AWS Certified Generative AI Developer - Professional
2025/12/16からAWSの新しい認定試験「AWS Certified Generative AI Developer - Professional」がベータ版受験可能になりました。
その名の通り、生成AIを利用した開発者向けの試験です。
以下、公式の説明
AWS Certified Generative AI Developer - Professional は、Bedrock などの AWS サービスを使用した、本番環境に対応する AI ソリューションの構築とデプロイに関する高度な技術的専門知識を示します。2 年以上のクラウドの経験があり、キャリアアップを高めたいと考えている開発者に最適です。AI イニシアチブに投資する組織にとって、この認定は、概念実証の枠を超えて、セキュリティとコスト効率を維持しながら具体的なビジネス成果をもたらす本番環境グレードの生成 AI ソリューションを構築できる開発者を特定および検証するための信頼できる方法を提供するものです。
最初の 5,000 名の試験参加者には、合格時に特別な Early Adopter バッジが贈られます。
注目は最後の文章、「最初の 5,000 名の試験参加者には、合格時に特別な Early Adopter バッジが贈られます。」です!
せっかくなので、初日受験して撃沈するかバッジゲットするかしてやろうということで、受験してまいりました!
さっそく結果
結果は合格でした!

ぎりっぎりの合格でした!
Early Adopterバッジもゲットできました!

感想
ガイドラインに抵触しない程度に感想を述べます。
まず、すべての問題にBedrockが登場してました(笑)
そして決して簡単ではなかったです。
他のプロフェッショナル試験同様、かなり具体的な状況が提供されますので、85問は正直体力勝負ですね。
個人的に特に難しいなと感じたのは、チャンキング戦略に関する問題です。
ナレッジベースがハルシネーションする、あるいは意味的に通らない場合にどうするべきか?のような問題が難しかったです。
StepFunctionsとBedrock Flowsの使い分けも難しいポイントでした。
他にもいくつか悩ましい問題があったので、せっかくの機会ですし、勉強ついでに記事にしようかと思います!
全体的にセキュリティ関連の問題も多くあったように感じます。
AWSがこれからPoCではなく本番運用を見据えているというのがよくわかる内容でした。
試験ガイドにあった新しい問題形式期待していたんですが、私は出会わなかったです。
設問の種類
試験には、以下の出題形式が 1 つ以上含まれています。
• 択一選択問題 : 正しい選択肢が 1 つ、誤った選択肢 (不正解) が 3 つ提示される。
• 複数選択問題 : 5 つ以上の選択肢のうち、正解が 2 つ以上ある。設問に対する点数
を得るには、正解をすべて選択する必要がある。
• 並べ替え: 指定されたタスクを完了することを目的とした 3~5 つの答えのリスト
が提示される。設問に対する点数を得るには、正解を選択し、正しい順序に並べる
必要がある。
• 内容一致: 3~7 つのプロンプトのリストと一致する答えのリストが提示される。
設問に対する点数を得るには、すべてのペアを正しく一致させる必要がある。
準備
こういった新しい試験の準備をどうするべきか悩む方も多いのではないでしょうか。
Udemy等のプラットフォームにも当然講座はないですし、情報量がとにかく少ないです。
今回は私が実施した勉強をご紹介します。
前提として、私はフルスクラッチで生成AI(Bedrock)を使用してチャットボットを作成した経験があります。
AWS公式の学習コンテンツ
AWS Skill Builderで講座が公開されています!
各領域ごとの必要とされるスキルの説明やサンプルの問題が提供されています。
課金すると模擬試験も受けられるようです!
私は守銭奴なので無料のものだけしかやってません。
自作問題
今回の試験も例にならって試験ガイドが用意されています。
AI Developer Professionalを受けようって方ならお察しかと思いますが、これ使って生成AIでサンプル問題作ればいいわけです!
私はPython信者なので、Strands AgentsとAWS Documentation MCPを使用して問題リストを作成し、Kiroにお願いして問題集アプリをReactで作りました。
参考までにスクリプトを載せておきますが、複数選択の解答の数が多かったり、諸々調整が必要です。
問題の雰囲気を把握するには十分かなと思います。
プロンプトは試験ガイドの内容を抜粋しています。
参考スクリプト
import logging
import pandas as pd
import random
import json
from mcp import stdio_client, StdioServerParameters
from strands.tools.mcp import MCPClient
from strands import Agent
from strands.models import BedrockModel
from utils import get_txt
from pathlib import Path
import boto3
logger = logging.getLogger()
logger.setLevel(logging.INFO)
PROFILE = 'XXXXXXXXXXXXXXXXXXXXXXXX'
REGION = 'ap-northeast-1'
MODEL_ID = 'jp.anthropic.claude-haiku-4-5-20251001-v1:0'
QUESTION_NUM = 85
if __name__ == "__main__":
session = boto3.Session(profile_name=PROFILE, region_name=REGION)
stdio_mcp_client = MCPClient(
lambda: stdio_client(
StdioServerParameters(
command="python",
args=["-m", "awslabs.aws_documentation_mcp_server.server"],
)
)
)
# 試験ガイドの項目を読み込み
exam_content_path = './exam_contents.csv'
exam_content_df = pd.read_csv(exam_content_path, encoding='utf-8')
# カテゴリごとの問題数を計算
category_rate = {
'基盤モデルの統合・データ管理・コンプライアンス': 0.31,
'実装と統合': 0.26,
'AI の安全性、セキュリティ、ガバナンス': 0.20,
'GenAI アプリケーションの運用効率と最適化': 0.12,
'テスト、検証、トラブルシューティング': 0.11
}
# CSVファイルをヘッダー付きで作成
output_path = './exam_questions.csv'
headers = ['Question', 'Question Type', 'Answer Option 1', 'Explanation 1', 'Answer Option 2', 'Explanation 2',
'Answer Option 3', 'Explanation 3', 'Answer Option 4', 'Explanation 4', 'Answer Option 5', 'Explanation 5',
'Answer Option 6', 'Explanation 6', 'Correct Answers', 'Overall Explanation', 'Domain']
pd.DataFrame(columns=headers).to_csv(output_path, index=False, encoding='utf-8')
total_question_count = 0
for category, rate in category_rate.items():
category_df = exam_content_df[exam_content_df['コンテンツ分野'] == category]
category_questions_skill = [(row['スキル内容'], row['タスク']) for i, row in category_df.iterrows()]
category_question_num = int(QUESTION_NUM * rate)
if not category_questions_skill:
logger.warning(f"No data found for category: {category}")
continue
category_count = 0
while category_count < category_question_num:
system_prompt = get_txt(Path(__file__).parent / random.choices(['choice_question_prompt.txt', 'select_question_prompt.txt'], weights=[70, 30], k=1)[0])
with stdio_mcp_client as mcp_client:
tools = mcp_client.list_tools_sync()
agent = Agent(
system_prompt=system_prompt,
model=BedrockModel(
model_id=MODEL_ID,
boto_session=session,
cache_prompt='default',
max_tokens=4096,
temperature=0.5
),
tools= tools
)
random_skill = random.choice(category_questions_skill)
user_prompt = f"""
コンテンツ分野: {category}
タスク: {random_skill[1]}
スキル内容: {random_skill[0]}
"""
generated_data = str(agent(user_prompt))
# 生成された文字列内に含まれるjson形式のデータを抽出
if '{' in generated_data and '}' in generated_data:
start_index = generated_data.index('{')
end_index = generated_data.rindex('}') + 1
json_str = generated_data[start_index:end_index]
try:
json_data = json.loads(json_str)
row_data = {col: json_data.get(col, '') for col in headers}
pd.DataFrame([row_data]).to_csv(output_path, mode='a', header=False, index=False, encoding='utf-8')
category_count += 1
total_question_count += 1
except json.JSONDecodeError:
logger.error(f"Invalid JSON format: {json_str}")
continue
if total_question_count < QUESTION_NUM:
questions_skill = [(row['スキル内容'], row['タスク']) for i, row in exam_content_df.iterrows()]
while total_question_count < QUESTION_NUM:
system_prompt = get_txt(Path(__file__).parent / random.choices(['choice_question_prompt.txt', 'select_question_prompt.txt'], weights=[70, 30], k=1)[0])
with stdio_mcp_client as mcp_client:
tools = mcp_client.list_tools_sync()
agent = Agent(
system_prompt=system_prompt,
model=BedrockModel(
model_id=MODEL_ID,
boto_session=session,
cache_prompt='default',
max_tokens=4096,
temperature=0.5
),
tools= tools
)
random_skill = random.choice(questions_skill)
user_prompt = f"""
コンテンツ分野: {category}
タスク: {random_skill[1]}
スキル内容: {random_skill[0]}
"""
generated_data = str(agent(user_prompt))
# 生成された文字列内に含まれるjson形式のデータを抽出
if '{' in generated_data and '}' in generated_data:
start_index = generated_data.index('{')
end_index = generated_data.rindex('}') + 1
json_str = generated_data[start_index:end_index]
try:
json_data = json.loads(json_str)
row_data = {col: json_data.get(col, '') for col in headers}
pd.DataFrame([row_data]).to_csv(output_path, mode='a', header=False, index=False, encoding='utf-8')
total_question_count += 1
except json.JSONDecodeError:
logger.error(f"Invalid JSON format: {json_str}")
continue
ちなみにKiroに作ってもらった問題アプリは以下のような感じです。
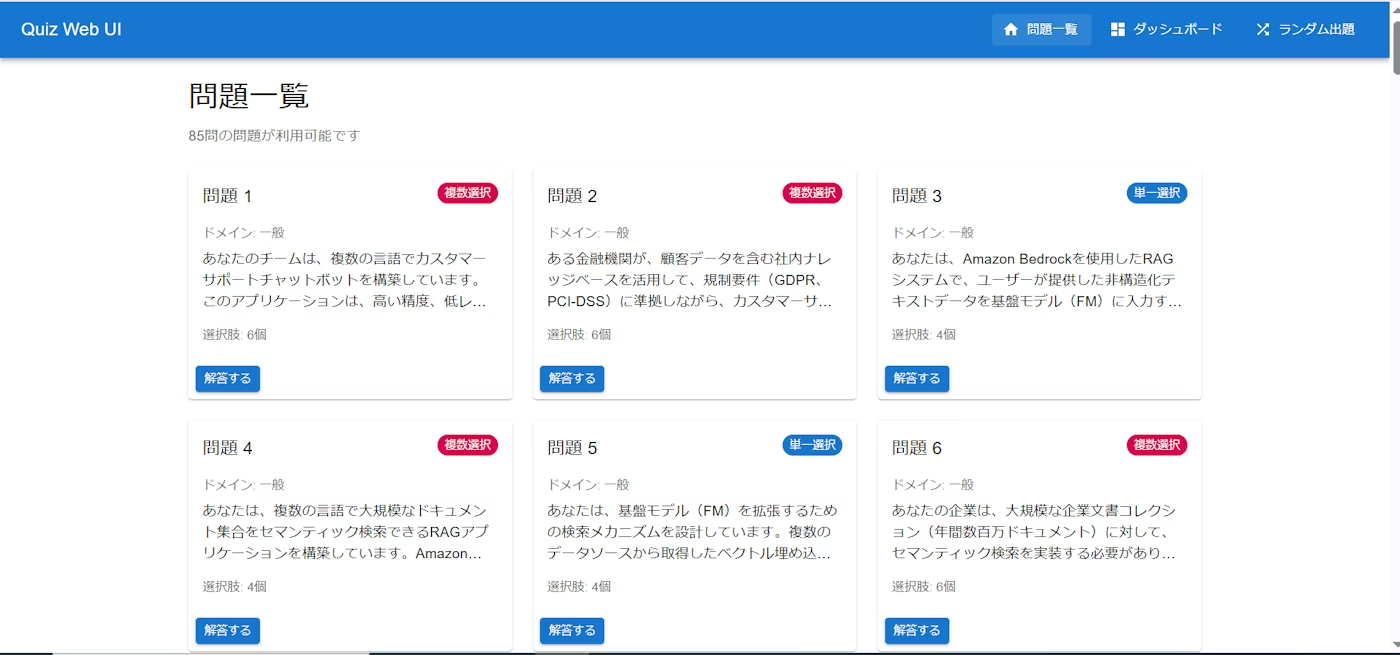
実際に受けてみて、似たような問題も多少はあったので全く無駄ではなかったかと思います!
その他
試験の準備として実施したことは上述の2つのみですが、以下のことを以前に体験していたことで解けた問題が多かったので、これから受験を考えている方は是非実施してみるといいかと思います。
フルスクラッチでの生成AIチャットアプリ構築
以下を含むようなウェブアプリを作成してみるといいかと思います。
・Bedrock API
・API Gateway
・Lambda
・DynamoDB
・Amplify
RAG構築
ナレッジベースを構築し、RAGチャットを作ってみるといいかと思います。
・Bedrock KnowledgeBase
・ベクターデータベース(Aurora or OpenSearch or S3 Vectors)
Strands Agentsによるエージェント作成
試験ガイドには記述があるのでやっておいた方がいいと思います!
出題数としては相当少なそうです
Bedrock Guardrailによる制御
責任ある生成AIに関する問題が多くみられました。
特にガードレール系の問題は多かったので一度実装してみるといいかと思います。
さいごに
とりあえず、合格できてよかったです!
みなさんも是非受験してみてください!
弊社では一緒に働く仲間を募集中です!
現在、様々な職種を募集しております。
カジュアル面談も可能ですので、ご連絡お待ちしております!
募集内容等詳細は、是非採用サイトをご確認ください。