測定を行った動機
音声認識(ASR) では、一般に音響特徴量には fbank か mfcc が用いられる。一方、Transformer を用いた画像識別などでは、特徴量の解析には CNN を用いた Feature Extractor を用いることも多い。そこで、wav ファイルを直接の入力とし、Conv1d で音響特徴量を算出する Feature Extractor による ASR モジュールの精度を測定した。比較のため、fbank, mfcc による精度測定も行った。
音声認識モジュール
音声認識は、非自己回帰的な音声認識 2 種類で行った。1種類は
24 layers PyTorch Transformer Encoder + CTCloss
である。もう1種類は
12 layers whisper like Transformer Encoder + 12 layers whisper like Transformer Decoder + CTCLoss
である。いずれも Encoder に簡単な conv1d を含む。whisper like Transformer Decoder の入力は、memory 入力に Encoder Outs と target 入力に Encoder Outs を Sequence 方向に 0.25 倍ダウンサンプリングした値を用いた。
Wav 入力による音声認識では、上記の2種類いずれにも Encoder の前段に Feature Extractor として、
7 layers( conv1d + BatchNorm1d + GELU) + LayerNorm + Linear + Dropout
を入れた。
学習結果
| model | WER |
|---|---|
| PT fbank | 25.8 |
| PT mfcc | 26.7 |
| PT wav | 26.1 |
| Whisper like fbank | 19.8 |
| Whisper like mfcc | 20.3 |
| Whisper like wav | 21.7 |
学習データ
学習データは、訓練データに、BASIC5000 の 3000 発話と common voice japanese 35000 発話を用いた、開発データには、BAIC5000 の 1000 発話を、テストデータにも BASIC5000 の 1000 発話を用いた。
測定
fbank + PyTorch Transformer Encoder + CTCLoss
測定時の Loss と CER のグラフを掲載する。
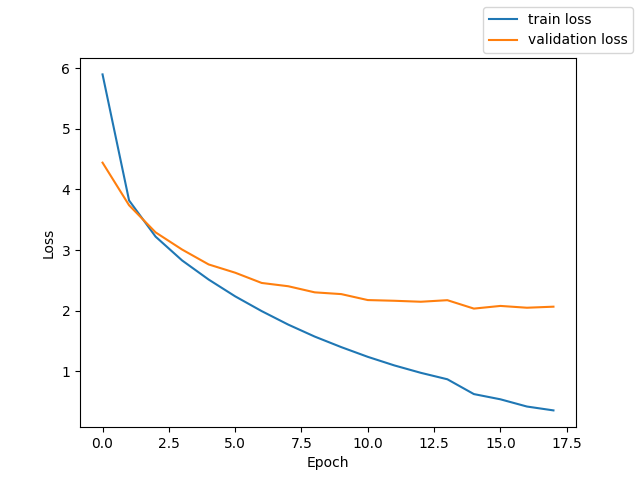
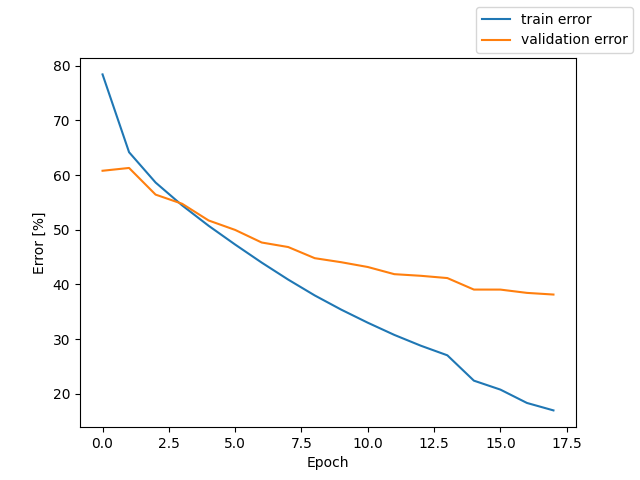
テストでの CER 25.8%
mfcc + PyTorcn Transformer Encoder + CTCLoss
測定時の Loss と CER のグラフを掲載する。
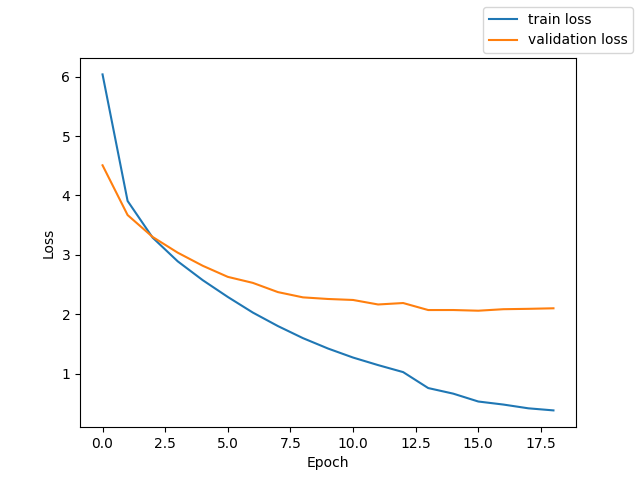
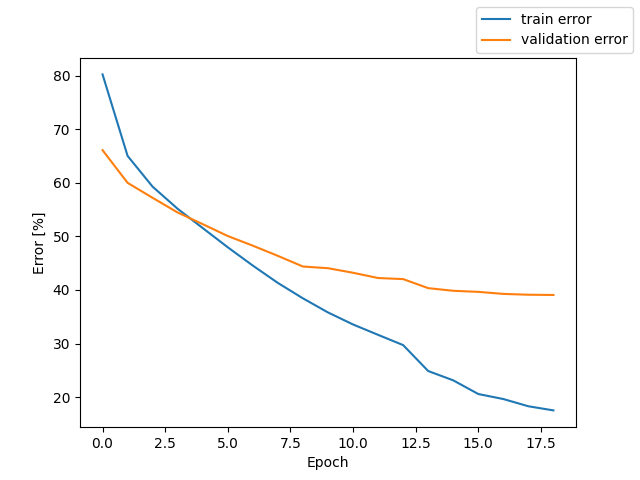
テストでの CER 26.7%
Wav + Feature Extractor + PyTorch Transformer Encoder + CTCLoss
測定時の Loss と CER のグラフを掲載する。
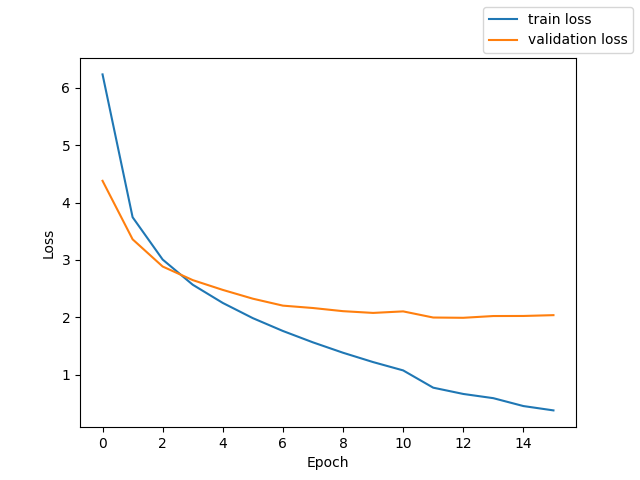
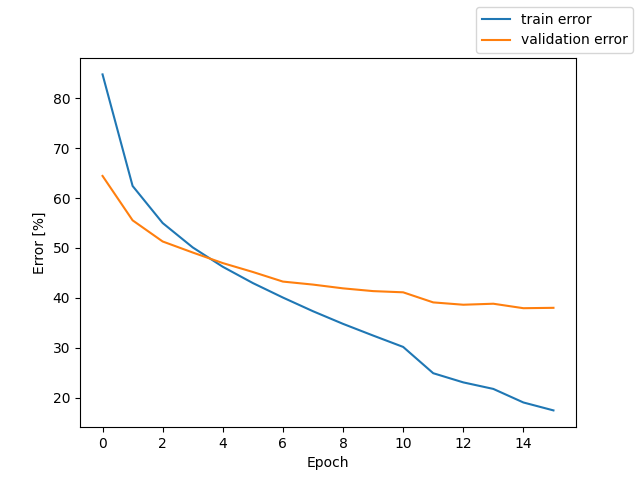
テストでの CER 26.1 %
fbank + whisper like Transformer Encoder + downsampling + Transformer Decoder + CTCLoss
測定時の Loss と CER のグラフを掲載する。
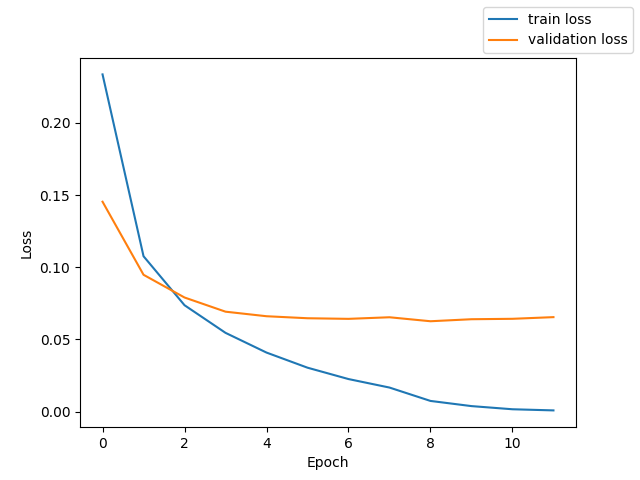
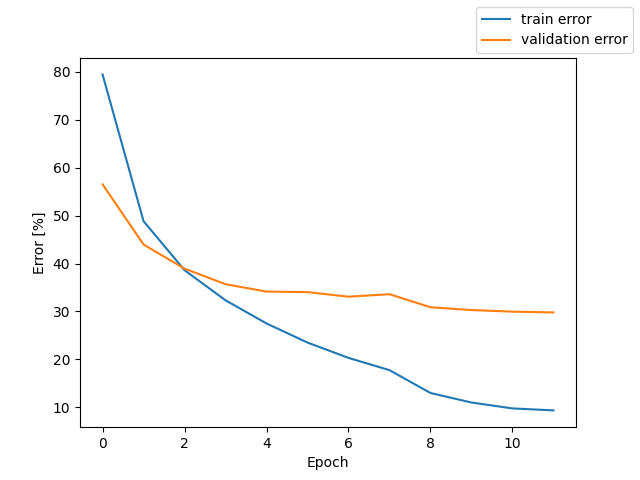
テストでの CER 19.8%
mfcc + whisper like Transformer Encoder + downsampling + Transformer Decoder + CTCLoss
測定時の Loss と CER のグラフを掲載する。
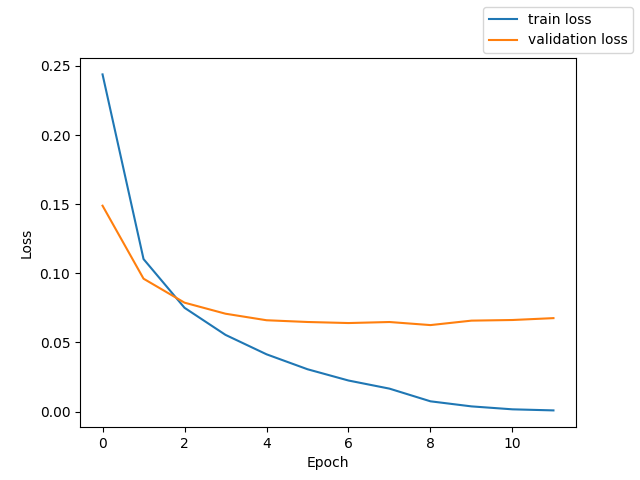
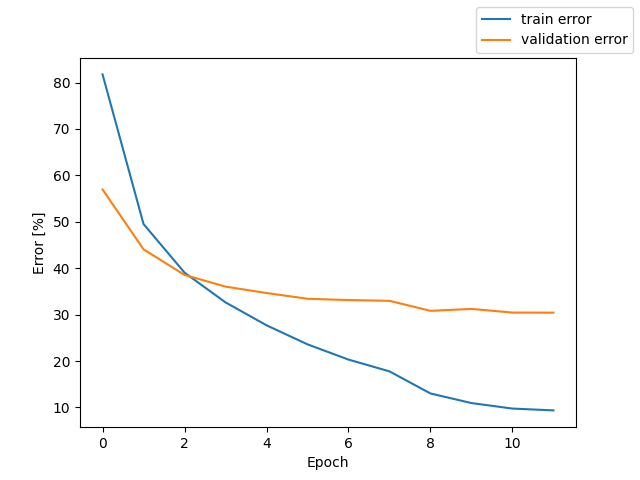
テストでの CER 20.3%
Wav + Feature Extractor + whisper like Transformer Encoder + downsampling + Transformer Decoder + CTCLoss
測定時の Loss と CER のグラフを掲載する。
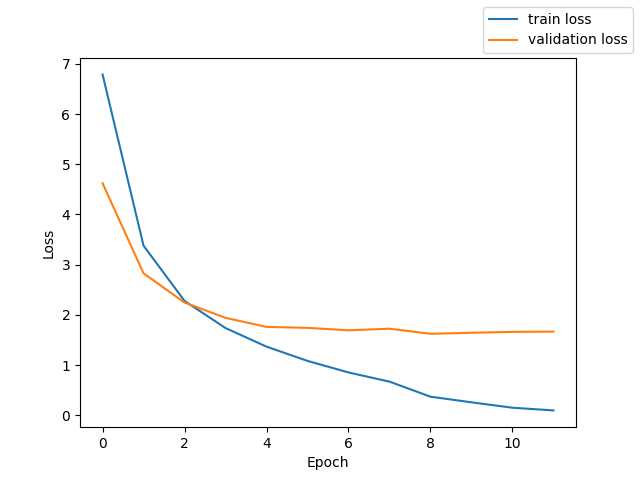
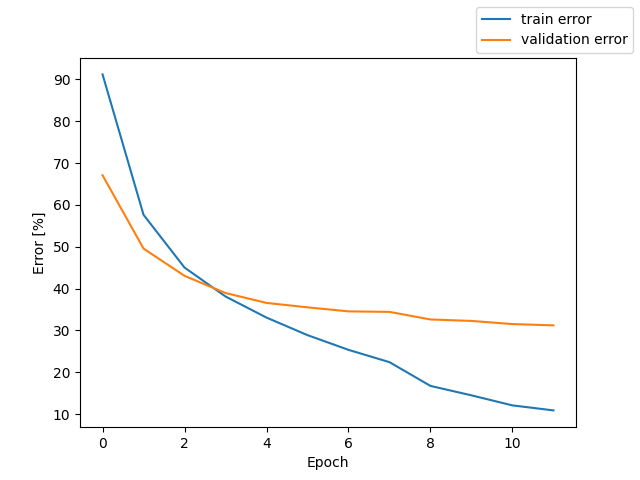
テストでの CER 21.7%
測定に用いたプログラム
測定に用いたプログラムを
に置いておきます。参考になれば幸いです。