1.簡単な概要
この記事では都内ラーメン屋の食べログ口コミを自然言語処理して、「可愛い店員さんがいるラーメン店」を探す方法について解説していきます。
先日、食べログの口コミを読んでいる中で、**「美人すぎるラーメン店主」**という世の男性なら思わず「なぬ!」と立ち止まってしまうワードを見つけたので、ガチで調べてみたら面白そうだなと思いやってみました。
まずは、口コミデータの取得から。
2.口コミデータの取得
詳しくはこちら↓↓で説明しています。
第1弾:【Python】ラーメンガチ勢によるガチ勢のための食べログスクレイピング
口コミを1件ずつ取得した後に、データフレームにまとめました。
※食べログ規約にもとづき口コミに関する箇所にはモザイクをいれております。ご了承ください。

3.可愛い店員さんがいるお店の定義
可愛い店員さんをどのようにして探すかが一番のポイントですが、
まずは、文章の中で**「可愛い」**が含まれる口コミを抽出してみました。
・真ん中のナルトが可愛い。
・小さく可愛い券売機で塩ラーメン(味玉のせ)(890円)を購入です
・感じ良い可愛い店員さんに数種類の具材の中からトッピングを口頭で3種類選び伝えました。
・提供された容器はかなり小さくて可愛い。
なるほど、口コミに「可愛い」が含まれてるからといって必ずしも可愛い店員さんを示しているわけではなさそうです。
上の文章において「可愛い」に係り受けしている単語が、
「ナルト、券売機、店員、容器」
となっていますので、自動的に**「店員」**だけに絞りたいですね。
係り受けを調べたいのでCaboCha(南瓜)を使います。
4.CaboCha(南瓜)
CaboCha は, SVM(Support Vector Machines) に基づく日本語係り受け解析器です。
係り受け解析とは?
文節間の「修飾する(係る)」「修飾される(受ける)」の関係を調べる事です。
ex.綺麗なラーメンを運ぶ可愛い店員
綺麗 => ラーメン #「綺麗な」が「ラーメン」を修飾する。
ラーメン => 運ぶ #「ラーメン」が「運ぶ」を修飾する。
運ぶ => 店員 #「運ぶ」が「店員」を修飾する。
可愛い => 店員 #「可愛い」が「店員」を修飾する。
なぜ形態素解析ではダメなのか?
・形態素解析のみ
- 綺麗
- な
- ラーメン
- を
- 運ぶ
- 可愛い
- 店員
->"ラーメンが綺麗"なのか"店員が綺麗"なのか特定できないためです。
Cabochaで簡単な文章で係り受け解析
import CaboCha
cabocha = CaboCha.Parser()
sentence = "綺麗なラーメンを運ぶ可愛い店員。"
tree = cabocha.parse(sentence)
print(tree.toString(CaboCha.CABOCHA_FORMAT_TREE))
>>>
綺麗な-D
ラーメンを-D
運ぶ---D
可愛い-D
店員。
EOS
このように文節の係り受けの情報を木構造として表現されます。
これを通称「係り受け木」と呼びます。
しかし、これでは少し見づらいので「係り受け木」の結果をもう少しわかりやすく表現してみます。
import CaboCha
def get_word(tree, chunk):
surface = ''
for i in range(chunk.token_pos, chunk.token_pos + chunk.token_size):
token = tree.token(i)
features = token.feature.split(',')
if features[0] == '名詞':
surface += token.surface
elif features[0] == '形容詞':
surface += features[6]
break
elif features[0] == '動詞':
surface += features[6]
break
return surface
def get_2_words(line):
cp = CaboCha.Parser('-f1')
tree = cp.parse(line)
chunk_dic = {}
chunk_id = 0
for i in range(0, tree.size()):
token = tree.token(i)
if token.chunk:
chunk_dic[chunk_id] = token.chunk
chunk_id += 1
tuples = []
for chunk_id, chunk in chunk_dic.items():
if chunk.link > 0:
from_surface = get_word(tree, chunk)
to_chunk = chunk_dic[chunk.link]
to_surface = get_word(tree, to_chunk)
tuples.append((from_surface, to_surface))
return tuples
line = '綺麗なラーメンを運ぶ可愛い店員'
tuples = get_2_words(line)
for t in tuples:
print(t[0] + ' => ' + t[1])
>>>
綺麗 => ラーメン
ラーメン => 運ぶ
運ぶ => 店員
可愛い => 店員
このように表現すると係り受け関係が良くわかります。
get_2_words(line)で1文の中で係り受けする単語の組み合わせをタプルで取得しています。
[(綺麗,ラーメン),(ラーメン,運ぶ),(運ぶ,店員),(可愛い,店員)]
今回やりたいことは、↓のような組み合わせの文章を見つけて、口コミから可愛い店員がいるか判断することです。
(可愛い,店員)
そして、(可愛い,店員)と同じような表現をしていたらOKとしたいので、それぞれの類似語も対象としました。
可愛い:['可愛い','かわいい','カワイイ','美人','綺麗','きれい','美しい','美女']
店員:['店員','スタッフ','女将','女性','店主','助手','奥さん','奥様','店長']
# 口コミを1文ずつに切り分けし、その文章内を係り受け解析し(単語A,単語B)にkawaii_wordがあればリストに加える
import regex
def taples_kawaii(txt):
kawaii_word = ['可愛い','かわいい','カワイイ','美人','綺麗','きれい','美しい','美女']
sen = regex.split(r'(?<=[。?])(?!$)', txt, flags=regex.VERSION1)
add_list=[]
for i in sen:
tuples = get_2_words(i)
for j in tuples:
for k in kawaii_word:
if k in j:
add_list.append(j)
return add_list
# 形態素解析するための関数を定義
import MeCab
tagger = MeCab.Tagger('-Owakati -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd')#タグはMeCab.Tagger(neologd辞書)を使用
tagger.parse('')
def tokenize_ja(text, lower):
node = tagger.parseToNode(str(text))
while node:
if lower and node.feature.split(',')[0] in ["名詞","形容詞"]:#分かち書きで取得する品詞を指定
yield node.surface.lower()
node = node.next
def tokenize(content, token_min_len, token_max_len, lower):
return [
str(token) for token in tokenize_ja(content, lower)
if token_min_len <= len(token) <= token_max_len and not token.startswith('_')
]
# kawaii_wordが含まれた(単語A,単語B)をさらに形態素解析し、tennin_wordが含まれていたらフラグ立てをする
def tennin_hantei(i):
txt = tokenize(i, 2, 10000, True)
vector_list =[]
a = 0
tennin_word = ['店員','スタッフ','女将','女性','店主','助手','奥さん','奥様','店長']
for k in txt:
if k in tennin_word:
a+=1
else:
a+=0
if a >=1:
kawaii_flg = 1
else:
kawaii_flg = 0
return kawaii_flg
import pandas as pd
from tqdm import tqdm
df = pd.read_csv('../output/tokyo_ramen_review.csv')
pd.set_option("display.max_colwidth", 400)
list_sentence = df['review'].tolist()
new_list=[]
for txt in tqdm(list_sentence):
new_list.append(taples_kawaii(txt))
kawaii_flg_list2=[]
kawaii_flg_list3=[]
for k in new_list:
kawaii_flg_list=[]
if len(k)==0:
kawaii_flg_list.append(0)
else:
for i in k:
kawaii_flg_list.append(tennin_hantei(i))
if tennin_hantei(i)==1:
kawaii_flg_list3.append(sum(kawaii_flg_list))
df['kawaii_flg']=kawaii_flg_list3
df_ramen = df.groupby(['store_name','score','review_cnt'])['review'].apply(list).apply(' '.join).reset_index().sort_values('score', ascending=False)
df_ramen2 = df.groupby(['store_name','score','review_cnt'])['kawaii_flg'].sum().reset_index().sort_values('kawaii_flg', ascending=False)
df_ramen2
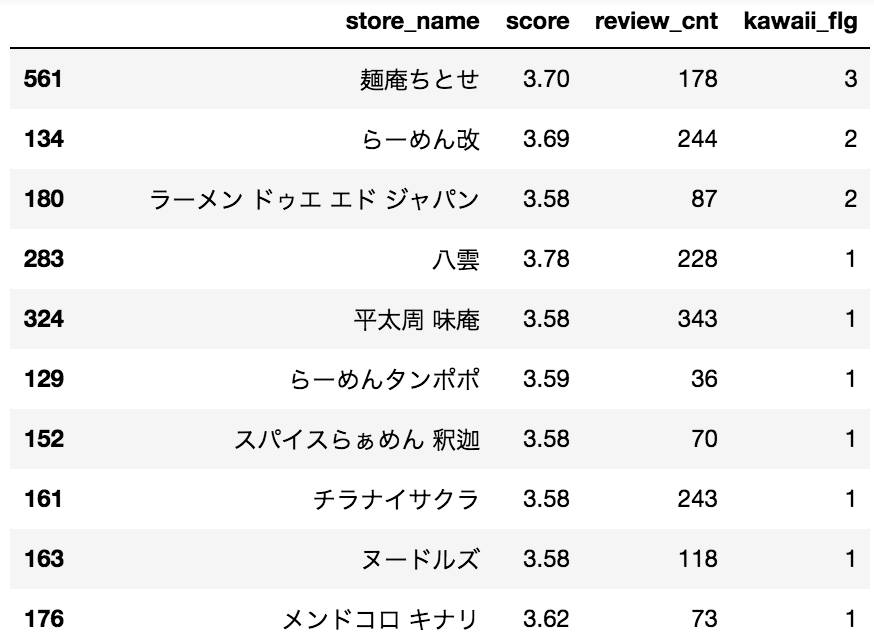
スクレイピングの際に1店舗あたりの口コミ数を20に絞っていたので、数は少ないですが可愛い店員さんがいる店を抽出することができました。
ちなみに、一位の「麺庵ちとせ」は、美人すぎる店員さんがいるラーメン屋として有名みたいです。
写真を直接掲載するのはさすがに躊躇われるので、リンクだけ貼っておきます。
5.おまけ:メタデータを抽出して、ラーメン屋を分析してみた。
メタデータとは、あるデータの性質を説明するためのデータのことです。
食べログでいうと、トップに出てくる
「最寄り駅・点数・口コミ件数・価格帯・定休日」
といった付帯情報のことを指します。
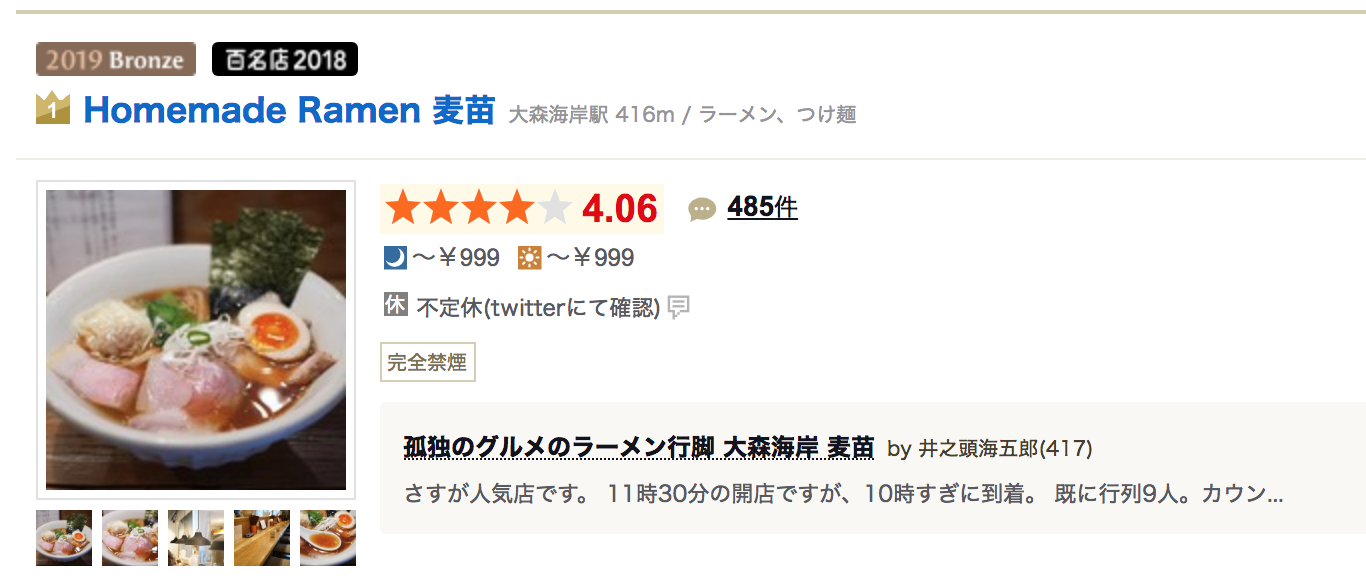
だが、しかし
ラーメンガチ勢の我々が欲している情報は、らーめんに関する情報なのです。
ラーメンに関する情報に触れられていないので、どんなラーメンなのかは写真から判断する以外に方法がありません。
そこで、↓のようなメタデータがあったらガチ勢ユーザーの満足度が向上するのでは、と思いました。

ということで、今回は、口コミデータからメタデータの取得にチャレンジしてみました。
6.メタデータを取得
特に難しいことはしていません。
口コミの文章を1文ずつに分解し、1文内で各単語の登場回数をカウントします。
そして、もっとも出現数回数多かった単語を抽出しました。
スープの種類 = ['醤油','味噌','塩','豚骨','鶏白湯','煮干し','担々麺','二郎']
スープの濃淡 = ['濃厚','淡麗']
麺の種類 = ['細麺','太麺']
では、写真から判断が難しそうな「田中商店」で、やってみました。
import pandas as pd
import regex
soup_list = ['醤油','味噌','塩','豚骨','鶏白湯','煮干し','担々麺','二郎']
noutan_list = ['濃厚','淡麗']
men_list = ['細麺','太麺']
df = pd.read_csv('../output/tokyo_ramen_review.csv')
df_ramen = df.groupby(['store_name','score','review_cnt'])['review'].apply(list).apply(' '.join).reset_index().sort_values('score', ascending=False)
list_sentence = df_ramen['review'].tolist()
main_soup = []
total_soup = []
main_noutan = []
total_noutan = []
main_men = []
total_men = []
for txt in list_sentence:
soup_dict = {}
noutan_dict = {}
men_dict = {}
sen = regex.split(r'(?<=[。?])(?!$)', txt, flags=regex.VERSION1)
for j in soup_list:
soup_cnt = 0
for i in sen:
if j in i :
soup_cnt += 1
soup_dict[j] = soup_cnt
main_soup.append(max(soup_dict, key=soup_dict.get))
total_soup.append(soup_dict)
for k in noutan_list:
noutan_cnt = 0
for l in sen:
if k in l:
noutan_cnt += 1
noutan_dict[k] = noutan_cnt
main_noutan.append(max(noutan_dict, key=noutan_dict.get))
total_noutan.append(noutan_dict)
for m in men_list:
men_cnt = 0
for n in sen:
if m in n:
men_cnt += 1
men_dict[m] = men_cnt
main_men.append(max(men_dict, key=men_dict.get))
total_men.append(men_dict)
df_ramen['main_soup'] = main_soup
df_ramen['total_soup'] = total_soup
df_ramen['main_noutan'] = main_noutan
df_ramen['total_noutan'] = total_noutan
df_ramen['main_men'] = main_men
df_ramen['total_men'] = total_men
df_ramen

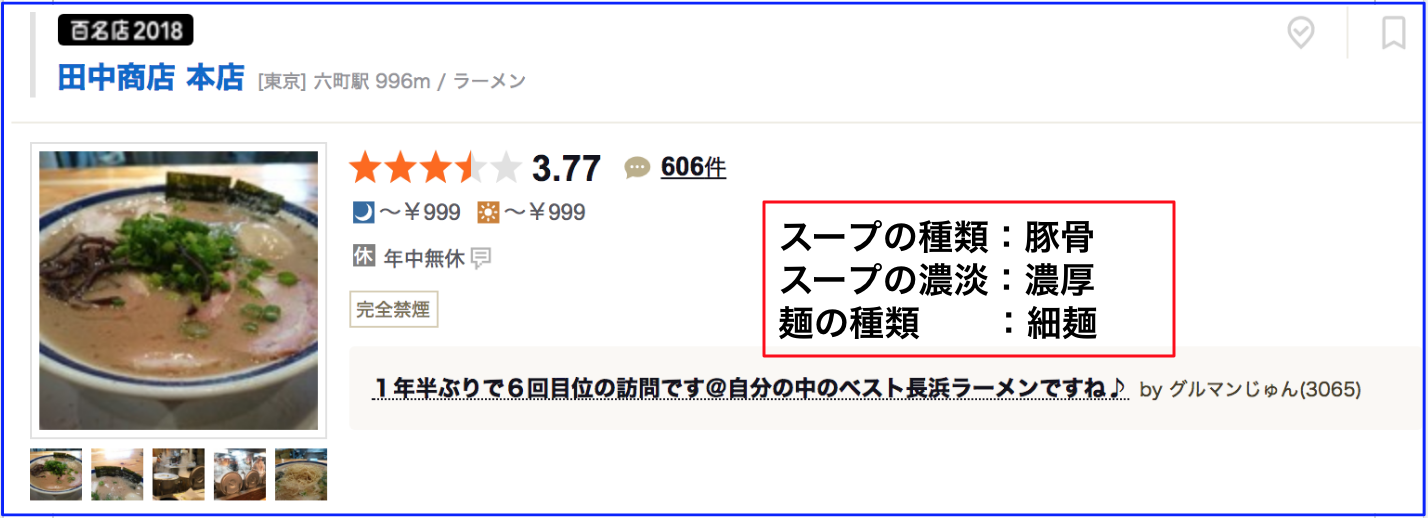
7.メタデータを用いた分析
せっかくなので、メタデータを用いて簡単な分析にもチャレンジしてみました。
食べログ3.58以上の567店舗のスープ別割合を求めました。
私の予想では、トップ5は↓こんな感じになるのではないかと。
1位:醤油
2位:塩
3位:豚骨
4位:味噌
5位:煮干し
# 積立棒グラフを作成
import matplotlib.pyplot as plt
import matplotlib as mpl
font = {"family":"IPAexGothic"}
mpl.rc('font', **font)
# 全567件のデータのスープ別割合
df_ramen2 = df_ramen.loc[:, ['score', 'main_soup']]
df_ramen3 = df_ramen2.groupby('main_soup').count().sort_values('score', ascending=False)#スープでbroupby
df_ramen3.reset_index()
df_ramen3['total_rate']=df_ramen3['score']/df_ramen3['score'].sum()#割合を計算
df_ramen3=df_ramen3.drop("score", axis=1)
# 上位100件のデータのスープ別割合
df_ramen_top100=df_ramen.iloc[0:100,:].reset_index()
df_ramen_top100_2 = df_ramen_top100.loc[:, ['score', 'main_soup']]
df_ramen_top100_3 = df_ramen_top100_2.groupby('main_soup').count().sort_values('score', ascending=False)#スープでbroupby
df_ramen_top100_3.reset_index()
df_ramen_top100_3['top100_rate']=df_ramen_top100_3['score']/df_ramen_top100_3['score'].sum()#割合を計算
df_ramen_top100_3=df_ramen_top100_3.drop("score", axis=1)
# 下位100件のデータのスープ別割合
df_ramen_bottom_100=df_ramen.iloc[:467,:].reset_index()
df_ramen_bottom_100_2 = df_ramen_bottom100.loc[:, ['score', 'main_soup']]
df_ramen_bottom_100_3 = df_ramen_bottom_100_2.groupby('main_soup').count().sort_values('score', ascending=False)#スープでbroupby
df_ramen_bottom_100_3.reset_index()
df_ramen_bottom_100_3['bottom100_rate']=df_ramen_bottom_100_3['score']/df_ramen_bottom_100_3['score'].sum()#割合を計算
df_ramen_bottom_100_3=df_ramen_bottom_100_3.drop("score", axis=1)
# 3つの積立棒グラフを作成
# 3つのデータを結合
df_ramen4 = df_ramen3.join(df_ramen_top100_3, how='inner').join(df_ramen_bottom_100_3, how='inner')
sample_df = df_ramen4.T
sample_df.plot.barh(stacked=True)
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0, fontsize=17)
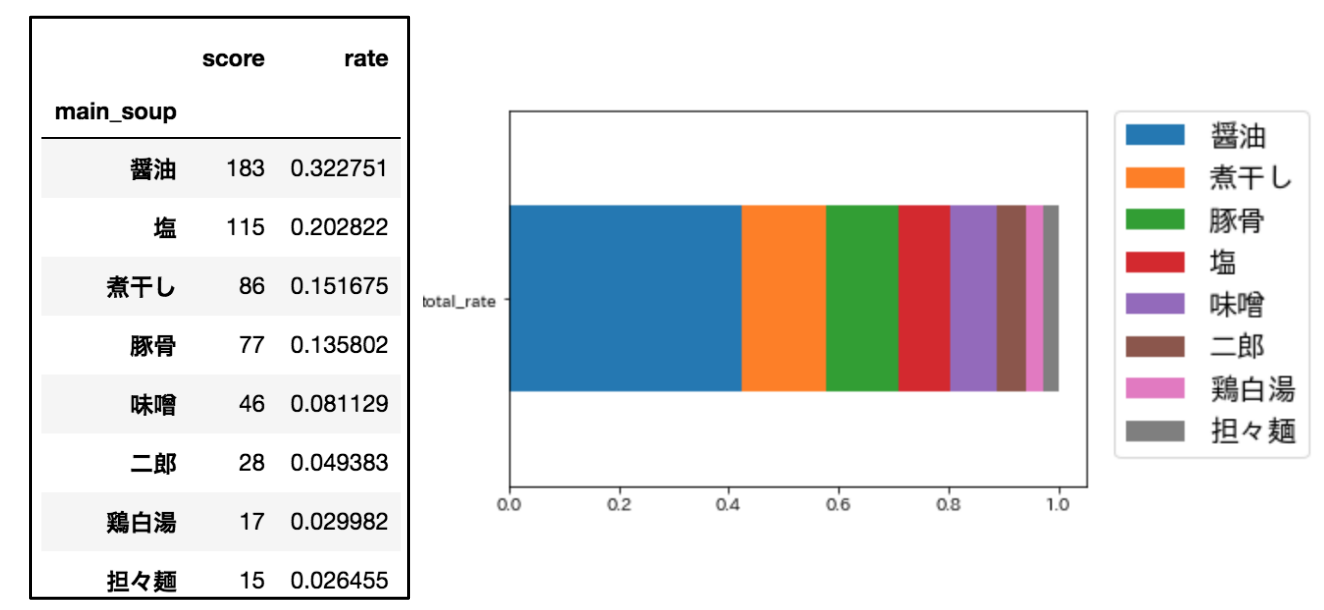
ふむふむ。
メジャーな醤油がはやりトップなんですねー
味噌や豚骨より煮干しが上位にくるあたりが意外でした。
では、次に抽出した567店舗のうち、食べログ評価上位100と下位100で比較してみます。

【上位100→下位100】
醤油:41%→26% ⤵︎
塩 :23%→11% ⤵︎
煮干:18%→16% ⤵︎
豚骨:9% →23% ⤴︎
二郎:4% →13% ⤴︎
食べログ3.58というハイレベルなお店の中でも、上位と下位では傾向が大きく変わることがわかりました。
上位100は、万人受けをするミシュランに掲載されるような上品で完成度の高いスープを武器にしたラーメン。通称「意識高い系」ラーメンが多くランクインしていました。
一方で下位100の特徴として二郎系やひと昔一世を風靡した魚介豚骨系のお店、通称「またおま系」の出現頻度が高くなっているようです。
近年のトレンドが反映されていて納得の結果です。
【意識高い系】
おしゃれな器、澄み切ったスープ、細くこじんまりと盛り付けられた麺、なんかよくわからなく添えられてる薬味。まるでフレンチを彷彿とさせる、この食べ物が「意識高い系ラーメン」です。

【またおま系(またおまけい)】
豚骨魚介スープを使用したつけ麺やラーメンのこと。主にラーメンマニアの人達が使用する。
語源は「またお前か」。最近の新しいラーメン屋が次々と豚骨魚介系の味を提供することから、ラーメンを食べる頻度の高いラヲタから「またお前か…」と言われるようになり、それら味付けの物をこのように呼ぶようになった。

8.課題
今回は口コミからメタ情報取得にチャレンジしましたが、いろいろと課題がありました。
スープ判定について
ラーメン屋のスープを調べる際に、単純に口コミに「醤油」などの単語の出現回数をカウントしましたが、
「サイドメニューの特製たまごかけご飯に醤油を垂らして・・・」
という場合もカウントしてしまっていました。スープ判別の際も係り受けを考慮すべきだったと思います。
可愛い店員さん判定について
係り受け解析をしたことにより、厳密な判定をしたつもりでしたが、
「美人すぎる店員がいると噂のラーメン屋に行きました」
という口コミの場合、「美人すぎる店員」で一単語と認識されてしまい、(美人,店員)という係り受けとならず、拾えていないことがわかりました。このあたりは難しいところです。
9.まとめ
・口コミからメタデータを抽出することはできるが、精度を高くするには工夫が必要
・メタデータが抽出できれば分析に応用できる
・美人店員さんがいるお店は抽出できたが「美人すぎる」と抽出できない
次回は、食べログ口コミから食べログ点数の予測にチャレンジする予定です。