はじめに
AI時代になり、APIを利用する主体が大きく変わってきたと感じています。
これまでAPIを利用するのは主にフロントエンドのアプリケーションでしたが、近年ではそれに加えて、AIや自動化処理、Agentのような存在が同じAPIを利用する場面が増えてきました。その結果として、APIの呼ばれ方も少しずつ変わってきているように思います。
一つ一つのAPIを単純に呼び出すのではなく、複数のデータを組み合わせた結果を、できるだけ少ないリクエストで取得したい、という要求が以前よりも強くなっているのではないでしょうか。
本記事では、そうした背景を踏まえ、GraphQLを使ってアプリケーションやAIから扱いやすいAPIを構築するという観点で、サンプル例を通じて構築の流れをご紹介します。
また、本記事においては一部 IBM Bob を活用しております。IBM Bob の活用例としても是非ご覧ください。
今回の構成
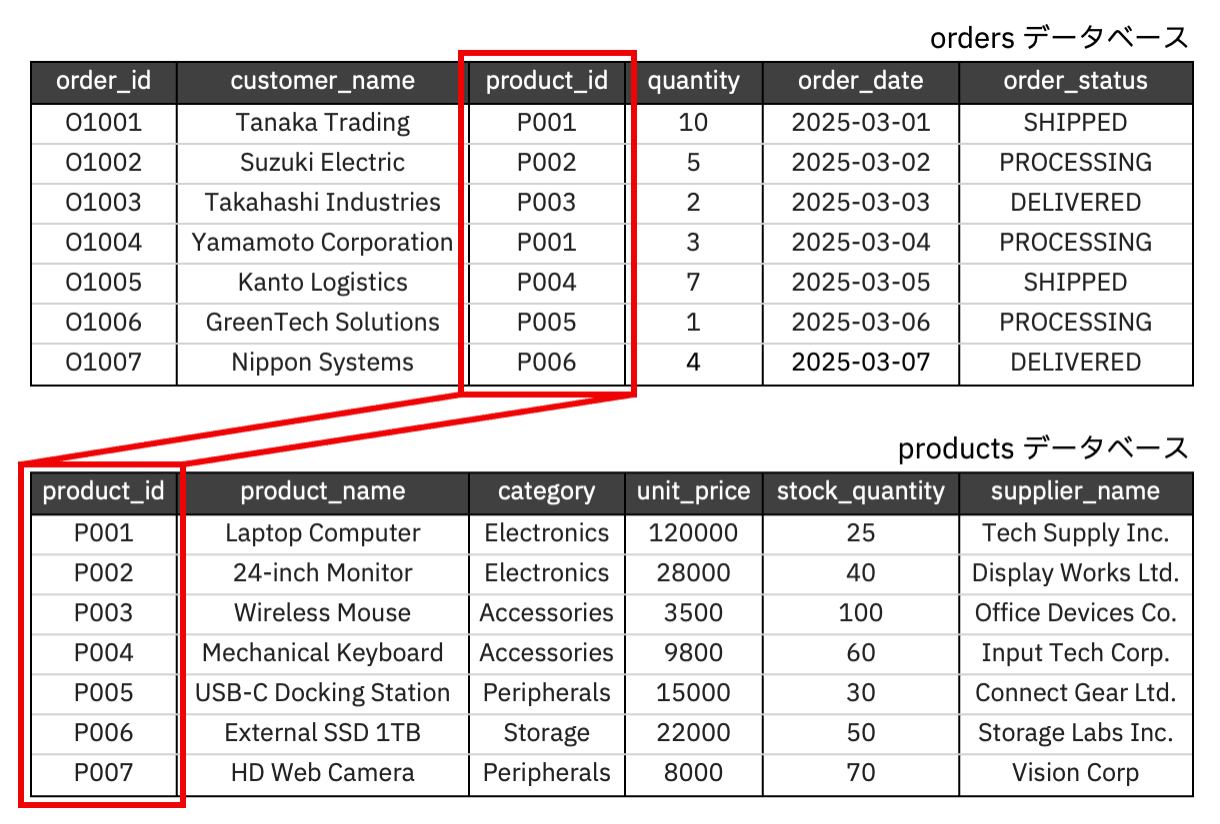
今回題材にしたのは、非常にシンプルな構成です。
一つは注文情報を持つ Order データベース、もう一つは商品情報を持つ Product データベースです。
Order データベースには Product ID が含まれており、その ID を使って Product データベースから対応する商品情報を取得できる、という関係になっています。
このようなケースにおいて、従来の REST API ベースの設計では、次のような流れになることが多いと思います。
REST API での呼び出しの流れ
- Order API を呼び出す
- レスポンスに含まれる Product ID を取り出す
- Product API を呼び出す
クライアント側、あるいはAI側で、上記のような手順を意識しながら実装する必要があります。もちろん、この方法自体が悪いわけではありませんが、APIを呼ぶ主体が増え、処理が複雑になるにつれてクライアント側の負荷は少しずつ大きくなっていきます。
GraphQL でデータソースをまとめて扱う
そこで今回試してみたのが、GraphQLを使って既存のAPIやデータベースをまとめて扱うというアプローチです。
GraphQLを使うことで、Order と Product のように分かれて存在しているデータソースを、
「一つのつながったデータ構造」として扱えるようになります。
クライアントやAIは、バックエンドにどのようなAPIやデータベースが存在しているかを細かく意識する必要がなく、欲しいデータのみを選択して問い合わせる、という使い方ができるようになります。
今回のケースでは、Order ID を指定するだけで、その注文情報と、それに紐づく Product の情報をまとめて取得する、といった問い合わせを一度のリクエストで行えるようになります。
今回の検証では、このGraphQLの仕組みを実現するためのツールとして、IBM API Connect for GraphQL を利用しました。バックエンドの構成を大きく変えることなく、コマンドベースで既存のAPIやデータソースを簡単にGraphQLとして公開できるため、GraphQLの構築には非常に適したツールであると考えています。
なお、GraphQL 自体の概要や考え方については、以前に別の記事でまとめています。基本的な仕組みにつきましてはそちらもあわせてご参照いただければと思います。
GraphQL API の構築の流れ
ここからは、IBM API Connect for GraphQLを例に、GraphQL APIを構築する様子を見ていきます。GraphQL API を構築するために必要な作業は、大きく分けると次のような手順になります。
GraphQL API 構築手順
- エンドポイントの初期化
- データソースのインポート
- GraphQL API のデプロイ
- GraphQL API のテスト実行
いずれも、GraphQLとしてデータを扱うための基本的なステップです。今回使用した IBM API Connect for GraphQL では、これらの作業をStepZen CLIという独自のCLIを活用してコマンドベースで実行していく形になります。
(ちなみにStepZenというのは、IBM API Connect for GraphQLの昔の呼び名です。当時のCLIを踏襲して提供しているため、その名残りがあります。)
1. エンドポイントの初期化
はじめにGraphQL APIを公開するエンドポイントを指定します。IBM API Connect for GraphQLにログイン後、以下のコマンドを実行することでエンドポイントが作成されます。
stepzen init --endpoint=api/<エンドポイント名>
なお、上記コマンドを実行するとGraphQL APIを公開するのに必要なファイルがローカルに作成されます。あらかじめフォルダーを作成し、フォルダーに移動した上で実行することを推奨します。
2. データソースのインポート
次にデータソースをインポートします。利用できるデータソースはREST APIやデータベース、GraphQL APIなどから選択することができます。最上段のコマンドを実行すると接続情報の入力のための質問が順に行われます。
% stepzen import postgresql
stepzen import postgresql - introspect a PostgreSQL database and extend your GraphQL schema with the types, queries and mutations for accessing it through a StepZen API.
? What is your host? (and optional port as host:port) <ホスト名>
? What is the username? <ユーザー名>
? What is the password? [hidden]
? What is your database name? <データベース名>
? What is your database schema (leave blank to use defaults)
? Automatically link types based on foreign key relationships using @materializer
(https://stepzen.com/docs/features/linking-types) No
Starting... done
Successfully imported postgresql data source into your GraphQL schema
GraphQL APIに含めたいデータソースを上記手順で順にインポートしていくことで、一つの GraphQL APIで複数のデータソースからデータを取得することができるようになります。
今回のケースでは Order データベースと Product データベースを読み込んでいます。
3. GraphQL API のデプロイ
これまでの手順において、GraphQL APIを公開するためのファイルがローカルに作成されました。指定したエンドポイントに対してファイルをデプロイするためには以下のコマンドを実行します。
stepzen start
上記コマンドを実行することでローカルに置かれたファイルが GraphQL サーバー上にデプロイされ、API実行が可能になります。
4. GraphQL API のテスト実行
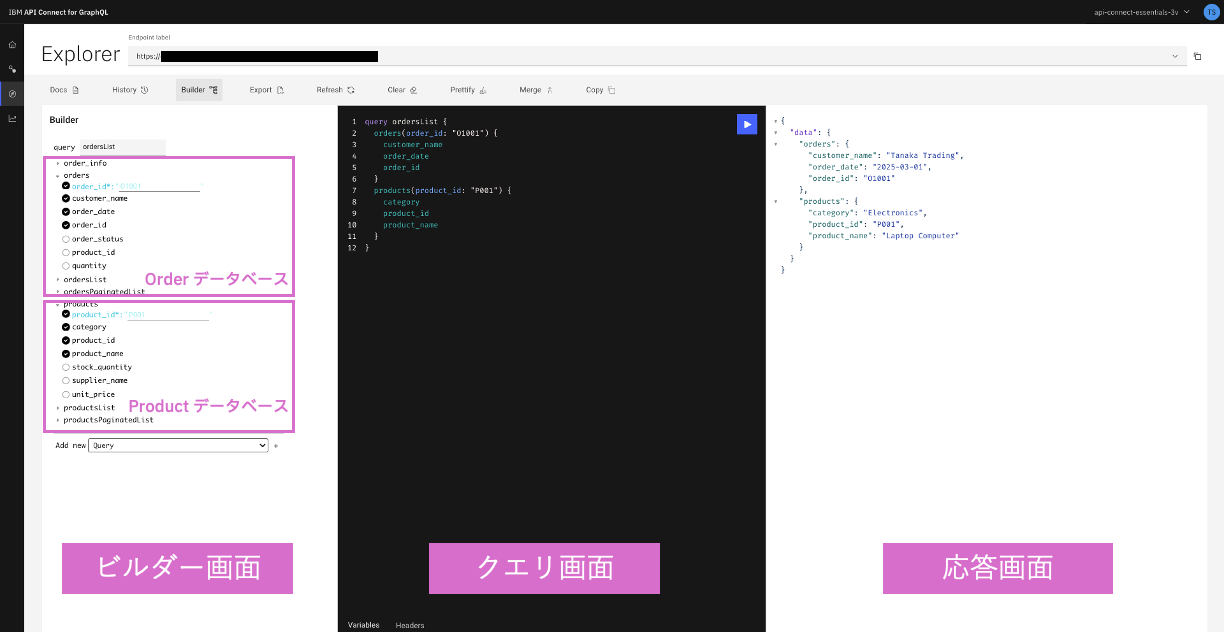
デプロイされた GraphQL API は、 IBM API Connect for GraphQL のコンソールからテスト実行ができます。Order データベース、 Product データベースそれぞれから必要なデータのみを選んで選択的にデータを取得できる様子を確認することができます。
ビルダー画面でチェックを入れたものが、クエリに反映されてその応答の様子を確認できます。
Order ID、 Product ID それぞれに値を入力することで、それらに紐づくデータを Order データベース、Product データベースそれぞれから取得している様子を確認することができます。
IBM Bob を利用したデータベースのフェデレーション
ここまでで、複数のデータベースを読み込み、GraphQL API としてまとめて扱えるようになるところまでを見てきました。この状態でも、Order データベースと Product データベースを
一つの GraphQL クエリで参照すること自体は可能です。
しかし、ここで一つポイントがあります。Order データベースと Product データベースは、単に「同時に取得できればよい」わけではなく、Order に含まれる Product ID を使って、対応する Product 情報を取得したいという関係性を持っています。このように、「複数のデータソースをまたいで、意味のある関連付けを行いながらデータを取得する」というケースの場合は、GraphQL 側で若干の作り込みが必要になってきます。
今回はこの作り込みの部分を IBM が提供する AI アシスタントである IBM Bob で実施してみました。
1. 編集が必要なファイルの確認
ここまでの手順の中で、ローカルには以下のファイルが生成されています。今回は postgresql に含まれる、 index.graphql の編集が必要です。
.
├── config.yaml
├── index.graphql
├── postgresql
│ └── index.graphql <-このファイルの編集が必要
└── stepzen.config.json
2. IBM Bob に与えたプロンプト
今回、IBM Bob には、既存のindex.graphqlファイルをそのまま置き換えられるように以下のプロンプトを与えて、新しいindex.graphqlファイルを生成してもらいました。
以下のプロンプトは一見複雑ですが、typeについてはIBM API Connect for GraphQLにて自動生成されたものをそのままコピーして利用しており、後半部分は基本的なルールを指示しているだけなのでそのままコピーしてご利用いただけます。
API Connect for GraphQL において、1つ目のテーブル(Orders)と 2つ目のテーブル(Products)を、外部キーを使って 1 回の GraphQL クエリで取得できる仕組みを、index.graphql に定義してください。
今回の前提として、最初に以下の GraphQL type 定義は与えられています(これらの type 自体は変更しないでください)。
type Orders {
customer_name: String!
order_date: Date!
order_id: String! (主キー)
order_status: String!
product_id: String!
quantity: Int!
}
type Products {
category: String!
product_id: String! (主キー)
product_name: String!
stock_quantity: Int!
supplier_name: String!
unit_price: Int!
}
Orders type には product_id が含まれており、これは Products type の主キー product_id と対応しています。
以下の情報も必ず参考にしてください
1つ目のテーブルには、2つ目のテーブルの主キーに対応するカラムが含まれています
利用者が 1つ目のテーブルの主キーを指定した場合、1つ目のテーブルのレコードを取得し、その中に含まれる「2つ目のテーブルの主キー」を使って2つ目のテーブルの該当レコードを取得します
この一連の処理を GraphQL の 1 クエリで実行できる構成を作成してください
index.graphql を編集してください
@materializer を利用してテーブル間の関連を定義してください
@materializer を適用するための 新しい type を 1 つ作成してください。type 名は任意で構いません。この type は「1つ目のテーブルの情報」と「2つ目のテーブルの情報」をまとめて返す役割を持ちます
作成した type の中に、任意の名前のフィールドを 1 つ追加してください
このフィールドの型は 2つ目のテーブルの type を指定してください
このフィールドに対して @materializer を適用してください
query には 2つ目のテーブルを取得する Query 名を指定してください
arguments には以下の意味を持つ指定を行ってください
name:呼び出し先 Query が受け取る引数名
field:親オブジェクト(1つ目のテーブル)に含まれるフィールド名
type Query に 新しい Query を 1 つ追加してください
この Query は引数として1つ目のテーブルの主キーを受け取り、戻り値の型は、先ほど作成した @materializer 用の type としてください
この Query には @dbquery を指定してください
type、schema、query、configuration を明示してください
query の SQL では、WHERE 句に 「1つ目のテーブルの主キー = $1」 を必ず指定してください
出力は index.graphql の内容のみを生成してください
解説文や補足説明は出力しないでください
3. 作成されたファイル
IBM Bobによって以下のファイルが生成されました。OrderWithProduct という type が自動で生成されており、その OrderWithProduct を参照するクエリタイプも作成されていることが確認できます。
type Orders {
customer_name: String!
order_date: Date!
order_id: String!
order_status: String!
product_id: String!
quantity: Int!
}
type Products {
category: String!
product_id: String!
product_name: String!
stock_quantity: Int!
supplier_name: String!
unit_price: Int!
}
type OrderWithProduct {
customer_name: String!
order_date: Date!
order_id: String!
order_status: String!
product_id: String!
quantity: Int!
sample_element: Products @materializer(
query: "getProductById"
arguments: [
{name: "product_id", field: "product_id"}
]
)
}
type Query {
getProductById(product_id: String!): Products @dbquery(
type: "postgresql"
schema: "public"
query: "SELECT category, product_id, product_name, stock_quantity, supplier_name, unit_price FROM products WHERE product_id = $1"
configuration: "postgresql_config"
)
getOrderWithProduct(order_id: String!): OrderWithProduct @dbquery(
type: "postgresql"
schema: "public"
query: "SELECT customer_name, order_date, order_id, order_status, product_id, quantity FROM orders WHERE order_id = $1"
configuration: "postgresql_config"
)
}
今回は、Query のみを実施できる形でプロンプトを与えたため、Mutationに関する処理には対応していませんが、適切なプロンプトを与えることでMutationにも対応可能なファイルを生成することは可能です。
ちなみに、IBM API Connect for GraphQLには、DBに対して外部キーの指定がある場合は、データベースのインポート時点でフェデレートを自動で行ってくれる機能もあります。
4. 生成されたファイルを適用してテスト実行
IBM Bob で生成された index.graphql ファイルをデプロイし、再び IBM API Connect for GraphQL にてテスト実行を行います。先ほどテストを行った際は、Order ID、 Product ID それぞれに値の入力が必要でしたが、データベースが正常にフェデレートされているため、Order ID のみの入力で、それに紐づく Product の情報を取得できていることを確認することができます。

まとめ
本記事では、AI時代におけるAPIの使われ方を背景に、GraphQLを使って複数のデータソースをまとめて扱うという考え方と、その実装までの流れを紹介しました。
GraphQLを利用することで、どのAPIをどの順番で呼ぶかではなく、どんなデータが欲しいかを起点にデータを取得できるようになり、クライアントアプリケーションやAIから見たAPIの使い勝手は、よりシンプルになります。
一方で、データベースをまたいでデータを関連付けながら取得する場合には、データソースのフェデレーションという考え方が必要になります。この部分は慣れてしまえばそれほど難しくありませんが、初めてGraphQLを扱う際には難しさを感じやすい部分でもあります。今回のケースでは、このフェデレーション部分を IBM Bob を使ってプロンプトベースで自動化することで、実装の負担を抑えられることを確認しました。
GraphQLを使ったデータ統合に取り組む際の、一つの参考例として、何かしらのヒントになれば幸いです。
参考情報
IBMの最新情報、イベント情報、さらに役立つ資料は、以下のIBM Communityでも発信・格納されています。最新のトレンドや有益な情報をチェックするために、ぜひご覧ください!
-
Integration コミュニティ: IBM Community - Integration
Integrationに関する最新のイベント情報、ナレッジ共有、便利なドキュメントをチェック!