はじめに
Google ADK (Agent Development Kit) と MCP (Model Context Protocol) を組み合わせ、BigQueryのデータを自律的に解析し、マーケティングナレッジを「Skill」として蓄積・活用するAIエージェントを構築しました。
モダンな構成でエージェントを構築する際の全体像と、実際に触ってみて分かった注意ポイントを共有します。
システム構成図
インフラ構成は以下の通りです。
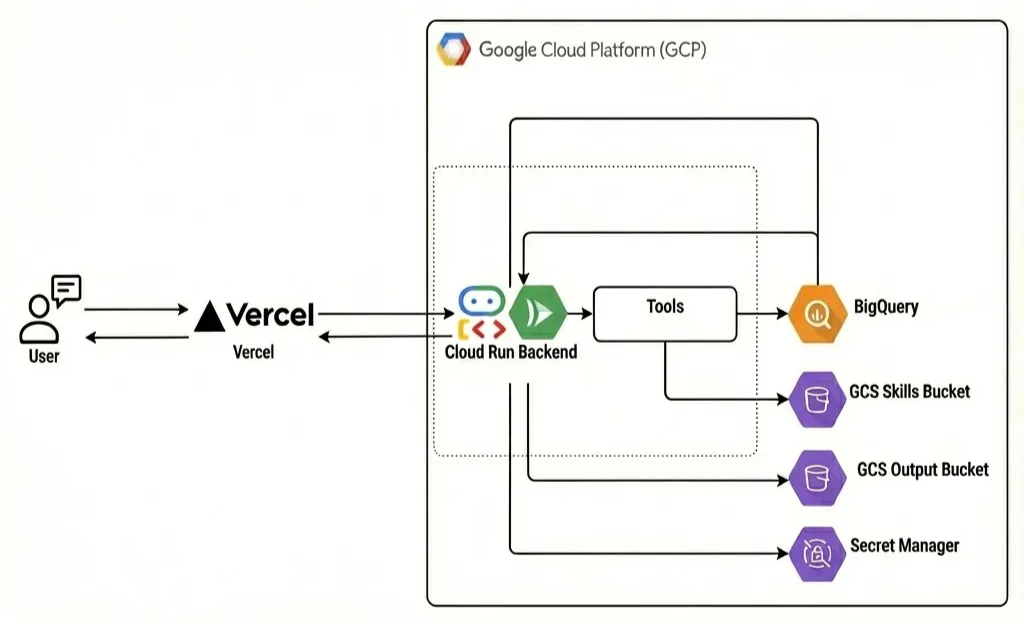
googleの各種リソースを利用するための設定はADKで使えたのでMCP構築は非常に簡単に構築できました。
bigqueryだけでいくと from google.adk.tools.bigqueryのBigQueryToolsetを利用するだけで基本的な動作は実現できました。
最初は下記のような構成を考えていました。
FastAPIの中で別にスキル選択を構築していたんですが、それだとMCPとの連携がうまく行かず、、
┌─────────────────────────────────────────────────────────────────┐
│ Frontend (Next.js) │
└─────────────────────────────┬───────────────────────────────────┘
│ POST /api/chat
▼
┌─────────────────────────────────────────────────────────────────┐
│ Backend (FastAPI) │
│ ┌─────────────────────────────────────────────────────────────┐│
│ │ chat.py (API Router) ││
│ │ 1. ユーザーメッセージを受信 ││
│ │ 2. match_skills_with() でスキル選択 (Gemini API) ││
│ │ 3. スキルコンテキストをメッセージに追加 ││
│ │ 4. runner.run_async() でエージェント実行 ││
│ └──────────────────────────┬──────────────────────────────────┘│
│ │ │
│ ┌──────────────────────────▼──────────────────────────────────┐│
│ │ InMemoryRunner (ADK) ││
│ │ - セッション管理 ││
│ │ - エージェントの実行 ││
│ └──────────────────────────┬──────────────────────────────────┘│
│ │ │
│ ┌──────────────────────────▼──────────────────────────────────┐│
│ │ root_agent (ADK Agent) ││
│ │ - model: gemini-2.5-flash ││
│ │ - instruction: base_instruction ││
│ │ - tools: ││
│ │ ├─ BigQuery Toolset (クエリ実行、スキーマ取得) ││
│ │ ├─ Google Search Tool (ウェブ検索) ││
│ │ └─ Visualization Tools (チャート作成) ││
│ └──────────────────────────┬──────────────────────────────────┘│
└─────────────────────────────┼───────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ External Services │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────────────────┐ │
│ │ Gemini API │ │ BigQuery │ │ Google Cloud Storage │ │
│ │ (LLM) │ │ (データ) │ │ (スキル保存) │ │
│ └─────────────┘ └─────────────┘ └─────────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘
こんなイメージで今回は作成しています。
ぶっちゃけこっちの実装の方が私的には楽でした、
┌─────────────────────────────────────────────────────────────────┐
│ Frontend (Next.js) │
│ localhost:3000 │
└─────────────────────────────┬───────────────────────────────────┘
│ POST /api/chat
▼
┌─────────────────────────────────────────────────────────────────┐
│ Backend (FastAPI) │
│ localhost:8000 │
│ ┌─────────────────────────────────────────────────────────────┐│
│ │ chat.py (API Router) ││
│ │ 1. ユーザーメッセージを受信 ││
│ │ 2. match_skills_with() でスキル選択 (Gemini API) ││
│ │ 3. スキルコンテキストをメッセージに追加 ││
│ │ 4. runner.run_async() でエージェント実行 ││
│ └──────────────────────────┬──────────────────────────────────┘│
│ │ │
│ ┌──────────────────────────▼──────────────────────────────────┐│
│ │ InMemoryRunner (ADK) ││
│ │ - セッション管理 ││
│ │ - エージェントの実行 ││
│ └──────────────────────────┬──────────────────────────────────┘│
│ │ │
│ ┌──────────────────────────▼──────────────────────────────────┐│
│ │ root_agent (ADK Agent) ││
│ │ - model: gemini-2.5-flash ││
│ │ - instruction: base_instruction ││
│ │ - tools: ││
│ │ ├─ BigQuery Toolset (クエリ実行、スキーマ取得) ││
│ │ ├─ Google Search Tool (ウェブ検索) ││
│ │ └─ Visualization Tools (チャート作成) ││
│ └──────────────────────────┬──────────────────────────────────┘│
└─────────────────────────────┼───────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ External Services │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────────────────┐ │
│ │ Gemini API │ │ BigQuery │ │ Google Cloud Storage │ │
│ │ (LLM) │ │ (データ) │ │ (スキル保存) │ │
│ └─────────────┘ └─────────────┘ └─────────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘
スキル関連でわたしたtoolsはこんな感じです。
def search_skills(query: str) -> str:
"""
スキルを検索して、関連するスキルの一覧を返します。
タスクを実行する前に、まずこのツールでスキルを検索してください。
スキルにはSQLテンプレートやベストプラクティスが含まれています。
Args:
query: 検索クエリ(例: "キャンペーンROI分析", "リード獲得", "広告効果")
Returns:
マッチしたスキルの一覧(ID、名前、説明)
"""
metadata_list = get_skill_metadata_cached()
if not metadata_list:
return "利用可能なスキルがありません。"
# スキル一覧を作成
skills_info = "\n".join([
f"- {meta.name}: {meta.description}"
for meta in metadata_list
])
# AIを使ってスキルを検索
prompt = f"""あなたはスキル検索アシスタントです。
ユーザーの検索クエリに対して、最も関連性の高いスキルを選択してください。
## 利用可能なスキル一覧:
{skills_info}
## 検索クエリ:
{query}
## 指示:
1. 検索クエリに関連するスキルを最大5個選択してください
2. 関連するスキルがない場合は空の配列を返してください
3. スキル名のみをJSON配列形式で返してください
4. 関連性の高い順に並べてください
## 出力形式(JSON配列のみ、説明不要):
["skill-name-1", "skill-name-2"]
"""
try:
client = genai.Client()
response = client.models.generate_content(
model="<your-favorite-model>",
contents=prompt,
)
# レスポンスからスキル名を抽出
response_text = response.text.strip()
# JSON配列を抽出
json_match = re.search(r'\[.*?\]', response_text, re.DOTALL)
if json_match:
selected_skills = json.loads(json_match.group())
# 有効なスキル名のみをフィルタリング
valid_skill_names = {meta.name for meta in metadata_list}
selected_skills = [s for s in selected_skills if s in valid_skill_names][:5]
else:
selected_skills = []
print(f"[AI Skill Search] Query: '{query}' -> Found: {selected_skills}")
if not selected_skills:
result_lines = [f"「{query}」に関連するスキルが見つかりませんでした。"]
result_lines.append("\n利用可能な全スキル:")
for meta in metadata_list:
result_lines.append(f"- {meta.name}: {meta.description}")
return "\n".join(result_lines)
# 見つかったスキルの情報を返す
result_lines = [f"「{query}」に関連するスキル:"]
for skill_name in selected_skills:
meta = next((m for m in metadata_list if m.name == skill_name), None)
if meta:
result_lines.append(f"- {meta.name}: {meta.description}")
result_lines.append("\n詳細を確認するには load_skill ツールでスキルをロードしてください。")
return "\n".join(result_lines)
except Exception as e:
print(f"[AI Skill Search] Error: {e}")
# フォールバック: 全スキルを表示
result_lines = [f"スキル検索中にエラーが発生しました。利用可能な全スキル:"]
for meta in metadata_list:
result_lines.append(f"- {meta.name}: {meta.description}")
return "\n".join(result_lines)
def load_skill(skill_name: str) -> str:
"""
指定されたスキルの詳細な指示をロードします。
search_skillsで見つけたスキルの詳細を取得するために使用します。
スキルにはSQLクエリテンプレートや実行手順が含まれています。
Args:
skill_name: ロードするスキルの名前(search_skillsで取得した名前)
Returns:
スキルの詳細な指示(SQLテンプレート、パラメータ説明など)
"""
skills = load_skills_by_names([skill_name]) # キャッシュされたスキルがあれば取得
if not skills:
# 利用可能なスキル一覧を提示
metadata_list = get_skill_metadata_cached()
available_names = [meta.name for meta in metadata_list]
return f"スキル '{skill_name}' が見つかりません。利用可能なスキル: {', '.join(available_names)}"
skill = skills[0]
result_lines = [
f"# {skill.name}",
f"**説明**: {skill.description}",
"",
"## 指示",
skill.instructions
]
return "\n".join(result_lines)
def list_all_skills() -> str:
"""
利用可能な全スキルの一覧を表示します。
どのようなスキルが利用可能か確認したい場合に使用します。
Returns:
全スキルの名前と説明のリスト
"""
metadata_list = get_skill_metadata_cached() # キャッシュされたスキルがあれば取得
if not metadata_list:
return "利用可能なスキルがありません。"
result_lines = [f"利用可能なスキル ({len(metadata_list)}件):"]
for meta in metadata_list:
result_lines.append(f"- {meta.name}: {meta.description}")
result_lines.append("\n詳細を確認するには load_skill ツールでスキルをロードしてください。")
return "\n".join(result_lines)
# ADK FunctionTools としてエクスポート
skill_tools = [
FunctionTool(search_skills),
FunctionTool(load_skill),
FunctionTool(list_all_skills),
]
Agent Skillsについて
GCS上に以下の構成でMarkdown/YAML形式の定義を配置し、エージェントが必要に応じて読み込んで実装しました。
基本的な動作はこれだけでもうまく行くと思います。
また、上の記事に記載した通りMCPのtoolの一部としてskills検索などを渡しました。
(baseのプロンプトにこれでスキル使って!と指示、ツールも提供するというスタイル)
MCPを動かす前にskillsを検索 + それを踏まえて実行だとうまいことしてくれなかったので、これがいいのかなと思っている次第です、、(プロンプトの問題もあるかもしれません)
skills/
└── marketing-analysis/
├── SKILL.md # 分析の手順や思考のガイドライン
├── scripts/ # 秘伝のSQLテンプレート
└── assets/ # 参照画像など
開発時に工夫したこと
構築にあたって特に注意したポイントを3つ挙げます。
1. Agent Skillsの利用
前述しましたが、skillsとMCPを併存させるならMCPの一部にskills関連のツールを渡した方がいいかもしれません。
ちなみにskillsはこの辺りを参考にさせていただきました。
https://github.com/gotalab/skillport/tree/main/src/skillport_cli
https://github.com/agentskills/agentskills/tree/main/skills-ref
2. bigqueryで必要なテーブルが調べられない
これは初期導入の企業やチームはほぼ必ず当たる問題かなと思います。
結局どのテーブルを参照すればいいのかがわからないので、会話にならない問題ですが、
こちらは専用のskillを作成して解決しました。
他にもセマンティックレイヤーの導入やOBTの作成などで一定解決できそうかと思います。
3. キャッシュの利用
Agent SkillsはGCSにあるため、毎度Skillsの検索を行うと、パフォーマンスに影響すると考え、キャッシュを利用するようにしました。
基本的にはskillsのリストはキャッシュに格納、一定時間がたてばキャッシュをクリアして再度リスト取得するようにしました。
まとめ
企業のデータ活用において、「データはBigQueryにあるが、活用ノウハウは人の頭の中にある」という状況は多いはずです。その橋渡しを「Skill」という形式で実装し、エージェントに道具として持たせる手法は、実務において非常に強力な武器になると確信しています。
今後もアップデートがあれば共有していきます!