この記事はHoudini Advent Calender 2023の23日目の記事です。
初めに
Houdiniを使用しているとキャッシュやら何やらで頻繁に使用するbgeo(とbgeo.sc)。面倒だから他のアプリケーションでもこれで出力してほしい、というわけで調べた内容をまとめています。
Houdiniを普通に使う分には必要のない知識です。Houdini EngineやHoudini Pythonやらを使用してbgeoファイルを扱う方がより簡単で安全です。
bgeoフォーマットの説明はHDKのドキュメントにあります。このドキュメントからHoudiniのPythonのコードやらC++のヘッダーを見ていけばより詳細な情報が追えると思います。
geoファイルについて
bgeoファイルを扱う前にgeoファイルから見ていきます。簡単に違いをまとめると
| 拡張子 | |
|---|---|
| geo | テキストのJSON形式。人間が読みやすい。 |
| bgeo | バイナリのJSON形式。プログラムで読みやすい。 |
JSON自体は多くのプログラミング言語でライブラリがあるので他のアプリケーションとデータをやり取りするという目的を果たすためならばgeoファイルで事足りると思います。
簡単なサンプルとしてボックスをgeoファイルで出力して中身を見ていきます。
[
"fileversion","20.0.547",
"hasindex",false,
"pointcount",8,
"vertexcount",24,
"primitivecount",6,
"info",{
"date":"2023-12-10 14:40:54",
"timetocook":0,
"software":"Houdini 20.0.547",
"artist":"towazumi",
"hostname":"DESKTOP-G4FAU66",
"time":0,
"bounds":[-0.5,0.5,-0.5,0.5,-0.5,0.5],
"primcount_summary":" 6 Polygons\n",
"attribute_summary":" 1 point attributes:\tP\n"
},
"topology",[
"pointref",[
"indices",[0,1,3,2,4,5,7,6,6,7,2,3,5,4,1,0,5,0,2,7,1,4,6,3]
]
],
"attributes",[
"pointattributes",[
[
[
"scope","public",
"type","numeric",
"name","P",
"options",{
"type":{
"type":"string",
"value":"point"
}
}
],
[
"size",3,
"storage","fpreal32",
"defaults",[
"size",1,
"storage","fpreal64",
"values",[0]
],
"values",[
"size",3,
"storage","fpreal32",
"tuples",[[0.5,-0.5,0.5],[-0.5,-0.5,0.5],[0.5,0.5,0.5],[-0.5,0.5,0.5],[-0.5,-0.5,-0.5],[0.5,-0.5,-0.5],[-0.5,0.5,-0.5],[0.5,0.5,-0.5]
]
]
]
]
]
],
"primitives",[
[
[
"type","Polygon_run"
],
[
"startvertex",0,
"nprimitives",6,
"nvertices_rle",[4,6]
]
]
]
]
Houdiniが出力する時点ですでに読みやすく整形されていてGeometry Spreadsheetと見比べながら情報を追っていけば理解しやすいと思います。
geoファイル形式で気を付けるところとしてはよくある辞書の形式ではなく配列で情報を持っている箇所が多いという部分です。なのでプログラムで扱う際は配列から2つずつ値を取り出して処理していくことが多いです。
{
"キー1" : "値1",
"キー2" : "値2"
}
[
"キー1", "値1",
"キー2", "値2"
]
また似たような構造としてアトリビュート情報は配列形式で最初にアトリビュートの定義が来て値が続いています。
[
[
"scope","public",
"type","numeric",
"name","P",
"options",{
"type":{
"type":"string",
"value":"point"
}
}
],
[
"size",3,
"storage","fpreal32",
"defaults",[
"size",1,
"storage","fpreal64",
"values",[0]
],
"values",[
"size",3,
"storage","fpreal32",
"tuples",[...]
]
]
]
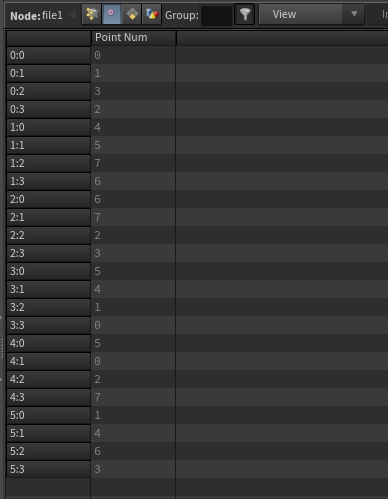
topology/pointref/indicesについて
頂点とポイントの対応リストになっています。Geometry SpreadsheetのVerticesのPoint Numに相当します。
nvertices_rleについて
こちらも2つで1セットのパラメータです。ますプリミティブを構成する頂点数が入り、その後にそれが何回続くかが入ります。
[
...,
"nvertices_rle",[4,6]
]
この場合だと四角ポリゴンが6つあるという情報になります。これに三角ポリゴンを1つ追加すると
[
...,
"nvertices_rle",[4,6,3,1]
]
のようになります。
bgeoファイルについて
前述した通りbgeoはgeoをバイナリフォーマットに変換したものです。
詳しい情報はUT_JsonDefines.hというヘッダーファイルに記述されているので、このコメントを読むと大体分かると思います。
なのでここでは簡易的な説明にしておこうと思います。
ヘッダー部分
UT_JID_MAGIC(0x7f)
先頭の1byte目はUT_JID_MAGIC(0x7f)が来ます。
UT_JID_BINARY_MAGIC(0x624a534e) / UT_JID_BINARY_MAGIC_SWAP(0x4e534a62)
次の4byteでこの2つのどちらかが来ます。ほとんどのPCがリトルエンディアンの環境だと思うのでJID_BinaryMagicSwapが来ることはほとんどないかと思います。
JID_BinaryMagicSwapが来た場合はデータを読み込んだ際にエンディアン変換を挟んでいく必要があります。
データ部分
ヘッダーを読み込んで問題なければデータ部分が続きます。
基本的には1byte読み込んでUT_JsonDefines.hで定義されているenumのどれか判断して必要に応じてデータを読み込むを繰り返す形です。
例えばJID_Real32が来た場合は4byte読み込み、また次のenumの1byteを読みというような感じです。
ARRAY_BEGIN, MAP_BEGINは対応するENDが来るまで中身のデータが続いていく形です。
UT_JID_ARRAY_BEGIN(0x5b) / UT_JID_ARRAY_END(0x5d)
配列の [ と ] です。テキストデータの [ と ] そのままなのでテキストエディタで開いても確認できます。
UT_JID_MAP_BEGIN(0x7b) / UT_JID_MAP_END (0x7d)
配列の { と } です。テキストデータの { と } そのままなのでテキストエディタで開いても確認できます。
特殊なルールあるデータ
長さ(サイズ)の読み込み
UT_JID_UNIFORM_ARRAYやUT_JID_STRING, UT_JID_TOKENDEFなどデータの長さが必要なパラメータがあります。その際に長さ部分で何byteのデータが必要なのかを1byte目だけを先に読み込んで判断します。
| 先頭1byte | 説明 |
|---|---|
| 0xf1より小さい | 読み込んだその1byteをそのままサイズとして使用します。 |
| 0xf2 | 続く2byteをunsignedな16bit整数値として使用します。 |
| 0xf4 | 続く4byteをunsignedな32bit整数値として使用します。 |
| 0xf8 | 続く8byteをunsignedな64bit整数値として使用します。 |
UT_JID_TOKENDEF(0x2b) / UT_JID_TOKENREF(0x26)
bgeoデータにはpublicやnameなど何度も登場する文字列があります。そういった文字列はUT_JID_TOKENDEFでIDを登録しておいて、以降はUT_JID_TOKENREFでそのIDを使用して文字列のように使用していきます。

画像はpublicという文字列のTOKENDEFとTOKENREFの部分のバイナリエディタ表示の切り抜きです。
IDは1Aを登録、文字列の長さは6、publicの文字列が続いて登録部分は終了です。
その後にUT_JID_TOKENREFで1Aを指定してpublicの文字列を使用するという扱いにします。
UT_JID_UNIFORM_ARRAYのboolの扱いについて
UT_JID_UNIFORM_ARRAYはreal32(32bitの浮動小数)だったらreal32のデータが連続で並ぶ形式ですがboolだけ特殊な扱いをします。
最小のデータサイズが4byteでそれだけで32個のboolを扱います。数が32を超えて33になったら8byteのデータサイズになります。
アトリビュート情報を読み込む際の特殊な情報
pagesize
アトリビュートのデータはUT_JID_UNIFORM_ARRAYで入ってきますがそのデータはページという単位で区切られています。Houdiniで出力されたbgeoのページサイズは1024がほとんどだと思います。
例えば位置のPのアトリビュートだとx,y,zをセットで1つとして数えて1024個で1ページになります。
constantpageflags
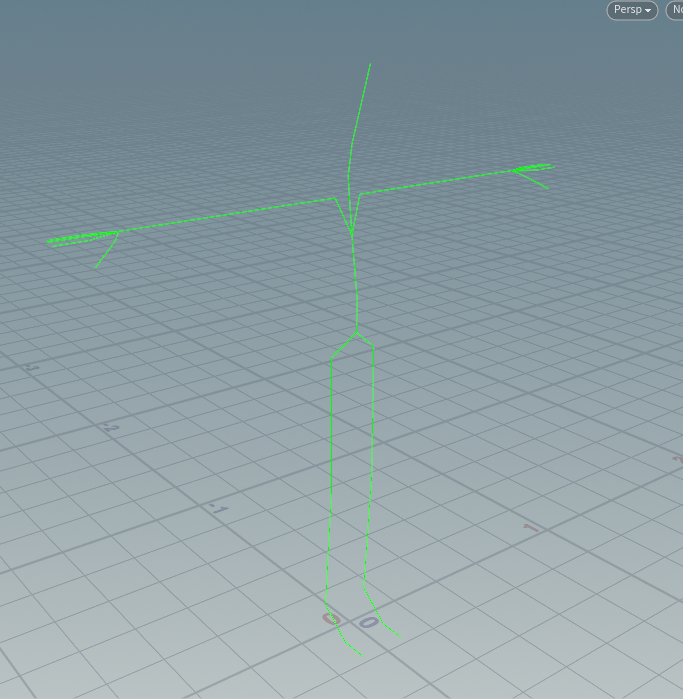
UT_JID_UNIFORM_ARRAYのboolで記録されています。これはどういうデータかというと前述したページで全て同じ値の時にtrueになりデータ1つ分だけしかbgeoデータには入っていないということを表します。
例えば以下のスケルトンは色のアトリビュートがconstantpageflags:[true]として記録されてただ一つだけの色データを持っています。
packing
データの格納順を表しています。スキンメッシュのboneCaptureアトリビュートで使用します。他ではまだ見たことがありませんがデータを見てデータの並び順が思った通りに来ないなと思ったら確認すべき項目です。
bgeo.scファイルについて
bgeoを圧縮したファイルです。c-bloscというライブラリを使用しています。
c-bloscはBlosc/c-bloscから入手出来ますがSideFXのfork版もあります。どちらを使用しても問題なさそうですがSideFXのfork版の方がビルド時間もファイルサイズも小さいのでこちらを使用した方が良さそうです。
bgeo.scはそのままc-bloscで圧縮しているわけではなくファイルの先頭と末尾にそれぞれヘッダー情報とフッター情報がありブロック単位で圧縮されています。
詳細な情報はUT_BloscDecompressionFilter.hを読むと分かると思います。
ここではbgeo.scを読み込んでbgeoを出力するpythonコードを置いておきます。
import os
import ctypes
import struct
directory = os.path.join(os.path.dirname(__file__))
input_sc_file = os.path.join(directory, 'electra_skin.bgeo.sc')
output_bgeo_file = os.path.join(directory, 'electra_skin.bgeo')
blosc_dll_path = os.path.join(directory, 'blosc.dll')
bgeo_data = b''
# bgeo.scファイルの読み込み、展開
with open(input_sc_file, 'rb') as f:
# headerの読み込み(チェックは省略)
header = f.read(4)
metadata = f.read(8)
bgeo_begin = f.tell()
# footerの読み込み(チェックは省略)
f.seek(-4, 2)
footer = f.read(4)
f.seek(-12, 2)
index_length = struct.unpack('>Q', f.read(8))[0]
f.seek(-12-index_length, 2)
bgeo_end = f.tell()
# index情報の読み込み
index_count = (index_length-16)//8
block_indices = list()
for i in range(0, index_count):
index = struct.unpack('>Q', f.read(8))[0]
block_indices.append(index)
block_size = struct.unpack('>Q', f.read(8))[0]
last_block_size = struct.unpack('>Q', f.read(8))[0]
bgeo_file_size = block_size*index_count + last_block_size
# blosc.dllの読み込み
blosc = ctypes.cdll.LoadLibrary(blosc_dll_path)
blosc.blosc_init()
f.seek(bgeo_begin)
for index in block_indices:
read_size = bgeo_begin + index - f.tell()
compressed_data = f.read(read_size)
data = ctypes.create_string_buffer(b'', block_size)
size = blosc.blosc_decompress(compressed_data, data, block_size)
bgeo_data += data
compressed_data = f.read(bgeo_end-f.tell())
data = ctypes.create_string_buffer(b'', last_block_size)
size = blosc.blosc_decompress(compressed_data, data, last_block_size)
bgeo_data += data
# bgeoファイルの出力
with open(output_bgeo_file, 'wb') as f:
f.write(bgeo_data)
まとめ
bgeoファイルの構造について簡単に説明を行いました。bgeoを中心とした独自のワークフローを組んでみたいという方がいれば是非チャレンジしてみてください。
bgeoファイルをバイナリjsonとして読み込む部分はそんなに難しくはないと思います。ただその後に欲しい情報がどういう風に格納されているか調べていくのに苦労するのかなーという印象です。