1.簡単な概要
この記事では都内ラーメン屋の食べログ口コミを使って隠れた名店をレコメンドで発掘するやり方を解説していきます。
私自身🍜が大好きで昔は年間100杯以上食べ歩いてきた自称ラーメンガチ勢です。しかしながら、直近の健康診断にひっかかり、医者からドクターストップをかけられてしまいました。。。
行き場をなくしたラーメン熱を発散すべく**機械学習でラーメンレコメンド(隠れた名店をレコメンドで発掘)**に挑戦してみることにしました。
今回は、集大成として、Word2vecでモデリングしたmodelを使って隠れた名店をガチで発掘し、実際にそのお店に行って確かめるところまでやります!
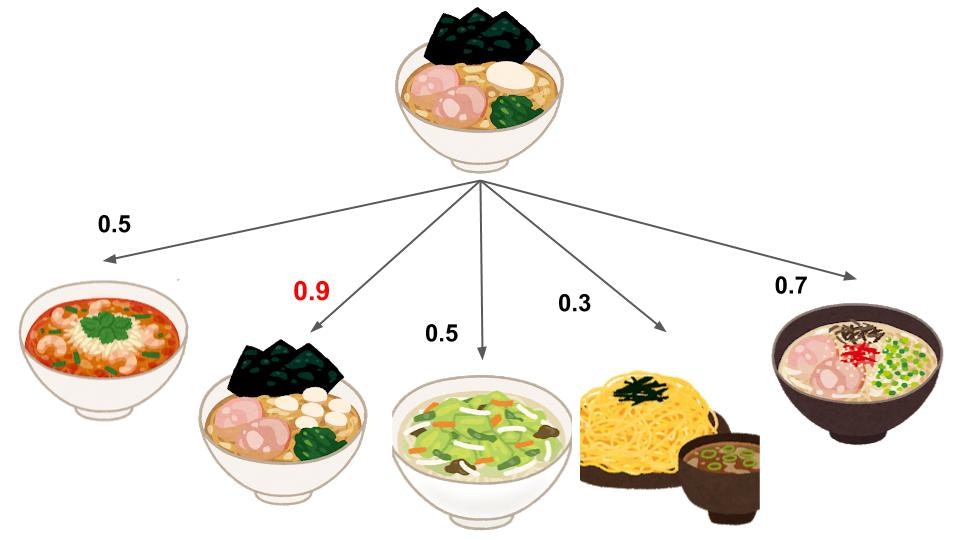
有名店のラーメンに対して類似度が高いラーメン店を探すイメージです。
techgymさんのブログに掲載いただきました!ありがとうございます。
【人工知能の無駄遣い?】AIプログラミングの面白記事をまとめてみました。
2.ラーメンガチ勢の悩み
「美味しい」ラーメン屋の新規開拓に困る
年間100杯以上食べるガチ勢の切実な悩みとして、行列必至の人気店やクチコミで話題のお店など、東京都内で人気のラーメン店は行き尽くしてしまい、「美味しい」ラーメン屋の新規開拓のネタに困るということがあると思います。あるあるですね。
ということで、
「自分の好みのラーメン屋の味に近い、隠れた名店を自力で探そう」
という結論に辿り着きました。
3.隠れた名店を発掘するロジックの流れ
「隠れた名店」の定義
食べログランキング1位のお店の口コミと類似度が高くかつ口コミ件数が少ないお店を「隠れた名店」と定義します。
口コミの類似度が高い ≒ ラーメンの味・クオリティが近しい。
口コミの件数が少ない ≒ 知名度が低い
これにより、食べログランキング1位並みのポテンシャルがあるにも関わらず、知名度が低い、いわゆる「隠れた名店」を探すことができるはず!
ということで、実際にやってみました!
ざっくり、3行でやり方を書くと
①学習データの取得
②word2vecでモデリング
③レコメンドロジック作成
となります。
①学習データの取得
詳しくはこちら↓↓で説明しています。
第1弾:【Python】ラーメンガチ勢によるガチ勢のための食べログスクレイピング
良質な口コミデータを集めるために食べログページをスクレイピングして必要な情報を取得しました。
スクレイピングする際のポイントとしては、
"ラーメン屋でかつ点数が高い名店のみ"
に絞って良質な口コミを取得することです。
スクレイピングで下記の情報はこちら
・店舗名:store_name
・食べログ点数:score
・口コミ件数:review_cnt
・口コミ文章:review
口コミを1件ずつ取得した後に、データフレームにまとめました。
※食べログ規約にもとづき口コミに関する箇所にはモザイクをいれております。ご了承ください。

②word2vecでモデリング
詳しくは、こちら↓↓
第2弾:[【Python】ラーメンガチ勢によるガチ勢のためのWord2vecによる自然言語処理]
(https://qiita.com/toshiyuki_tsutsui/items/19590b464f15f845efcd)
スクレイピングで取得した口コミを学習データとして、word2vecでモデリングすると、「ラーメン」に特化したモデル構築をすることができました。
↓は、個性的なラーメンで知られている**「二郎」**と類似度が高いワードを表示しています。
# モデルのロード
word2vec_ramen_model=word2vec.Word2Vec.load("../model/word2vec_ramen_model.model")
word2vec_ramen_model.most_similar("二郎")
>>>
[('ラーメン二郎', 0.7518627643585205),
('二郎系', 0.7041865587234497),
('インスパイア', 0.6942269802093506),
('上野毛', 0.6394986510276794),
('メグジ', 0.6040332317352295),
('ヤサイ', 0.5899537205696106),
('乳化', 0.5867205858230591),
('直系', 0.5784134268760681),
('英二', 0.5678684711456299),
('一之江', 0.567740261554718)]
見事「二郎」に近い単語が並びました!
解説すると、**「上野毛」はラーメン二郎上野毛店を指し、「メグチ」はラーメン二郎目黒店のことです。「英二」**も二郎系のお店ですね。
モデルができたので最後にレコメンドロジックを作成します。
③レコメンドロジック作成
ざっくり4行でまとめると、
Ⅰ.コーパスの中身をkmeansでクラスタリング
Ⅱ.TF-IDFで文章における特徴的な単語を抽出
Ⅲ.お店間の類似度を計算
Ⅳ."隠れた名店"度をスコア化
となります。
Ⅰ.コーパスの中身をkmeansでクラスタリング
なぜ、kmeansでクラスタリングが必要かというと、口コミには、ラーメンの味だけでなく、様々な口コミが含まれているからです。ラーメンとは関係ないワードを事前に弾くことが目的です。
クラスタリングでワードを絞らずに進めると、例えば「お店の最寄駅が同じ店」が類似度高くなり、上位にレコメンドされてしまいます。
口コミ例
※実験用に作ったオリジナルです。
都営三田線〇〇駅から歩いて5分程、行列が目印となっているからすぐ見つけることができました。水曜日夜の17時50分頃到着で10番目でした。
待つこと20分、満を持して入店。店内はやや暗くて、席は6席くらいですね。
早速券売機で、淡麗中華そば800円・和え玉200円・味玉100円を購入。
これが夜の淡麗ラーメン!これは旨いなぁ煮干しの上品な旨味が恐ろしく旨く、鼻に抜ける香りも素晴らしい。
玉葱が主張しすぎない縁の下の力持ち的な良い仕事してますね。味玉も半熟ではないももの旨い。
豚チャーシュー(角煮)がデカくて柔らかい、旨味が抜群な角煮がこのスープとベストマッチしている。塩分は強くないしエグミが程よく煮干しの旨味溢れたスープと具材どれも素晴らしいバランスで作られているな旨味、コク、余韻どれも素晴らしい。
こんなクオリティの高い煮干しそばはこれからも何度も食べたくなります。
さすが食べログ3.8を超えてるだけありますね。
あと、店主はガタイがとにかくでかくて一見怖面なんですが、とっても丁寧な接客でちょっと意外でした。
↑の口コミをみると、大半はラーメンとは無関係なワードも多く含まれています。
今回の目的は、純粋に「ラーメン」の類似度を測りたかったので、ラーメンに関する言葉だけに絞りたいなと思いました。
そこで、活用したのが "kmeans" です。
from collections import defaultdict
from gensim.models.keyedvectors import KeyedVectors
from sklearn.cluster import KMeans
model = KeyedVectors.load('../model/word2vec_ramen_model.model')
max_vocab = 30000 #40000にしても結果は同じだった
vocab = list(model.wv.vocab.keys())[:max_vocab]
vectors = [model.wv[word] for word in vocab]
n_clusters = 6 #クラスター数はこちらで任意の値を定める
kmeans_model = KMeans(n_clusters=n_clusters, verbose=0, random_state=42, n_jobs=-1)
kmeans_model.fit(vectors)
cluster_labels = kmeans_model.labels_
cluster_to_words = defaultdict(list)
for cluster_id, word in zip(cluster_labels, vocab):
cluster_to_words[cluster_id].append(word)
for words in cluster_to_words.values():
print(words[:20])
↓は口コミの一例ですが、口コミのワードをkmeansで6つに分類すると以下のようにクラスタリングされました。
クラスター別に20個ずつ単語を表示。

強引ですが、各クラスターごとに名前を付けてみました。
def change_dict_key(d, old_key, new_key, default_value=None):
d[new_key] = d.pop(old_key, default_value)
change_dict_key(cluster_to_words, 0, '日付、お店の評価、ネット用語に関するワード')
change_dict_key(cluster_to_words, 1, '人や接客、内装に関するワード')
change_dict_key(cluster_to_words, 2, 'その他のワード')
change_dict_key(cluster_to_words, 3, '券売機や注文に関するワード')
change_dict_key(cluster_to_words, 4, '曜日時間、店舗の地理的なワード')
change_dict_key(cluster_to_words, 5, 'ラーメンの中身に関するワード')
df_dict = pd.DataFrame.from_dict(cluster_to_words, orient="index").T
df_dict.ix[:,[5,3,1,4,0,2]]
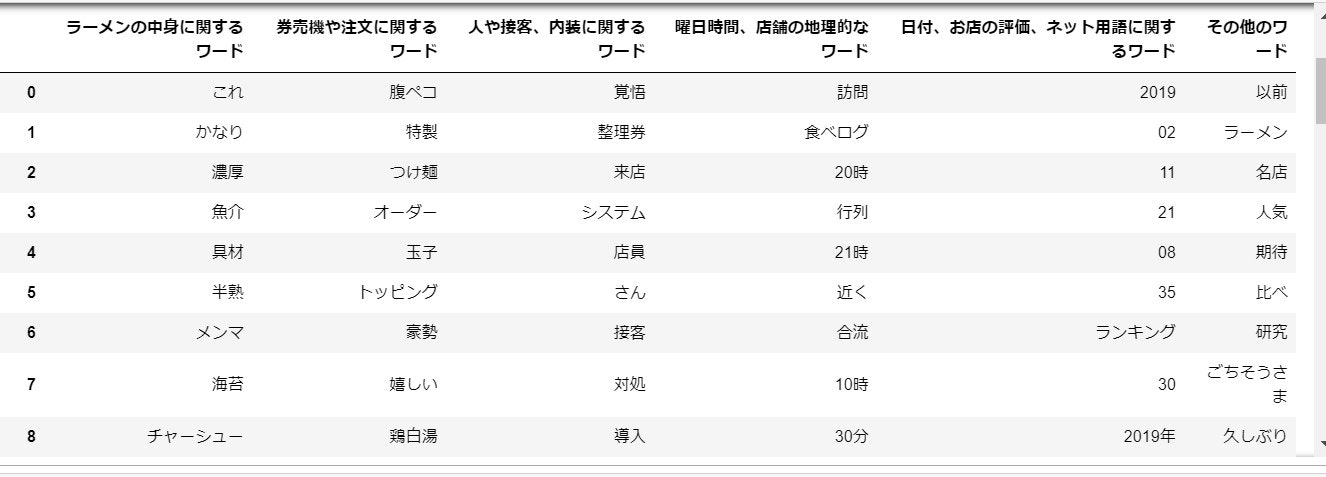
①ラーメンの中身に関するワード
②券売機や注文に関するワード
③人や接客、内装に関するワード
④曜日時間、店舗の地理的なワード
⑤日付、お店の評価、ネット用語に関するワード
⑥その他のワード
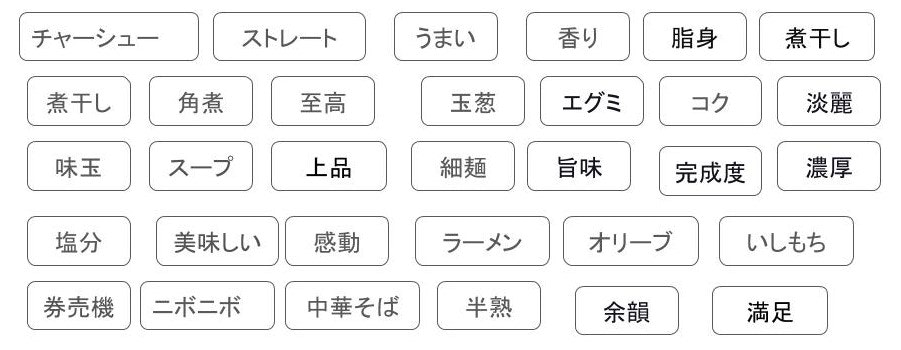
試行錯誤した結果、
①ラーメンの中身に関するワード
③券売機や注文に関するワード
だけにワードを絞ると、レコメンドの結果が最もよくなりました。
先ほどの口コミを絞った結果がこちら。
Ⅱ.TF-IDFで文章における特徴的な単語を抽出
口コミから①でラーメンに関するワードに絞り、その中でTF-IDF値の高いワードを抽出します。
# 参考 https://qiita.com/tatsuya-miyamoto/items/f1539d86ad4980624111
from gensim import corpora
from gensim import models
taste_words = cluster_to_words['ラーメンの中身に関するワード']
kenbaiki_words = cluster_to_words['券売機や注文に関するワード']
taste_words.extend(kenbaiki_words)
ramen_word = taste_words
cluster_to_words.keys()
# 文書
f = open('../work/ramen_corpus.txt','r',encoding="utf-8")
trainings = []
for i,data in enumerate(f):
word = data.replace("'",'').replace('[','').replace(']','').replace(' ','').replace('\n','').split(",")
trainings.append([i for i in word if i in ramen_word])
# 単語->id変換の辞書作成
dictionary = corpora.Dictionary(trainings)
# textsをcorpus化
corpus = list(map(dictionary.doc2bow,trainings))
# tfidf modelの生成
test_model = models.TfidfModel(corpus)
# corpusへのモデル適用
corpus_tfidf = test_model[corpus]
# id->単語へ変換
texts_tfidf = [] # id -> 単語表示に変えた文書ごとのTF-IDF
for doc in corpus_tfidf:
text_tfidf = []
for word in doc:
text_tfidf.append([dictionary[word[0]],word[1]])
texts_tfidf.append(text_tfidf)
from operator import itemgetter
texts_tfidf_sorted_top20 = []
# TF-IDF値を高い順に並び替え上位単語20個に絞る。
for i in range(len(texts_tfidf)):
soted = sorted(texts_tfidf[i], key=itemgetter(1),reverse=True)
soted_top20 = soted[:20]
word_list = []
for k in range(len(soted_top20)):
word = soted_top20[k][0]
word_list.append(word)
texts_tfidf_sorted_top20.append(word_list)
# 結果をデータフレームに追加
df = pd.read_csv('../output/tokyo_ramen_review.csv')
df_ramen = df.groupby(['store_name','score','review_cnt'])['review'].apply(list).apply(' '.join).reset_index().sort_values('score', ascending=False)
df_ramen['texts_tfidf_sorted_top20'] = texts_tfidf_sorted_top20
df_ramen['id'] = ['ID-' + str(i + 1).zfill(6) for i in range(len(df_ramen.index))]
df_ramen_texts_tfidf_sorted_top20 = df_ramen.iloc[:,[5,0,1,2,4]].reset_index(drop=True)
df_ramen_texts_tfidf_sorted_top20
pickle.dump(df_ramen_texts_tfidf_sorted_top20, open('../work/df_ramen_texts_tfidf_sorted_top20', 'wb'))
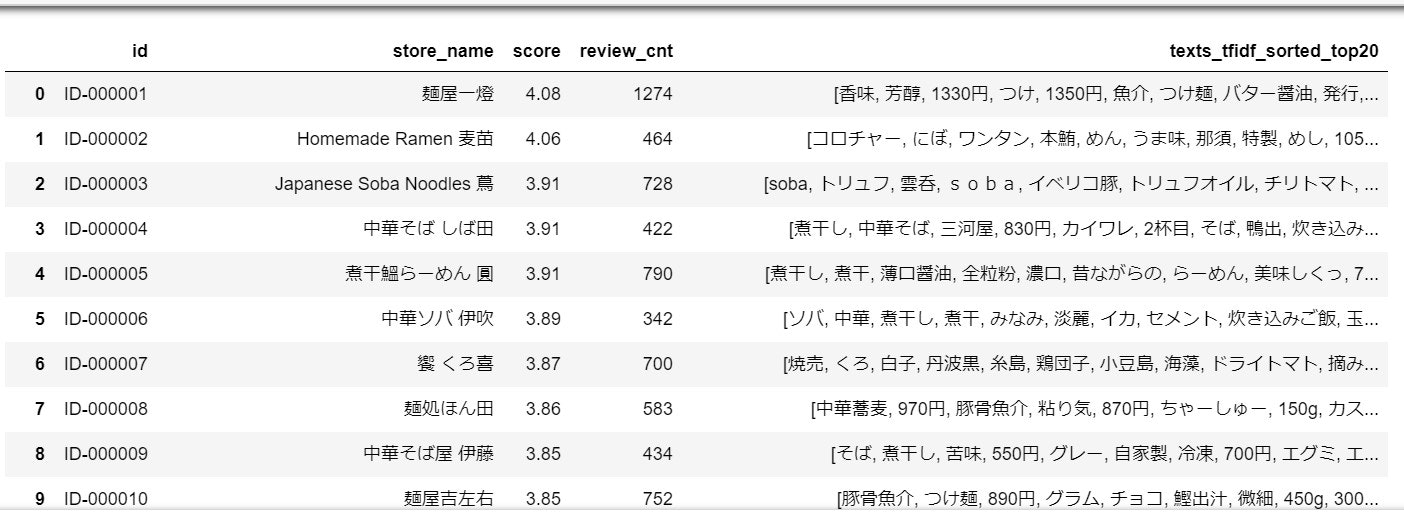
これでラーメン店Xの口コミの特徴を表している単語の抽出することができました。

※画像では7単語ですが、実際は20単語でやっています。
Ⅲ.お店間の類似度を計算
口コミの特徴を表している単語の抽出に成功しましたので、次に単語間類似度を総当たりで計算し、平均をとります。例として、煮干し系のラーメン店2店の類似度を計算してみます。
 ※画像では7単語ですが、実際は20単語でやっています。
※画像では7単語ですが、実際は20単語でやっています。
↑の計算を「煮干し」→「角煮」・・・「淡麗」まですべてに対して行います。
単語数分の類似度が出たところで、さらに平均を取ります。
この作業をスクレイピングで取得した店すべて総当たりで計算し、類似度が高い順に並び替えます。
from itertools import product
f = open('../work/df_ramen_texts_tfidf_sorted_top20','rb')
store_df = pickle.load(f)
store_cross = []
for ids in product(store_df['id'], repeat=2):
store_cross.append(ids)
store_cross_df = pd.DataFrame(store_cross, columns=['id_x', 'id_y'])
store_cross_detail = store_cross_df.merge(
store_df[['id','store_name','score','review_cnt','texts_tfidf_sorted_top20']], how='inner', left_on='id_x', right_on='id'
).drop(columns='id').merge(
store_df[['id','store_name','score','review_cnt','texts_tfidf_sorted_top20']], how='inner', left_on='id_y', right_on='id'
).drop(columns='id')
store_cross_detail = store_cross_detail[store_cross_detail['id_x'].isin(store_df['id'].loc[0:50])]
store_cross_detail = store_cross_detail.reset_index(drop=True).sort_values(['id_x'])
ラーメン店xとラーメン店yの類似度を算出
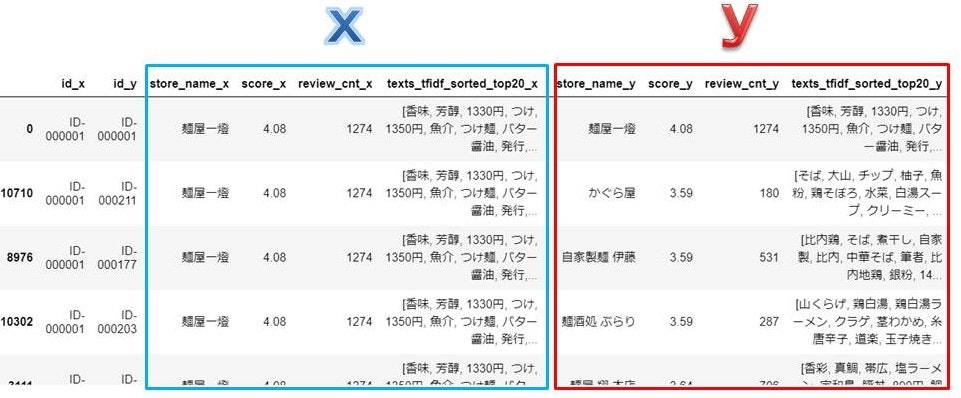
## ラーメン店xに対してラーメン店yの類似度を算出
import itertools
from tqdm import tqdm
# コサイン類似度を算出する関数を定義
def cos_sim(v1, v2):
return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2))
# cossimだけの組み合わせ(同じワード同士の組みあわせがでてくるため)
# 2次元を1次元にする setが重複を削除てきなやつ。
uniq_words = list(set(itertools.chain.from_iterable(store_df['texts_tfidf_sorted_top20'].values)))
scores = {}
for word1, word2 in product(uniq_words, repeat=2):
scores[(word1, word2)] = cos_sim(word2vec_ramen_model.wv[word1],word2vec_ramen_model.wv[word2])
avg_avg_scores = []
for i in tqdm(range(len(store_cross_detail['texts_tfidf_sorted_top20_x']))):
avg_scores = []
for j in range(len(store_cross_detail['texts_tfidf_sorted_top20_x'][i])):
word_cross_scores = []
word_a = store_cross_detail['texts_tfidf_sorted_top20_x'][i][j]
for k in range(len(store_cross_detail['texts_tfidf_sorted_top20_y'][i])):
word_b = store_cross_detail['texts_tfidf_sorted_top20_y'][i][k]
score = scores[(word_a, word_b)]#単語間のスコアを出す。
word_cross_scores.append(score)
avg_scores.append(np.mean(word_cross_scores))#20個の単語間スコアの平均値
avg_avg_scores.append(np.mean(avg_scores))#20個の単語間スコアの平均値の平均値
store_cross_detail.insert(6, 'avg_cos_sim_rate', avg_avg_scores)
# 「二郎」と類似度が高いラーメン屋を高い順に表示
store_cross_detail = store_cross_detail.sort_values(['id_x', 'avg_cos_sim_rate'], ascending=[True, False])
df_sim_x = store_cross_detail[store_cross_detail['store_name_x'].str.contains('二郎')]
df_sim_x.reset_index(drop=True)
def min_max(x, axis=None):
min = x.min(axis=axis, keepdims=True)
max = x.max(axis=axis, keepdims=True)
result = (x-min)/(max-min)
return result
b = df_sim_x['avg_cos_sim_rate']
c = min_max(b.values)
df_sim_x.insert(7, '正規化', c)
df_sim_x
ラーメン二郎ひばりヶ丘駅前店と類似度が高いお店(高い順)

**ラーメン二郎ひばりヶ丘駅前店(x)**に類似度が高いラーメン屋(y)は、
1位:"ラーメン二郎 ひばりヶ丘駅前店"
2位:"らーめん 陸"
3位:"ラーメン二郎 品川店"
4位:"ラーメン富士丸 明治通り都電梶原店"
5位:"ラーメン二郎 桜台駅前店"
という結果でした。
1位は**"ラーメン二郎 ひばりヶ丘駅前店"**になるのは口コミが同じだからです。
2位、3位のお店と写真で比較してみます。
二郎 ひばりヶ丘駅前店 らーめん 陸 二郎 品川店



写真からでも類似度の高さがわかりますね。
mikoさんからありがたいコメントをいただきました!
二郎は乳化と非乳化のスープに分類できるんですけど、投入したひばりヶ丘二郎は乳化だったはずで、出力された品川とか桜台も乳化なので上手くいってるなあと思いました!
Ⅳ.隠れた名店を発掘せよ<"隠れた名店"度をスコア化>
いよいよ、具体的に"隠れた名店"を発掘する作業をするために、名店度を数値を付けてスコア化しました。今回は世界初のミシュラン1ツ星ラーメンである「蔦」@巣鴨駅に対して類似度が高い&隠れているお店を探します。
「蔦」をご存知でない非ガチ勢の方は是非↓の記事で予習してください!
https://icotto.jp/presses/1708
store_cross_detail = store_cross_detail.sort_values(['id_x', 'avg_cos_sim_rate'], ascending=[True, False])
df_sim_x = store_cross_detail[store_cross_detail['store_name_x'].str.contains('蔦')]
df_sim_x.reset_index(drop=True)
def min_max(x, axis=None):
min = x.min(axis=axis, keepdims=True)
max = x.max(axis=axis, keepdims=True)
result = (x-min)/(max-min)
return result
b = df_sim_x['avg_cos_sim_rate']
c = min_max(b.values)
df_sim_x.insert(7, '正規化', c)
d = df_sim_x['review_cnt_y']
e = 1-min_max(d.values)
df_sim_x.insert(11, 'レビュー数_正規化', e)
f = df_sim_x['正規化']*(df_sim_x['レビュー数_正規化'])
df_sim_x.insert(9, '隠れた名店_score', f)
df_kakureta_meiten = df_sim_x.sort_values('隠れた名店_score', ascending=False)
df_kakureta_meiten[df_kakureta_meiten['review_cnt_y'] < 100]
隠れた名店度をスコア化するために、レビュー数が少ないお店が1、多いお店が0に近づくように正規化しました。
すると、
類似度を正規化したスコア × レビュー数を正規化したスコア = 隠れた名店度
このようにして隠れた名店度を数値で表します。
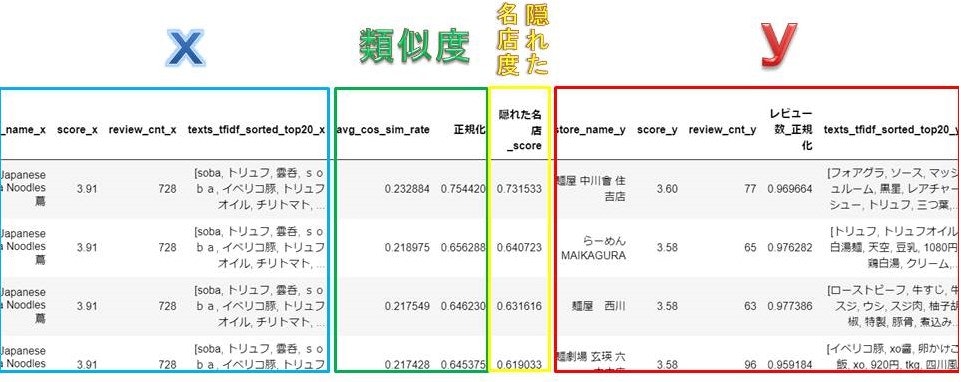
世界初のミシュラン1ツ星ラーメン**「蔦」**対してに類似度が高いが、レビュー数が少ない、隠れた名店は、
1位:"麺屋 中川會 住吉店" 73.1ポイント
2位:"らーめん MAIKAGURA" 64.1ポイント
3位:"麵屋 西川" 63.2ポイント
蔦

麺屋 中川會 住吉店 MAIKAGURA 麵屋 西川



1位は「麺屋 中川會 住吉店」という結果となりました!
上位3店は、どれも淡麗系で写真からも似ていることがわかります。
4.隠れた名店に行ってみた!
本当に隠れた名店かどうかを確かめるために実際に行ってみました。
錦糸町駅から歩いて7分。お昼の時間帯でしたが、並ぶことなく入店できました。

扉に「醤油ラーメンがおすすめです」と書いてあったので、素直に「特製醤油ラーメン」1,100円を注文。暫くしてラーメンが着丼。見た目からして、クオリティの高い淡麗系。これは期待せずにはいられません。では早速一口。んんん!口の中に醤油のまろやかさとフォアグラのうま味広がる絶妙なスープ。う、うまい! 間違いなく美味しいラーメンでした。大満足です。

店内を見渡すと芸能人やラーメン評論家のサインがずらり。
テレビにも紹介されているそうで、有名なお店だったということを後から知りました。
食べログのレビューが少なかったのは、リニューアルオープンしてから2年しか経っていないことが原因だったようです。
知っている人からすると「隠れた名店」というのは大袈裟かもしれませんが、レベルが高いラーメンを並ばずに食べられる穴場的な存在であることには間違いないと思います。
麺屋 中川會 住吉店:https://tabelog.com/tokyo/A1312/A131201/13205611/
ラーメンコラム:https://www.syokuraku-web.com/column/3161/
5.課題
今回ご紹介した「麺屋 中川會 住吉店」は、私的にも「蔦」と類似度が高いラーメン屋といえると思いますが、すべての結果を細かく見ていくと結果が微妙だったお店もありました。
例えば、TF-IDFでトッピングが特徴的な単語として抽出されてしまうと、スープの種類が違うラーメン屋同士が類似度が高くなるという現象が起こります。また、一つのお店で、種類の違うラーメンを提供していて口コミも均衡していた場合、例えば、塩ラーメン、醤油ラーメン、味噌ラーメンどれもクオリティが高いお店です。TF-IDFで抽出した単語に、「濃厚・淡麗・塩・味噌・醤油」のように矛盾したワードが並んでしまう可能性があります。
このあたりの問題点をどのように解消するかが今後の課題です。
6.まとめ
ドクターストップが掛かっていて医者からラーメンを控えるよういわれていましたが、今回ばかりは我慢できず食べてしまいました。。。
今回は「隠れた名店を発掘」という目的で機械学習にチャレンジしましたが、課題はあるものの概ね当初の目的は達成することができたのかなと思います。
隠れた名店として発掘できました「麺屋 中川會 住吉店」は、私の生活圏外ということもあり、今回の企画がなければ、きっと一生食べることはなかったラーメン屋です。
私にとって、ここまで辿り着く道のりは想定以上にハードだったこともあり、自力で見つけた「隠れた名店」は思い出に残る"一杯"となりました。
次回は、番外編として、可愛い店員さんがいるラーメン店を食べログ口コミから自然言語処理で抽出してみたにチャレンジする予定です。