はじめに
ディープラーニングによって既存の画像から新しい画像を生成するGAN(Genarative Adversarial Network)という技術は、私がディープラーニングで最も感動した技術ですが、通常学習には膨大な訓練データと時間が必要なので、なかなか個人では試せていませんでした。そんな折、たった1枚の訓練画像から生成することのできるGANを開発したという下記の論文を目にし、調べてみました。
こちらは今年の3月に投稿された論文で、去年投稿された
SinGAN: Learning a Generative Model from a Single Natural Image
で提案されたSinGAN(Single-Image-GAN)の改善のようです。
GAN
GAN(敵対的生成ネットワーク)自体については知名度も高く、多くのサイトで説明されているので詳細は省きます。こちらなどを参照ください。
GANとは訓練データの分布を学習してそっくりなデータを生成する「生成モデル」の一つで、偽物のデータを生成するGeneratorとそれを本物と区別するDiscriminatorを作り、これらを交互に学習させることで最終的に本物と区別できないようなデータを生成するものです。これはよく偽札作りに例えられます。偽札を作る偽造者(Generator)は警察(Discriminator)を騙すように学習していき、警察は偽札を見破れるように学習していきます。
ここで訓練データを$\boldsymbol{x}$,ノイズを$z$,確率分布を$p(\boldsymbol{x})$,$p(z)$,Generatorを$G$,Discriminatorを$D$,Discriminatorが$\boldsymbol{x}$を正しく識別する確率を$D(\boldsymbol{x})$,Generatorの$z$からの生成データを$G(z)$とすると目的関数は以下のようになります。
{\rm min}_{G}{\rm max}_{D}V(D,G)=\mathbb{E}_{\boldsymbol{x}\sim p_{data}(\boldsymbol{x})}[{\rm log}D(\boldsymbol{x})]+\mathbb{E}_{z\sim p_{z}(z)}[{\rm log}(1-D(G(z)))]
Generatorは本物を偽物と間違え($D(\boldsymbol{x})\to 0$)、偽物を本物と間違える($D(G(z))\to1$)ようにするため、$V(D,G)$が小さくなるように学習し、Discriminatorはその逆で$V(D,G)$が大きくなるように学習します。
GANにはたくさんの派生があり、画像変換(線画⇔写真、夏の写真⇔冬の写真)や実在しない人間の画像生成など驚くべき技術がたくさん生み出されています。(詳しくはこちら)
SinGAN
従来のGANでは学習に大量の訓練データを必要としますが、SinGAN(Single-Image-GAN)はその名の通り1枚の画像から学習することのできるGANです。SinGANのタスクとしてUnconditional Image Generation、Image Harmonizationなどがあります。(後述)
学習方法
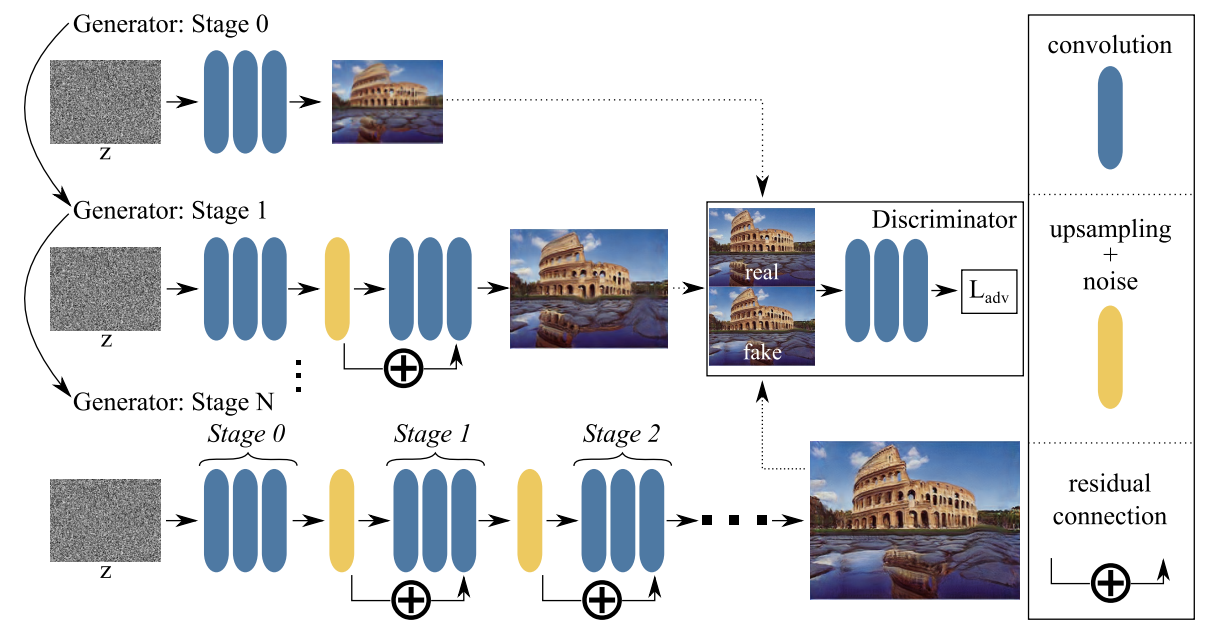
SinGANでは図(論文Short Summaryより引用)のように複数のGeneratorを用い、各Generatorは前のGeneratorの出力画像を入力として受け取ります。また、Generatorはそれぞれ個別に学習し、学習時に前のGeneratorの重みは固定します。(始めにG0を学習し、G0を固定してG1を学習、G0,G1を固定してG2を学習…)
ここで重要な点として、Discriminatorは画像を全体としてでなくパッチとして見るようにし、一部分を見れば本物そっくりだが全体として見ると異なっているような画像を作ることができます。(図の分裂したコロッセオ)

ConSinGAN
上記の手法ではGenerator間の相互作用を制限してしまうことが発覚したということで、新しく提案された手法がGeneratorを固定せずに同時に(Concurrently)学習するConSinGAN(Concurrently-Single-Image-GAN)です。
学習方法
全てのGeneratorを同時に学習するとオーバーフィッティングしてしまうので、論文では次の2点を取り入れています。
- 後半3つのGeneratorを同時に学習する。
- 前のGeneratorに行く度に学習率を1/10倍に小さくする。
これは図(論文Short Summaryより引用)のようになります。
最適化手法はAdamです。

ここで学習率を小さくすることは生成画像の多様性を作れる分訓練画像の再現性は失われ、トレードオフの関係にあります。
今回このConSinGANの学習方法でGenerator数を減らす事で、SinGANと比べて学習時間が約1/6となり、しかもより高いパフォーマンスをあげたとのことです。
モデルアーキテクチャ
Genarator,Discriminatorとも図(論文より引用)のように畳み込み層を複数層重ねた構造をしています。ここで次のGeneratorへの入力となる特徴マップはupsamplingした後多様性のためにノイズを加え、さらに出力が大きくずれないようにresidual connectionで繋いでいます。
目的関数
ステージ$n$での目的関数は下記のようになります。
{\rm min}_{G_{n}}{\rm max}_{D_{n}}L_{\rm adv}(G_n,D_n)+\alpha L_{\rm rec}(G_n)
ここで$L_{\rm adv}(G_n,D_n)$は目的関数にWasserstein距離を用いたWGAN-GP(論文)の目的関数で識別の精度を表す項で、$L_{\rm rec}(G_n)$は生成画像と訓練画像の距離で学習の安定性を表す項です。
L_{\rm adv}(G_n,D_n)=\mathbb{E}_{z\sim p_{z}(z)}[D(G(z))]-\mathbb{E}_{{\boldsymbol x}\sim p_{data}}[D({\boldsymbol x})]+\lambda \mathbb{E}_{{\hat{\boldsymbol x}}\sim p_{{\hat{\boldsymbol x}}}}[(||\nabla_{{\hat{\boldsymbol x}}} D({\hat{\boldsymbol x}})||_2-1)^2]\\
L_{\rm rec}(G_n)=||G_n(x_0)-x_n||_2^2
$\alpha$はデフォルト10の定数で、${\hat{\boldsymbol x}}$は訓練データと生成データを結んだ直線上の点、$\lambda$は定数、$x_n$は訓練画像、$x_0$は$G_n$への入力画像です。
ただし$L_{\rm adv}(G_n,D_n)$の入力はタスクによって異なり、例えばUnconditional Image Generationではノイズが与えられますがImage Harmonizationでは訓練画像をAugment(一部を切り取ったり色を変えるなどのノイズを加える)した画像を与えた方が良い結果になったそうです。
タスク
今回はUnconditional Image GenerationとImage Harmonizationを使ってみました。他にも興味深いタスクが述べられているので興味のある方は論文をご覧ください。
Unconditional Image Generation
図(論文Short Summaryより引用)のように訓練画像にランダムにノイズ$z$を加え、大域的な構造を保ちながらリアルな実在しない画像を作ることができます。(画像サイズを変えても調整しているのが分かります。)

Image Harmonization
図(論文Short Summaryより引用)のように訓練画像(絵画など)を学習し、加えたオブジェクトを学習した画像のスタイルで調和させます。

ファインチューニング
Image Harmonizationでは、さらに学習済みのモデルにnaive画像(上図のNaive)を加えて訓練し直すことでより良い結果を得ることができます。(上図のFine-tune)
実装
公開されているGitHubをcloneして、無料でGPUが使用できるGoogle Colaboratory上で動かしました。
# リポジトリクローン
!git clone https://github.com/tohinz/ConSinGAN.git
# 使用ライブラリインストール
pip install -r requirements.txt
途中でColaboratoryのツールのバージョンが違うという内容のエラーが出ましたが動作は問題ありませんでした。
Unconditional Generation
Images/Generation/に訓練画像を置きます。以前ヴェネツィアで撮影したリアルト橋(rialto.jpg 1867×1400ピクセル)を使ってみます。

!python main_train.py --gpu 0 --train_mode generation --input_name Images/Generation/rialto.jpg
--gpuで使用するGPU(デフォルトで0)、--train_modeでタスクの指定(generation, harmonizationなど)、--input_nameで訓練画像のpathを指定します。なお、今回は変更していませんが任意で学習率(--lr_scale)やGenerator数(--train_stage)なども変えることができます。
デフォルトではGenerator数5, それぞれ2000イテレーションで学習しています。
サイズが大きいからか訓練には69分かかりました。結果はTrainedModels/rialto/yyyy_mm_dd_hh_mm_ss_generation_train_depth_3_lr_scale_0.1_act_lrelu_0.05というところにできました。生成サンプルをいくつか載せます。



少しノイズが強いですがグニョグニョした橋ができました。
Image Harmonization
絵画×猫
絵画(干し草作り)に猫の写真を合わせてみます。
左が訓練画像(300×300ピクセル hoshikusa.jpg)、右がnaive画像(142×130ピクセル hoshikusa_naive.jpg)です。これらをImage/Harmonization/に配置します。
なお本来は追加するオブジェクトの部分を切り取ったマスク画像を配置するようですが作れなかったのでマスクなしで作成しています。


!python main_train.py --gpu 0 --train_mode harmonization --train_stages 3 --min_size 120 --lrelu_alpha 0.3 --niter 1000 --batch_norm --input_name Images/Harmonization/hoshikusa.jpg
訓練時間は15分でした。続いて訓練モデルにnaive画像を適用します。
!python evaluate_model.py --gpu 0 --model_dir TrainedModels/hoshikusa/yyyy_mm_dd_hh_mm_ss_harmonization_train_depth_3_lr_scale_0.1_BN_act_lrelu_0.3 --naive_img Images/Harmonization/hoshikusa_naive.jpg
結果はTrainedModels/hoshikusa/yyyy_mm_dd_hh_mm_ss_harmonization_train_depth_3_lr_scale_0.1_BN_act_lrelu_0.3/Evaluation/にできます。

分解能が悪いですが写真の猫の色が変わりました。
さらにファインチューニングしてみます。
!python main_train.py --gpu 0 --train_mode harmonization --input_name Images/Harmonization/hoshikusa.jpg --naive_img Images/Harmonization/hoshikusa_naive.jpg --fine_tune --model_dir TrainedModels/hoshikusa/yyyy_mm_dd_hh_mm_ss_harmonization_train_depth_3_lr_scale_0.1_BN_act_lrelu_0.3
イテレーション数をデフォルトの2000回(11分)やると左のように背景の色と一体化してオーバーフィッティングしてしまいました。論文では500回で十分と述べられています。(右)


白黒背景×ラーメン
写真を漫画風に変換してみます。
左が訓練画像(pen_building.jpg 600×337ピクセル)、右がnaive画像(pen_building_naive.jpg 283×213ピクセル)です。


同様に実行して結果は次のようになりました(訓練時間9分)。左が通常評価、右がファインチューニング(100イテレーション)です。


ラーメンを漫画風にできました。このタスクはファインチューニングしなくても十分のようです。
まとめ
今回は個人的に興味を持っていたGANのモデルで、1枚の訓練画像で生成できるSinGANを改善したConSinGANについての論文を読み、動かしてみました。画像生成技術はたくさんのモデルが出ていて感動するような技術が多く、結果も分かりやすいので楽しいですね。ただ、著作権の問題で自分の好きなアニメや漫画の画像を使って作ったものを公開できないのは残念でした。