学習を行った動機
以前に、CLIP + DENSE CONNECTOR + GPT2 のシステムを v7 データセットでファインチューニングした自己回帰型の画像キャプショニングシステムについてご報告をさせていただきました。
このシステムでは、GPT2 が causal mask を用いて、入力センテンスとこれを一つずらした教師センテンスを用いて事前学習を行っているため、画像キャプショニングのファインチューニングでも、自己回帰型の推論を前提として補助入力キャプションと教師キャプションを一個ずらしてファインチューニングしました。
一方、BERT は、MLM で事前学習しているため、画像キャプションの推論も MASK PREDICT でできるのではと考えました。画像キャプショニングのファインチューニングも教師キャプションに対して MLM に似たファインチューニングを行いました。
ページの後半に、length_predictor なしの報告があります。
ファインチューニングシステム概略
使用させていただいたモジュール
Clip
Clip は、
clip_model_id = "openai/clip-vit-large-patch14-336"
self.clip_model = CLIPVisionModel.from_pretrained(clip_model_id, output_hidden_states = True)
を feature extractor + Encoder として使わせていただきました。
Bert と Tokenizer
Bert は、
model_id = "google-bert/bert-large-uncased"
self.bert = BertModel.from_pretrained( model_id )
tokenizer = BertTokenizer.from_pretrained(model_id)
を使わせていただきました。self.bert を Decoder として使わせていただきました。
Dense Connector
Dense Connector は、
のページを参考にさせていただき、
images = torch.randn( ( 1, 3, img_size, img_size ) )
memory = self.clip_model( images )
memory = memory.last_hidden_stat
clip_dim = memory.size(2)
dim_embedding = 1024
self.dc_linear = nn.Linear( clip_dim * 3, dim_embedding )
def dense_connector(self, memory ):
tmp1 = torch.tensor([], device = self.device )
tmp2 = torch.tensor([], device = self.device )
tmp_full = len( memory.hidden_states )
tmp_half = tmp_full // 2
for i in range( 0, tmp_half ):
tmp1 = torch.cat( [tmp1, memory.hidden_states[i][None]], dim = 0 )
tmp1 = torch.sum(tmp1, dim=0) / tmp_half
for i in range( tmp_half, tmp_full ):
tmp2 = torch.cat( [tmp2, memory.hidden_states[i][None]], dim = 0 )
tmp2 = torch.sum(tmp2, dim=0 ) / ( tmp_full - tmp_half )
tmp3 = torch.cat([tmp1, tmp2], dim=-1)
tmp3 = torch.cat( [ memory.last_hidden_state, tmp3], dim = -1 )
#tmp3 = sel.dc_ln( tmp3 )
tmp3 = self.dc_linear( tmp3 )
return tmp3
を使いました。
Special Tokens
decoder に Bert を使うので、当たり前ですが tokenizer も BertTokenizer を使いました。special tokens は、
[CLS] start of sentence token
[SEP] end of sentence token
[MASK] mask token
[PAD] pad token
として使いました。
BERT への入力
CLIP の出力の hidden_states と last_hidden_state を、DENSE CONNECTOR( sum と 平均と torch.cat したテンソルを nn.Linear 層で第三軸 dim_embedding で調整) と transpose と conv1d (第二軸 seq_length を調整)を使って、[batch, 97, 1024] の tensor としました。これを、memory とします。97 について説明します。memory は、mask されたキャプションに埋め込みを行ったテンソル [ batch, seq_len, 1024 ] と第二軸で torch.cat して bert に入力します。画像関連のテンソルとキャプション関連のテンソルを torch.cat して bertに入力すると考えた時、両者は同じくらいのシーケンス長が良いのではと考えました。v7 のキャプションを bert.tokenizer で encode したときの token の長さの平均が 42 でした。すなわち、seq_len の平均値が 42 です。キャプションのシーケンス長の平均が 42 なのでキャプションのシーケンス長の最大値を 84 に設定しています。一方、Clip の出力のシーケンス長は 577 なので、これをキャプション関連のテンソルのシーケンス長の最大値の 84 に近い値にすることを考えます。memory の 577 を Conv1dの stride でダウンサンプリングすると stride = 6 で 97 になりました。1024 は BERT large の隠れ層の次元です。これに合わせて、padding_mask も作り、BERT の入力としました。
class CaptioningTransformer(nn.Module):
def __init__(self, img_size: int, length_max: int, dim_embedding: int,
vocab_size: int, tokenizer, dropout: float=0.1, model_id: str=''):
super().__init__()
#略
#CLIP
clip_model_id = "openai/clip-vit-large-patch14-336"
self.clip_model = CLIPVisionModel.from_pretrained(clip_model_id, output_hidden_states = True)
# img_size = 336
# dim_embeding = 1024
# vocab_size = len( tokenizer )
images = torch.randn( ( 1, 3, img_size, img_size ) )
memory = self.clip_model( images )
memory = memory.last_hidden_state
img_length = memory.size(1)
clip_dim = memory.size(2)
self.ln_memory = nn.LayerNorm( dim_embedding )
self.emb = nn.Embedding( vocab_size, dim_embedding, padding_idx=tokenizer.pad_token_id )
self.pos_emb = PositionalEmbedding( dim_embedding )
self.dropout = nn.Dropout( dropout )
self.dc_linear = nn.Linear( clip_dim * 3, dim_embedding )
#self.dc_ln = nn.LayerNorm( dim_embedding )
# Down Sampling
#img_length = 577
#length_max = 84
stride = img_length // length_max
self.conv1 = nn.Conv1d( dim_embedding, dim_embedding, 1, stride )
print( "img_length:", img_length )
print( "text_length_max:", length_max )
print( "stride:", stride )
seq_len = self.conv1( memory.transpose(1,2) ).size( 2 )
self.bert = BertModel.from_pretrained( model_id )
# 略
def forward(self, images: torch.Tensor, captions: torch.Tensor, caption_lengths: torch.Tensor ):
self.device = images.device
masked_captions, mask = self.masking( captions, caption_lengths )
memory = self.clip_model( images )
memory = self.dense_connector( memory )
memory = self.dropout( memory )
memory = self.ln_memory( memory )
memory = self.conv1( memory.transpose(1,2) ).transpose(1,2)
emb_caption = self.emb( masked_captions ) * math.sqrt(self.dim_embedding)
emb_caption += self.pos_emb( emb_caption )
bert_in = torch.cat( [memory, emb_caption], dim = 1 )
bert_in_padding_masks = (~(torch.eq( masked_captions, self.pad_token_id ))).float()
bert_in_padding_masks = torch.cat( [torch.ones( memory.shape[:2], device=self.device ), bert_in_padding_masks], dim = 1 )
outputs = self.bert( inputs_embeds = bert_in, attention_mask = bert_in_padding_masks ).last_hidden_state
# 略
教師キャプションから mask されたキャプションを作る関数。
BERT の MLM をモデルにしました。
self.mask_token_id = tokenizer.mask_token_id
self.pad_token_id = tokenizer.pad_token_id
self.max_idx_en = len( tokenizer )
def masking(self, input_x: torch.Tensor, lengths: torch.Tensor) -> tuple[torch.Tensor]:
output = input_x.clone()
masks = torch.zeros_like( output, device=output.device, dtype=torch.bool )
for n in range( output.size(0) ):
all_prob = torch.rand( (1) )
if all_prob > 0.99:
num_mask = lengths[n]
num_arbi = 0
num_nochange = 0
else:
mask_prob0 = torch.rand( (1) )
mask_prob = all_prob * mask_prob0
resi_prob = all_prob * ( 1.0 - mask_prob0 )
arbi_prob = all_prob * ( resi_prob * 0.5 )
nochange_prob = all_prob * ( resi_prob * 0.5 )
num_mask = math.floor( lengths[n].item() * mask_prob )
num_arbi = math.floor( lengths[n].item() * arbi_prob )
num_nochange = math.floor( lengths[n].item() * nochange_prob )
mask_mask = list( random.sample( list(range( 0, lengths[n])), num_mask ))
output[n,mask_mask] = self.mask_token_id
not_mask_mask = [ n for n in range( lengths[n] ) if n not in mask_mask ]
mask_arbi = random.sample( not_mask_mask, num_arbi )
for i in range( lengths[n] ):
if i in mask_arbi:
output[n,i] = torch.randint( 0, self.max_idx_en, size=(1,))
not_mask_arbi = [ n for n in not_mask_mask if n not in mask_arbi ]
mask_nochange = random.sample( not_mask_arbi, num_nochange )
not_mask_nochange = [ n for n in not_mask_arbi if n not in mask_nochange ]
mask = [ False if n in not_mask_nochange else True for n in range(lengths[n]) ]
masks[n,:lengths[n]] = torch.tensor( mask )
return output, masks
推論で mask predict を使う場合は、bert に入力するキャプション部分の初期値の全てが mask トークンなので、[0,1] で一様乱数を発生させた all_prob が 0.99 より大きかったら、全てのトークンを mask トークンで置き換えました。それ以外の場合は、mask_prob0 を [0,1] で一様乱数で発生させ、mask トークンの比率は、all_prob * mask_prob0 としました。任意トークンへの変更比率とトークンを変更しない比率は、all_prob * ( 1 - mask_prob0 ) * 0.5 としました。入力は、[batch, seq_len ] の input_x とその長さ lengths です。長さは、キャプションの pad を除いた長さで、size は [batch] です。出力は、input_x に処理をした output と、[batch, seq_len] の size でマスク位置が True の masks です。
キャプションについての損失
キャプションの損失は、BERT の出力の last_hidden_state の [:,97:,:] と、教師キャプションのクロスエントロピーで計算しました。実際の計算では、マスク位置のみの損失を計算しました。
caption_loss = nn.CrossEntropyLoss( ignore_index = tokenizer.pad_token_id )( outputs.last_hidden_state[:,;97,:][masks], targets[masks] )
です。
length predictor
Mask Predict で推論を行う場合、 BERT に入力する全部 MASK の初期キャプションの長さを決めてやらないと計算できません。推論の際に、長さを重要視せず、最初に seq_len = 100 などで計算を初めて、推論後に文章の終わりを示す [SEP]トークンのあとは、PAD で埋められるようにできないか試行錯誤しました。nn.Embedding で padding_idx を指定せず、損失の計算でクロスエントロピーの ignore_index を指定しない。教師キャプションにかける mask に pad 位置も含める。という設定を試しましたが、学習時の 0.1 エポックくらいから loss が下がらず WER は 100 前後で減少しないという結果でした。そのため、facebookresearch の
を参考に、 length_predictor を導入させていただきました。
def lengths_predictor(self, memory):
x = self.ln_length(memory)
x = self.conv_length( x )
predicted_lengths_logits = torch.matmul( x[:,0,:], self.embed_lengths.weight.transpose(0,1)).float()
predicted_lengths_logits [:,0] += float('-inf')
predicted_lengths = F.log_softmax( predicted_lengths_logits, dim = -1 )
return predicted_lengths
ここで、memory は BERT へ入力するテンソルの一部です。これを layer norm に入れ、第二軸の seq_len について、conv1d の入力チャネルと出力チャネルを用いて [ batch, 97, 1024 ]から [ batch, 1, 1024 ] に変換しています。このテンソル、[batch, 1, 1024] の seq_len = 0 の成分と self.embed_lengths.weight.transpose(0,1), [1024,1024] の matmul を計算して、[batch, 1024] の logits テンソルを作ります。ここで、self.embed_lengths はnn.Embedding(1024, 1024 )の学習パラメーターです。この 1024 が、0 〜 1024 トークンまでの長さを表します。長さ 0 はありえないので、[batch,0] を -inf として、F.log_softmax をとることにより、長さ 0 の確率の log を小さくしています。
オリジナルの length_predictor は、機械翻訳の Mask Predict で使われていました。ソース言語の special token に [length] トークンを導入して、ソースの文章を ["[length]","[CLS]","i","am","a", "cat",".","[SEP]"] などとして、[length] トークンの位置の x[:,0,:] と self.embed_lengths.weight.transpose(0,1) の matmul をとっていました。しかし、今回 x は Clip の出力で、[length] トークンを入れることができなかったので、conv1d の出力を使いました。
長さに関する損失を計算する関数。
def calc_length_loss( predicted_lengths, length_target):
length_lprobs = predicted_lengths
length_loss = -length_lprobs.gather( dim = -1, index=length_target[:,None])
length_loss = length_loss.float().mean()
return length_loss
入力は、予測された長さ logit テンソル[ batch, 1024 ] と実際の教師の長さ[ batch, 1 ] です。戻り値が長さに関する損失です。
全体的な損失
全体的な損失は、計算されたキャプション logits についての損失 caption_loss と計算された長さ logits の損失 length_loos の和として
loss = alpha * loss_caption + ( 1 - alpha ) * length_loss
で計算しました。ここで、alpha = 0.9 としました。
my_decode 関数
WER や BLEU の計算には、数字トークンではなく文字トークンあるいは文章を入力します。すなわち、decode しておかないとなりません。しかし、CrossEntropy 計算時に ignore_index = tokenizer.pad_token_id をしておくと、 [SEP] トークンの後ろが [PAD] トークンで埋められません。tokenizer.decode 関数の skip_special_tokens = True 関数で decode しても、推論した文章の [SEP] トークンのあとのゴミ文字列が現れるようです。そこで、my_decode 関数を作りました。
def my_decode(self, token_list, tokenizer ):
def my_index( l, x ):
if x in l:
return l.index(x)
else:
return -1
if my_index( token_list, tokenizer.sep_token_id ) != -1:
token_list = token_list[:my_index( token_list, tokenizer.sep_token_id )]
else:
token_list = token_list
text = tokenizer.decode( token_list, skip_special_tokens = True )
return text
安定してファインチューニングを行うために注意したこと。
Clip の上流層と Bert の下流層のパラメータの勾配を監視
ファインチューニングがうまく行えない原因に勾配消失が上げられる。勾配消失がおきていないか、Clip の上流層と Bert の下流層の学習パラメータの勾配を監視した。gradient norm のグラフを掲載する。
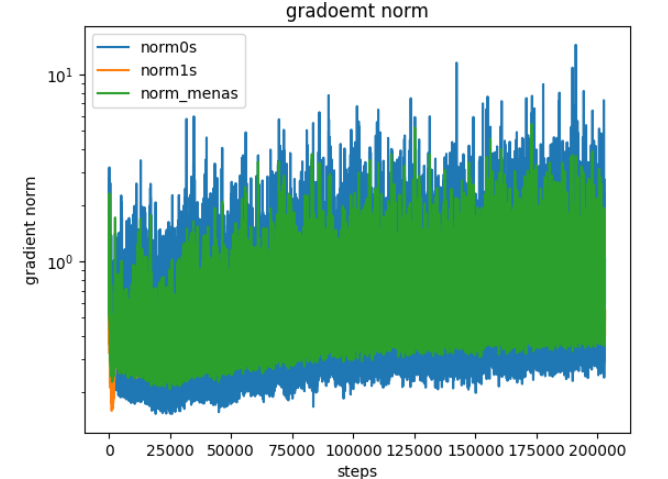
norm0s がclip の上流層で、 norm1s が bert の下流層、norm_means が全パラメーターの勾配の平均です。
#for name, param in model.named_parameters():
# print( name )
norm0 = torch.sqrt( torch.norm( model.clip_model.vision_model.encoder.layers[0].self_attn.q_proj.weight.grad, p = 2 ) ).item()
norm1 = torch.sqrt( torch.norm( model.bert.encoder.layer[23].attention.self.query.weight.grad, p = 2 ) ).item()
norm_mean = torch.mean( torch.stack ([ torch.sqrt( torch.norm( param.grad, p = 2 ) ) for param in model.parameters() if param.grad is not None ] ) ).item()
with open(norm_file, 'a') as f:
print( "epcoch:", epoch, ", step:", global_step, ", norm0:", norm0, ", norm1:", norm1, ", norm_mean:", norm_mean, file=f )
f.flush()
小さめの学習率の設定
小さめの学習率を設定しました。clip の学習率は 2e-7、bert の学習率は 2e-5、その他は 1e-4 としました。
学習率スケジューラーの使用
学習率スケジューラーに
scheduler = get_linear_schedule_with_warmup( optimizer, num_warmup_steps, num_global_steps )
を使いました。学習は 10 epochs で、batch_size = 20, len( train_lodaer ) = 20298 でした。最初の 1 epoch は、学習率が 0 から線形に設定した学習率に増加し、その後 9 epochs で 0 に減少する設定です。
AdamW と weight_decay と betas の設定
オプティマイザーには AdamW を用いました。
params_clip = []
params_bert = []
params_others = []
for name, parameter in model.named_parameters():
if parameter.requires_grad:
if 'clip_model' in name:
params_clip.append(parameter)
elif 'bert' in name:
params_bert.append(parameter)
else:
params_others.append(parameter)
param_groups = [
{'params': params_clip, 'lr': 2e-7},
{'params': params_bert, 'lr': 2e-5},
{'params': params_others, 'lr': 1e-4}
]
optimizer = torch.optim.AdamW( param_groups, weight_decay = 0.01, betas= (0.9, 0.999) )
です。
grad_clip を用いない。
グラジエントクリッピングを用いない。
計算速度を改善するため
計算速度を改善するために AMP と Scaler の設定をしました。
推論関数
推論関数は、3種類を準備しました。
一番オーソドックスな inference 推論関数
preidct_length_beam 関数で、各バッチについて長さの予測値を1つだけ選び、各バッチについて1つだけ推論計算をする inference 関数です。
def predict_length_beam(gold_target_len, predicted_lengths, length_beam_size):
if gold_target_len is not None:
beam_starts = gold_target_len - (length_beam_size - 1) // 2
beam_ends = gold_target_len + length_beam_size // 2 + 1
beam = torch.stack([torch.arange(beam_starts[batch], beam_ends[batch], device=beam_starts.device) for batch in range(gold_target_len.size(0))], dim=0)
else:
beam = predicted_lengths.topk(length_beam_size, dim=1)[1]
beam[beam < 2] = 2
return beam
# 推論モジュール
@torch.no_grad()
def inference( images, tokenizer ):
# batch_size = 1 でお願いします。
length_beam_size = 1
model.eval()
device = images.device
memory = model.clip_model( images )
memory = model.dense_connector( memory )
memory = model.dropout( memory )
memory = model.ln_memory( memory )
memory = model.conv1( memory.transpose(1,2) ).transpose(1,2)
predicted_lengths = model.lengths_predictor( memory )
memory = memory[:,None].expand( -1, length_beam_size, -1, -1 )
memory = memory.view( memory.size(0) * memory.size(1), memory.size(2), memory.size(3) )
beam = predict_length_beam( None, predicted_lengths, length_beam_size )
beam2 = beam.view( beam.size(0) * beam.size(1) )
masked_captions = torch.ones( (beam2.size(0), torch.max( beam2 ) ), dtype=torch.long ) * tokenizer.pad_token_id
for n, length in enumerate( beam2 ):
if int( length ) >= 3:
masked_captions[n,1:beam2[n]] = tokenizer.mask_token_id
masked_captions[n,0] = tokenizer.cls_token_id
masked_captions[n,beam2[n]-1] = tokenizer.sep_token_id
masked_captions[n,beam2[n]:] = tokenizer.pad_token_id
else:
masked_captions[n * length_beam_size * m, 0:1] = tokenizer.mask_token_ie #<end>
emb_caption = model.emb( masked_captions ) * math.sqrt(model.dim_embedding)
emb_caption += model.pos_emb( emb_caption )
bert_in = torch.cat( [memory, emb_caption], dim = 1 )
bert_in_padding_masks = (~(torch.eq( masked_captions, model.pad_token_id ))).float()
bert_in_padding_masks = torch.cat( [torch.ones( memory.shape[:2], device = device ), bert_in_padding_masks], dim = 1 )
iter_max = 10
for i in range( iter_max ):
outputs = model.bert( inputs_embeds = bert_in, attention_mask = bert_in_padding_masks ).last_hidden_state
outputs = outputs[:,memory.size(1):,:]
outputs = model.ln_outputs( outputs )
logits = model.linear( outputs )
probabilities = torch.nn.functional.softmax( logits, dim = 2 )
captions = torch.argmax( logits, dim = 2 )
if i < iter_max - 1:
masked_captions = []
for n in range( outputs.size(0) ):
max_prob = torch.max( probabilities[n,:,:], dim = 1 ).values
sorted_max_prob = torch.sort( max_prob, dim = 0 ).values
masked_caption = captions[n]
num_mask = torch.sum( torch.eq( masked_caption, tokenizer.mask_token_id ).int() )
kosuu_mask = math.floor(( iter_max - i - 1 ) * torch.max( predicted_lengths) / iter_max )
if kosuu_mask - 1 < 0:
kosuu_mask = 1
if num_mask > kosuu_mask:
kosuu_mask = num_mask
thresh = sorted_max_prob[ kosuu_mask - 1 ]
t_indices = max_prob < thresh
masked_caption[t_indices] = tokenizer.mask_token_id
masked_caption[0] = tokenizer.cls_token_id
masked_caption[beam2[n]-1] = tokenizer.sep_token_id
masked_caption[beam2[n]:] = tokenizer.pad_token_id
masked_captions.append( masked_caption )
masked_captions = torch.stack( masked_captions, dim = 0 )
emb_captions = model.emb( masked_captions ) * math.sqrt(model.dim_embedding)
bert_in = torch.cat( [memory, emb_caption], dim = 1 )
bert_in_padding_masks = (~(torch.eq( masked_captions, model.pad_token_id ))).float()
bert_in_padding_masks = torch.cat( [torch.ones( memory.shape[:2], device= device ), bert_in_padding_masks], dim = 1 )
return logits
inference2 関数
長さの予測値を複数採用して計算する inference2 関数です。独自に作成しました。
# 推論モジュール
@torch.no_grad()
def inference2( images, length_beam_size, tokenizer ):
# batch_size = 1 でお願いします。
model.eval()
device = images.device
memory = model.clip_model( images )
memory = model.dense_connector( memory )
memory = model.dropout( memory )
memory = model.ln_memory( memory )
memory = model.conv1( memory.transpose(1,2) ).transpose(1,2)
predicted_lengths = model.lengths_predictor( memory )
memory = memory[:,None].expand( -1, length_beam_size, -1, -1 )
memory = memory.view( memory.size(0) * memory.size(1), memory.size(2), memory.size(3) )
beam = predict_length_beam( None, predicted_lengths, length_beam_size )
beam2 = beam.view( beam.size(0) * beam.size(1) )
masked_captions = torch.ones( (beam2.size(0), torch.max( beam2 ) ), dtype=torch.long ) * tokenizer.pad_token_id
for n, length in enumerate( beam2 ):
if int( length ) >= 3:
masked_captions[n,1:beam2[n]] = tokenizer.mask_token_id
masked_captions[n,0] = tokenizer.cls_token_id
masked_captions[n,beam2[n]-1] = tokenizer.sep_token_id
masked_captions[n,beam2[n]:] = tokenizer.pad_token_id
else:
masked_captions[n * length_beam_size * m, 0:1] = tokenizer.mask_token_ie #<end>
emb_caption = model.emb( masked_captions ) * math.sqrt(model.dim_embedding)
emb_caption += model.pos_emb( emb_caption )
bert_in = torch.cat( [memory, emb_caption], dim = 1 )
bert_in_padding_masks = (~(torch.eq( masked_captions, model.pad_token_id ))).float()
bert_in_padding_masks = torch.cat( [torch.ones( memory.shape[:2], device = device ), bert_in_padding_masks], dim = 1 )
iter_max = 10
for i in range( iter_max ):
outputs = model.bert( inputs_embeds = bert_in, attention_mask = bert_in_padding_masks ).last_hidden_state
outputs = outputs[:,memory.size(1):,:]
outputs = model.ln_outputs( outputs )
logits = model.linear( outputs )
probabilities = torch.nn.functional.softmax( logits, dim = 2 )
captions = torch.argmax( logits, dim = 2 )
max_probs = torch.max( probabilities[:,:,:], dim = 2 ).values
if i < iter_max - 1:
masked_captions = []
for n in range( outputs.size(0) ):
max_prob = torch.max( probabilities[n,:,:], dim = 1 ).values
sorted_max_prob = torch.sort( max_prob, dim = 0 ).values
masked_caption = captions[n]
num_mask = torch.sum( torch.eq( masked_caption, tokenizer.mask_token_id ).int() )
kosuu_mask = math.floor(( iter_max - i - 1 ) * torch.max( predicted_lengths) / iter_max )
if kosuu_mask - 1 < 0:
kosuu_mask = 1
if num_mask > kosuu_mask:
kosuu_mask = num_mask
thresh = sorted_max_prob[ kosuu_mask - 1 ]
t_indices = max_prob < thresh
masked_caption[t_indices] = tokenizer.mask_token_id
masked_caption[0] = tokenizer.cls_token_id
masked_caption[beam2[n]-1] = tokenizer.sep_token_id
masked_caption[beam2[n]:] = tokenizer.pad_token_id
masked_captions.append( masked_caption )
masked_captions = torch.stack( masked_captions, dim = 0 )
emb_captions = model.emb( masked_captions ) * math.sqrt(model.dim_embedding)
bert_in = torch.cat( [memory, emb_caption], dim = 1 )
bert_in_padding_masks = (~(torch.eq( masked_captions, model.pad_token_id ))).float()
bert_in_padding_masks = torch.cat( [torch.ones( memory.shape[:2], device= device ), bert_in_padding_masks], dim = 1 )
mean_prob = torch.zeros( beam2.size(0) )
for n, length in enumerate( beam2 ):
mean_prob[n] = torch.mean( max_probs[n,:length], dim = -1 )
return captions, mean_prob
複数の予測した長さについてキャプションを推論するので、その確率 mean_prob により各バッチについてキャプションを一つ選びます。
length_beam_size = 3
captions2, mean_prob = inference2(imgs, length_beam_size, tokenizer )
bsz = imgs.size(0)
captions2 = captions2.view( bsz, length_beam_size, -1 )
mean_prob = mean_prob.view( bsz, length_beam_size )
best_lengths = mean_prob.max(-1)[1]
captions2 = torch.stack([captions2[b, l, :] for b, l, in enumerate(best_lengths)], dim = 0 )
hypo_ids = captions2
inference3 関数。
長さの予測値を複数採用して計算する inference3 関数。facebookresearch を参考にさせたいただきました。
def duplicate_encoder_out(encoder_out, encoder_padding_mask, decoder_padding_mask, causal_mask, bsz, beam_size):
encoder_out = encoder_out.unsqueeze(1).repeat(1, beam_size, 1, 1 ).view( bsz * beam_size, encoder_out.size(1), encoder_out.size(2))
if encoder_padding_mask is not None:
encoder_padding_mask = encoder_padding_mask.unsqueeze(1).repeat(1,beam_size,1).view(bsz * beam_size, -1 )
if decoder_padding_mask is not None:
decoder_padding_mask = decoder_padding_mask.unsqueeze(1).repeat(1,beam_size,1).view(bsz * beam_size, -1 )
if causal_mask is not None:
causal_mask = causal_mask
return encoder_out, encoder_padding_mask, decoder_padding_mask, causal_mask
def predict_length_beam(gold_target_len, predicted_lengths, length_beam_size):
if gold_target_len is not None:
beam_starts = gold_target_len - (length_beam_size - 1) // 2
beam_ends = gold_target_len + length_beam_size // 2 + 1
beam = torch.stack([torch.arange(beam_starts[batch], beam_ends[batch], device=beam_starts.device) for batch in range(gold_target_len.size(0))], dim=0)
else:
beam = predicted_lengths.topk(length_beam_size, dim=1)[1]
beam[beam < 2] = 2
return beam
def outputs_to_tgt_tokens( outputs, img_seq_len, device ):
outputs = outputs[:,img_seq_len:,:]
outputs = model.ln_outputs( outputs )
logits = model.linear( outputs )
outputs = F.softmax( logits, dim = 2 )
tgt_tokens = torch.argmax( logits, dim = 2 )
token_probs = torch.max( outputs, dim = 2 )[1]
return tgt_tokens, token_probs
def build_bert_in_and_masks( memory, masked_captions):
emb_caption = model.emb( masked_captions ) * math.sqrt(model.dim_embedding)
emb_caption += model.pos_emb( emb_caption )
bert_in = torch.cat( [memory, emb_caption], dim = 1 )
bert_in_padding_masks = torch.ne( masked_captions, model.pad_token_id ).float()
bert_in_padding_masks = torch.cat( [torch.ones( memory.shape[:2], device = device ), bert_in_padding_masks], dim = 1 )
return bert_in, bert_in_padding_masks
# 推論モジュール
@torch.no_grad()
def inference3(
images, length_beam_size, is_inference = True
):
memory = model.clip_model( images )
memory = model.dense_connector( memory )
memory = model.dropout( memory )
memory = model.ln_memory( memory )
memory = model.conv1( memory.transpose(1,2) ).transpose(1,2)
img_seq_len = memory.size(1)
predicted_lengths = model.lengths_predictor( memory )
beam = predict_length_beam( None, predicted_lengths, length_beam_size)
max_len = beam.max().item()
bsz = memory.size(0)
length_mask = torch.triu( memory.new( max_len,max_len).fill_(1).long(),1 )
length_mask = torch.stack([length_mask[beam[batch] - 1 ] for batch in range(bsz)], dim = 0)
tgt_tokens = memory.new( bsz, length_beam_size, max_len ).fill_(model.mask_token_id).long()
tgt_tokens = ( 1 - length_mask ) * tgt_tokens + length_mask * model.pad_token_id
tgt_tokens = tgt_tokens.view( bsz * length_beam_size, max_len )
def select_worst(token_probs, num_mask):
bsz, seq_len = token_probs.size()
masks = [token_probs[batch, :].topk(max(1, num_mask[batch]), largest=False, sorted=False)[1] for batch in range(bsz)]
masks = [torch.cat([mask, mask.new(seq_len - mask.size(0)).fill_(mask[0])], dim=0) for mask in masks]
return torch.stack(masks, dim=0)
def assign_single_value_long(x, i, y):
b, l = x.size()
i = i + torch.arange(0, b*l, l, device=i.device).unsqueeze(1)
x.view(-1)[i.view(-1)] = y
return x
def assign_single_value_byte(x, i, y):
x.view(-1)[i.view(-1).nonzero()] = y
return x
def assign_multi_value_long(x, i, y):
b, l = x.size()
i = i + torch.arange(0, b*l, l, device=i.device).unsqueeze(1)
x.view(-1)[i.view(-1)] = y.view(-1)[i.view(-1)]
return x
encoder_out = memory
encoder_out, _, _, _ = duplicate_encoder_out( encoder_out, None, None, None, bsz, length_beam_size)
bsz, seq_len = tgt_tokens.size()
pad_mask = tgt_tokens.eq(model.pad_token_id)
seq_lens = seq_len - pad_mask.sum(dim=1)
iter_max = 10
masked_captions = tgt_tokens
memory = encoder_out
bert_in, bert_in_padding_masks = build_bert_in_and_masks( memory, masked_captions)
outputs = model.bert( inputs_embeds = bert_in, attention_mask = bert_in_padding_masks ).last_hidden_state
tgt_tokens, token_probs = outputs_to_tgt_tokens( outputs, img_seq_len, encoder_out.device )
tgt_tokens = assign_single_value_byte(tgt_tokens, pad_mask, model.pad_token_id )
token_probs = assign_single_value_byte(token_probs, pad_mask, 1.0)
for counter in range( 1, iter_max ):
num_mask = ( seq_lens.float() * ( 1.0 - ( counter / iter_max))).long()
assign_single_value_byte(token_probs, pad_mask, 1.0)
mask_ind = select_worst(token_probs, num_mask)
tgt_tokens = assign_single_value_long(tgt_tokens, mask_ind, model.mask_token_id)
tgt_tokens = assign_single_value_byte(tgt_tokens, pad_mask, model.pad_token_id)
masked_captions = tgt_tokens
bert_in, bert_in_padding_masks = build_bert_in_and_masks( memory, masked_captions)
outputs = model.bert( inputs_embeds = bert_in, attention_mask = bert_in_padding_masks ).last_hidden_state
new_tgt_tokens, new_token_probs = outputs_to_tgt_tokens( outputs, img_seq_len, encoder_out.device )
token_probs = assign_multi_value_long(token_probs, mask_ind, new_token_probs)
token_probs = assign_single_value_byte(token_probs, pad_mask, 1.0)
tgt_tokens = assign_multi_value_long(tgt_tokens, mask_ind, new_tgt_tokens)
tgt_tokens = assign_single_value_byte(tgt_tokens, pad_mask, model.pad_token_id)
lprobs = token_probs.log().sum(-1)
return tgt_tokens, lprobs, max_len, length_mask
複数の予測した長さについてキャプションを推論するので、その log 確率 lprobs により各バッチについてキャプションを一つ選びます。
length_beam_size = 3
preds, lprobs, max_len, length_mask = inference3( imgs, length_beam_size )
hypotheses = preds
bsz = imgs.size(0)
hypotheses = hypotheses.view(bsz, length_beam_size, max_len)
lprobs = lprobs.view(bsz, length_beam_size)
tgt_lengths = (1 - length_mask).sum(-1)
avg_log_prob = lprobs / tgt_lengths.float()
best_lengths = avg_log_prob.max(-1)[1]
hypotheses = torch.stack([hypotheses[b, l, :] for b, l in enumerate(best_lengths)], dim=0)
pred = torch.squeeze( hypotheses, dim = 0 )
hypo_ids = [pred]
計算結果
ファインチューニングの loss, WER, BLEU
ファインチューニング時の caption loss, length loss, loss, WER, BLEU のグラフを掲載します。
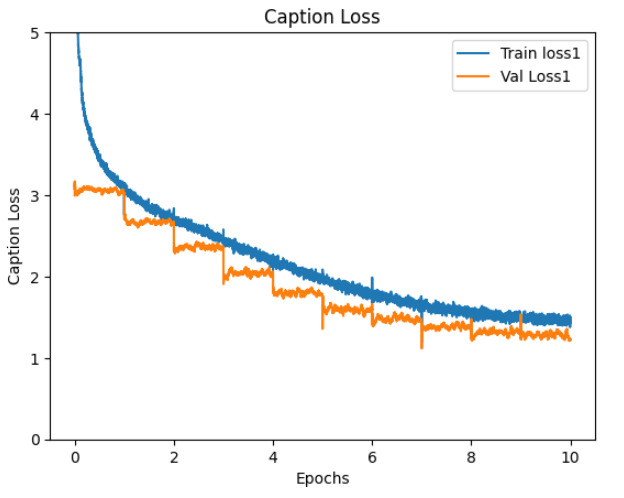

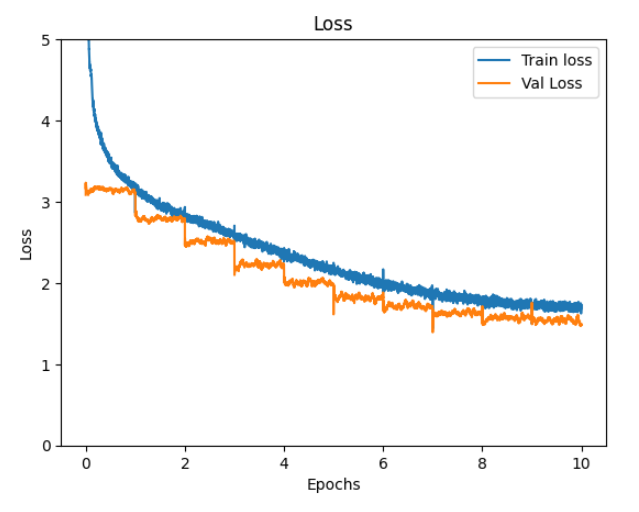
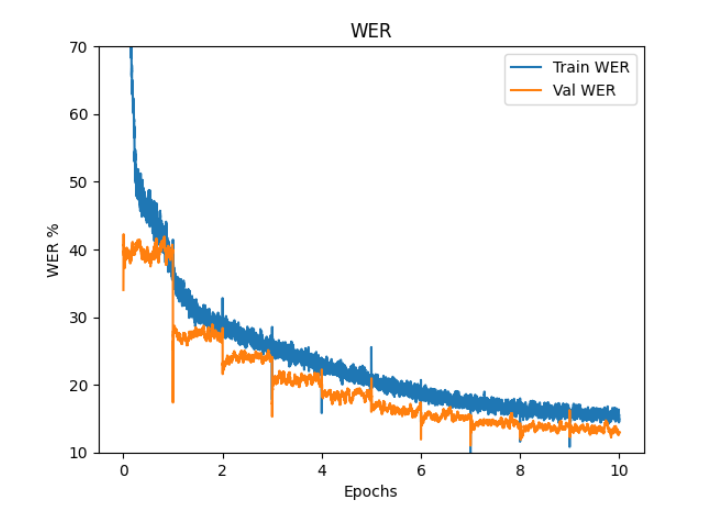
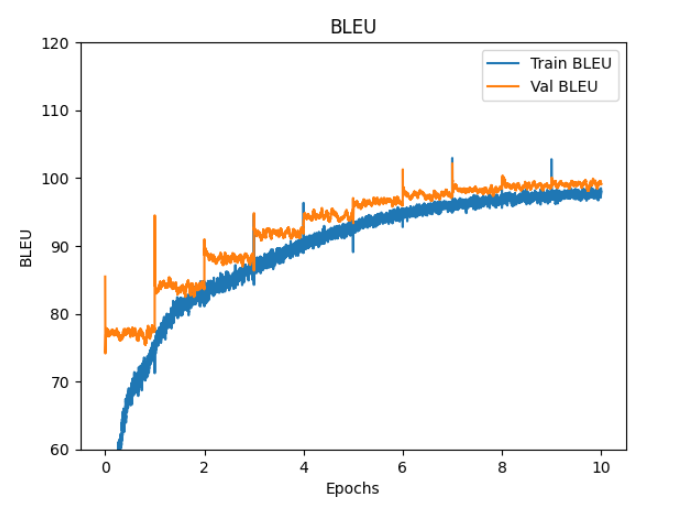
epoch 10 での train と val の loss と WER
loss WER BLEU
train 1.73 15.5 97.7
val 1.49 13.0 99.1
epoch 10 でのテスト結果。
各推論関数で計算した WER と BLEU です。 21 テストデータについての平均です。
WER BLEU
inference2 86.9 41.8
inference3 113.8 45.7
inference1 119.7 37.8
inferece2 での caption 結果をご報告させていただきます。
this pic. WER : 75.0
this pic. BLEU: 64.70489139970005
test number = 0 average, WER = 75.0, BLEU = 64.70489501953125
refe: in this i can see there are red colored strawberries.
hypo: in this image we can see strawberriesberriess on the table.

this pic. WER : 159.0909090909091
this pic. BLEU: 31.894430839533815
test number = 1 average, WER = 117.04545593261719, BLEU = 48.29966354370117
refe: there are few persons sitting on the chairs. here we can see monitors, keyboards, tables, and devices.
hypo: in this image we can see a sitting sitting sitting sitting the the the the the the the the the the the the the the the the the the the the the the, there on the wall.

this pic. WER : 89.28571428571429
this pic. BLEU: 36.8408644179049
test number = 2 average, WER = 107.79220581054688, BLEU = 44.48006057739258
refe: this image is taken outdoors. at the bottom of the there is a floor. in the background there are a few buildings with walls, windows and balconies. in the middle of the image two men and a woman are standing on the floor and they are with smiling faces.
hypo: in this image we can see three persons standing standing and and and and and the the the the the the the the the the the the the the the there is a building.

this pic. WER : 78.94736842105263
this pic. BLEU: 46.658235048402695
test number = 3 average, WER = 100.58099365234375, BLEU = 45.02460479736328
refe: in this image in front there are plants. in the background of the image there is sky.
hypo: in this image we can see flowers flowers flowers flowers flowers and.. in the the the the sky sky the sky.

this pic. WER : 110.5263157894737
this pic. BLEU: 57.57386768707436
test number = 4 average, WER = 102.57005310058594, BLEU = 47.53445816040039
refe: this is a black and white image. in this image we can see women wearing spectacles.
hypo: in this image black can white a woman wearing a woman and and and the the the the the is is is background.

this pic. WER : 80.95238095238095
this pic. BLEU: 41.6473742217379
test number = 5 average, WER = 98.96712493896484, BLEU = 46.55327224731445
refe: as we can see in the image there is a white color plate. in plate there is a dish.
hypo: in this image we can see some food item on the plate.

this pic. WER : 82.35294117647058
this pic. BLEU: 12.932296817152414
test number = 6 average, WER = 96.59366607666016, BLEU = 41.75027847290039
refe: this image is clicked in a musical concert where there is a woman standing and she is holding a guitar in her hand. she is wearing black color dress. there is a mic in front of her and there is a bottle. she is holding a stick. there are speakers back side and there are some musical instruments on the bottom left corner.
hypo: in this image we can see a woman is a guitar and and and a..... a a a a a a a a the the the the the the a a is a wall.

this pic. WER : 66.66666666666666
this pic. BLEU: 67.76053712135516
test number = 7 average, WER = 92.85279083251953, BLEU = 45.00156021118164
refe: in this image, we can see a black color dog, there is a blurred background.
hypo: in this image we can see a dog dog the the the the the the background is is blurred.

this pic. WER : 112.5
this pic. BLEU: 52.731369012375175
test number = 8 average, WER = 95.03581237792969, BLEU = 45.86042785644531
refe: in this picture there is a bowl and a plate in the center of the image, which contains food items in it.
hypo: in this image we can see a food on a plate,,,,,,,, and and and and and and the the the a is on a table.

this pic. WER : 82.05128205128204
this pic. BLEU: 7.19945121243371
test number = 9 average, WER = 93.73736572265625, BLEU = 41.994327545166016
refe: in this picture i can observe some food places in the plate. the food is in brown, orange, green and red colors. it is looking like a burger. the background is completely blurred.
hypo: in this image we can see a food item is on the plate.

this pic. WER : 74.46808510638297
this pic. BLEU: 42.06723085411382
test number = 10 average, WER = 91.98561096191406, BLEU = 42.00095748901367
refe: in this image i can see a person standing wearing a black shirt, blue jeans and glasses. he is holding a electronic gadget in his hand. in the background i can see few people standing, and the ceiling of the building.
hypo: in this image we can see a people standing standing and and and and a a a a a the the the the the the the the the the the the the the the there is a wall.

this pic. WER : 108.8235294117647
this pic. BLEU: 35.25360605251009
test number = 11 average, WER = 93.38876342773438, BLEU = 41.43867874145508
refe: in this image we can see cars, people, banners, hoardings, tent, pole, trees, boards, and buildings. in the background there is sky.
hypo: in this image we can see a are, the the the the the the the the the the the the the the the the the the the the the the,,,,,,,, the the the the the the the, there sky the sky.

this pic. WER : 71.875
this pic. BLEU: 57.523976624204685
test number = 12 average, WER = 91.73385620117188, BLEU = 42.67601013183594
refe: in this image we can see two persons standing and holding the objects, there are some stones, grass, plants and trees, also we can see the sky.
hypo: in this image we can see two persons standing standing and and and holding holding holding holding holding holding the the the the the the the the the the the the there there the trees.

this pic. WER : 80.95238095238095
this pic. BLEU: 22.23911599682565
test number = 13 average, WER = 90.96375274658203, BLEU = 41.21623611450195
refe: in front of the image there are some engravings on the headstone, around the headstone on the surface there are green leaves and dry leaves and sticks, behind the headstone there are trees and a wall.
hypo: in this image we can see a stone on the the the the the the the the there there the plants.

this pic. WER : 100.0
this pic. BLEU: 39.488079232775256
test number = 14 average, WER = 91.56616973876953, BLEU = 41.10102462768555
refe: in this picture i can see building and few trees and a cloudy sky.
hypo: in this image we can see a wall, wall, the the the the the there sky the sky.

this pic. WER : 97.05882352941177
this pic. BLEU: 40.729808409913666
test number = 15 average, WER = 91.90945434570312, BLEU = 41.07781982421875
refe: in this image there are many people in front of the building. some of them are holding camera. in the background there are buildings. there is a banner over here.
hypo: in this image we can see a people people people the the the the the the the the the the the the the the the the the the the the the the the the the there is the sky.

this pic. WER : 66.66666666666666
this pic. BLEU: 44.652652321685615
test number = 16 average, WER = 90.42459106445312, BLEU = 41.28810501098633
refe: in this image i can see a snake on the ground. it is in black color. i can see few wooden sticks, few stones and grass.
hypo: in this image we can see a snake on the the the the the the the there on the ground.

this pic. WER : 70.83333333333334
this pic. BLEU: 46.564834533117704
test number = 17 average, WER = 89.336181640625, BLEU = 41.58125305175781
refe: in this image we can see a person standing and holding a book and to the side we can see a podium with mic and there is a laptop and some other objects on the table. we can see a person standing in the bottom right.
hypo: in this image we can see a woman standing standing standing and and a a a a a a a a a a a a a the the the the the the the the the there is a curtain.

this pic. WER : 75.86206896551724
this pic. BLEU: 32.23561851247666
test number = 18 average, WER = 88.62701416015625, BLEU = 41.089378356933594
refe: in this picture i can see 2 women in front and the women right is holding a brush in her hand and i see the paint on the face of the woman on the left and in the background i see the grass and on the top left of this image i see the blue color things.
hypo: in this image we can see two woman. woman woman the the the the the the the the the the the the the the the background is the grass.

this pic. WER : 67.74193548387096
this pic. BLEU: 47.3207124860853
test number = 19 average, WER = 87.582763671875, BLEU = 41.400943756103516
refe: in this image we can see an animal, water, rocks, and leaves. at the bottom of the image we can see a person who is truncated.
hypo: in this image we can see a animal in a the the the the the the the the the the the the the the there there the trees.

this pic. WER : 73.80952380952381
this pic. BLEU: 48.82781090482512
test number = 20 average, WER = 86.92689514160156, BLEU = 41.75460433959961
refe: in this image we can see three people, one of them is wearing a backpack, in front of them, we can see some bags, box, also we can see some plants, grass, and trees.
hypo: in this image we can see three persons standing standing standing and and and and and and and and and the the the the the the the the the the the, trees and and trees.

test 21 average WER : 86.92690122346679
test 21 average BLEU: 41.754607795533516
計算に用いたプログラムを github に置いておきます。
よろしくお願いいたします。
画像キャプショニングにおける今回のシステムの問題点。
ネットの解説で、mask prediction では、生成する文章の長さが問題になる。これを解決するには、pad を用いるか length predictor を学習させる手法が用いられるとのことです。今回、pad でうまくキャプションを生成できなかったので、length predictor を導入させていただきました。結果を見ると、訓練時の WER と BLEU に比べて、テスト時に生成したキャプションの品質が悪いです。これは、長さの予測がうまくいっていないことも一因として考えられます。しかし、キャプションの長さは、キャプションをつくる人の主観によって決まる可能性が高く、Clip の出力からキャプションの長さを予測することはかなり困難だと感じています。もう一度、pad でうまくいかないか試す価値はあるかもしれません。
TO DO
nn.Embedding の padding_idx を指定しないこと。クロスエントロピーロスの ignore_index に tokenizer.pad_token_id を指定しないこと。教師キャプションに mask をかける時、pad 位置も含めること。ここまでは実行済み。padding の attention mask を使わない。Bert に入力する attention マスクを None にする。教師キャプションとマスクされたキャプションすべての長さを PAD を用いて固定長にする。inference の時にこの固定長の MASK キャプションから始める。
TO DO の結果
TO DO の結果をご報告させていただきます。プログラムは、上記 github の without_length_predictor フォルダに置いておきます。
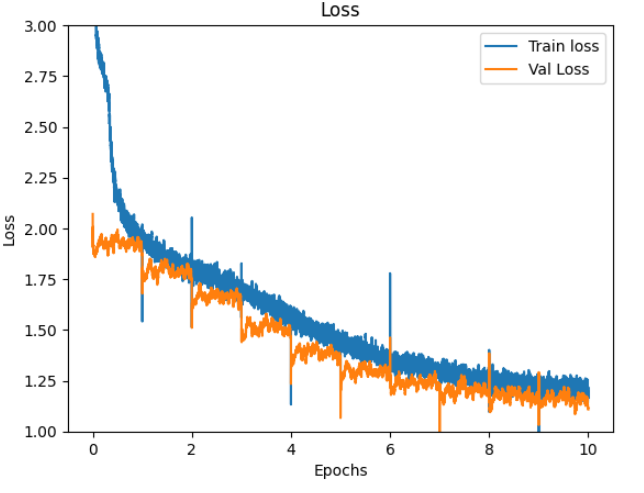
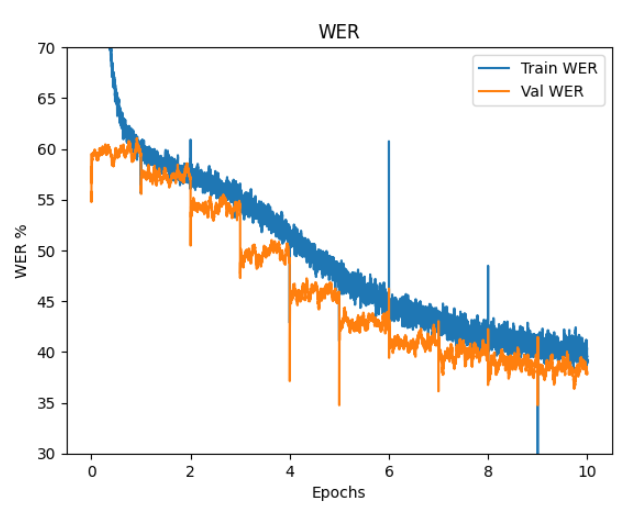
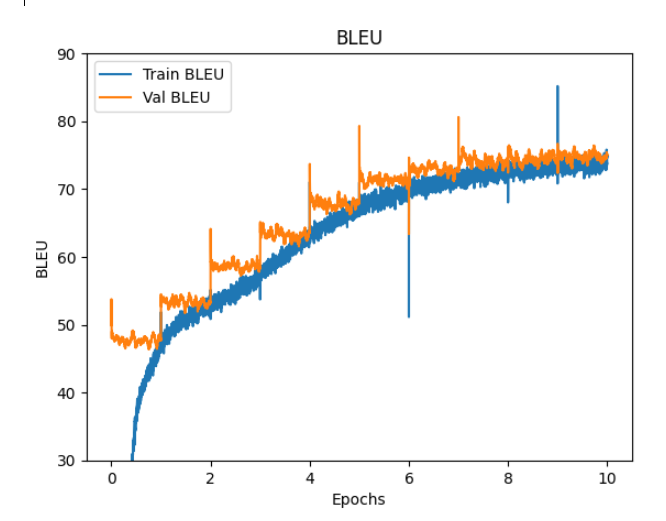
Loss, WER, BLEU
epoch 10 の train val。 length_predictor ありの測定とはパラメーターが違うので直接比較できません。all_prob = torch.rand( (1) ) と mask_prob0 = torch.rand( (1) ) が、all_prob = torch.normal( 0.8, 0.2) と mask_prob0 = torch.normal( 0.8, 0.2 )になっています。
loss WER BLEU
train 1.18 39.2 74.8
val 1.11 37.9 75.1
Loss, WER, BLEU のグラフを掲載します。
epoch9, 10 での TEST 結果
WER BLEU
epoch 9 74.0 31.3
epoch 10 73.6 27.6
生成したキャプション
epoch 10 の学習が終了したあとに生成したキャプションです。
hypo: in this image we can see some strawberries the table surface.
refe: in this i can see there are red colored strawberries.
this pic. WER : 0.6666666666666666
this pic. BLEU: 0.6247616030574529
test number = 1 average, WER = 0.6666666865348816, BLEU = 0.6247615814208984

hypo: in this image i can see few people sitting sitting on the..
refe: there are few persons sitting on the chairs. here we can see monitors, keyboards, tables, and devices.
this pic. WER : 0.8636363636363636
this pic. BLEU: 0.31947446576212973
test number = 2 average, WER = 0.7651515007019043, BLEU = 0.4721180200576782

hypo: in this image we can see three persons standing on the the floor. buildings buildings.
refe: this image is taken outdoors. at the bottom of the there is a floor. in the background there are a few buildings with walls, windows and balconies. in the middle of the image two men and a woman are standing on the floor and they are with smiling faces.
this pic. WER : 0.8928571428571429
this pic. BLEU: 0.11606282923096954
test number = 3 average, WER = 0.8077200055122375, BLEU = 0.3534329831600189

hypo: in this image we can see some,, flowers, plants, sky the the clouds.
refe: in this image in front there are plants. in the background of the image there is sky.
this pic. WER : 0.7894736842105263
this pic. BLEU: 0.45279990304290557
test number = 4 average, WER = 0.8031584620475769, BLEU = 0.37827470898628235

hypo: in this image we can see a woman wearing aggles.
refe: this is a black and white image. in this image we can see women wearing spectacles.
this pic. WER : 0.631578947368421
this pic. BLEU: 0.45330009958839473
test number = 5 average, WER = 0.7688425779342651, BLEU = 0.3932797908782959

hypo: in this image we can see some food in the plate plate.
refe: as we can see in the image there is a white color plate. in plate there is a dish.
this pic. WER : 0.8095238095238095
this pic. BLEU: 0.4792515333256459
test number = 6 average, WER = 0.7756227850914001, BLEU = 0.40760841965675354

hypo: in this image i can see a woman is standing and a guitar in a
refe: this image is clicked in a musical concert where there is a woman standing and she is holding a guitar in her hand. she is wearing black color dress. there is a mic in front of her and there is a bottle. she is holding a stick. there are speakers back side and there are some musical instruments on the bottom left corner.
this pic. WER : 0.8676470588235294
this pic. BLEU: 0.01311929651057275
test number = 7 average, WER = 0.7887691259384155, BLEU = 0.35125282406806946

hypo: in this image we can see a dog.
refe: in this image, we can see a black color dog, there is a blurred background.
this pic. WER : 0.5
this pic. BLEU: 0.24153871270205204
test number = 8 average, WER = 0.7526729702949524, BLEU = 0.33753857016563416

hypo: in this image we can see food items on a plate.
refe: in this picture there is a bowl and a plate in the center of the image, which contains food items in it.
this pic. WER : 0.7916666666666666
this pic. BLEU: 0.2416736801845192
test number = 9 average, WER = 0.7570055723190308, BLEU = 0.326886922121048

hypo: in this image we can see a food item the plate plate.
refe: in this picture i can observe some food places in the plate. the food is in brown, orange, green and red colors. it is looking like a burger. the background is completely blurred.
this pic. WER : 0.8205128205128205
this pic. BLEU: 0.07036031350037669
test number = 10 average, WER = 0.7633563280105591, BLEU = 0.30123424530029297

hypo: in this image we can see a group standing people some floor and
refe: in this image i can see a person standing wearing a black shirt, blue jeans and glasses. he is holding a electronic gadget in his hand. in the background i can see few people standing, and the ceiling of the building.
this pic. WER : 0.8085106382978723
this pic. BLEU: 0.07395890302600679
test number = 11 average, WER = 0.7674612402915955, BLEU = 0.2805728614330292

hypo: in this image we can see buildings, banners,,, banners,,,, sky and..
refe: in this image we can see cars, people, banners, hoardings, tent, pole, trees, boards, and buildings. in the background there is sky.
this pic. WER : 0.5294117647058824
this pic. BLEU: 0.345430104276125
test number = 12 average, WER = 0.7476237416267395, BLEU = 0.28597763180732727

hypo: in this image we can see two standing standing and holding a gun. the we there are trees and and..
refe: in this image we can see two persons standing and holding the objects, there are some stones, grass, plants and trees, also we can see the sky.
this pic. WER : 0.625
this pic. BLEU: 0.5596540422693415
test number = 13 average, WER = 0.7381911873817444, BLEU = 0.307029664516449

hypo: in this image we can see a stone, plants, and and..
refe: in front of the image there are some engravings on the headstone, around the headstone on the surface there are green leaves and dry leaves and sticks, behind the headstone there are trees and a wall.
this pic. WER : 0.8571428571428571
this pic. BLEU: 0.03473874000754297
test number = 14 average, WER = 0.7466877102851868, BLEU = 0.28758031129837036

hypo: in this image we can see a,, trees, sky and sky clouds.
refe: in this picture i can see building and few trees and a cloudy sky.
this pic. WER : 0.6
this pic. BLEU: 0.5413609128079863
test number = 15 average, WER = 0.7369085550308228, BLEU = 0.3044990003108978

hypo: in this image we can see a group of people standing and holding the background we there some buildings.
refe: in this image there are many people in front of the building. some of them are holding camera. in the background there are buildings. there is a banner over here.
this pic. WER : 0.7352941176470589
this pic. BLEU: 0.4571905521725783
test number = 16 average, WER = 0.7368077039718628, BLEU = 0.31404221057891846

hypo: in this image we can see a snake on the and...
refe: in this image i can see a snake on the ground. it is in black color. i can see few wooden sticks, few stones and grass.
this pic. WER : 0.6
this pic. BLEU: 0.20100947378845824
test number = 17 average, WER = 0.7287602424621582, BLEU = 0.30739325284957886

hypo: in this image we can see a woman standing and holding a paper. her there is see a..
refe: in this image we can see a person standing and holding a book and to the side we can see a podium with mic and there is a laptop and some other objects on the table. we can see a person standing in the bottom right.
this pic. WER : 0.6666666666666666
this pic. BLEU: 0.19437398934385508
test number = 18 average, WER = 0.7253105640411377, BLEU = 0.30111441016197205

hypo: in this image we can see two women.
refe: in this picture i can see 2 women in front and the women right is holding a brush in her hand and i see the paint on the face of the woman on the left and in the background i see the grass and on the top left of this image i see the blue color things.
this pic. WER : 0.896551724137931
this pic. BLEU: 0.0019152827775531266
test number = 19 average, WER = 0.7343232035636902, BLEU = 0.28536707162857056

hypo: in this image we can see a bear bear and the water.
refe: in this image we can see an animal, water, rocks, and leaves. at the bottom of the image we can see a person who is truncated.
this pic. WER : 0.7096774193548387
this pic. BLEU: 0.2028533308805255
test number = 20 average, WER = 0.7330909967422485, BLEU = 0.28124135732650757

hypo: in this image we can see three standing standing on the ground,.
refe: in this image we can see three people, one of them is wearing a backpack, in front of them, we can see some bags, box, also we can see some plants, grass, and trees.
this pic. WER : 0.7857142857142857
this pic. BLEU: 0.16172690339062004
test number = 21 average, WER = 0.735596776008606, BLEU = 0.2755502164363861

test 21 average WER : 0.7355967920920637
test 21 average BLEU: 0.2755502224593148
よろしくお願いいたします。