環境
Consul Server(0.5.2) x 3
Consul Agent(0.5.2) x 数十台
現象
とある日、プロダクトのConsulクラスタ管理下のサーバがちょいちょいアラート出すので
Consulログを確認するとノードが数分間隔で EventMemberFailed と EventMemberJoin を繰り返していた。
特に特定のノード、というわけでもなく、ランダムにノードがFailし、数十秒後にJoinし直す、というログがひっきりなしに出力されていた。
「consul flapping」でぐぐってみると、いくつか同じような現象で悩んでいる事案があるようだった。
原因となったサーバ
ほぼ全てのノードがflapping状態だったので原因つかめず途方に暮れていたが、この投稿 で
memberlist: Refuting a suspect message (from: a-01)
のfromのサーバを見るといいよ、とあったのでgrepしてみるとビンゴ。
そのサーバにログインしてみると動作がめっちゃ重い。
ただ、topやvmstatでみても過負荷ではないし特に原因は見当たらず…
しかしEC2のステータスを見るとなんか定期的にFailしてたのでサーバ自体がなんかおかしかった様子。
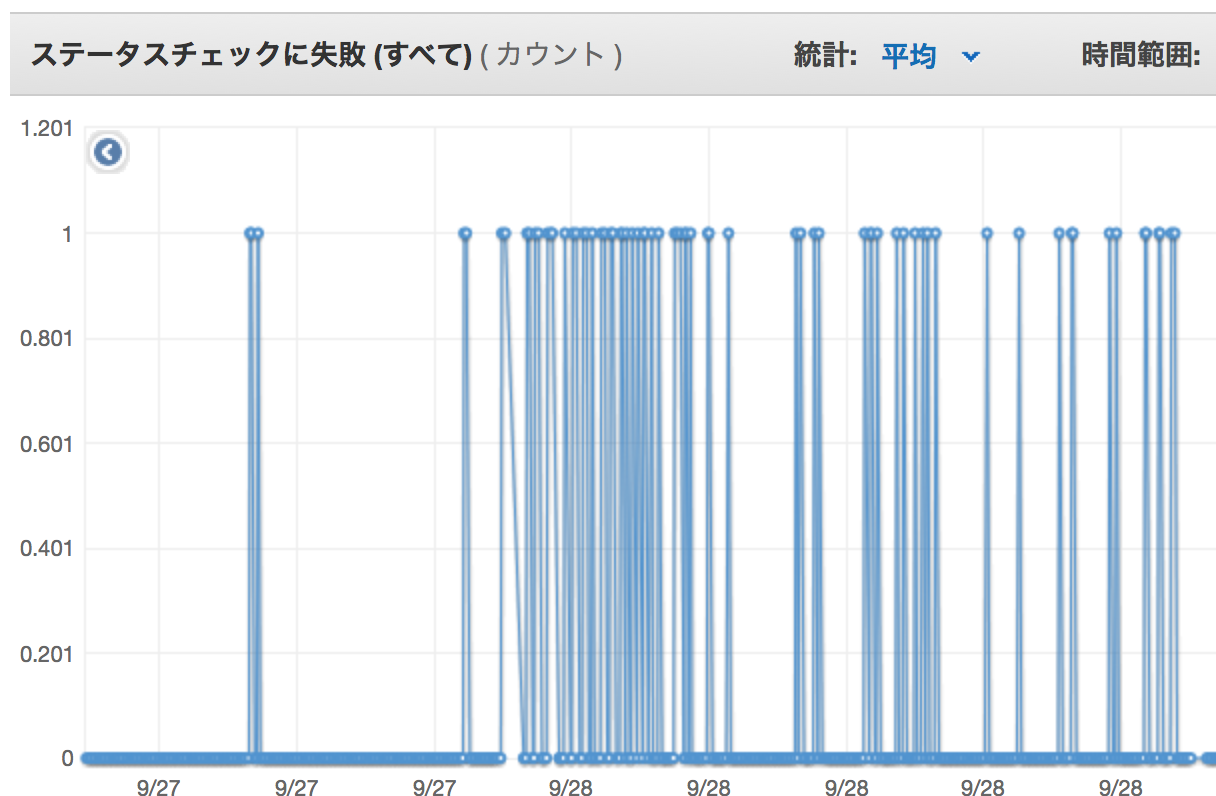
復旧
原因となったEC2 stop>start でインスタンスリフレッシュしたらサーバが正常に戻り
全てのサーバログに出力されていたRejoinのログもピタリと止まり、
クラスタ全体も安定稼働に戻った。
Agentサーバが不安定になった根本的な原因?
よくわかってないけど、2つの可能性を考えてみた。
- EC2自体がおかしくなってリタイアする予定だった?
- 通知は来てないけど、たまにあるし…
- I/O クレジット食いつぶしてた?
- t2.microだったし、しばらく起動しっぱなしだったし、ネットワークも定期的に使われてたので、I/Oクレジットがなくなって不安定になった説。 ※そもそもこれ(I/Oクレジット残)確認する方法あるんだっけ?
まとめ
Agentの1台のネットワークが不安定になると、全体的に不安定になるのちょっと怖いなーと思いました。
常に監視しといて、怪しいサーバはforce-leaveで切り離すとかしないといけないのだろうか…
もう少しマジメに監視する必要ありそう