こんにちは。秋田県のIT企業、北日本コンピューターサービスのR&Dチーム「AUL(アウル)」に所属しています。トラフクロウです。
今回が初の投稿になりますので、内容については広い心で眺めていただけるとうれしいです。
この記事はTransformer(トランスフォーマー)について僕が勉強した内容をまとめたものになっています。 トランスフォーマーが紹介された論文「Attention Is All You Need」を読んで僕が気になった部分や疑問に感じた部分をまとめました。
僕がトランスフォーマーについて勉強しようと考えたきっかけは仕事で自然言語処理AIを使ったことです。
社会人になって最初に配属されたプロジェクトではトランスフォーマーから派生したBERT(バート)というAIを使っていました。当時指導してくれた先輩いわく「バートは文章をベクトルにしてくれて、意味どうしの計算ができるんだよ」とのことでした。
学生時代からベクトルというものは知っていましたが、文字列が数値情報になる過程をまったくイメージすることができず「どうやっているんだろう?不思議だなぁ」と感じたことを覚えています。
「ただの文字列をどうやって意味のある数値に変換しているのだろう?」 こんな疑問から、バートについて調べはじめました。そして、バートはトランスフォーマーというAIの派生であること。さらには、トランスフォーマの一部分を切り出したモデルであることを知りました。
それならば、「トランスフォーマーの仕組みが分かれば、バートも分かるじゃないか!」 ということでトランスフォーマーの勉強をはじめたわけです。

この記事はトランスフォーマーの概要をざっくりと知りたい人向けです
この記事では、僕がトランスフォーマーを勉強したときに感じた疑問と、その答えをまとめています。以下、お品書きです。
・トランスフォーマーって何者?
・トランスフォーマーの性能の秘密は?
・アテンションって具体的にどんなもの?
・トランスフォーマーの中身ってどうなっているの?
・エンコーダーって何?
・どうやって文字列をベクトルに変換しているの?
・デコーダーって何?
この記事に数式は出てきません。
この記事の目的は「トランスフォーマーざっくり内容を理解する」です。そのため、計算式を用いた説明や解説は行いません。
トランスフォーマーとは文章を入れると文章を出力するAIのこと
まず1つ目の疑問である 「トランスフォーマーって何者?」 についてです。
トランスフォーマーは2017年に Googleの研究チームによって作成された機械翻訳用のAI です。論文内では、英語をドイツ語やフランス語に翻訳する作業を行ったと記されています。トランスフォーマーはそれまでにない 特別な内部構造を採用することで次の能力を獲得 しました。
- 当時のAIの中で最高の性能を実現
- 効率的な計算能力による学習時間の削減

少し余談ですが、トランスフォーマーの発表から数年がたち、たくさんの応用モデルが作成されています。
例えば、テキスト生成で有名なOpenAI社のChatGPTはトランスフォーマーを土台としたGPTモデルを使っています(GPTのTはトランスフォーマーのTです)。また、画像処理に特化したVision Transformer(ビジョントランスフォーマー)や、複数の自然言語処理タスクを統一的に扱うことができるT5(ティーファイブ)もトランスフォーマーを応用したAIになります。
トランスフォーマーの出現は自然言語処理の分野に革命をもたらしました。それでは、どうやってトランスフォーマーはこれほどの高い汎用性と生成能力を獲得したのでしょうか?
トランスフォーマーはアテンション機構をつかうことで圧倒的な性能を手に入れた
ここでは 「トランスフォーマーの性能の秘密は?」 について見ていきます。
論文発表当時は、recurrent neural network(リカレントニューラルネットワーク、再帰ニューラルネットワーク)という構造を用いることが文章生成AIの一般的な戦略でした。
リカレントモデルは、直前の出力を次の入力値とすることで過去の情報を反映させた出力ができるという特徴を持っています。これにより、人間が読んで自然な文章を生成できるのです。

一方で、リカレントモデルには複数の計算を同時に処理できないという欠点があります。ある時点での計算を実行するためには、直前の計算結果を準備しておく必要があるからです。この並列計算の課題は、AIを効率的に学習できないことの原因になります。
余談ですが、複数の計算を同時に行うことができるモデルとしてconvolutional neural network(コンボリューショナルニューラルネットワーク、畳み込みニューラルネットワーク)があります。畳み込みモデルは、リカレントモデルとはまったく別の構造を持つモデルです。主に画像処理の分野で使われています。受け取った画像データを「畳み込み」という処理で圧縮し、情報を凝縮して処理するイメージです。

トランスフォーマーの大きな特徴の1つは、当時主流だったリカレントと畳み込みの構造を持たないことです。しかし、トランスフォーマーは特殊な戦略をとることでリカレントモデルの生成能力と畳み込みモデルの効率的な計算を両立 することに成功しました。
その特殊な戦略は self-Attention(セルフアテンション、自己注意機構)とよばれています。
セルフアテンションとは、入力されたデータを細かく分解し、各データに対し、互いの重要度(関係性)をわりあてる戦略 です。大きなデータを構成するパーツどうしの関係性に注目することでより詳細にデータの特徴を計算することができます。パーツどうしの関係性にアテンション(注意する)わけですね。

アテンションとはデータどうしの関係性の強さを表す数値のこと
次に感じる疑問は 「アテンションって具体的にどんなもの?」 だと思います。
トランスフォーマーに入力された文章は、意味の最小単位である単位であるトークン(単語)に分割されます。この過程を形態素解析とよんだりします。

アテンションを計算するときはまず、分割した単語から1つを選びとります。そして選ばれた単語と文章に含まれるすべての単語を比較し、互いの関連性を計算します。ここで計算される単語どうしの関係性の強さを表す数値がアテンションです。
下の図は論文内で紹介されているアテンションを可視化した図です。トランスフォーマーが「この単語たちは高い関連性をもっているな」と判断した時に線の色が濃くなるようになっています。

Attention Is All You Need より引用(Figure4)
ここでふと気になることがあります。というのも、トランスフォーマーは文章を解析して翻訳してくれますが、それ自体はプログラミング言語で記述されたプログラムです。そしてアテンションは数学的な理論に基づき計算された数値になります。それでは、どうやって普通の文字列(単語)から数値を導き出しているのでしょうか?
この謎を明らかにするために、ここからはトランスフォーマーの中身をくわしめに見ていこうと思います。
トランスフォーマーは、入力文を解析するエンコーダーと出力文を作るデコーダーで構成されている
文字から数値への変換がどこで行われるのかを探るため、「トランスフォーマーの中身ってどうなっているの?」 について見てみましょう。
トランスフォーマーの構成要素は大きく2つあります。1つ目は入力された 文章を解析するEncoder(エンコーダー) とよばれる部分。2つ目は、翻訳結果を出力するDecoder(デコーダー) とよばれる部分です。

片方ずつ順番に見てみましょう。
エンコーダーは入力文を構成する単語をベクトルに変換する
まずは、「エンコーダーって何?」 についてです。エンコーダーの内部構造はざっくりと次の図のようになっています。

エンコーダーに 入力された文章はトークナイザーとよばれる変換器を使って単語に分割されます。 トークナイザーは文章処理系のAIが持っている単語分割用の機能で、AIの振る舞いにあわせて作られます。そのため、AIが異なれば単語の分割方法にもビミョーな違いがでてきます。
トークナイザーで分割された単語は、ベクトルとよばれる数値の並びに変換されます。 どの単語にどんなベクトルをわりあてるかについても厳格なルールはありません。そのため、ベクトルのわりあてはAIによって個性が出る部分になります。この個性がAIの性能に直結する場合も少なくありません。

単語をベクトルに変換した後は、各単語ベクトルに文章内での位置情報を付与します。 単語の情報だけでは「これ は ペン です」と「です は これ ペン」のように同じ単語で作られた文章どうしを区別できないためです。
そこで、単語が左から何番目に配置されているかを表す特殊なベクトルを各単語ベクトルに足し合わせます。位置情報を表す特殊なベクトルは位置ベクトルとよばれます。この足し算の結果得られたベクトルこそが、後の計算で使われる真の単語ベクトルです。

さて、ここまでくれば数学を使って単語ベクトルどうしをガリガリ計算することができます。その計算を行う部分がエンコーダー内にずらっと並んでいる「計算層」です。
計算層は単語どうしの関係性の強さ(アテンション)を計算する部分です。ここで計算されたアテンションは対応する単語ベクトルに掛け算され、そのあとすべて足し合わされます。 この足し算の結果得られたベクトルは、アテンションの情報を付与されたベクトルです。
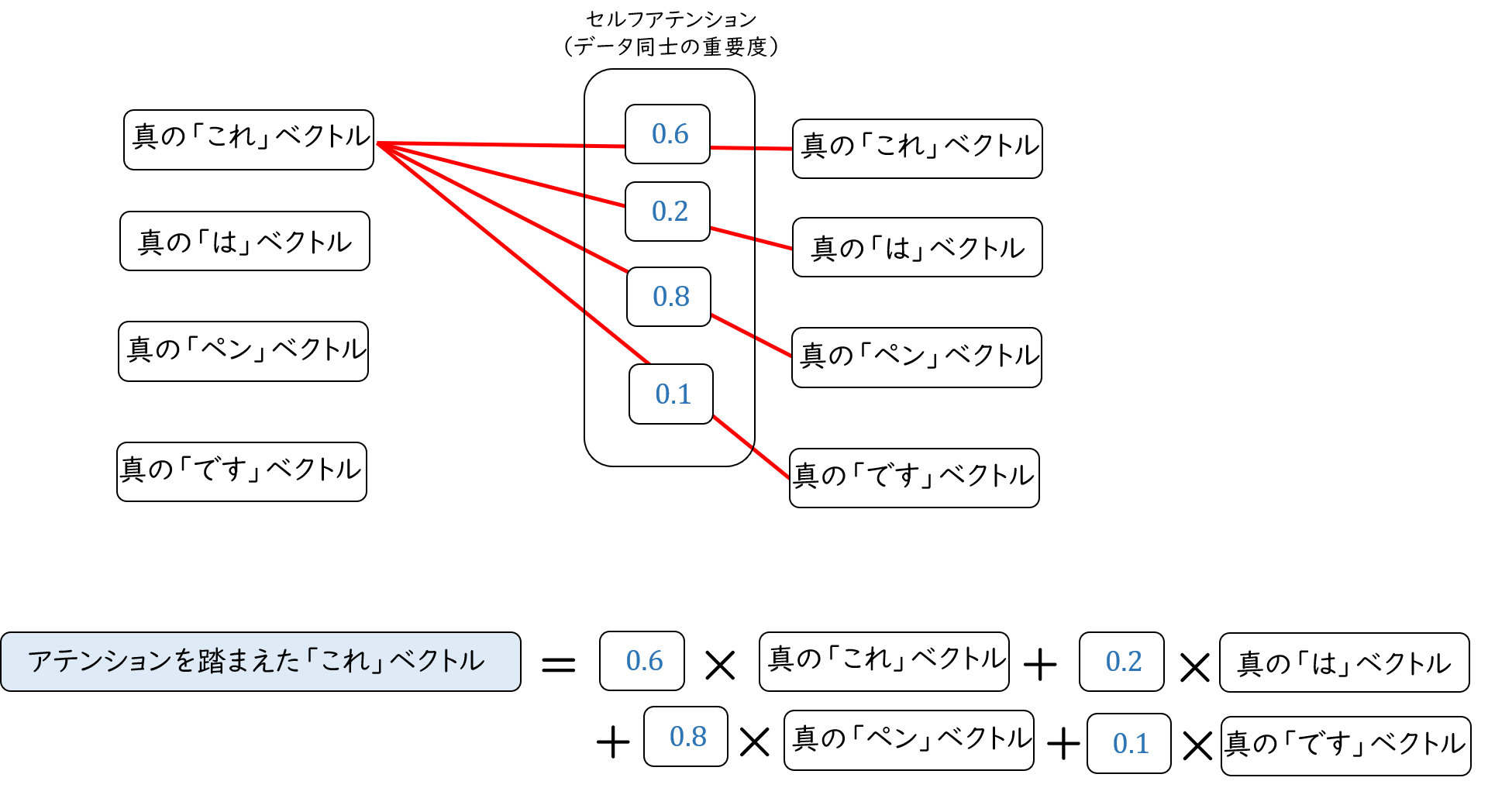
このように、1つの単語ベクトルを他の単語との関係性を考慮して表現することで文脈とらえた単語の認識が可能になります。
最初の計算層で得られた新しい単語ベクトルは次の計算層に入力され、その後同様に計算されます。 アテンションの計算を重ねがけすることで、より洗練されたベクトルができるのです。トランスフォーマーの論文ではこの計算過程を2回、4回、6回、8回の場合で実験しています。
文章を正確に解析するためのトランスフォーマーの工夫はこれだけではありません。
トランスフォーマーはマルチヘッドアテンションとよばれる構造を持っています。マルチヘッドアテンションはトランスフォーマーの文章読解力の核心とも言える構造です。
マルチヘッドアテンションの戦略は、1つの単語ベクトルを細かく分割して各パーツごとにアテンションを計算するというものです。 論文では1,4,8,16,32分割のパターンで実験をしていました。例えばサイズ512のベクトルを8分割すると、サイズ64のサブベクトル(論文ではヘッドとよばれています)が8つできます。

マルチヘッドアテンションではすべてのベクトルをこのように分割して、各分割ごとに、個別にアテンションを計算します。そして最終的に得られた各ベクトルを再度連結することで元のサイズに復元します。

「なんでわざわざベクトルを分割するの?」と思った方もいるかと思います。実際に僕も「なんでこんな面倒なことをするのさ」と思いました。
このベクトルの分割については、実験から得られた非常に興味深い理由があります。
実は驚くべきことに、各サブベクトル(ヘッド)ではまったく別のアテンションが計算されている のです。次の図は論文からの抜粋で、5番目と6番目のヘッドに注目した際のアテンションです。

Attention Is All You Need より引用(Figure5)
図の線の引きかたや濃さが異なることから、同じ単語の組み合わせに対して別のアテンションが計算されていることがわかります。これはトランスフォーマーがヘッドごとに、異なる観点で文章の文法や構造を解析している ことを意味しています。そしてこの多角的な文法解析がトランスフォーマーの優れた文章読解力の秘訣であるとされているのです。
以上がエンコーダーのあらましです。
途中でさらっと「単語がベクトルに変換される」と書きましたが具体的にはどうやって変換するのでしょうか? これは僕がトランスフォーマーを調べたきっかけとなった疑問ですが、その答えは意外とあっさりしていました。
単語からベクトルへの変換は事前に作成した対応表をつかっている
「どうやって文字列をベクトルに変換しているの?」 について、以前の僕は「きっと、すさまじい数学理論を駆使して崇高な変換をしているに違いない」と思っていました。しかし論文を読んでみるとそれほど仰々しいことは行われていないようです。
単語とベクトルを紐づける具体的な方法についてはトランスフォーマーの論文の30番目の参考文献である「Using the Output Embedding to Improve Language Models」に詳しく書いてあります。詳細の説明は省略しますが、ざっくり次のような仕組みになっているようです。
- 学習時点でAIが認識可能な単語を事前に決めておく
論文では3万2千単語と2万5千単語を認識できる2つのモデルが紹介されています。 - 各単語にランダムなベクトルを割り振る
ベクトルのサイズ(次元)は全単語共通です。トランスフォーマーの論文では256, 512, 10241のパターンで実験しています。 - 単語に対応するベクトルは機械学習により、単語の意味を認識できるようになっている
例えば「休み」と「休暇」のベクトルは言葉の意味が似ているので、似ているベクトルに変換されます。
以上のような手順で、単語とベクトルの対応表が作られます。つまり、トランスフォーマーは入力された単語にどんなベクトルを割り当てるべきかを毎回計算しているわけではなく、どう変換すべきかを既に知っているのです。

デコーダーはエンコーダーが出力したベクトルから文章を生成する
最後は 「デコーダーって何?」 についてです。デコーダーの内部構造はざっくりと次の図のようになっています。

デコーダーもエンコーダーと同様に、単語ベクトルの作成から始まります。しかし、入力するのは下の図のような特殊な単語たちです(論文の中に具体的な記述を見つけることができなかったので厳密には異なるかもしれません)。

先頭の「開始トークン」は文章が始まったことを表す特殊トークンです。その後ろに並んでいる「マスクトークン」はまだ実態が分かっていない未知の単語になります。デコーダーでは、開始トークンを足掛かりにして横に並ぶマスクトークンをどんな単語に置き換えればよいかを予測します。 このとき、1つの単語を予測したらその結果を踏まえて次の単語を予想していきます。
文章生成のときに計算でつかわれるのは、エンコーダーのときと同様、トークンに対応するベクトルと位置ベクトルを足し合わせた単語ベクトルです。
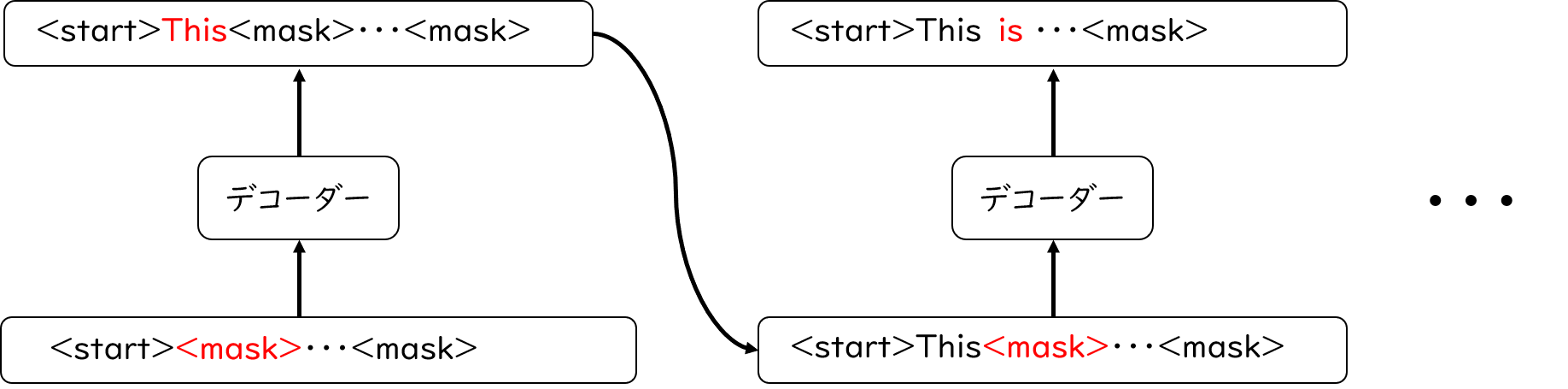
計算についてもエンコーダーの場合とほぼ同じで、入力値のセルフアテンションを計算していきます。エンコーダーとの主な違いは、デコーダーでは2種対のアテンション機構を使う ということです。
1つ目はマスクマルチヘッドアテンション です。大まかなの仕組みはエンコーダーで紹介したマルチヘッドアテンションと同じですが、異なる特徴が1つあります。それは マスクトークンのアテンションを計算しない ことです。
例えば先頭から2個目までの単語をすでに予測していて、次に3番目の単語を予想する場合を考えてみましょう。3番目の単語を予測するために、マスクマルチヘッドアテンションでは単語同士のアテンションを計算します。しかしこのとき、3番目以降のマスクトークンのアテンションは強制的に0として計算されます。
マスクトークンのアテンションを強制的に0にすることがマスクマルチヘッドアテンションの役割であり大きな特徴です。

まだ明らかになっていない単語の情報を排除することで、次の単語の予測に無駄なノイズが入ることを防いでいるのです。
2つ目のアテンション機構はエンコーダーとデコーダーをつなぐマルチヘッドアテンション です。名前が長いのでクロスとよばせてください。
クロスアテンションではエンコーダーが出力した単語ベクトルと、デコーダーに入力された単語ベクトルどうしでアテンションを計算します。これは、トランスフォーマーに入力された翻訳前の文章の情報を出力用の計算に混ぜ込むことが目的 です。

このような計算を経てさまざまな情報を圧縮したベクトルが出力されます。デコーダー内でつくられたベクトルをさらに解析することで、次の単語は何になるかを予想できるようになります。 厳密な理屈には触れませんが、ざっくりと次のような手順です。
- あらかじめトランスフォーマーが出力可能な単語の一覧を洗い出しておく
- デコーダーの出力ベクトルが、一覧表のどの単語の特徴に近いかを調べる
これはかなり曖昧な表現です。実際には線形変換やソフトマックス関数といった道具を使いますが少々複雑なので割愛します。 - 次の単語の候補になりそうなものをいくつか選びとる

最後のステップで単語の候補をいくつか選びとると書きました。これはビームサーチとよばれる手法です。トランスフォーマーの論文を見た限りでは38番目の参考文献で挙げられている「Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation」の方法を採用しているようです。
ビームサーチとは、効率的な文章生成を行うための戦略 の1つです。
ビームサーチでは1つの単語を予測する際に決められた数だけ候補単語をピックアップします。この決められた数のことを「ビーム幅」といいます。そして、次の予測では直前に選ばれた候補単語全てに対し、ビーム幅分の候補単語を探します。この工程を繰り返していくのです。
しかし、このままでは回数を重ねるごとに候補の数が増えてしまい計算量が膨大になってしまいます。そこで、それまでに選ばれた候補をさらにビーム幅の数までしぼります。下の図はビーム幅が3の場合の例です。

候補単語の選び方について補足しますが、どの単語と候補とし、何を切り捨てるかはトランスフォーマーが勝手に判断してくれます。これまでのベクトルの計算結果を踏まえてトランスフォーマーが最も正しそうなモノを選択するのです。
以上の工夫により、少ない計算で適切な解答を予想できるというわけです。
まとめ
以上がトランスフォーマーというAIのあらましです。
つまるところ トランスフォーマーは、アテンション機構を採用することで高い文章読解力と効率的な計算方法を獲得した翻訳AI という解釈になります。
ここまで読んでいただき、ありがとうございました!
かなりボリューミーな内容になってしまいましたが、ここまでお付き合いいただいた方はありがとうございました。
今回は、内容が複雑化することを避けるために計算式を使わずに記事を作成しました。しかし、トランスフォーマーや一般のニューラルネットワークで利用されている計算理論は非常に興味深く面白いものが多いです。今後は計算式のみに焦点を当てた記事なども書けたらいいなと思っています。
この記事は、トランスフォーマーの論文を僕なりに必死に読んで作成しました。僕は英語が大の苦手なので解釈が間違っている部分もあるかもしれません。お気づきになった点があればご指摘いただけると助かります。また内容についてご質問等も歓迎しますので、よろしくお願いいたします。
参考文献ならびに参考図書
- Attention Is All You Need
- Using the Output Embedding to Improve Language Models
- Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
- 山田育矢, 鈴木正敏, 山田康輔, 李凌寒, 「大規模言語モデル入門」, 技術評論社, 2023
- 黒川利明, 「Transformerによる自然言語処理」, 朝倉書店, 2022