はじめに
データ活用を推進する中で、これらのような課題は出てきませんか?
- 「似たようなデータが多すぎてどれを使えばいいかわからない」
- 「データの数字がツールによって違う」
- 「メンテナンスが属人化してしまって、ナレッジ共有が進まない」
弊社ではこれらの課題を解決してデータ活用/AI活用をより円滑に進めるために社内のDWHルールを作成しました。
本記事では、"何を決めていると便利か"についてと、"弊社の事例"として作成したものの一部を紹介しようと思います。
見てほしい人
この記事はデータ基盤を作り上げようとしている初期の方に見てほしいです。
あまりデータ基盤ルールについて書かれている記事はなかったので
この記事によって少しでも誰かの手助けになれば幸いです。
初期に決めておくべき事項
データの全体像
全体アーキテクチャは今後の指針となるものです。
これがない状態で運用を続けると歪なDWHができてしまうのでご注意ください
命名ルール
初期に命名ルールは決めておきましょう。
今後の変更時のコストがとんでもないことになるので早めにルール化しておくのが吉です。
descriptionの記載
こちらもテーブルが大きくなってしまってからだと記入コストが大きくなります。
また、退職者が作成した通称"パンドラのテーブル"が作成される原因になるのでお気をつけください。
弊社のルール紹介
弊社が作成したものの一部として記載しています。
最初は正直ここまで決められれば十分かなと個人的に思っている次第です。
現状の課題
弊社ではBigQueryを採用しており、下記の問題が発生していました。
ただ、細かな課題やよくしたい箇所が多かったので優先度的に高い(=放っておくと今後の技術負債になりやすいもの)をピックアップしています。
類似の定義のデータが複数存在する
それぞれのプロジェクトで必要な範囲のデータを作成し参照する際に、他のプロジェクトと似たような定義のデータを抽出してしまい、知らないうちにデータの重複が発生。冗長なデータが増えることで、コストの負担増や管理の複雑化を招いていました。
データオーナー(責任者)が分からない
データを作成した担当や関係者を記録しておらず、時間が経過すると誰がデータを管理しているのか分からなくなり、メンテナンスが不可能な「野良データ」が発生していました。
利用用途が分からない
利用経緯が不明なため、今も使っているのか判断できず、不要なデータを消せないという問題がありました。
全体アーキテクチャ
データを整理整頓するために、以下の図のような「レイヤー(層)」に分けて管理することにしました。
(メダリオンアーキテクチャというものを採用していますが、弊社ではデータソース、データウェアハウス、データマートの区分の方が想像つきやすいみたいでリネームしています。)
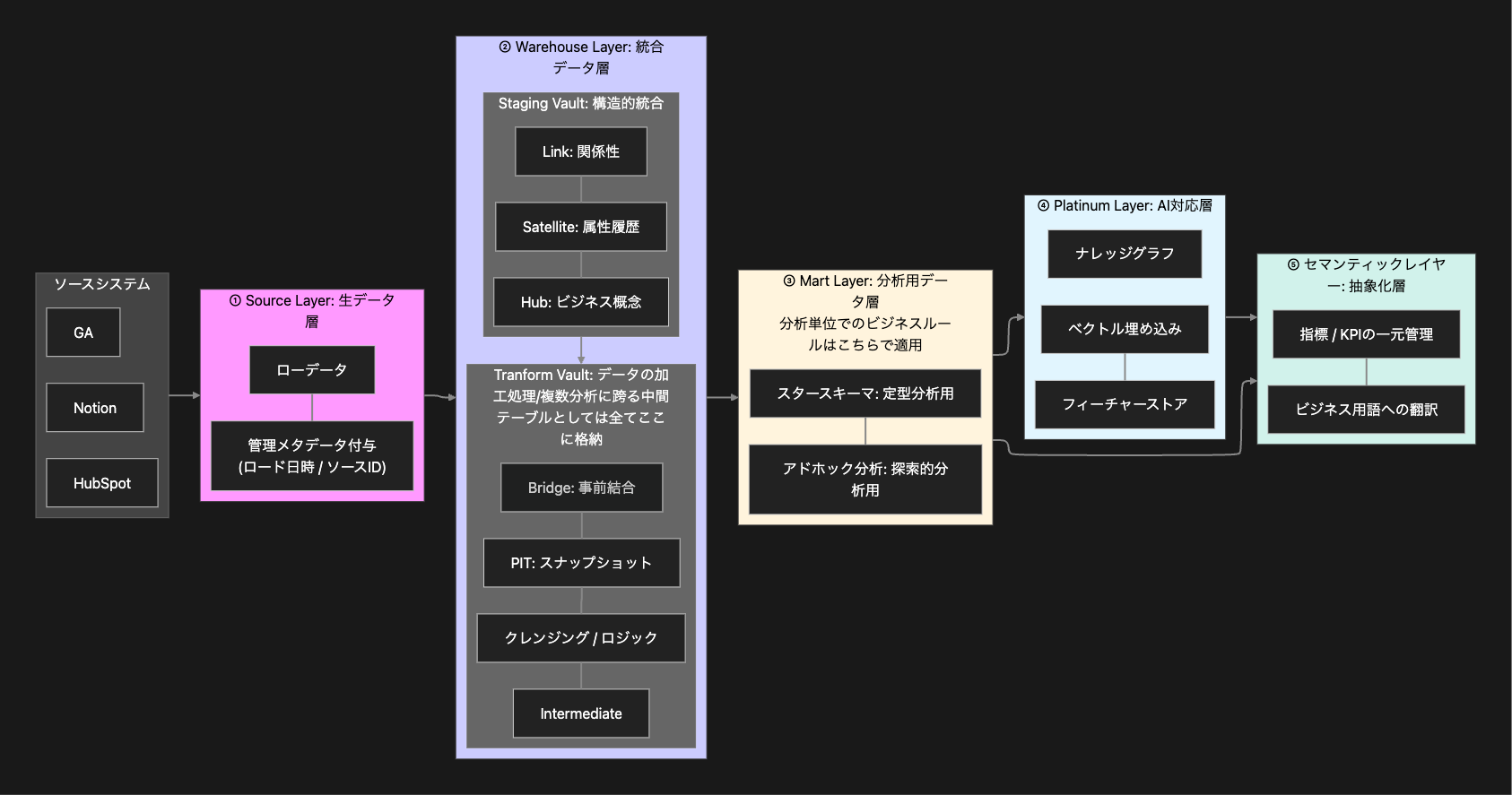
① Source Layer(生データ層)
役割: 元データを「そのまま」保存する場所です。
価値: データの欠損を防ぎ、いつでも元の状態を確認できます。
② Warehouse Layer(統合データ層)
役割: データを共通ルールで整理し、加工する場所です。
価値: システムをまたいで「同じ顧客」を特定し、計算ロジックを1カ所に集約します。
③ Mart Layer(分析用データ層)
役割: ユーザーが使う「完成品」のデータです。
価値: レポート作成や分析が、速く・簡単に・正確に行えます。
④ Platinum Layer(AI対応層)
役割: AIや機械学習に特化したデータ形式です。
価値: 高度な予測分析や、生成AI(LLM)への活用を支えます。
⑤ Semantic Layer(抽象化層)
役割: 全社共通の「データの辞書」です。
価値: 全員が同じ定義で数字を見ることができ、解釈のズレをなくします。
作成したルールのポイント
こちらの全体アーキテクチャを基にいくつかルールを作成しました。
1. データセット単位での権限制御(メダリオンアーキテクチャ)
生データ(Source)や中間データ(Warehouse)をデータセットレベルで物理的に分離しました。
BigQueryの特性を活かし、「一般のアナリストには分析用のMart層だけを見せる」といった制御を行います。これにより、権限管理の煩雑さを解決します。
2. 接頭辞(Prefix)による「データの身分証明」
データセット名には必ずsource_ whse_ mart_ といった接頭辞を付けることにしました。
これにより、SQLを書く人だけでなく、BIツールを使う人も「今見ているのは信頼できる完成品(mart)なのか」を即座に判断できます。
3. 「ゴミ」を溜めない仕組み(有効期限の設定)
探索的な調査で作った一時的なテーブル(アドホック分析)には、「6ヶ月」という有効期限を設けました。
「とりあえず作ったデータ」が永続的に残ってコストを食い潰したり、検索の邪魔になったりするのを防ぎます。
4. BigQueryの説明欄(Description)への記載徹底
「カラムの意味がわからない」という問い合わせをゼロにするため、テーブル作成時に説明を付与することをルール化しました。
ここに「管理者(オーナー)」の情報も記載することで、不具合時の連絡先も明確にしています。
5. 小文字スネークケースの統一
BigQueryでは大文字と小文字が区別されません。
プログラムによって書き方がバラバラだと混乱を招くため、user_id のような小文字・アンダースコア繋ぎに統一し、誰もが読みやすいコードを目指しています。
セキュリティについて
私たちは皆さんの大切なデータを扱うため、個人情報(PII)の定義を明確にし、開発環境ではマスキング(情報を隠す処理)を徹底するルールも定めています 。
おわりに
最後になりますが、こちらのルールは普遍的なものではなく、会社の成長に合わせてスクラップアンドビルドが繰り返して行くものになります。
初期で決めたものに固執しすぎないということも大事なので、こちらをご承知おきいただけると幸いです。
また、こちらのルールを今度は"運用に乗せられるか"が非常に重要な鍵となります。
この辺りは別記事にて取り組んだ内容等をお知らせできればと思っていますので、
お待ちくださいませ。
ルールというのは、単にエンジニアが作業をしやすくするためのものではありません。
「正しいデータに基づいた意思決定を、誰もが素早く行える環境」を作るための土台です。
今後もこのルールをアップデートしながら、より使いやすいデータ基盤を目指していきます。