ごとに分けられて配列に入っていると考えます。',
'こうした文章の中で特定の単語や文字の並びの出現回数を調べるには',
'正規表現とReduceを使うのが簡単です。'
];
const count = arr.reduce(
(acc, cur) => acc + ( cur.match(/の/g) || [] ).length,
0
);
console.log(count); // -> 5 ("の"の出現回数)
実はreduce()は最初の要素の実行をスキップし、2番目の要素からスタートします。1番目の要素はそのまま最初のaccに渡されます。
今回はそれでは困るので、2番目の引数に0を設定しています。こうすることで、最初のaccに0が渡され、配列の最初の要素から順番にコールバックを実行してくれるようになります。
filter
filter()は配列の各要素のうち条件にあったものだけを抜き出して新しい配列を生成する関数です。
const arr = ['hoge', 'fuga', 'piyo'];
const newArray = arr.filter( elem => /o/.test(elem) );
console.log(newArray); // -> ["hoge", "piyo"]
/.../は正規表現オブジェクトを表します。RegExp.prototype.test()は引数に正規表現がマッチするかどうかを判定します。マッチすればtrue、マッチしなければfalseです。
/o/.test(elem)はelemにoという文字が含まれるかどうかを判定しています。このfilterとか正規表現とかはスクレイピングをするときにかなり役立つ印象です。
コラム:関数型プログラミング
この後の章でしばらく関数型プログラミングの話が続くので、関数型プログラミングとはどういうものなのかについて簡単に説明します。
正確性に欠けることを承知の上で言ってしまえば、関数型プログラミングは「関数とデータを引き離す」プログラミング手法のことです。
- 関数が関数外部の状態を変化させない
- 関数が引数以外の入力を受け取らない
数学の関数みたいに考えるとわかりやすいかもしれません。
例えばf(x)=2x+3みたいな感じである入力xに対してどのような出力をするのかを定義します。
似たような感じでg(x)=-3xみたいに定義すると、下のように数学的に記述できるんですね。
const f = x => 2*x + 3;
const g = x => -3*x;
const x = 3; // 入力データ
const data = g(f(x));
console.log(data); // -> -27
// 何回同じ処理をしても入力が同じなので出力は変化しない
console.log(g(f(x))); // -> -27
console.log(g(f(x))); // -> -27
実は前の章でみてきたArray.prototypeの関数にあったsort map reduce filterは関数型プログラミングの考えに基づいている関数です。すなわち、元の関数を変化させず、同じ入力をすれば何度操作を繰り返しても同じ出力が得られます。
関数型プログラミングの概念をもとにコードを組んでいくと、処理の途中でデータが変化することがなくなるのですが、それを「サイドエフェクトがない」だとか「純粋関数」だとか言うわけです。早速見ていきましょう。
20. サイドエフェクトと純粋関数
関数は入出力のルートをそれぞれ2つずつ持っています。
const hiddenInput = 5;
const obviousInput = 3;
let hiddenOutput;
let obviousOutput;
const func = x => {
// 隠れた入出力を持つ
hiddenOutput = x * hiddenInput;
return x;
};
obviousOutput = func( obviousInput );
関数が隠れた出力を持つ場合、その関数には「サイドエフェクト(副作用)がある」と言い、隠れた入力を持つ場合は「参照透過性がない」と言います。
サイドエフェクト(副作用)
サイドエフェクトとは日本語でいうと「副作用」のことで、関数を実行した際に何らかの状態を変化させてしまう場合に「サイドエフェクトがある」というように使用します。
let a = 0;
const inc = () => {
a += 1;
};
const inc = a => a + 1;
サイドエフェクトがよくわからなくても、基本的に「関数を実行した際に何が起きるのかがその行だけで明白」にできるように気をつけていれば自然とサイドエフェクトが無いコードが書けると思います。
let a = 0;
inc(); // 何が起きているのかパッと見では分からない
inc();
console.log(a); // -> 2
let a = 0;
a = inc(a);
a = inc(a);
console.log(a); // -> 2
コラム:組み込みオブジェクトの独自拡張
上記のa = inc(a);はいまいち見た目が微妙という感想を抱く人もいると思います。そもそもletって怪しくてあんまり使う気になれないんですよね。
どうせならパイプ記法的にconst b = a.inc().inc();みたいに書きたいと思いませんか?
そういう場合はサクッと新しいクラスを作っちゃいましょう。
class ExNumber extends Number{
// ちなみに下のようなsuperするだけのconstructorは省略しても問題ありません。
constructor(args){
super(args);
}
inc(){
return new ExNumber( this + 1 );
}
}
const hoge = new ExNumber(1);
console.log(hoge); // -> 1
const fuga = hoge.inc().inc().inc();
console.log(fuga); // -> 4
console.log(hoge); // -> 1
参照透過性
参照透過性をもつ関数とは隠れた入力を持たない関数のことで、簡単にいってしまえば「同じ引数で実行すれば必ず同じ返り値になる関数」のことです。
純粋関数
純粋関数とは、関数のうち「サイドエフェクトが無い」かつ「参照透過性をもつ」もののことをさします。
外部の状態とは完全に独立しているので、コードを解読する際に考えないといけないことが減ります。状態から独立しているので並列処理にも強いです。
const addPerson = (group, person) => {
group.push(person);
}
const group = [];
addPerson(group, { name: 'hoge' });
const addPerson = (group, person) => {
return [...group, person];
}
const group1 = [];
const group2 = addPerson(group1, { name: 'hoge' });
console.log(group1); // -> []
console.log(group2); // -> [{name: "hoge"}]
ネストされたオブジェクトは適当に処理してると参照コピーになるので注意しましょう。
21. クロージャー
JavaScriptでは、関数が外側のスコープにある変数への参照を保持できるようになっています。この性質のことを「クロージャー」と呼び、これを利用すると関数にあたかも状態を持つかのような挙動をさせることができます。
const createCounter = () => {
let cnt = 0;
return {
inc: () => ++cnt
}
};
const counter = createCounter();
console.log(counter.inc()); // -> 1
console.log(counter.inc()); // -> 2
// 当然ですが、counterはただの関数です。cntにはアクセスできません。
console.log(cnt); // -> ReferenceError
console.log(counter.cnt); // -> undefined
JavaScriptでは不要になったメモリをガベージコレクタが自動で解放してくれるのですが、その解放基準は「グローバルオブジェクトから到達できるかどうか」となっています。
上記の例ではglobal -> counter -> cntと参照されているため、cntのメモリが解放されずに内部状態のように働いています。
22. 高階関数(HOF)
JavaScriptでは関数もオブジェクトの一つです。これを利用して関数を引数にしたり戻り値を関数にすることができます。JavaScriptを使い慣れている人なら当たり前すぎて今更何言ってるんだとなるかもしれません。
#19で出てきたsort()やmap()、filter()、reduce()は全て引数に関数をとるので高階関数だと言えます。また#21のクロージャーなどで関数を返すものも高階関数だと言えるでしょう。
関数型プログラミングを行う場合にこの高階関数が使えるというのは必須条件になってきます。
23. 再帰
再帰の例といえば5!みたいな階乗ですよね。
const factorial = n => n === 1 ? 1 : n * factorial(n-1);
突然出てきた?と:は3項演算子と呼ばれる演算子です。下記のfooとbarは同じものをif文と3項演算子で書いてみたもの。
const foo = condition => {
if (condition) {
return hoge;
} else {
return fuga;
}
};
// ↕︎同じ
const bar = condition => condition ? hoge : fuga;
フィボナッチ数なんかも再帰で書くことができます。
const fibonacci = n => (
n === 0 ? 0
: n === 1 ? 1
: fibonacci(n-1) + fibonacci(n-2)
);
console.log(fibonacci(0)); // -> 0
console.log(fibonacci(1)); // -> 1
console.log(fibonacci(2)); // -> 1
console.log(fibonacci(3)); // -> 2
console.log(fibonacci(4)); // -> 3
ただし、fibonacci(n-1) + fibonacci(n-2)を見ればわかるようにこの再帰は分岐しているためnが増えるたびに計算時間が約1.618倍になってしまいます。このことについては後ほど#28や#29で扱います。
24. コレクションとジェネレーター
JavaScriptのコレクションにはObjectとArrayの他にMap、Set、WeakMap、WeakSetがあります。
Object
Objectは使い慣れすぎていてMapを使う気がおきませんね。for ofで回す時なんかはObject.entries()を使うことが多いです。
const obj = {
hoge: 'hoge',
fuga: 10,
piyo: {
piyopiyo: true
}
};
for( const [key, value] of Object.entries(obj) ){
console.log(`key: ${key}, value: ${value}`);
// -> "key: hoge, value: hoge"
// -> "key: fuga, value: 10"
// -> "key: piyo, value: [object Object]"
if(key === 'piyo')console.log(value.piyopiyo); // -> true
}
Array
まあ配列についても今更特にコメントすることはありません。
const arr = [ 'hoge', 'fuga', 'piyo' ];
for( const value of arr )console.log(value);
// -> "hoge"
// -> "fuga"
// -> "piyo"
ループを回す時にどうしてもインデックスが欲しい場合はArray.prototype.entries()を使います。
for( const [index, value] of arr.entries() ){
console.log(`index: ${index}, value: ${value}`);
}
// -> "index: 0, value: hoge"
// -> "index: 1, value: fuga"
// -> "index: 2, value: piyo"
Map
Objectとの違いは大きく3つあります。
- 任意の値がキーになれる
- 大きさを得るのが簡単 (
Map.prototype.sizeで瞬殺) -
for ofが直感的に使える
const fuga = {
toString: () => 'fugaオブジェクト'
};
const map = new Map([
[4, 'hoge'], // 数字もキーになれる
[fuga, 10], // オブジェクトもキーになれる
[true, { // booleanもキーになれる
piyopiyo: true
}]
]);
console.log(map.size); // -> 3
for( const [key, value] of map ){
console.log(`key: ${key}, value: ${value}`);
}
// -> "key: 4, value: hoge"
// -> "key: fugaオブジェクト, value: 10"
// -> "key: true, value: [object Object]"
ちなみに最後の出力が[object Object]となっているのはテンプレートにObjectが埋め込まれると自動でObject.prototype.toString()が呼び出されるためです。
WeakMap
Mapとの違いは大きく2点。
- キーは
Objectのみ - 列挙不可能
何かが弱い感じのMap。何が弱いのかというと参照が弱いです。
弱い参照とはガベージコレクションを妨げない参照のことで、つまりキーとなったObjectはWeakMap以外で使用されなくなった時点でガベージコレクションの対象となるためメモリを解放することができます。
const wm = new WeakMap();
const obj1 = {};
let obj2 = {};
wm.set(obj1, 'object1');
wm.set(obj2, undefined);
console.log(wm.has(obj1)); // -> true
console.log(wm.has(obj2)); // -> true
console.log(wm.get(obj1)); // -> "object1"
console.log(wm.get(obj2)); // -> undefined
wm.delete(obj1); // 通常のMapと同じように消すことも可能
obj2 = {}; // ※下記
console.log(wm.has(obj1)); // -> false
console.log(wm.has(obj2)); // -> false
WeakMapからオブジェクトへの参照は弱い参照のため、他の場所からの参照がなくなる上記の※時点でもともとのobj2のメモリを解放することができます。
SetとWeakSet
一意の値を格納するのに使用できます。Setはなんでも格納できますが、WeakSetはオブジェクトしか格納できません。また、WeakSetは列挙できません。
const set = new Set(['👻', '🎉', '🎂', '🎄']);
console.log(set.size); // -> 4
console.log(set.add('🌟')); // -> Set(5) {"👻", "🎉", "🎂", "🎄", "🌟"}
console.log(set.add('👻')); // -> Set(5) {"👻", "🎉", "🎂", "🎄", "🌟"}
for( const value of set ){
console.log(value);
}
// -> "👻"
// -> "🎉"
// -> "🎂"
// -> "🎄"
// -> "🌟"
ジェネレーター
ジェネレーターは中断できる感じのfunctionです。
const hoge = function*(){
yield 1;
yield 2;
}
const h = hoge();
console.log(h.next()); // -> {value: 1, done: false}
console.log(h.next()); // -> {value: 2, done: false}
console.log(h.next()); // -> {value: undefined, done: true}
// 列挙することも可能
for( const value of hoge() ){
console.log(value); // -> 1 2
}
// マクロのように使えなくもない (あまり記述量が減らない気がするが...)
const rep = function*(x){
for(let i = 0; i<x; i++){
yield i;
}
}
for( const i of rep(5) ){
console.log(i); // -> 0 1 2 3 4
}
25. Promise
PromiseはJavaScriptで非同期処理を簡単に書けるようにしてくれる構文です。一部の処理については今は#26のasync awaitを使うのが一般的ですが、async awaitは内部でPromiseを使用している上にPromiseでしかできない処理もあるので完全に置き換わった訳ではありません。
Callback地獄の時代
Promise登場以前はCallbackを駆使して非同期処理を行なっていました。しかし非同期処理を連続して行いたい場合、CallbackにCallbackを渡してさらにそのCallbackにまた別のCallbackを渡して...という書き方をするしかありませんでした。
// 300ms後にcallbackを実行する関数
const doAfter300ms = (callback)=>{
setTimeout(callback, 300);
}
doAfter300ms(()=>{
console.log('1st step');
doAfter300ms(()=>{
console.log('2nd step');
doAfter300ms(()=>{
console.log('3rd step');
// 際限なくネストが深くなっていく
});
});
});
Promise時代
Promiseを使う場合、非同期関数をPromiseで包んで先に(処理が終わるのを待たずに)Promiseオブジェクトだけreturnします。
Promiseの中身はresolve rejectの2つの引数をとる関数にします。resolveが実行されるとそのPromiseが解決され、.then()に処理が移っていきます。rejectが呼ばれると.then()をスキップして.catch()に処理が移ります。
// 300ms後にcallbackを実行する関数
const doAfter300ms = (callback)=>{
return new Promise((resolve, reject)=>{
setTimeout(()=>{
callback();
resolve();
}, 300);
});
};
console.log(doAfter300ms()); // -> [object Promise] {}
doAfter300ms(()=>{
console.log('1st step');
})
.then(()=>{
return doAfter300ms(()=>{
console.log('2nd step');
});
})
.then(()=>{
// 途中で同期的な処理を混ぜることも可能
console.log('hogehoge');
})
.then(()=>{
return doAfter300ms(()=>{
console.log('3rd step');
});
})
.catch(e=>{
// Promiseチェーンの中で`reject`が呼ばれたらここに飛ぶ
});
なお、resolve()に値を設定すると次の.then()で受け取ることができます。reject()なら.catch()で受け取れます。
const hoge = new Promise(resolve=>{
setTimeout(()=>{
resolve(5);
}, 300);
});
hoge.then(x=>{
console.log(x); // -> 5
});
26. async/await
asyncは関数の前にくっつけるとその関数がasync functionという非同期処理用の関数に変化します。そしてawaitはasync関数内でのみ使用できるキーワードで、Promiseオブジェクトの前に付けると関数を一時停止してその場でPromiseの解決を待ちます。
// 300ms後にcallbackを実行する関数(再掲)
const doAfter300ms = (callback)=>{
return new Promise((resolve, reject)=>{
setTimeout(()=>{
callback();
resolve();
}, 300);
});
};
(async ()=>{
await doAfter300ms(()=>{
console.log('1st step');
});
await doAfter300ms(()=>{
console.log('2nd step');
});
await doAfter300ms(()=>{
console.log('3rd step');
});
})();
awaitはPromiseの返り値を受け取ることもできます。
const hoge = new Promise(resolve=>{
setTimeout(()=>{
resolve(5);
}, 300);
});
(async ()=>{
const x = await hoge;
console.log(x); // -> 5
})();
なお、async awaitではtry ~ catch構文が使用できる他、await/catchという書き方もできるとのこと。
// try ~ catch の例
try {
const x = await fuga();
} catch (err) {
console.error(err);
}
// await/catch の例
const x = await fuga().catch( err => {
console.error(err);
};
try ~ catchだとブロックスコープができて邪魔という場合などにawait/catchの書き方はかなり便利そうです。
27. データ構造
データ構造とはデータの集まりをどのような形式で格納するのかというものです。データ構造次第でどのような処理が得意なのかが決まってくるため、特に処理すべきデータが多い場合には目的に沿って適切なデータ構造を選択する必要があります。
配列
※JavaScriptの配列の実装はこの配列とは異なる場合があるので注意。
連続したメモリアドレス上にデータを格納する構造。
それぞれのデータへのアクセスがO(1)で行える。
データの挿入・削除はO(n)。データの探索も基本的にはO(n)になる。
連想配列
配列はa[0]みたいに数字を添字にしてアクセスするんですが、数字以外の型でアクセスできるようにしたものが連想配列です。JavaScriptは全てのオブジェクトがこの連想配列になっています。
JavaScriptでの実装ではそれぞれのデータへのアクセスやキーの追加・削除などがO(1)で行えます。
ただ、最近のJavaScriptエンジンは優秀で、JavaScriptの配列を上の配列にするみたいな最適化をしてくれるらしいんですよね。この辺りはあまり詳しくないので情報求めてます。
リスト
データと「別のデータへのポインタ」を保持するデータ構造。
配列に比べると任意の位置での挿入・削除がO(1)でできるというのがメリット。ただしランダムアクセス性は低い。
色々種類がありますが、基本的なもの2つだけ紹介します。
片方向リスト
後ろしか指さないタイプのリスト。逆に辿ることはできない。

双方向リスト
両方指すタイプのやつ。

グラフ
頂点と枝からなるデータ構造。
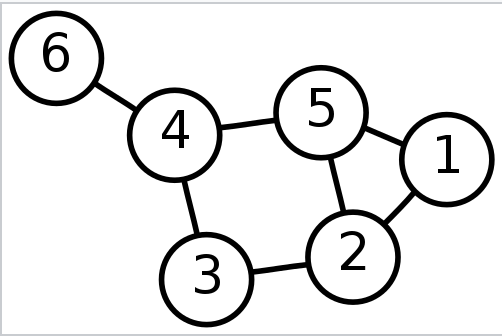
木
グラフの一つ。閉路を持たず、全ての頂点が連結されているグラフのこと。
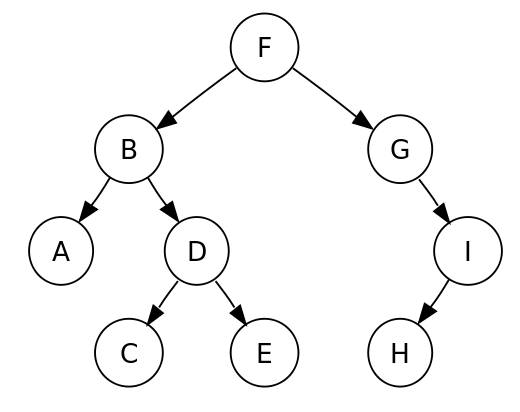
例えばDOMはツリーとしてメモリ上に展開されています。
28. 計算時間
これまでも何回か使いましたが、O記法を使って表現します。詳しい説明は教科書に譲りますが、例えばO(1)はデータの量がどれだけ増加しても一定時間で処理できることを意味し、O(n)はデータ量に比例して処理時間も伸びていくことを示しています。
O(1)
定数時間という名前がついています。上述の通り、データの量がどれだけ増加しても処理時間が変わらないものを指します。
- Objectのプロパティ読み取り・書き込みなど。
O(log n)
対数時間。ソートされた配列を2分探索する場合など、元のデータの大きさに対して割合でデータ量が減っていく場合などはこのO(log n)になります。
データ量が10から100になると処理時間が2倍、1万になると4倍と言う感じ。
O(n)
線形時間。データ量に比例して計算量が伸びていきます。
リストの任意の場所にデータを追加する場合など。(頭から辿る必要があるため)
データ量が10から100になると処理時間は10倍になります。
O(n log n)
実際に使っていくアルゴリズムでかなり見かける(気がする)計算量。
ソート系のアルゴリズムの期待計算量はだいたいこれです。例えばクイックソートだとパーティションの分割がO(log n)で、その上で再帰的に全部のデータを見るので合わせてO(n log n)となります。
O(n^k)
kは定数を表します。名前は多項式時間。配列全体をk重ループで回すとこの計算量に。
ひとまとめにしていますが、実際に使用する上ではO(n^2)とO(n^3)のようにkの値が違うとかなり計算量が異なってきます。
O(k^n)
指数時間。代表例は巡回セールスマン問題など。
よほどデータ量が少なくない限り実用的ではない計算量です。
29. アルゴリズム
アルゴリズムは「処理を行うための一連の手続き」みたいなものです。特に処理すべきデータの量が多い場合など、アルゴリズムの組み方で計算量が全然違ってきます。
#23でフィボナッチ数列を再帰で実装してみました。
const fibonacci = n => (
n === 0 ? 0
: n === 1 ? 1
: fibonacci(n-1) + fibonacci(n-2)
);
しかし上記の実装だと計算量に問題があります。
例えばn=40だとfibonacci(39) + fibonacci(38)が計算されますが、fibonacci(39)を展開してみると
{ fibonacci(38) + fibonacci(37) } + fibonacci(38)
となり、fibonacci(38)が2回計算されてしまっていることがわかります。
そこで、一度計算したfibonacci数を配列に保存し、2回目以降は保存された数字を利用することにします。
const arr = [0, 1];
const fibonacci = n => (
arr[n] !== undefined
? arr[n]
: arr[n] = fibonacci(n-1) + fibonacci(n-2)
// JavaScriptでの代入式は代入した値を返します
);
console.log(fibonacci(50)); // -> 12586269025
元の再帰がO(黄金比^n)だったのに対して新しいメモ化再帰はO(n)にできました。
ただこのアルゴリズムというのは奥が深い分野で、とてもこの1章だけで書き切れるものではないんですよね。詳しく知りたい人は蟻本がおすすめです。追加の例として蟻本の名前の由来? にもなっている「蟻」問題を紹介します。
問題
長さLcmの竿の上をn匹のアリが毎秒1cmのスピードで歩いています。
竿は狭くてすれ違えないので、アリ同士が出会うとお互いに反転します。また、竿の端に到達するとアリは竿の下に落ちていきます。
各アリの現在の位置が与えられた時、全てのアリが竿から落ちるのにかかる最大の時間と最小の時間をそれぞれ求めなさい。
__.___.__._____.__ (竿の上にいるアリのつもり)
制約
1 ≤ L ≤ 1e6 (注:10^6=1,000,000のことです)
1 ≤ n ≤ 1e6
0 ≤ xi ≤ L
まず、全てのアリがどちらを向いているのかを場合分けしていくと2^n通りになることが分かります。
| n | 1 | 10 | 20 | 30 | 50 |
|---|---|---|---|---|---|
| 2^n | 2 | 1024 | 1e6 | 1e9 | 1e15 |
nと2^nの関係は上記の通りで、とてもn=1e6のような大きなnを現実的な時間で計算することはできません。コンピューターが1秒間に処理できる計算量はおよそ1e7〜1e8くらいです。(これを逆算すると、問題文の制約がn≤1e6なのでO(n)の解法を見つけろという問題であることが分かります。O(n log n)でも通るかも?)
この解法では現実的な時間で計算できないことが分かりました。別の解法を探す必要があります。
まず簡単そうな最小時間の求め方を考えると、全てのアリを近い方の端に落としてしまえば良いことが分かります。アリ同士が出会わないので簡単に求められます。
次に最大時間はどう求めるのかを考えていきます。よく考えてみると、アリ同士が出会った際にお互い逆方向に進み出すのですが、これはアリ同士がそのまますれ違ったと解釈しても問題ないと分かります。
➡️⬅️
↓ イメージ図(伝われ)
↩️↪️ ⇔ ⬅️➡️
するとそれぞれのアリの向きはどうでもよく、端までの距離がもっとも遠いアリを見つければ良いことが分かります。最大値を見つけるにはそれぞれのアリについて一回ずつ調べれば良いのでO(n)で解けることが分かりました。
これは極端な例ですが、アルゴリズムを活用すると様々な処理の計算量を落とすことができます。知っ得です。もし初めてアルゴリズムを学ぶという場合はいきなり蟻本を読むと挫折すると思うので、AtCoder Beginner Contestなどを解いてみるのがオススメです。
30. ポリモーフィズム
ポリモーフィズムは日本語にすると多態性とか多様性とかいう感じの言葉で、要するに様々な型の入力に対して同じ関数を使用できることを指します。同じ関数を利用できると何が嬉しいのかというと、引数の型ではなく処理の目的に沿って関数を使用できるのでより直感的に理解できるという点が挙げられます。
例えば2つの引数(a, b)をとってその2つが実質的に同じかどうかを判断する関数を書きたいとします。
引数の型がNumberかBooleanか、はたまたObjectなのかで内部の処理は結構変わってきますよね。
でも同じ関数で利用できたら分かりやすくないですか?
必然的に「どうやって型の判断をするのか?」が問題になるのですが、JavaScriptではObject.prototype.toString.call()を使うのが簡単です。MDNに載ってました。
Object.prototype.toStringにcall()かapply()でオブジェクトを渡してあげると[object String]みたいな感じで戻ってきます。
const type = val => {
return Object.prototype.toString.call(val).slice(8, -1);
};
console.log(type({})); // -> "Object"
console.log(type(1)); // -> "Number"
console.log(type(false)); // -> "Boolean"
console.log(type('hoge')); // -> "String"
console.log(type(null)); // -> "Null"
console.log(type([])); // -> "Array"
console.log(type(/a-z/)); // -> "RegExp"
console.log(type(()=>{})); // -> "Function"
console.log(type(undefined)); // -> "Undefined"
これであとは引数を型ごとにswitchすればそれぞれの型に合わせた実装を行えます。
自作classの名前が欲しい時はgetPrototypeOf().constructor.nameなんかが良いんじゃないかと思いついたのですが、minifyされた時に名前が変わるので意図通りに動かなくなる問題が発生しがちだそうです。azuさんありがとうございます。
const type = val => {
return val === null
? 'Null'
: val === undefined
? 'Undefined'
: Object.getPrototypeOf(val).constructor.name;
};
31. デザインパターン
デザインパターンとは、再利用やメンテナンスを楽に行うための設計を分類して名前をつけたものです。
GoF本で発明された概念だとWikipediaに書いてありました。一部界隈では聖書のように扱われているそうです。ちなみに英語版(PDF)は無料で読めます。
1994年に登場してからもう20年以上経過していることもあって、デザインパターンの良い部分に触れ続けている今のプログラマーにはその良さが今ひとつ伝わらないのかもしれません。
例えば配列でもMapでも、はたまたジェネレーター関数でもfor ofで回せるのはIterator Patternのおかげですし、Prototype PatternなんかはJavaScriptの言語の根幹であるとも言えます。DOMのEventListenerはObserver Patternそのものですし。
32. カリー化と部分適用
カリー化
カリー化とは全ての関数の引数の数を1つにすることだと言えます。
// カリー化されていない
const add = (a, b) => a + b;
console.log(add(1, 2)); // -> 3
// カリー化されている
const cAdd = a => b => a + b;
console.log(cAdd(1)(2)); // -> 3
関数を受け取ってカリー化するための関数を自前で実装すると下のようになります。これは元の関数の引数が2個の時用のものです。
const curry = fn => (
function cfn(a, b) {
switch (arguments.length) {
case 0:
return cfn;
case 1:
return _b => fn(a, _b);
default:
return fn(a, b);
}
});
const add = (a, b) => a+b;
const cAdd = curry(add);
console.log(cAdd()); // -> function cfn(a, b){...}
console.log(cAdd(1)); // -> _b => add(1, _b)
console.log(cAdd(1)(2)); // -> 3
console.log(cAdd(1, 2)); // -> 3
理解のために書いてみましたが、こういうのを自分で実装するのは危ない気がします。実際は適当なライブラリを使うのが簡単で良いと思います。
部分適用
さて、関数がカリー化されている場合に使用できるテクニックが「部分適用」です。ほぼ確実にカリー化とセットで登場します。
部分適用とは「元々の関数の引数の一部を固定する」というもので、前節の例でいうと下記の部分が部分適用です。
console.log(cAdd(1)); // -> _b => add(1, _b)
add()の第一引数が1に固定されているのが分かります。これを部分適用と言います。
メリット
関数をカリー化しておくことで多様な関数を簡単に作成できるようになります。
例えば下記のようなデータがあったとします。
const data = [
{
id: 1,
name: 'watace'
},
{
id: 2,
name: 'hoge'
},
{
id: 3,
name: 'fuga'
}
];
上記のデータからidだけを抜き出す関数とnameだけを抜き出してみます。
const ids = data.map( x => x.id );
const names = data.map( x => x.name );
カリー化と部分適用を使うと下記のようになります。
// さっき作ったカリー化するための関数を使っています
const get = curry(
(prop, obj) => obj[prop]
);
const ids = data.map(get('id'));
const names = data.map(get('name'));
ま、ちょっと僕もいまいちこのテクニックを使いこなせていないので出てくる例も微妙なんですが、より自然言語らしく表現できるし余計な要素 (例えばxとか=>とか) が入ってこないのが利点ですね。
今年のアドベントカレンダーを見ていたらJavaScript2の1日目に「JavaScript で forEach を使うのは最終手段」という記事が上がっていて、その犬の例がカリー化と部分適用の説明に良さそうだったので拝借してみます。
例えばArray.prototype.filter()を使って犬のリストからタイプがポメラニアンのものだけを抜き出す関数をみてみます。
const pomeranians = dogs.filter(dog => dog.type === 'pomeranian');
先ほど使ったcurryを使うと下のように書き換えられます。
const type = curry(
(type, obj) => obj.type === type
);
const pomeranians = dogs.filter(type('pomeranian'));
const poodles = dogs.filter(type('poodle'));
const chihuahuas = dogs.filter(type('chihuahua'));
同じようなフィルター関数が簡単に作れるのはかなり便利ですね。
33. Clean Code
Clean Codeは2008年に出版された本のタイトル。いかに綺麗で読みやすいコードを書くのかについて書かれています。
実際、コードを読む時間と書く時間の比率は10:1以上になる。
新しいコードを書くための努力として、我々は常に古いコードを読んでいる。Indeed, the ratio of time spent reading vs. writing is well over 10:1.
We are constantly reading old code as part of the effort to write new code.
Robert C. Martin (2008). Clean Code: A Handbook of Agile Software Craftsmanship
ちなみに例によって英語版pdfは無料で公開されているんですね。
さて、このclean codeの内容は色々な場所でまとめられているのですが、このリポジトリのまとめが分かりやすかったのでその分類に沿ってその一部を簡単に紹介します。
変数
発音できて意味のある名前を使う
const yyyymmdstr = moment().format('YYYY/MM/DD');
const currentDate = moment().format('YYYY/MM/DD');
検索しやすい名前を使う
5よりもSERVER_REQUEST_TIMEOUT_SECONDSの方が検索しやすいですよね。
説明的な変数を使う
const address = 'One Infinite Loop, Cupertino 95014';
const cityZipCodeRegex = /^[^,\\]+[,\\\s]+(.+?)\s*(\d{5})?$/;
saveCityZipCode(address.match(cityZipCodeRegex)[1], address.match(cityZipCodeRegex)[2]);
const address = 'One Infinite Loop, Cupertino 95014';
const cityZipCodeRegex = /^[^,\\]+[,\\\s]+(.+?)\s*(\d{5})?$/;
const [, city, zipCode] = address.match(cityZipCodeRegex) || [];
saveCityZipCode(city, zipCode);
関数
引数を2個以下にするのが理想
引数が3個以上ある場合は、その関数があまりにも多くのことをしようとしていないか確かめてみる必要があります。
また、データ入力などの場合はObjectを引数に渡すようにすると呼び出しの際の見通しがよくなります。
const addUser = (id, name, age, avator) => {
...
};
const addUser = ({id, name, age, avator}) => {
...
};
addUser({
id: 10001,
name: 'watace',
age: 23,
avator: 'https://...',
});
1つの関数は1つのことだけを処理するべき
テストも書きやすくなります。
const emailClients = clients => {
clients.forEach( client => {
const clientRecord = database.lookup(client);
if (clientRecord.isActive()){
email(client);
}
});
};
const isActiveClient = client => {
const clientRecord = database.lookup(client);
return clientRecord.isActive();
};
const emailActiveClients = clients => {
clients
.filter(isActiveClient)
.forEach(email);
};
条件判定は切り分けると読みやすい
if (fsm.state === 'fetching' && isEmpty(listNode)){
...
}
const shouldShowSpinner = (fsm, listNode) => {
return fsm.state === 'fetching' && isEmpty(listNode);
};
if (shouldShowSpinner(fsmInstance, listNodeInstance)){
...
}
オブジェクトとデータ構造
メソッドには出来るだけthisをreturnさせる
pipe記法的に続けて書くことができるようになります。
class Car {
constructor(make, model, color) {
this.make = make;
this.model = model;
this.color = color;
}
setMake(make) {
this.make = make;
// NOTE: Returning this for chaining
return this;
}
setModel(model) {
this.model = model;
// NOTE: Returning this for chaining
return this;
}
setColor(color) {
this.color = color;
// NOTE: Returning this for chaining
return this;
}
save() {
console.log(this.make, this.model, this.color);
// NOTE: Returning this for chaining
return this;
}
}
const car = new Car('Ford','F-150','red')
.setColor('pink')
.save();
エラーハンドリング
エラーを握り潰さないこと
try {
functionThatMightThrow();
} catch (error) {
console.log(error);
}
try {
functionThatMightThrow();
} catch (error) {
// 選択肢1 : console.logよりも目立つ
console.error(error);
// 選択肢2 : ユーザーに通知
notifyUserOfError(error);
// 選択肢3 : サーバーにエラーレポートを送信
reportErrorToService(error);
// もちろん全部行っても良い
}
コメント
コメントが必要になるということはそのコードが複雑になりすぎているということらしいです。
明白な内容をコメントしない
Code comments pic.twitter.com/TGVxOybTnA
— Jeff Atwood (@codinghorror) 2018年4月9日
良いコードはコード自体がドキュメントのようなものになってくれます。
コメントを書かずに済むようなコードを書きましょう。
古いコードをコメントアウトして残さない
可読性を下げてしまいます。
git diff [hash]...[hash]とかを使ってください。
日記を書かない
代わりにgit log -- [file]を見ます。
また、その行が最後に変更されたコミットを特定したい場合はgit blameを使いましょう。
終わりに
書き始めたら意外と時間がかかって焦りました。
間違いや疑問点などありましたらコメントでおしらせください。
参考文献
- 継承とプロトタイプチェーン - JavaScript | MDN
- 図で理解するJavaScriptのプロトタイプチェーン - Qiita
- Object.create() - JavaScript | MDN
- Array - JavaScript | MDN
- 関数型プログラミング入門 | POSTD
- 「関数型プログラミングって何?」日本語訳 - Okapies' Archive
- Master the JavaScript Interview: What is a Pure Function?
- 参照透過性と副作用についての提言 - Qiita
- Higher-Order Functions in JavaScript — SitePoint
- 再帰的なアルゴリズムの実例集 - Qiita
- Map - JavaScript | MDN
- Array vs Set vs Map vs Object — Real-time use cases in Javascript (ES6/ES7)
- ES6 In Depth: Collections - Mozilla Hacks - the Web developer blog
- Promise - JavaScript | MDN
- async function - JavaScript | MDN
- Big-O Algorithm Complexity Cheat Sheet (Know Thy Complexities!) @ericdrowell
- Data Structures in JavaScript – Silicon Wat – Medium
- 残業したくないあなたに:データ構造とアルゴリズム - Qiita
- データ構造 - Wikipedia
- Time complexity - Wikipedia
- プログラミングコンテストチャレンジブック [第2版] ~問題解決のアルゴリズム活用力とコーディングテクニックを鍛える~ | 秋葉拓哉, 岩田陽一, 北川宜稔 |本 | 通販 | Amazon
- JavaScriptの「型」の判定について - Qiita
- GitHub - ramda/ramda: Practical functional Javascript
- Ramda.jsを使った関数型プログラミングの実践 - WPJ
- Why Curry Helps – Hugh FD Jackson
- 食べられないほうのカリー化入門 - Qiita
- CleanCode読書メモ - Qiita
- GitHub - ryanmcdermott/clean-code-javascript: Clean Code concepts adapted for JavaScript