はじめての技術記事!!!!
よわよわ情報系学生ちなっちゃん(@toremolo72)です.大学卒業まであと1年,プログラミングをもっと頑張ってから卒業したい!ということでやってみたこととかはまとめていきたいなと思います!
概要
colabだけで完結させる単語のつながりネットワークの可視化
colabで,Google Scholarから得られる書誌情報(タイトル,著者名など)を形態素解析したデータを使って,共起ネットワーク(単語のつながりネットワーク)を可視化します.
想定読者
- 何か見て楽しいものを簡単に作ってみたい初心者の人(printとかif文とかはわかるよっていうレベルで🙆♀️)
- colabのファイルを作って実行することができる人
- ネットワーク分析したいデータがある人
単語のつながりネットワークを可視化すると嬉しいこと
- シンプルにみてて楽しい
- 自分の興味ある内容にまつわる面白そうな単語を簡単に見つけられる
- ネットワークのクラスターができると,なんとなくその分野がわかってくる
- 論文のサーベイをするときにとても役立つ
目次
- ネットワーク分析をやるに至った経緯
- 共起ネットワークとは?
- colabだけで共起ネットワークを作ってみる
- データを準備する(今回はOctparseを使用)
- MeCabで形態素解析+Pythonでデータ整備
- Networkxで共起行列と共起ネットワーク定義+Pyvisで可視化
ネットワーク分析をやるに至った経緯
所属している筑波大学情報メディア創成学類の3年生の実験科目で取り組みました!いろんなテーマ(ビジュアルプログラミングとか自然言語処理とかハードウェア開発とか他にも色々)から選択制で,ソーシャルネットワーク分析を選択して取り組んだ内容です.
授業の前半は知識のインプットがメインでしたが,後半は自分でテーマを決めて実践してみる感じだったので,テーマを「自分の研究テーマに関する書誌情報を使って単語のつながりを可視化する」に設定しました.
共起ネットワークとは?
関連する言葉を点(ノード)として表し,それらがどのように関連しているかを線(エッジ)で結んだものです.
例えば,「夏休み」という言葉を聞くと,「海」「旅行」「花火」といった言葉が頭に浮かぶかもしれません.これらの言葉は,「夏休み」という言葉と共によく使われる言葉です.この関係性を表したものが共起ネットワークと呼ばれています.
このネットワークをグラフィカルに表現することで,ある言葉が他のどの言葉と関係が深いか,どのような文脈でよく使われるかが視覚的に分かります.
colabだけで共起ネットワークを作ってみる
手順としては,①書誌情報を取得 ②「単語」にまとめる ③ネットワークの定義 ④可視化,という感じです!この記事では②〜④についてがメインです.

データを準備する
ここはcolabでやってません!
スクレイピングだけ全然できなくて,Octoparseというスクレイピングソフトウェアを使用しました🥺 とても使いやすかったです!無料で使えました.カスタマイズモードで,Google Scholarから書誌のタイトル・著者・書誌へのリンクなどを引っ張ってきました.私は「湿板写真」というキーワードで検索した結果を使用しました.大体600件くらいのデータになりました.
参考:Google Scholarの検索結果をスクレイピングする
こんな感じで集まりました↓
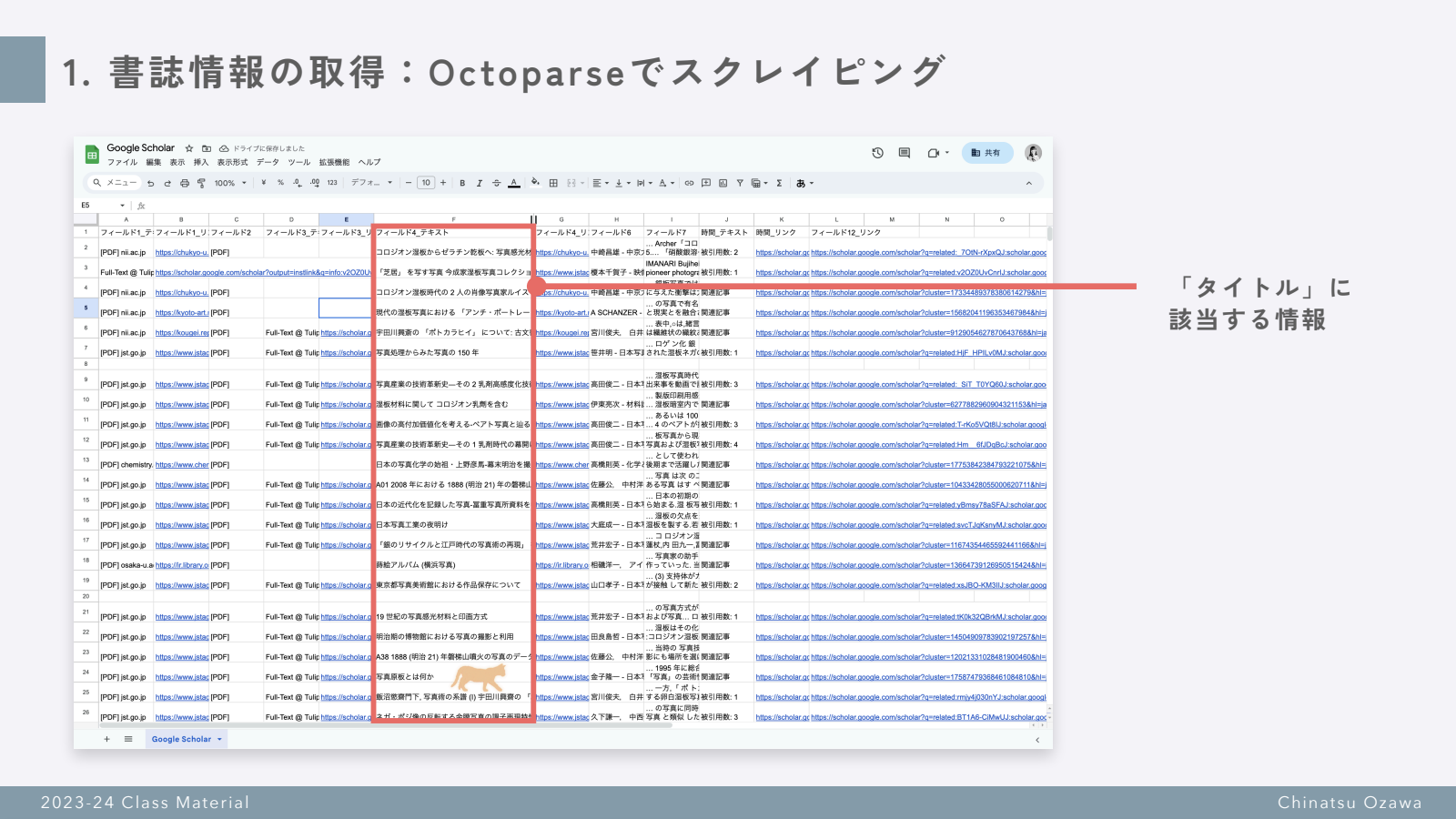
データをCSVで準備したら早速ネットワークを作る作業にはいります!
MeCabで形態素解析
CSVでデータを準備したら,colabのファイルを作ります.GoogleDriveでcolaboratoryを開いたら,左のファイルアイコンをクリックしてCSVファイルをアップロードします.
sample.csvをアップロードするとしたら,こうなってればOK!↓
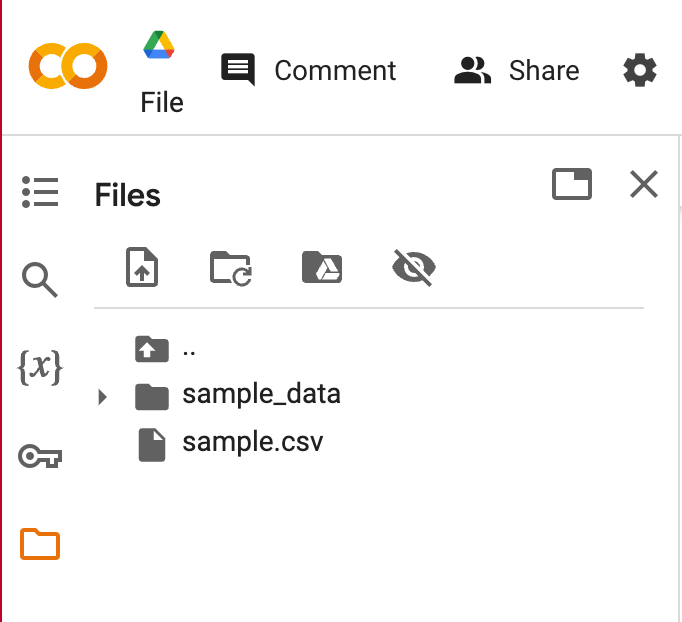
ファイルを入れたら,コードブロックに以下のコードを貼り付けます.
このimport ~は,お道具箱みたいなものです.「DIYをしてドライバーやネジなどの道具を持ってきて,それらを使って家具を作る」といった時の,ドライバーやネジなどの道具を持ってくることが,import ~にあたります.
import pandas as pd
! pip install mecab-python3 unidic-lite
import MeCab
import time
貼り付けたら,コードブロックの左上にある▶️ボタンをおして実行します.緑色でOKみたいになったら大丈夫です!
次に,左上にある+Codeをおして新しくコードブロックを出します.

新しいコードブロックに,以下のコードを貼り付けてください.
# CSVファイルを読み込む
def read_csv(file_path, column_name):
df = pd.read_csv(file_path)
return df[column_name].tolist()
# 形態素解析モデルの構築
t = MeCab.Tagger()
# CSVファイルのパスと解析したい列の名前を指定
file_path = 'ファイル名.csv' # CSVファイルのパス
column_name = '列の名前' # 解析したい列の名前
# CSVファイルから文章を読み込む
sentences = read_csv(file_path, column_name)
# 出力ファイルの設定
output_file = 'mecab_output.txt'
# 形態素解析の実行とファイルへの書き込み
with open(output_file, 'w', encoding='utf-8') as file:
for sentence in sentences:
sentence = str(sentence).lower()
tokens = t.parse(sentence)
file.write(tokens)
print(f"形態素解析結果を {output_file} に保存しました。")
貼り付けたら,以下の部分の'を残して,テキストの部分だけを自分のファイル名に変更してください.
# CSVファイルのパスと解析したい列の名前を指定
file_path = 'ファイル名.csv' # CSVファイルのパス
column_name = '列の名前' # 解析したい列の名前
もし,sample.csvの中のtitleという列を指定したい場合は,
# CSVファイルのパスと解析したい列の名前を指定
file_path = 'sample.csv' # CSVファイルのパス
column_name = 'title' # 解析したい列の名前
というふうになります.
基本の形態素解析.ipynbの中身が何書いてるかわかんないよ〜という方に,めっちゃコメントを入れて書き下し文付きにすると,
# CSVファイルを読み込む
def read_csv(file_path, column_name): #CSVファイルを読み込むための関数を定義するよ
df = pd.read_csv(file_path) #pd(pandas)という道具にread_csvっていうcsvを読み込んでくれる機能があるから使ってみるよ
return df[column_name].tolist() #Pythonで使える形式にしたよ
# 形態素解析モデルの構築
t = MeCab.Tagger() #これは形態素解析をするためのおまじないだよ
# CSVファイルのパスと解析したい列の名前を指定
file_path = 'ファイル名.csv' # CSVファイルのパス
column_name = '列の名前' # 解析したい列の名前
# CSVファイルから文章を読み込む
sentences = read_csv(file_path, column_name) #sentencesという名前の箱にcsvの特定の列のデータを入れるよ
# 出力ファイルの設定
output_file = 'mecab_output.txt' #mecab_output.txtというファイルに結果を書いておいてね
# 形態素解析の実行とファイルへの書き込み
with open(output_file, 'w', encoding='utf-8') as file:
for sentence in sentences:
sentence = str(sentence).lower()
tokens = t.parse(sentence)
file.write(tokens)
print(f"形態素解析結果を {output_file} に保存しました。")
という感じになります(※これはあくまでも私の感覚なので,正確性というよりはプログラムコードの内容にイメージを持つためのものと考えてください…)
形態素解析したデータをPythonで整える
形態素解析は,文章を最小の単位にするものなので,単語が分割されすぎちゃったりします.例えば,「1964(数詞)と年(助数詞可能)」みたいな感じで,本当は「1964年」と出力してほしいのに「1964」と「年」に分かれちゃうといったことが起きます.これを整えていきます.

新しいコードブロックを出して,以下のコードを貼り付けて実行してください.
def update_text_file(input_file_path, output_file_path):
with open(input_file_path, 'r', encoding='utf-8') as file:
lines = file.readlines()
updated_lines = []
skip_next = False
for i in range(len(lines) - 1):
if skip_next:
skip_next = False
continue
current_line = lines[i].strip()
next_line = lines[i + 1].strip()
if '名詞-数詞' in current_line and '名詞-普通名詞-助数詞可能' in next_line:
current_line_parts = current_line.split()
next_line_parts = next_line.split()
if current_line_parts and next_line_parts:
combined_word = current_line_parts[0] + next_line_parts[0]
current_line = current_line.replace(current_line_parts[0], combined_word, 1)
skip_next = True
updated_lines.append(current_line)
# 最後の行を確認
if not skip_next:
updated_lines.append(lines[-1].strip())
with open(output_file_path, 'w', encoding='utf-8') as file:
for line in updated_lines:
file.write(line + '\n')
# 使用例
input_file_path = 'mecab_output_re.txt' # 入力ファイルのパス
output_file_path = 'mecab_output_re_re.txt' # 出力ファイルのパス
update_text_file(input_file_path, output_file_path)
以下の部分の名詞-数詞と 名詞-普通名詞-助数詞可能の部分に,それぞれ繋げたい単語の品詞を形態素解析結果を見て置き換えると,他のパターンも整えることができます.
if '名詞-数詞' in current_line and '名詞-普通名詞-助数詞可能' in next_line:
current_line_parts = current_line.split()
next_line_parts = next_line.split()
例えば,〇〇化(自在化とか)は,〇〇:名詞-xxxと化:接尾辞-xxxなので,以下のように変更します.
if '名詞-' in current_line and '接尾辞-' in next_line:
current_line_parts = current_line.split()
next_line_parts = next_line.split()
この時に,整えた後のファイル名(出力のファイルのパスという部分)を変更するのを忘れずに!
# 使用例
input_file_path = 'mecab_output_re.txt' # 入力ファイルのパス
output_file_path = 'mecab_output_re_re.txt' # 出力ファイルのパス
update_text_file(input_file_path, output_file_path)
Networkxで共起行列と共起ネットワーク定義+Pyvisで可視化
データを整えたら,ネットワークを定義していきます.共起ネットワークは5つのステップで定義できます.
- 名詞だけ抜き出したリストを作る
- 文章単位で名詞のコンビ(共起)を作る
- 単語の並びをソートする
- 単語のコンビを1つのリストにする
- 上記のデータ(共起行列と言います)を使ってネットワークを定義する
共起行列〜共起ネットワークの定義はこちらの記事がとてもわかりやすかったので参考にしました!:【自然言語処理】【Python】共起ネットワークの作り方を理解する
今回は,それぞれの工程でどのようなデータを入力して,どのようなデータが出力されているかを残すために,工程毎に入力と出力のファイルを明記していたりなどでくどいかもしれませんが,ご了承ください!
早速1から順に実行していきます.
名詞だけを抜き出す
新しいコードブロックを出して,以下のコードを貼り付けます.MeCabで形態素解析すると,一文の終わりにEOSという文字がつくので,それを頼りに名詞だけを抜きだして一文ずつリストにまとめていきます.
def extract_nouns(file_path, output_file_path):
with open(file_path, 'r', encoding='utf-8') as file:
lists = []
current_list = []
for line in file:
if 'EOS' in line:
if current_list:
lists.append(current_list)
current_list = []
continue
if '名詞' in line:
first_word = line.split()[0]
current_list.append(first_word)
if current_list:
lists.append(current_list)
with open(output_file_path, 'w', encoding='utf-8') as output_file:
for list_ in lists:
output_file.write(' '.join(list_) + '\n')
# この関数を使ってファイルを解析し、結果を別のファイルに保存するには、以下のようにします
input_file_path = 'mecab_output.txt' # 入力ファイルのパスを設定してください
output_file_path = 'meishi_output.txt' # 出力ファイルのパスを設定してください
extract_nouns(input_file_path, output_file_path)
以下の部分のinput_file_path = 'mecab_output.txt'を,整え終わったファイルの名前に変更して,実行してください.
# この関数を使ってファイルを解析し、結果を別のファイルに保存するには、以下のようにします
input_file_path = 'mecab_output.txt' # 入力ファイルのパスを設定してください
output_file_path = 'meishi_output.txt' # 出力ファイルのパスを設定してください
extract_nouns(input_file_path, output_file_path)
文章単位で名詞のコンビ(共起)を作る
次は,名詞同士の組み合わせを作ります.新しいコードブロックをだして以下のコードを貼り付け,実行してください.
import itertools
def create_noun_combinations(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
sentences = [line.strip().split() for line in file if line.strip()]
sentences_combs = [list(itertools.combinations(sentence, 2)) for sentence in sentences]
return sentences_combs
# この関数を使用する例
file_path = 'meishi_output.txt' # 名詞が格納されたファイルのパスを設定してください
noun_combinations = create_noun_combinations(file_path)
print(noun_combinations[0]) # 最初の文の名詞の組み合わせを表示
実行してうまくいってると,以下のように名詞の組み合わせが出力されます.
[('コロジオン', '湿板'), ('コロジオン', 'ゼラチン'), ('コロジオン', '乾板'), ('コロジオン', '写真'),…
単語の並びをソートする
同じ単語のコンビを数えないように,単語の並びをソートします.新しいコードブロックをだして以下のコードを貼り付け,実行してください.
import itertools
import collections
def count_noun_combinations(input_file_path):
with open(input_file_path, 'r', encoding='utf-8') as file:
sentences = [line.strip().split() for line in file if line.strip()]
sentences_combs = [list(itertools.combinations(sentence, 2)) for sentence in sentences]
sorted_combs = [[tuple(sorted(comb)) for comb in sentence] for sentence in sentences_combs]
target_combs = []
for words_comb in sorted_combs:
target_combs.extend(words_comb)
# 単語の組み合わせをカウント
ct = collections.Counter(target_combs)
return ct.most_common()[:1000]
# この関数を使用する例
input_file_path = 'meishi_output.txt' # 入力ファイルのパスを設定してください
most_common_combinations = count_noun_combinations(input_file_path)
print(most_common_combinations)
実行してうまくいってると,以下のように名詞の組み合わせが出力されます.
[(('写真', '電子'), 34), (('写真', '進歩'), 34), (('保存', '写真'), 33), (('写真', '技術'), 31), …
単語のコンビを1つのリストにする
文章単位で分けていたコンビを,1つのリストに集約させます.新しいコードブロックをだして以下のコードを貼り付け,実行してください.
import itertools
def create_and_save_aggregated_noun_combinations(input_file_path, output_file_path):
with open(input_file_path, 'r', encoding='utf-8') as file:
sentences = [line.strip().split() for line in file if line.strip()]
sentences_combs = [list(itertools.combinations(sentence, 2)) for sentence in sentences]
sorted_combs = [[tuple(sorted(comb)) for comb in sentence] for sentence in sentences_combs]
# すべての単語の組み合わせを一つのリストに集約
target_combs = []
for words_comb in sorted_combs:
target_combs.extend(words_comb)
# 集約されたリストをファイルに保存
with open(output_file_path, 'w', encoding='utf-8') as output_file:
for comb in target_combs:
output_file.write(f'{comb[0]}, {comb[1]}\n')
# この関数を使用する例
input_file_path = 'meishi_output.txt' # 入力ファイルのパスを設定してください
output_file_path = 'kyoki_gyoretsu_output.txt' # 出力ファイルのパスを設定してください
create_and_save_aggregated_noun_combinations(input_file_path, output_file_path)
ここまでの工程を経て作成されたデータはkyoki_gyoretsu_output.txtというファイルに保存されています.このデータを共起行列と言います.
ネットワークを定義する
最後に,ネットワークを定義して,pyvisで可視化していきます.
pyvisをインストールします.新しいコードブロックをだして以下のコードを貼り付け,実行してください.
!pip install pyvis==0.2.1
実行し終わったら,新しいコードブロックをだして以下のコードを貼り付け,実行してください.
from IPython.display import HTML
HTML("/content/cooccurrence_network.html")
from pyvis.network import Network
import pandas as pd
def create_cooccurrence_network(most_common_combinations):
# ネットワークの初期設定
cooc_net = Network(height="750px", width="100%", bgcolor="#FFFFFF", font_color="black")
# データフレームの作成
data = pd.DataFrame(most_common_combinations, columns=['word_pair', 'count'])
data[['word1', 'word2']] = pd.DataFrame(data['word_pair'].tolist(), index=data.index)
# エッジデータの追加
for index, row in data.iterrows():
cooc_net.add_node(row['word1'], label=row['word1'], title=row['word1'])
cooc_net.add_node(row['word2'], label=row['word2'], title=row['word2'])
cooc_net.add_edge(row['word1'], row['word2'], value=row['count'])
# ネットワークの可視化設定
cooc_net.set_options("""
var options = {
"nodes": {
"font": {
"size": 12
}
},
"edges": {
"color": {
"inherit": true
},
"smooth": false
},
"physics": {
"forceAtlas2Based": {
"gravitationalConstant": -26,
"centralGravity": 0.005,
"springLength": 230,
"springConstant": 0.18
},
"maxVelocity": 146,
"solver": "forceAtlas2Based",
"timestep": 0.35,
"stabilization": {
"enabled": true,
"iterations": 2000,
"updateInterval": 25
}
}
}
""")
return cooc_net
# この関数を使用するには、most_common_combinationsを引数として渡します
input_file_path = 'meishi_output.txt' # 入力ファイルのパスを設定してください
most_common_combinations = count_noun_combinations(input_file_path)
cooccurrence_network = create_cooccurrence_network(most_common_combinations)
cooccurrence_network.show("cooccurrence_network.html")
実行するとcooccurrence_network.htmlというファイルが出力されます.このファイルをダウンロードしてブラウザでみることができます.
すぐみたいよ!という方は新しいコードブロックに以下のコードを貼り付けて実行してください.
from IPython.display import HTML
HTML("/content/cooccurrence_network.html")
私が実際に可視化したネットワークはこんな感じでした↓
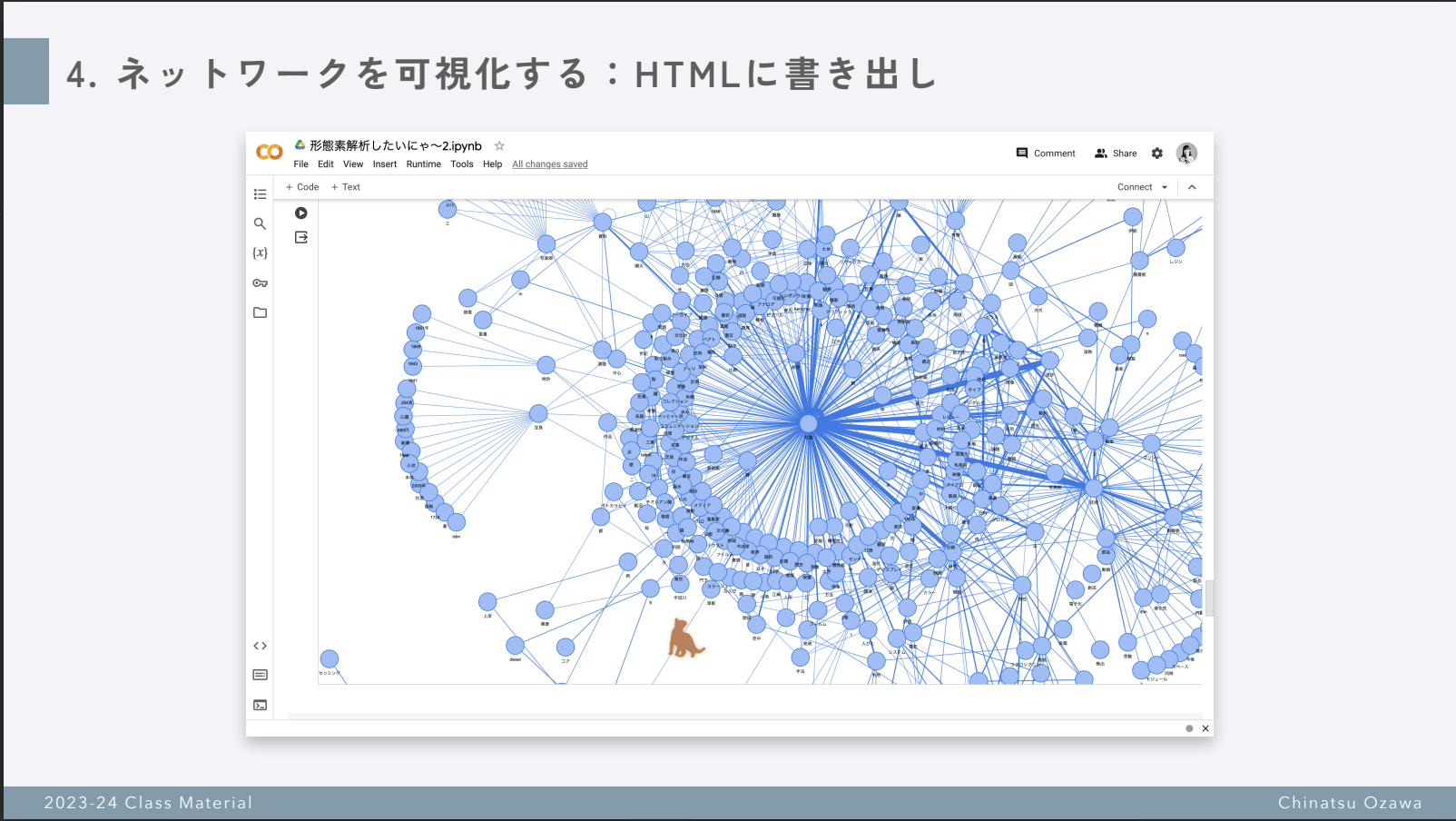
色々数字を変えて変化を見てみる
単語の並びをソート.ipynbの以下の部分の数字(ここでは1000)を変更すると,ネットワークに使われる単語のコンビの数が変わります.
# 単語の組み合わせをカウント
ct = collections.Counter(target_combs)
return ct.most_common()[:1000]
例えば,この数字を10から始めて,1000まで10~100単位で変えて出力してみると,ネットワークがどんどん大きくなって,クラスターができるなど色々な特徴を観察できます!ぜひ遊んでみてください.
まとめ
プログラミング全然わかんないにゃ〜という感じでも,CSV形式でデータさえあればとりあえずこの記事を上から下までコピペして実行するだけで簡単に共起ネットワークを作ることができます!
ネットワークが大きすぎると回り始めてとても可愛いので,大変おすすめです.
そして,colabがあれば初心者を苦しめる環境構築をせずともPythonが使えます.
困った時の合言葉は「わからないことはChatGPTにきく」です.
わからないところ全部投げて「ここがわかりません!」というと,懇切丁寧に教えてくれます.お陰で,私も共起ネットワークの可視化まで辿り着けました….
特に,CSVでファイルの受け渡しなどは全部GPTが書いてくれました.圧倒的感謝.
こんな感じの記事でいいのかはわかりませんが,これからも作ってみたものとか色々載せていけたらなと思います!最後まで読んでいただきありがとうございました〜!!!!