1. 初めに
の記事の続きとなります。
vLLMでRayを使用したマルチノード推論実施方法について共有できればと思います。
2. ノードの概念とマルチノードの必要性について
ここでは、ノードの概念について説明したいと思います。
ノードは簡単に言うと物理的なマシンのことです。例えば、下記の図をイメージしていただければと思います。
簡単に言うと、「1マシンを1ノードにして分かりやすくしよう」という概念です。
ここで考えて頂きたいのが、1マシン(1ノード)に乗り切らない場合です。
その際の解決策として複数のマシン(ノード)を使用する方法があります。これをマルチノードと呼びます。
3. rayについて
マルチノードを扱うことが出来るライブラリの1つとしてrayがあげられます。
rayは、複数のノード(マシン)にまたがって処理を実行するためのフレームワークの1つなので、今回の推論ではこちらのライブラリを使用しました。
インストールは下記のように実施します。
pip install -U "ray[data,train,tune,serve]"
4. rayによるノード起動と何をしているか
起動コード
下記のスクリプトをsbatch start_ray_cluster.shというふうに起動することマルチノード推論が可能となります。詳細はスクリプトの後に記載します。
#!/bin/bash
#SBATCH --job-name=vllm-multinode-minimal # ジョブ名を指定
#SBATCH -p P04 # 適切なパーティションに変更
#SBATCH --nodelist=osk-gpu[60,62] # ここにノードを記載する
#SBATCH --nodes=2 # 2ノードを指定
#SBATCH --ntasks-per-node=2
#SBATCH --gpus-per-node=8 # 1ノードに対するGPU数を指定
#SBATCH --cpus-per-task=64
#SBATCH --time=6-00:00:00
#SBATCH --mem=0
#SBATCH --output=./ray-minimal-%j.out
#SBATCH --error=./ray-minimal-%j.err
############## Slurm pre-amble finished ##############
set -eo pipefail
######## 1. モジュールのロード ########
source /etc/profile.d/modules.sh
module purge
module load cuda/12.6 miniconda/24.7.1-py312
module load hpcx/2.18.1-gcc-cuda12/hpcx-mt
module load cudnn/9.6.0
module load nccl/2.24.3
source "$(conda info --base)/etc/profile.d/conda.sh"
conda activate llmbench
### Network Settings
export NCCL_DEBUG=TRACE
export GPU_MAX_HW_QUEUES=2
export TORCH_NCCL_HIGH_PRIORITY=1
export NCCL_CHECKS_DISABLE=1
export NCCL_IB_HCA=mlx5_0,mlx5_1,mlx5_2,mlx5_3,mlx5_4,mlx5_5,mlx5_8,mlx5_9
export NCCL_IB_GID_INDEX=3
export NCCL_CROSS_NIC=0
export NCCL_PROTO=Simple
export RCCL_MSCCL_ENABLE=0
export TOKENIZERS_PARALLELISM=false
export HSA_NO_SCRATCH_RECLAIM=1
export NCCL_SOCKET_IFNAME=enp25s0np0
export NVTE_FUSED_ATTN=0
export CUDA_DEVICE_MAX_CONNECTIONS=1
export NUMEXPR_MAX_THREADS=$SLURM_CPUS_PER_TASK
unset ROCR_VISIBLE_DEVICES
ulimit -v unlimited
######## 2. ヘッドノードのipアドレス取得 ########
nodes_array=($(scontrol show hostnames "$SLURM_JOB_NODELIST" | tr '\n' ' '))
head_node=${nodes_array[0]}
port=37173
dashboard_port=$((port + 1))
head_node_ip=$(srun --nodes=1 --ntasks=1 -w "$head_node" hostname --ip-address | awk '{print $1}')
if [[ "$head_node_ip" == *" "* ]]; then
IFS=' ' read -ra ADDR <<<"$head_node_ip"
if [[ ${#ADDR[0]} -gt 16 ]]; then
head_node_ip=${ADDR[1]}
else
head_node_ip=${ADDR[0]}
fi
fi
ip_head=$head_node_ip:$port
export ip_head
echo "============================================"
echo "Ray Cluster Information:"
echo " Head Node: $head_node ($head_node_ip)"
echo " Cluster Address: $ip_head"
echo " Dashboard: http://$head_node_ip:$dashboard_port"
echo " Total Nodes: ${#nodes_array[@]}"
echo " Total GPUs: $((${#nodes_array[@]} * 8))"
echo "============================================"
######## 3. ヘッドノードの起動 ########
echo "[INFO] Starting Ray head on $head_node..."
srun --nodes=1 --ntasks=1 -w "$head_node" \
bash -c "
unset ROCR_VISIBLE_DEVICES
source \"\$(conda info --base)/etc/profile.d/conda.sh\"
conda activate llmbench
ray start --head --node-ip-address=$head_node_ip --port=$port \
--dashboard-port=$dashboard_port --dashboard-host=0.0.0.0 \
--num-cpus=$SLURM_CPUS_PER_TASK --num-gpus=$SLURM_GPUS_PER_NODE --block
" &
sleep 30
######## 4. ワーカーノードの起動 ########
worker_num=$((SLURM_JOB_NUM_NODES - 1))
echo "[INFO] Starting $worker_num worker nodes..."
for ((i = 1; i <= worker_num; i++)); do
node_i=${nodes_array[$i]}
echo "[INFO] Starting worker on $node_i..."
srun --nodes=1 --ntasks=1 -w "$node_i" \
bash -c "
unset ROCR_VISIBLE_DEVICES
source \"\$(conda info --base)/etc/profile.d/conda.sh\"
conda activate llmbench
ray start --address $ip_head --node-ip-address=\$(hostname --ip-address) \
--num-cpus=$SLURM_CPUS_PER_TASK --num-gpus=$SLURM_GPUS_PER_NODE --block
" &
sleep 15
done
echo "[INFO] All Ray processes started. Waiting for cluster stabilization..."
sleep 30
echo "============================================"
echo "Ray Cluster Ready!"
echo " SSH to head node: ssh $head_node"
echo " Connect to cluster: ray.init(address='localhost:37173')"
echo " Dashboard: http://$head_node_ip:$dashboard_port"
echo "============================================"
######## 5. ヘルスチェック ########
ray_health_url="http://${head_node_ip}:${dashboard_port}/api/gcs_healthz"
ray_pids=($(jobs -pr))
echo "[INFO] Monitoring Ray processes: ${ray_pids[*]}"
health_check () {
curl -sf --max-time 5 "$ray_health_url" >/dev/null 2>&1
}
while true; do
# Check process health
for pid in "${ray_pids[@]}"; do
if ! kill -0 "$pid" 2>/dev/null; then
echo "[ERROR] Ray process $pid has exited at $(date)"
exit 1
fi
done
# Check dashboard health
if ! health_check; then
echo "[WARNING] Ray dashboard health check failed at $(date)"
fi
sleep 300
done
何をしているか
まず、マルチノードでは「ヘッドノード」と「ワーカーノード」と呼ばれる概念が登場します。
簡単に言うと
ヘッドノード
- クラスタ全体の管理
- タスク分配やリソース管理およびスケーリングなどを担当する
- 実際の計算も行うことが可能
ワーカーノード
- ヘッドノードからの指示で計算を実施するノード
という概念です。
先ほどのスクリプトでは、上記の2つのノードを起動させるスクリプトとなります。
コードの大まかな流れは下記です。
- モジュールのロード:HPC内で使用するモジュールをロードします
- ヘッドノードのipアドレス取得:ヘッドノードで必要なipアドレスを取得します
- ヘッドノードの起動:
ray start --headでヘッドノードを起動します - ワーカーノードの起動:
ray start --address <ヘッドノードのipアドレス>でヘッドノードを起動します - ヘルスチェックを実施
5. マルチノードでの推論の実行
ヘッドノードへのssh接続
ログを確認して、ヘッドノードのipアドレスを確認してログインノードで
ssh <ヘッドノードのipアドレス>
を実行してssh接続します。
ヘッドノードでのvLLMの起動
下記の設定でvLLMを起動します。
vllm serve <モデル名> \
--port $INFER_PORT \
--tensor-parallel-size 8 \
--pipeline-parallel-size 2 \
--distributed-executor-backend ray \
--max-model-len 32768 \
--rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}' \
--gpu-memory-utilization 0.95
ポイントとしては、
-
--pipeline-parallel-sizeを2に設定している点 -
--distributed-executor-backendをrayに設定している点
となります。
tensor parallelとpipeline parallelの概念図を下記に示します。
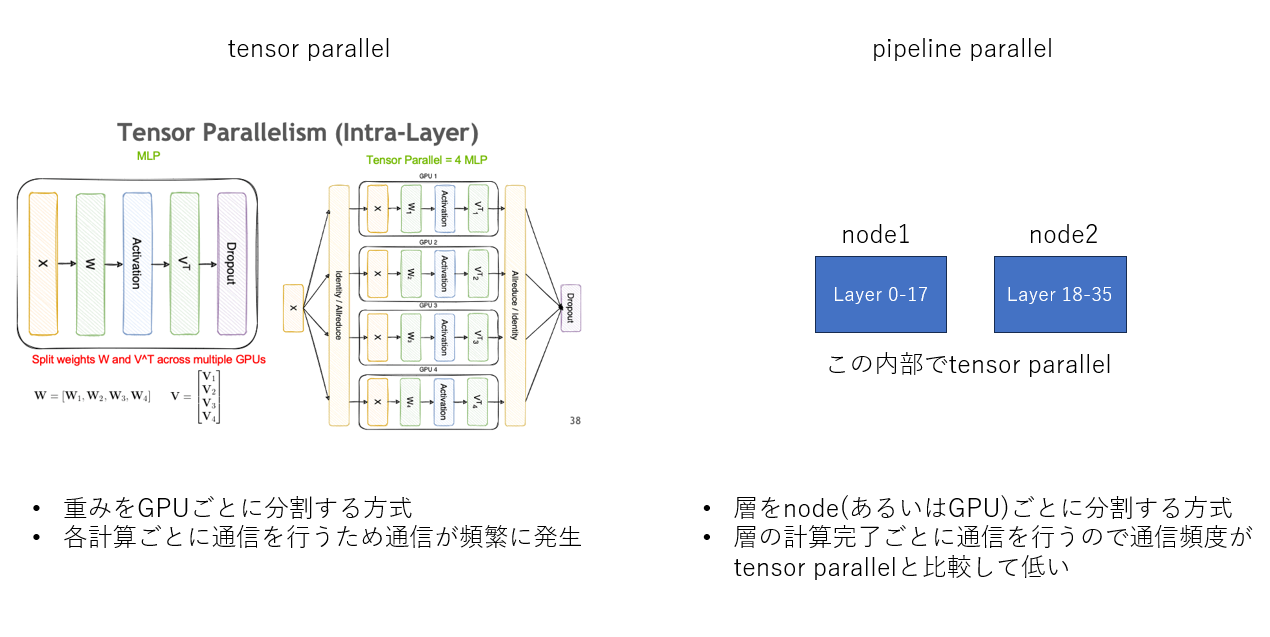
tensor parallelの図については、nvidiaの記事から抜粋しています。こちらの記事は理解しやすいかと思いますのでお勧めです。
マルチノード推論は異なるマシン間での通信が発生します。この通信速度がボトルネックになる可能性があるため、上述のような設定としています。
推論
vLLMのサーバーモードでは、OpenAI互換のAPIが使えます。これを利用して、公式の下記の処理を「別のssh接続をして実行する」、「同じbashファイルで推論する」などで推論を行います。
6. 感想
- 今まであまり理解が追い付いていなかった分散システムについての理解が少し進んだ
- tensor parallel、pipeline parallelの違いとどのような場面で有効かを知ることができた
本プロジェクトは、国立研究開発法人新エネルギー・産業技術総合開発機構(以下「NEDO」)の「日本語版医療特化型LLMの社会実装に向けた安全性検証・実証」における基盤モデルの開発プロジェクトの一環として行われます