測定を行った動機
以前から、Transformer を使った非自己回帰型の画像キャプショニングプログラムの開発を行っていました。しかし、思うように精度が上がらない状態でした。そんな中で、自己回帰的な画像キャプショニングでどのくらいの精度がでるか試してみました。「Python で学ぶ画像認識」という教科書に掲載されている Transformer を用いた画像キャプショニングプログラムの精度を試してみました。教科書のプログラムではtransformer の隠れ次元が 300 なので、これを 768 にして学習させました。また、教科書では COCO val2014 をデータとして使っていたので、COCO tarin2017 にしました。訓練時の非自己回帰的な推論文で、WER が 52 %、BLEU が 23 % で、テスト環境での自己回帰的な推論文で 67 % くらい、NLTK の BLEU が 20 %(smoohting function 7 を使いました) という結果がでました。実際に 100epoch 訓練後に test データで生成したキャプションは、

推論した文章 : <start> a car car on a street next to a <end>
です。かなり、品質が良くないと言わざる負えないと思います。
そこで、まずは自己回帰的なプログラムの精度を上げなければと思いました。ネットで検索したところ、CLIP + DenseConnector + Vicuna で良い文章が生成されたというページを見つけました。Decoder に、LLM を使うのがミソのように思われました。そこで、自分の環境で実現可能そうな例を探したところ、
のページが参考になりそうでした。このページを読み、自分でも、ファインチューニングを行いました。
今回の CLIP + Dense Connector + GPT2 のシステムで生成したキャプションは

推論した文章 :
This is an outside view. Here I can see a woman standing on the ground.
Two persons are wearing black dress and standing on the floor.
In the background, I can see a building, a building and the sky.
です。音声認識の場合は、発話された文言に忠実に認識を行うので、目標とする文章と推論した文章の文言が一致するのが望ましいです。画像キャプショニングの場合、画像をキャプションに翻訳する時に同じ意味の違う単語を使うとか、文章の言い回しが異なるとかを考慮して判断しなければなりません。このことを考えると、精度が上がっていると思います。
使わせていただいたプログラムなど
CLIP には、clip-vit-large-patch14-336 を使わせていただきました。GPT2 には、「LLM 自作入門」という本の GPT2_large を padding_mask を入力できるように改修したものを使わせていただきました。GPT2 のパラメーターは OpneAI の公開しているパラメーターです。Dense Connector は、
を参考にさせていただきました。これらの要素より作成した画像キャプショニングプログラムのファインチューニングを行いました。
入力と損失の計算。
CLIP の入力は、336 × 336 の画像です。CLIP の出力は 、hidden_state が26層の[batch, 577,1024] で、last_hidden_state が [batch, 577, 1024] です。これらを Dense Connector に入力し conv1d に 2回(stride = 5 と 2 )通して Linear をかけ、[batch, 58, 1280] にします。
# self.dc_linear = nn.Linser( 3 * 1024, 1280 )
# Dense Connector のソース
def dense_connector(self, memory ):
tmp1 = torch.tensor([], device = self.device )
tmp2 = torch.tensor([], device = self.device )
tmp_full = len( memory.hidden_states )
tmp_half = tmp_full // 2
for i in range( 0, tmp_half ):
tmp1 = torch.cat( [tmp1, memory.hidden_states[i][None]], dim = 0 )
tmp1 = torch.sum(tmp1, dim=0) / tmp_half
for i in range( tmp_half, tmp_full ):
tmp2 = torch.cat( [tmp2, memory.hidden_states[i][None]], dim = 0 )
tmp2 = torch.sum(tmp2, dim=0 ) / ( tmp_full - tmp_half )
tmp3 = torch.cat([tmp1, tmp2], dim=-1)
tmp3 = torch.cat( [ memory.last_hidden_state, tmp3], dim = -1 )
#tmp3 = sel.dc_ln( tmp3 )
tmp3 = self.dc_linear( tmp3 )
return tmp3
この Dense Connector の出力 [batch, 58, 1280 ]と、caption を embedding した self.emb( captions[:,:-1] ) [batch, seq_len-1, 1280] を cat したものを GPT2 の入力としました。tokenizer = tiktoken.get_encoding("gpt2") には、tokenizer.pad_token_id がないので、pad は、id = 50256 の '<|endoftext|>' としました。その代わり、pad については、padding_mask テンソルを作り、GPT2 の MHA で、attn_scores の padding_mask が True に対応した部分は、attn_scores を -torch.inf にするように改修しました。
こうすると、損失をどのように計算するかという問題になります。まず、GPT2 decoder の出力の seq_len が 58 の部分から最後までを改めてdecoder の出力とします。58 というのは、画像に対応した seq_len の最後の一個は入れるということです。これと、caption の CrossEntropyLoss をとって損失としました。すなわち、GPT2 decoder への入力が 画像の seq_len が最後の部分に対応した decoder の出力と caption[:,0] の損失、GPT2 decoder への入力が caption[:,:-1]に対応した decoder の出力と caption[:,1:] の損失を計算していることになります。
推論の関数について
tiktoken の gpt2 のtokeizer については、pad token がないため、batch_size = 1 の時の推論のコードについて説明させていただきます。
def inference( imgs ):
# batch_size = 1 で実行してください。
device = imgs.device
with torch.no_grad():
memory = model.clip_model( imgs )
memory = model.dense_connector( memory )
memory = model.dropout( memory )
memory = model.ln_memory( memory )
memory = model.conv1( memory.transpose(1,2) )
memory = model.conv2( memory ).transpose( 1, 2 )
captions = torch.tensor( [[]], device = device, dtype = torch.long )
for i in range( max_length ):
if i == 0:
gpt_in_padding_masks = torch.zeros( memory.shape[:2], device = device ).bool()
outputs = model.decoder( memory, gpt_in_padding_masks )
else:
emb_caption = model.emb( captions )
gpt_in = torch.cat( [memory, emb_caption], dim = 1 )
gpt_in_padding_masks = torch.zeros( gpt_in.shape[:2], device = device ).bool()
outputs = model.decoder( gpt_in, gpt_in_padding_masks )
last_outputs = outputs[:,-1]
word = torch.argmax( last_outputs, dim = 1 )
captions = torch.cat( [captions, word[None]], dim = 1 )
return captions
まずは、学習時の順伝播と同じに、CLIP と dense connector で、入力の画像テンソルから [batch = 1, 58, 1280] の memory を作ります。次に、今作った memory を初期値として自己回帰的に caption を生成していきます。
自己回帰の行い方は、まず、初期値の memory を GPT2 decoder に入力して、memory の seq_len の最後の位置の token を captions の第 1 トークンとします。次に、memory の初期値に、caption の第 1 トークンを nn.Embedding( vocab_size, dim_hidden ) で埋め込んだ emb_caption を cat します。この cat した値を GPT2 decoder に入力して、出力の最後を captions の第 2 トークンとします。これを max_length=50 までイタレートして caption を得ます。
学習データ
学習データは、Open Images V7 を使わせていただきました。0.8 を訓練用に、0.1 を開発(評価)用に、0.1 をテスト用に割り当てました。
学習曲線
Loss と WER と BLEU のグラフを掲載させていただきます。
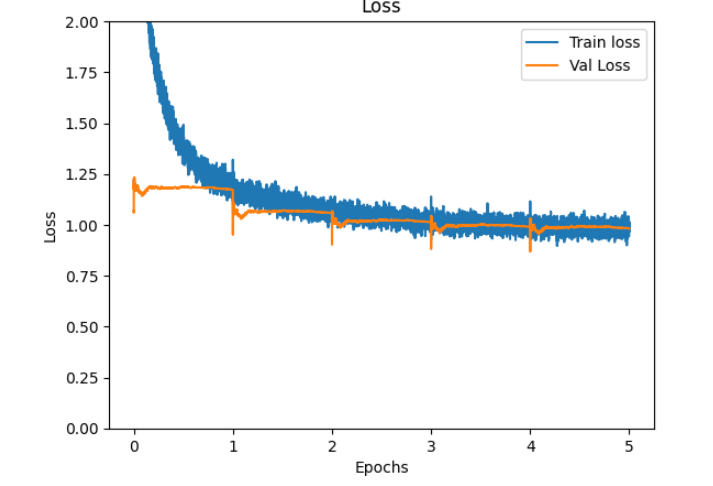
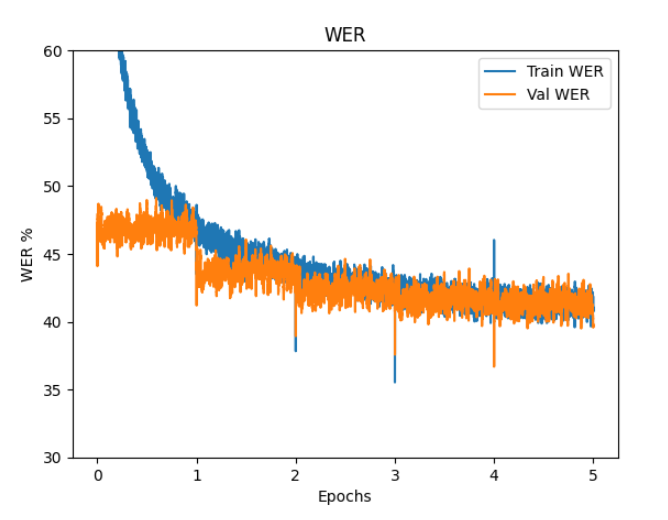
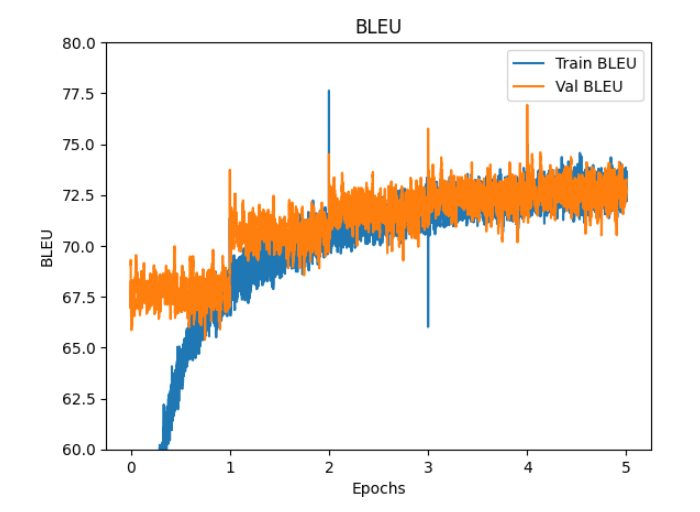
テストデータでの測定結果
テストデータでの測定結果は、WER が97.3 BLEU が45.9 CIDER が1.38 でした。生成したキャプションは
Fig.1
refe: In this I can see there are red colored strawberries.
hypo: In this image we can see a food item.

Fig.2
refe: There are few persons sitting on the chairs. Here we can see monitors, keyboards, tables, and devices.
hypo: In this picture we can see a group of people sitting on the chairs, some objects, some objects on the tables, some objects, some objects are placed on the surface, we can see some objects on the tables and in the background, we can

Fig.3
refe: This image is taken outdoors. At the bottom of the there is a floor. In the background there are a few buildings with walls, windows and balconies. In the middle of the image two men and a woman are standing on the floor and they are with smiling faces.
hypo: This is an outside view. Here I can see a woman standing on the ground. Two persons are wearing black dress and standing on the floor. In the background, I can see a building, a building and the sky.
Fig.4
refe: In this image in front there are plants. In the background of the image there is sky.
hypo: This picture is clicked outside. In the center we can see the plants and we can see the flowers. In the background there are plants and we can see the flowers. At the top we can see the sky and the clouds are present in the dark

Fig.5
refe: This is a black and white image. In this image we can see women wearing spectacles.
hypo: In the picture we can see a woman wearing a cap and the black jacket is standing on the floor. . This picture

Fig.6
refe: As we can see in the image there is a white color plate. In plate there is a dish.
hypo: In this image we can see food item. .

Fig.7
refe: This image is clicked in a musical concert where there is a woman Standing and she is holding a guitar in her hand. She is wearing black color dress. There is a mic in front of her and there is a bottle. She is holding a stick. There are speakers back side and there are some musical instruments on the bottom left corner.
hypo: In this image we can see a person standing on the floor and holding a guitar. In front of her we can see a microphone and a wall. At the top we can see a light, wall and a light. In the background we can see

Fig.8
refe: In this image, we can see a black color dog, there is a blurred background.
hypo: In this image we can see a cat. In the background there is snow. .

Fig.9
refe: In this picture there is a bowl and a plate in the center of the image, which contains food items in it.
hypo: In this image we can see the plate containing food item on the plate.

Fig.10
refe: In this picture I can observe some food places in the plate. The food is in brown, orange, green and red colors. It is looking like a burger. The background is completely blurred.
hypo: In this picture we can see food items in the plate and there is a blurry background.

Fig.11
refe: In this image i can see a person standing wearing a black shirt, blue jeans and glasses. He is holding a electronic gadget in his hand. In the background i can see few people standing, and the ceiling of the building.
hypo: In this image I can see a man is standing, he wore a white shirt and blue color jacket, in front of him I can see few persons standing and I can see few objects in the background.

Fig.12
refe: In this image we can see cars, people, banners, hoardings, tent, pole, trees, boards, and buildings. In the background there is sky.
hypo: In the center of the image we can see a person standing and holding some object and there is a person in a vehicle and a banner. On the right and left side of the image we can see vehicles on the road. In the background there are

Fig.13
refe: In this image we can see two persons standing and holding the objects, there are some stones, grass, plants and trees, also we can see the sky.
hypo: In this image, we can see two persons wearing clothes and standing on the ground. There is a person in the middle of the image. There is a rock in the bottom of the image. There is a sky at the top of the image.

Fig.14
refe: In front of the image there are some engravings on the headstone, around the headstone on the surface there are green leaves and dry leaves and sticks, behind the headstone there are trees and a wall.
hypo: In this image we can see a stone with a stone and a stone. In the background there are plants and trees.

Fig.15
refe: In this picture I can see building and few trees and a cloudy sky.
hypo: In this image there is a wall, on the top of the roof there is a tree. .

Fig.16
refe: In this image there are many people in front of the building. Some of them are holding camera. In the background there are buildings. There is a banner over here.
hypo: In this picture I can see few people are standing and holding cameras and I can see a camera in the backdrop. I can see the sky in the middle.

Fig.17
refe: In this image I can see a snake on the ground. It is in black color. I can see few wooden sticks,few stones and grass.
hypo: In this image we can see the rock. There are stones and grass. .

Fig.18
refe: In this image we can see a person standing and holding a book and to the side we can see a podium with mic and there is a laptop and some other objects on the table. We can see a person standing in the bottom right.
hypo: In the picture we can see a woman sitting on the chair, she is speaking in front of her, she is wearing a black color dress and standing near the table on the table, on the table we can see a paper, beside to her we

Fig.19
refe: In this picture I can see 2 women in front and the women right is holding a brush in her hand and I see the paint on the face of the woman on the left and in the background I see the grass and on the top left of this image I see the blue color things.
hypo: In this image, we can see a woman and there are some people. At the bottom, there is a grass and we can see some objects.

Fig.20
refe: In this image we can see an animal, water, rocks, and leaves. At the bottom of the image we can see a person who is truncated.
hypo: In this image there is one person standing and holding a snake in the water. There is a fish in the bottom left corner and the water might be in the water.

Fig.21
refe: In this image we can see three people, one of them is wearing a backpack, in front of them, we can see some bags, box, also we can see some plants, grass, and trees.
hypo: In this image I can see two persons. In front the person is holding a cloth and in the background I can see grass, number of trees.

である。それなりにキャプションを生成できていると考える。
測定に使用したプログラムを github に掲載しておきます。
よろしくお願いいたします。
今回の計算は、GPT2 に LLM の勉強をした、Build a Large Language Model のモジュールを使用させていただきました。時間がとれたら、計算方法がなんとなくわかったみたいなので、Hugging Face で公開されている OpenAI の学習済み GPT2 での計算もご報告できればと思います。
Hugging Face で OpenAI が公開している事前学習済 GPT2 バージョン、2025年9月2日追記
Hugging Face で OpenAI が公開している事前学習済の CLIP と GPT2 を用いて v7 データセットで Fine Tuning しました。プログラムは、
の CLIP_hfGPT2_AR というフォルダにおいてあります。
学習曲線
Loss と WER と BLEU のグラフを掲載させていただきます。
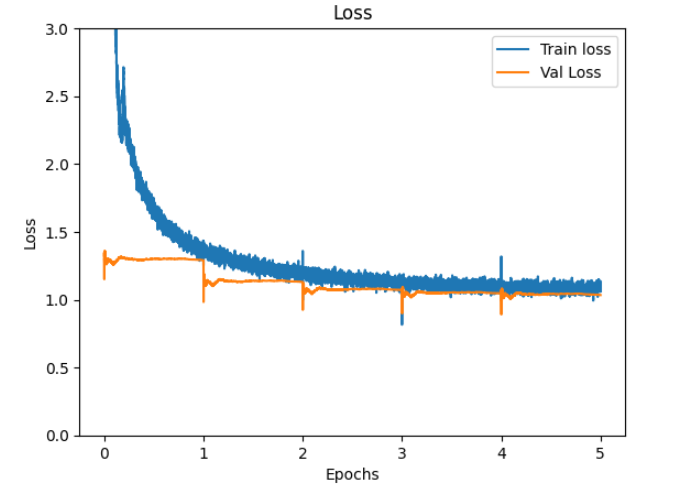
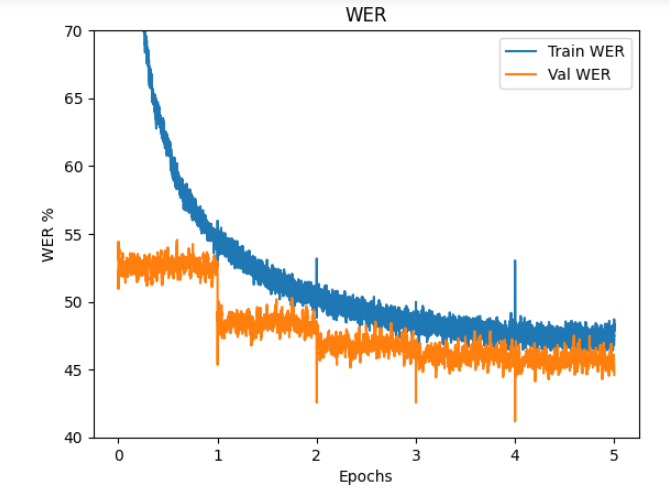
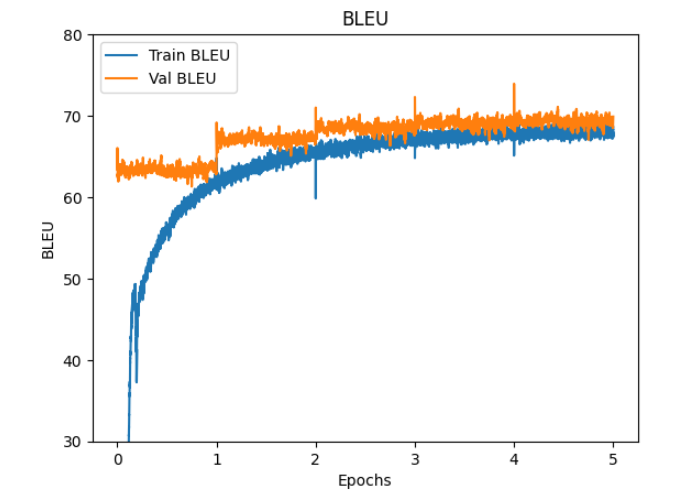
epoch 5 で、
train loss: 1.12 WER: 48.4 BLEU:67.6
val loss: 1.03 WER: 44.6 BLEU:69.9
でした。
テスト結果
epoch 5 まで Fine Tuning した重みを使い、20テストデータについて、自己回帰型の推論を行いました。推論関数には、inference と inference2 の2種類の関数を用いました。
def inference( imgs, length_max, temperature=0.0, top_k=None ):
# batch_size = 1 で実行してください。
device = imgs.device
with torch.no_grad():
memory = model.clip_model( imgs )
memory = model.dense_connector( memory )
memory = model.dropout( memory )
memory = model.ln_memory( memory )
memory = model.conv1( memory.transpose(1,2) )
memory = model.conv2( memory ).transpose( 1, 2 )
captions = torch.tensor( [[]], device = device, dtype = torch.long )
for i in range( length_max ):
if i == 0:
gpt_in_padding_masks = torch.ones( memory.shape[:2], device = device ).bool()
logits = model.decoder( inputs_embeds = memory, attention_mask = gpt_in_padding_masks ).logits
else:
emb_caption = model.emb( captions )
gpt_in = torch.cat( [memory, emb_caption], dim = 1 )
gpt_in_padding_masks = torch.ones( gpt_in.shape[:2], device = device ).bool()
logits = model.decoder( inputs_embeds = gpt_in, attention_mask = gpt_in_padding_masks ).logits
logits = logits[:,-1]
# New: Filter logits with top_k sampling
if top_k is not None:
# Keep only top_k values
top_logits, _ = torch.topk(logits, top_k)
min_val = top_logits[:, -1]
logits = torch.where(logits < min_val, torch.tensor(float("-inf")).to(logits.device), logits)
# New: Apply temperature scaling
if temperature > 0.0:
logits = logits / temperature
# Apply softmax to get probabilities
probs = torch.softmax(logits, dim=-1) # (batch_size, context_len)
# Sample from the distribution
idx_next = torch.multinomial(probs, num_samples=1) # (batch_size, 1)
# Otherwise same as before: get idx of the vocab entry with the highest logits value
else:
idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch_size, 1)
captions = torch.cat( [captions, idx_next], dim = 1 )
#word = torch.argmax( last_outputs, dim = 1 )
#captions = torch.cat( [captions, word[None]], dim = 1 )
return captions
def inference2( imgs, length_max, temperature=0.0, top_k=None ):
# batch_size = 1 で実行してください。
device = imgs.device
with torch.no_grad():
memory = model.clip_model( imgs )
memory = model.dense_connector( memory )
memory = model.dropout( memory )
memory = model.ln_memory( memory )
memory = model.conv1( memory.transpose(1,2) )
memory = model.conv2( memory ).transpose( 1, 2 )
captions = torch.tensor( [[]], device = device, dtype = torch.long )
generated = memory
for i in range( length_max ):
gpt_in_padding_masks = torch.ones( generated.shape[:2], device = device ).bool()
outputs = model.decoder( inputs_embeds = generated, attention_mask = gpt_in_padding_masks ).logits
logits = outputs[:,-1]
# New: Filter logits with top_k sampling
if top_k is not None:
# Keep only top_k values
top_logits, _ = torch.topk(logits, top_k)
min_val = top_logits[:, -1]
logits = torch.where(logits < min_val, torch.tensor(float("-inf")).to(logits.device), logits)
# New: Apply temperature scaling
if temperature > 0.0:
logits = logits / temperature
# Apply softmax to get probabilities
probs = torch.softmax(logits, dim=-1) # (batch_size, context_len)
# Sample from the distribution
idx_next = torch.multinomial(probs, num_samples=1) # (batch_size, 1)
# Otherwise same as before: get idx of the vocab entry with the highest logits value
else:
idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch_size, 1)
next_token_embed = model.emb( idx_next )
#print( "size of generated:", generated.size() )
#print( "size of next_token_embed:", next_token_embed.size() )
generated = torch.cat( (generated, next_token_embed), dim = 1 )
captions = torch.cat( [captions, idx_next], dim = 1 )
#word = torch.argmax( last_outputs, dim = 1 )
#captions = torch.cat( [captions, word[None]], dim = 1 )
return captions
test 結果は
inference WER 91.5 BLEU 46.2 CIDER 1.89
inference2 WER 87.6 BLEU 43.5 CIDER 2.10
でした。ここでは、inference2 の結果をご報告させていただきます。

refe: In this I can see there are red colored strawberries.
hypo: In this image we can see some food items on the table.

refe: There are few persons sitting on the chairs. Here we can see monitors, keyboards, tables, and devices.
hypo: In this image I can see a woman sitting on the chair and I can see a laptop and a laptop. In the background I can see few people sitting on the chairs and I can see a laptop and a laptop.

refe: This image is taken outdoors. At the bottom of the there is a floor. In the background there are a few buildings with walls, windows and balconies. In the middle of the image two men and a woman are standing on the floor and they are with smiling faces.
hypo: In this image we can see a group of people standing and smiling. In the background of the image we can see a building, doors, a building, a door, a door, a door and a door.

refe: In this image in front there are plants. In the background of the image there is sky.
hypo: In this image we can see some plants, plants, plants, plants, and some other objects.

refe: This is a black and white image. In this image we can see women wearing spectacles.
hypo: In this image we can see a woman wearing a black dress and a black color dress. In the background of the image we can see a wall.

refe: As we can see in the image there is a white color plate. In plate there is a dish.
hypo: In this image we can see a food item on the plate.

refe: This image is clicked in a musical concert where there is a woman Standing and she is holding a guitar in her hand. She is wearing black color dress. There is a mic in front of her and there is a bottle. She is holding a stick. There are speakers back side and there are some musical instruments on the bottom left corner.
hypo: In this image we can see a woman standing and holding a guitar in her hand and playing guitar. In the background we can see a wall, wall, curtain, curtain, curtain, curtain, curtain, curtain, curtain, curtain, curtain, and some objects.

refe: In this image, we can see a black color dog, there is a blurred background.
hypo: In this image we can see a dog standing on the ground.

refe: In this picture there is a bowl and a plate in the center of the image, which contains food items in it.
hypo: In this image we can see food items on a plate, spoon, knife, spoon, spoon, spoon, spoon, fork, spoon, fork, plate, fork and other objects.

refe: In this picture I can observe some food places in the plate. The food is in brown, orange, green and red colors. It is looking like a burger. The background is completely blurred.
hypo: In this picture I can see a food item and a food item on the plate. I can see the brown and brown color food item.

refe: In this image i can see a person standing wearing a black shirt, blue jeans and glasses. He is holding a electronic gadget in his hand. In the background i can see few people standing, and the ceiling of the building.
hypo: In this image we can see a group of people standing on the floor. In the background we can see a wall, a wall, a projector screen, a projector screen, a projector screen and a projector screen.

refe: In this image we can see cars, people, banners, hoardings, tent, pole, trees, boards, and buildings. In the background there is sky.
hypo: In this image we can see a group of people standing on the road. In the background we can see a building, trees, poles, poles, poles, poles, and a few people. At the top of the image we can see the sky.

refe: In this image we can see two persons standing and holding the objects, there are some stones, grass, plants and trees, also we can see the sky.
hypo: In this 
image we can see a man standing and holding a rifle in his hand. In the background we can see trees, plants, grass, grass, grass, sky and clouds.

refe: In front of the image there are some engravings on the headstone, around the headstone on the surface there are green leaves and dry leaves and sticks, behind the headstone there are trees and a wall.
hypo: In this image we can see a stone, stones, stones, grass, stones, grass, grass, and the sky.

refe: In this picture I can see building and few trees and a cloudy sky.
hypo: In this image we can see a building with windows and a door.

refe: In this image there are many people in front of the building. Some of them are holding camera. In the background there are buildings. There is a banner over here.
hypo: In this image we can see a group of people standing on the road. In the background we can see a building, trees, buildings, poles, and the sky.

refe: In this image I can see a snake on the ground. It is in black color. I can see few wooden sticks,few stones and grass.
hypo: In this image we can see a snake on the ground.

refe: In this image we can see a person standing and holding a book and to the side we can see a podium with mic and there is a laptop and some other objects on the table. We can see a person standing in the bottom right.
hypo: In this image I can see a woman standing and holding a microphone in her hand. I can see a table and a laptop. I can also see a laptop and a laptop. I can also see a board and a screen.

refe: In this picture I can see 2 women in front and the women right is holding a brush in her hand and I see the paint on the face of the woman on the left and in the background I see the grass and on the top left of this image I see the blue color things.
hypo: In this image we can see a woman holding a stick in her hand. In the background there is a wall.

refe: In this image we can see an animal, water, rocks, and leaves. At the bottom of the image we can see a person who is truncated.
hypo: In this image we can see a person standing on the rock. In the background we can see the sky, trees, mountains and the sky.

refe: In this image we can see three people, one of them is wearing a backpack, in front of them, we can see some bags, box, also we can see some plants, grass, and trees.
hypo: In this image we can see a man and a woman. In the background we can see trees, grass, sky, clouds and sky.
test WER: 87.61316177040997
test BLEU: 43.51152702336057
test CIDER: 2.1009364309303304