こんにちは。秋田県のIT企業、北日本コンピューターサービスのR&Dチーム「AUL(アウル)」に所属しています。トラフクロウです。
AIや数学の勉強をしているとベクトルという言葉が頻繁に登場します。とりわけ僕が相手取るのは3次元よりも大きな次元数をもつ高次元のベクトルです。高校数学に始まり、かれこれ十数年ベクトルと良好な関係を築いてきましたが、ただ1つだけ不満があります。それは、
高次元に行くな!目に見える範囲にいてくれ!
ということです。
僕たち人間は、空間として3次元までしか知覚することができません。これは子供だろうが、大人だろうが、IQや学力などにも関係なく、ホモ・サピエンスとしての生物的な限界です。そのため、必然的に、高次元空間に住んでいる高次元ベクトルを視覚的にイメージできないのです。
「生物学的な限界を無視して仕事で高次元ベクトルをバンバン使う」そんな状況に、これまで僕をはじめとした多くの方が甘んじてきたわけですが、もしも高次元ベクトルを完全に可視化することができたらステキだと思いませんか?
というわけで、今回の記事は「情報の損失をなくしてベクトルを可視化する方法をがんばって考えてみたよ」という内容です。
この記事では、任意の高次元ベクトルを2次元平面上で可視化する方法を紹介します。
世の中にはすでに、t-SNEなど、いろいろなベクトルの可視化方法があります。多くの場合は高次元ベクトルを無理やり低次元空間に投影するという戦略で可視化しています。しかし、これでは低次元に圧縮する過程で多くの情報がつぶされてなくなってしまいます。贅沢を言うと怒られそうですが、せっかくなら、本来のベクトルの情報をすべて残した状態でその姿を見たいですよね?
「なんとかできないかな?」とあれこれ考えるうちに「これなら可視化できるのでは?」ということを思い付いたので、この記事で紹介したいと思います(とはいっても、たぶん誰かがすでにやっているはず)。
以下、今回のお品書きです。
- ベクトルと関数を同一視する
- 関数のグラフを描くようにベクトルのグラフを描く
- 指数移動平均をとって描画を滑らかにする
- BERTモデルの埋め込みベクトルを可視化する
ベクトルは関数である。
高次元ベクトルの可視化を考えるにあたり、ベクトルのもつ「矢印」や「数字の並び」というイメージを変えたいと思いました。これまでと同じイメージでは次元の壁は抜け出せないと考えたからです。そんなとき、大学時代に勉強した量子力学の授業を思い出しました。量子力学曰く「関数は無限次元のベクトルである」らしいです。
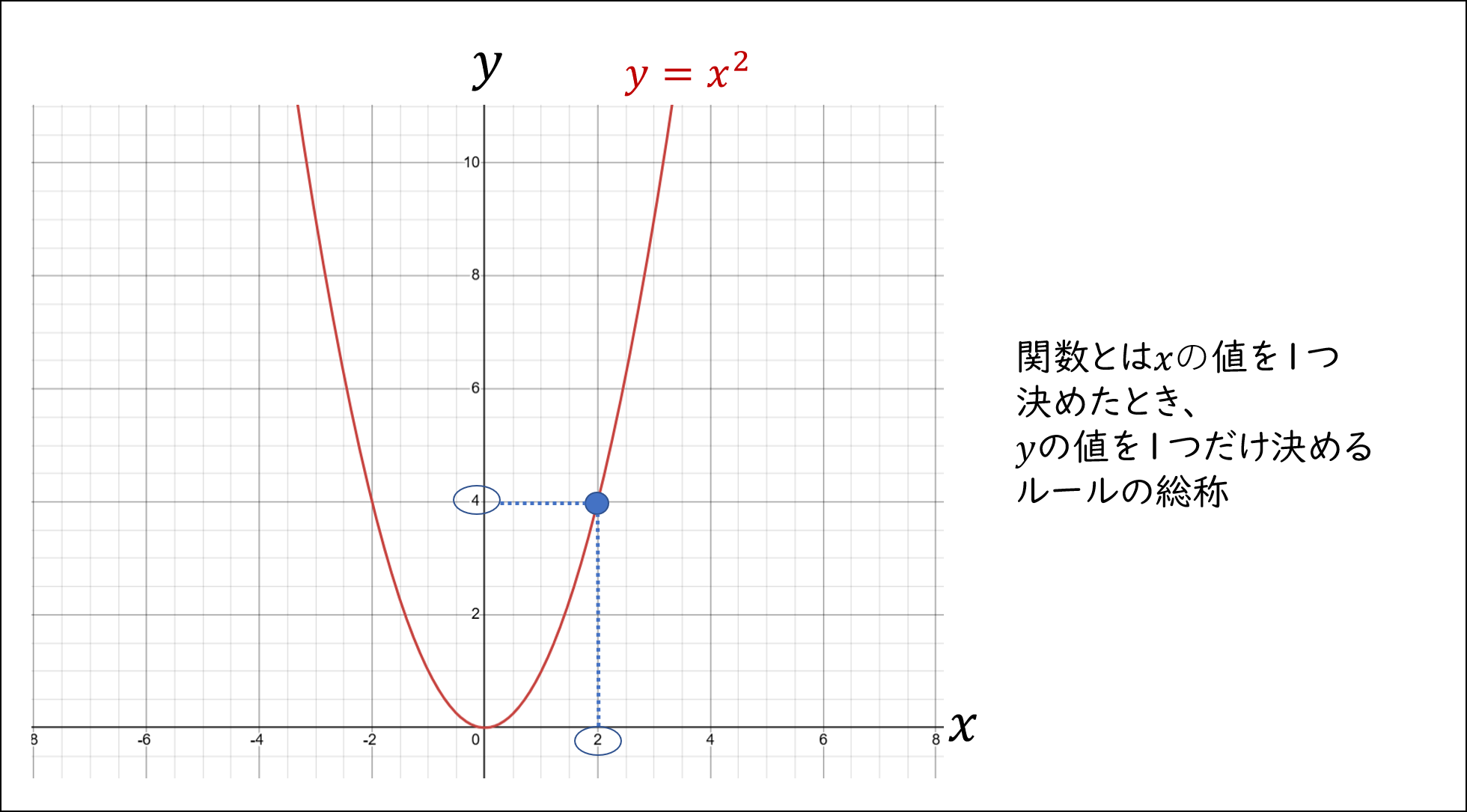
関数と聞くとアレルギーを起こす人もいますが、そんなに仰々しいものではありません。関数とは「1つの数字に1つの数字を対応させるルール」のことです。例えば高校で習う有名な関数に
y = x^2
があります。$y = x^2$ では $x = 2$ のように $x$ を1つ決めると $y = 4$ のように $y$ が1つ決まります。つまり $y=x^2$は $x, y$ で表現された数の対応のルールということです。
量子力学の世界では関数を無限次元のベクトルと考えながら議論をする風潮があります。関数とベクトルを同一に考えるには次のようなイメージをするとわかりやすいです。
関数に $i$ を入れて、それに対応して得られた数字 $a_i$ を ベクトルの $i$ 番目の数字だと考える

このように考えると、関数は、ベクトルのような数字の羅列であると思うことができます。しかも $y = x^2$ のような関数は、$x$ の値が $1, 2, 3$ のような正の整数の場合だけでなく、$-1$ などの負の整数や $1/2$ のような有理数、$\sqrt{10}$ のような無理数の場合でさえも対応する $y$ の値を計算できます。
つまりベクトルして「$1$番目の数字」はもちろん「$-1$番目の数字」や「$\sqrt{10}$番目の数字」など普通ではありえないような順番を指定したベクトルが作れてしまうのです。
この形式的な番号指定は世の中に存在するすべての数字で有効なため、関数は無限次元ベクトルに等しいと考えられているのです。
関数ならグラフを描けるじゃないか。
関数がベクトルだと思えるのなら、逆もまた然りです。ベクトルを関数であると考えてもいいじゃないかと思いました。つまり
\boldsymbol{v} = (-1, 2, 5, -3, 9)
のようなベクトルは $x = 1, 2, 3, 4, 5$ のとき $y = -1, 2, 5, -3, 9$ となる関数であると考えるのです。
そしてさらに、関数であれば平面上にプロットしてグラフを考えることができます。同様にベクトルも数字を平面上にプロットすることでグラフが描けるのです。
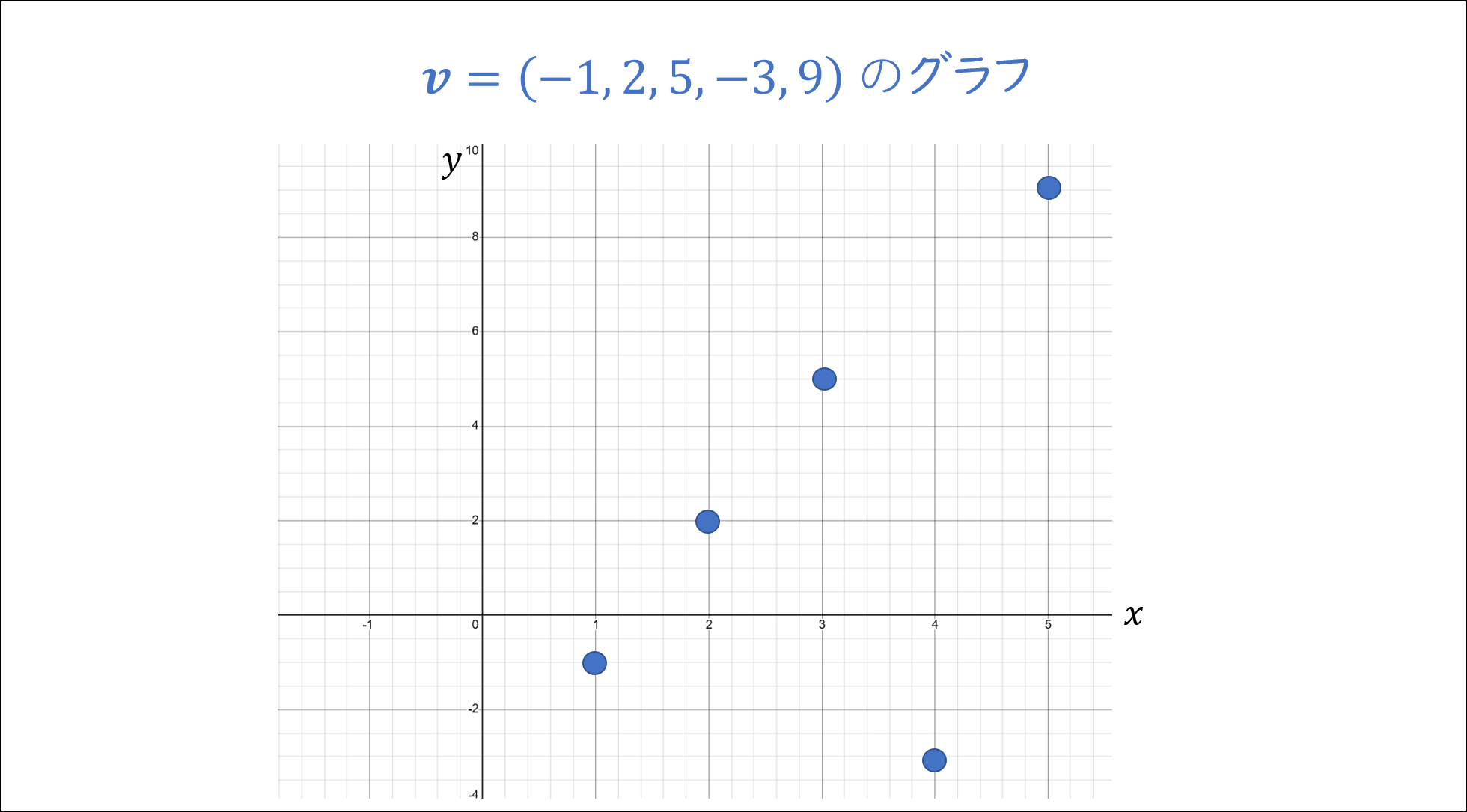
この例の時点で、すでに僕たちは5次元ベクトルを完全に可視化できました(ホモ・サピエンスの限界を超えた!!)。
指数移動平均でもっと滑らかなグラフを描こう。
意外とあっさり可視化できたということで、もっと高次元のベクトルを見てみようと思います。次は BERT モデルを使って「犬はかわいい」という文章に対応するベクトルを描画した様子です。BERT モデルには東北大学さんが HuggingFace 上で公開している bert-base-japanese-v3 を使用し、[CLS] トークンの埋め込みベクトルを観察しています。
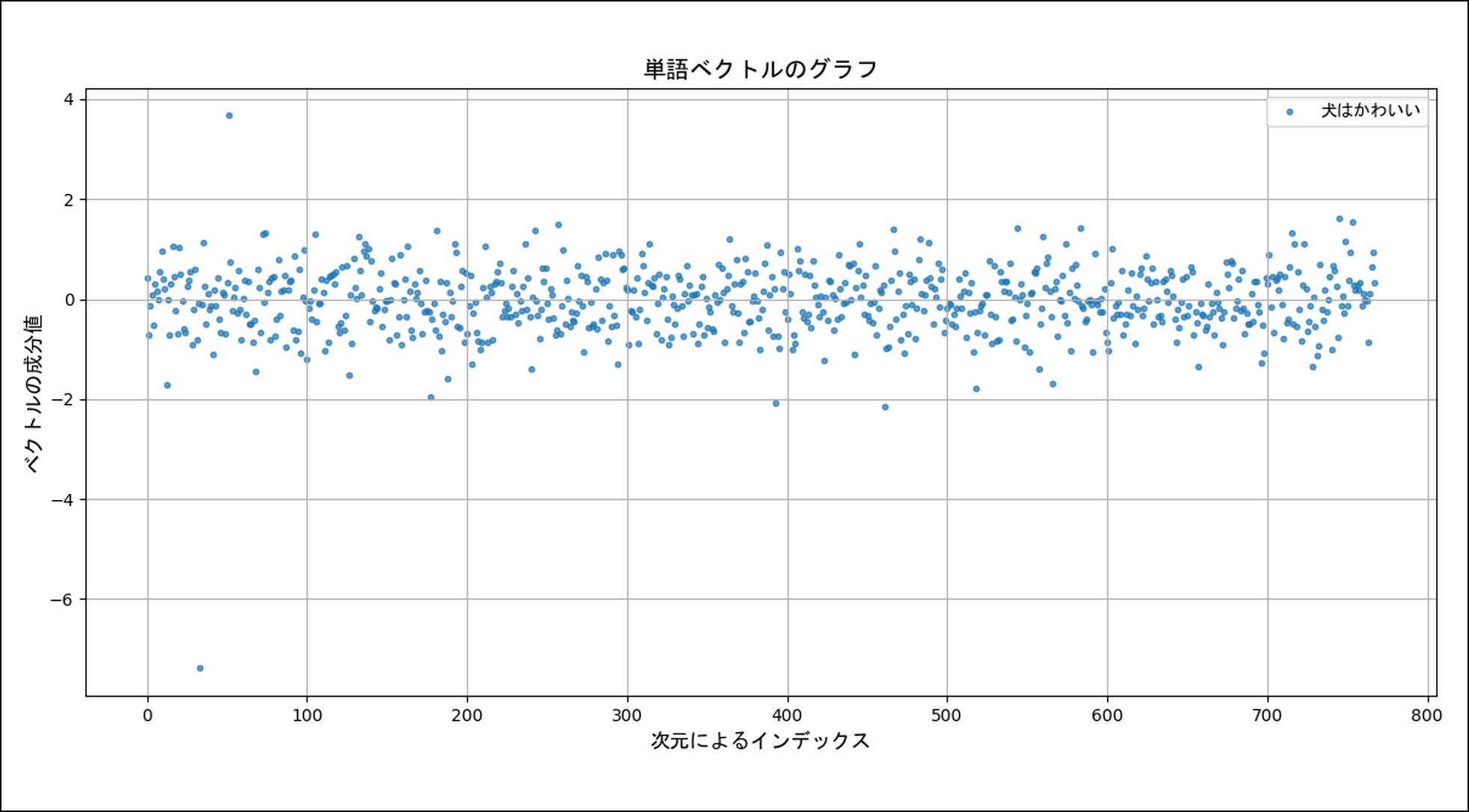
「うーん、見づらい!」。
「だ、だけど、他のベクトルと区別できれば、まぁ、成功でしょ(震え声)」。
ということで「猫はキュート」と「エビフライの逆襲」という2つの文章を追加して比較してみました。結果は、
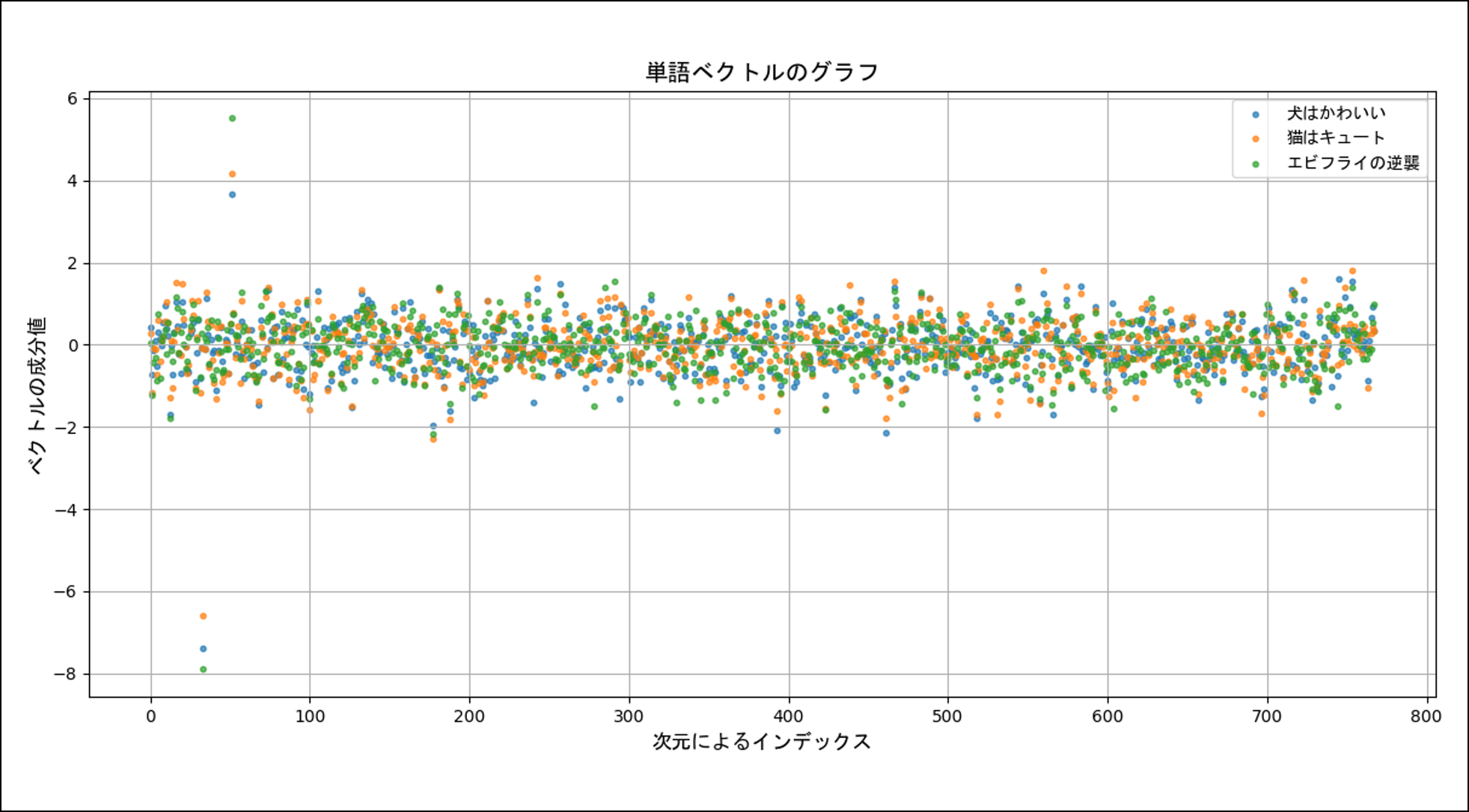
「うん。全然区別できないね★」
ということで、惨敗です。
ちなみに、各文章でのcos類似度の値は次のようになります。いかに上の散布図が役立たずかがわかりますね。
| 文章1 | 文章2 | cos類似度 |
|---|---|---|
| 犬はかわいい | 猫はキュート | 0.906741 |
| 犬はかわいい | エビフライの逆襲 | 0.749553 |
| 猫はキュート | エビフライの逆襲 | 0.785955 |
敗因は、おそらく、プロットした点が不規則に動きすぎていて視覚的な構造が把握できないことです。上の3つはどれを見ても「ごちゃごちゃ、バラバラしている」というだけで、視覚的なパターンがわかりません。
そこで、ベクトルをただ横に並べるだけでなく工夫をすることにしました。
具体的には文章から得られたベクトル $\boldsymbol{v}$ を用いて新しいベクトル $\boldsymbol{w}$ を次のように計算します。
w_i = \alpha w_{i-1} + (1 - \alpha) v_i \quad \quad (ただし w_0 = v_0 とする)
ここで、$w_i, v_i$ はベクトル $\boldsymbol{w}, \boldsymbol{v}$ の $i$ 番目の数字(成分)であり、$\alpha$ は $0$ から $1$ の間で固定したパラメータです。
この作り方で得られるベクトル $\boldsymbol{w}$ の $i$ 番目の成分 $w_i$ は、ベクトル $\boldsymbol{v}$ の $i$ 番目の値の大きさに応じて変化します。つまり $\boldsymbol{w}$ はベクトル $\boldsymbol{v}$ の各成分の値にリンクして、直前の値が増減する様子を記録しているわけです。
実際に $\alpha = 0.9$ として、「犬はかわいい」ベクトルを描画すると次のようになります。さっきよりは視覚的な構造が見えるようになりましたね(そんな気がします)。
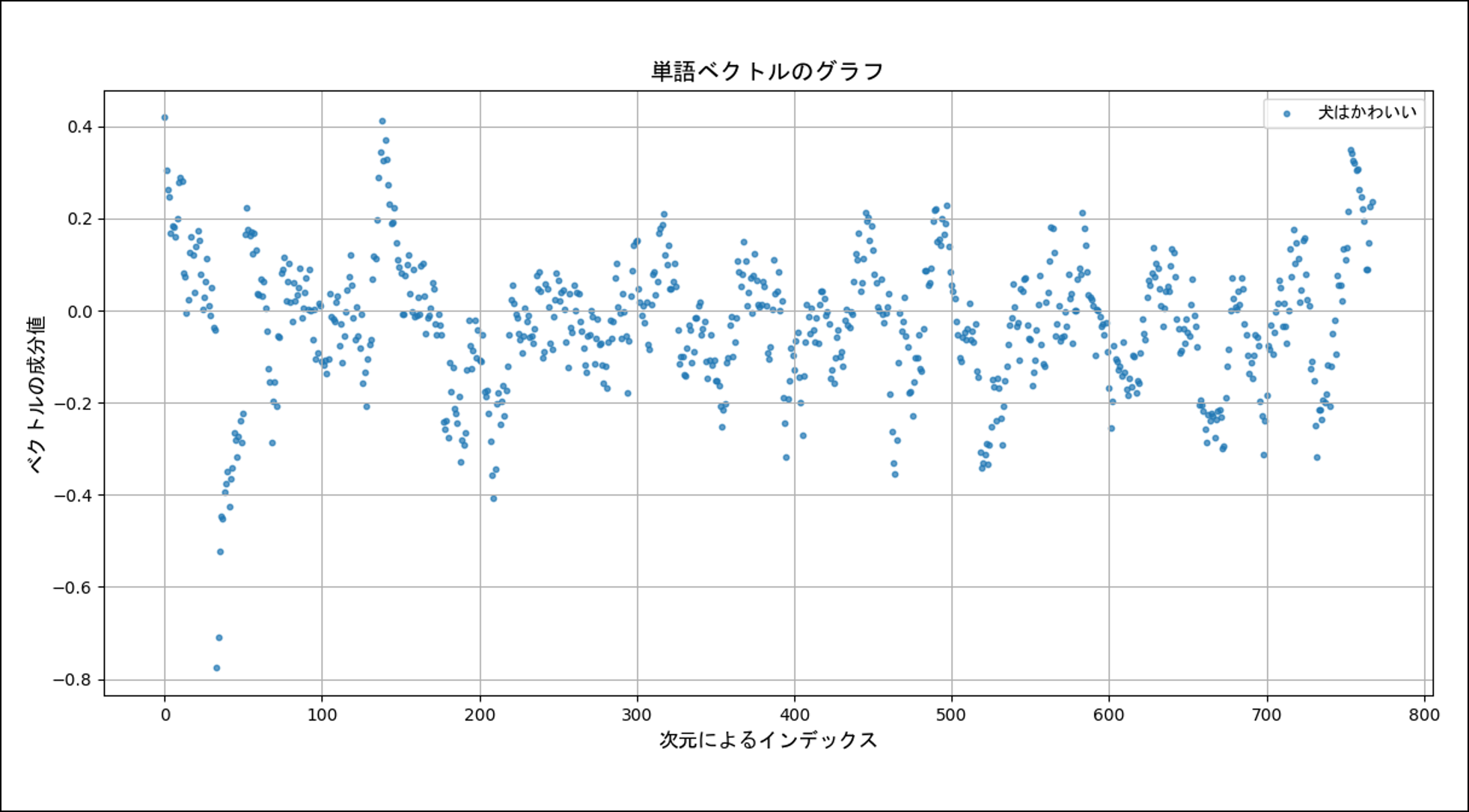
ちなみに後から知りましたが、この計算方法には指数移動平均という名前がついているそうです(折れ線グラフのギザギザをなくすために使われるらしい)。
[散布図作成に使用したコードはこちら]
import torch
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
from transformers import BertJapaneseTokenizer, BertModel
from scipy.spatial.distance import cosine
# 日本語フォント(MSゴシック)を指定
jp_font = FontProperties(fname="C:/Windows/Fonts/msgothic.ttc")
# 単語ベクトル取得
def get_bert_vector(word, model, tokenizer):
sentence = f"{word}"
tokens = tokenizer(sentence, return_tensors="pt", truncation=True, padding=True)
with torch.no_grad():
output = model(**tokens)
return output.last_hidden_state[:, 0, :].squeeze().numpy()
# EMA(指数移動平均)
def repeated_ema(v, alpha=0.1, times=1):
smoothed = v.copy()
for _ in range(times):
s = np.zeros_like(smoothed)
s[0] = smoothed[0]
for i in range(1, len(smoothed)):
s[i] = (1 - alpha) * smoothed[i] + alpha * s[i-1]
smoothed = s
return smoothed
# モデル読み込み
tokenizer = BertJapaneseTokenizer.from_pretrained("tohoku-nlp/bert-base-japanese-v3")
model = BertModel.from_pretrained("tohoku-nlp/bert-base-japanese-v3")
# 設定
words = ["犬はかわいい"]
alpha = 0.9
# 指数移動平均を適用する回数
times = 1
# ベクトル計算
original_vectors = {}
smoothed_vectors = {}
for i in range(times):
for word in words:
vec = get_bert_vector(word, model, tokenizer)
original_vectors[word] = vec
smoothed_vectors[word] = repeated_ema(vec, alpha=alpha, times=i)
# グラフ描画
plt.figure(figsize=(12, 6))
x = np.arange(len(next(iter(smoothed_vectors.values()))))
for word in words:
plt.scatter(x, smoothed_vectors[word], label=word, s=10, alpha=0.7)
# plt.title(f"単語ベクトルのグラフ(EMA: α={alpha}, 適用回数={times})", fontproperties=jp_font, fontsize=14)
plt.title(f"単語ベクトルのグラフ", fontproperties=jp_font, fontsize=14)
plt.xlabel("次元によるインデックス", fontproperties=jp_font, fontsize=12)
plt.ylabel("ベクトルの成分値", fontproperties=jp_font, fontsize=12)
plt.legend(prop=jp_font, fontsize=12)
plt.grid(True)
plt.tight_layout()
plt.show()
[指数移動平均をとったら別のベクトルを見ていることになるんじゃ?って人のための解説]
上ではベクトル $\boldsymbol{v}$ に指数移動平均を適用し、$\boldsymbol{w}$ を作りました。その結果、$\boldsymbol{v}$ のときはバラバラだった点たちが、ある程度のまとまりを見せ始めました。
しかしここで、
「ベクトル $\boldsymbol{w}$ は $\boldsymbol{v}$ から計算された別のベクトルなんだから、$\boldsymbol{w}$ をいくら観察しても $\boldsymbol{v}$ を見ていることにはならないんじゃないの?」
と疑問に思う方もいると思います。しかし、心配ご無用です。なんと、
「1つのベクトル $\boldsymbol{w}$ は1つのベクトル $\boldsymbol{v}$ から唯一つに定まってしまう」
のです。つまり、ベクトル $\boldsymbol{w}, \boldsymbol{v}$ は同一視できてしまいます。ここからは、その理由を紹介します。
今回の観察で困ることは、2つの異なるベクトル $\boldsymbol{a}, \boldsymbol{b}$ があり、これらに指数移動平均を適用した場合に、全く同じベクトル $\boldsymbol{w}$ ができてしまう場合です。
そのようなことが起こると、どんなにベクトル $\boldsymbol{w}$ が優れた性質を持っていたとしても、もともと比較したかったベクトル $\boldsymbol{a}, \boldsymbol{b}$ の評価には使えません。
しかし、そんなことは絶対に起こらないということが次のように証明できます。簡単のために考えるベクトルの次元を3次元ベクトルに固定しておきましょう($n$ 次元でも考え方は同じです)。
次のように、ベクトル $\boldsymbol{a}, \boldsymbol{b}$ が与えられているとします。
\boldsymbol{a} = (a_1, a_2, a_3), \quad \quad \boldsymbol{b} = (b_1, b_2, b_3)
そして、それぞれに指数移動平均を適用して得られたベクトルはそれぞれ、
\begin{align*}
\boldsymbol{w_a} &= (a_1, \alpha a_1 + (1-\alpha) a_2, \alpha^2 a_1 + \alpha (1-\alpha) a_2 + (1-\alpha) a_3) \\
\boldsymbol{w_b} &= (b_1, \alpha b_1 + (1-\alpha) b_2, \alpha^2 b_1 + \alpha (1-\alpha) b_2 + (1-\alpha) b_3)
\end{align*}
となります。ただし、$\alpha$ は $0$ ~ $1$ の範囲の定数です。
ここで、
\boldsymbol{w_a} = \boldsymbol{w_b}
であると仮定して、指数移動平均の結果が一致してしまった場合、もとのベクトル $\boldsymbol{a}, \boldsymbol{b}$ の関係はどうなるのかを観察してみましょう。
ベクトルがイコールになるときに、それらベクトルの各成分どうしは等しくなります。そのため次の3つの式が成り立ちます。
\begin{align*}
a_1 &= b_1 \\
\alpha a_1 + (1-\alpha) a_2 &= \alpha b_1 + (1-\alpha) b_2 \\
\alpha^2 a_1 + \alpha (1-\alpha) a_2 + (1-\alpha) a_3 &= \alpha^2 b_1 + \alpha (1-\alpha) b_2 + (1-\alpha) b_3
\end{align*}
1つ目の式を2つ目の式に代入することで、
a_2 = b_2
が得られます。そしてさらに、この結果を1つ目の式と一緒に3つ目の式に代入することで
a_3 = b_3
が得られます。これは最初に与えられた2つのベクトル $\boldsymbol{a}, \boldsymbol{b}$ が同じベクトルであることを意味しています。つまり、
2つのベクトルの指数移動平均の結果が一致するのは、もとの2つのベクトルが等しい場合に限る
ということです。
したがって、指数移動平均の結果は「区別」という意味でもとのベクトルの情報を完全に保持しており、指数移動平均の比較結果をもとのベクトルの比較結果として扱うことも妥当であると考えられます。
高次元ベクトルを眺めてみよう。
指数移動平均は複数回適用するごとにグラフが滑らかになります。次の図は指数移動平均を「犬はかわいい」ベクトルに5回まで適用した際のベクトルの様子です。
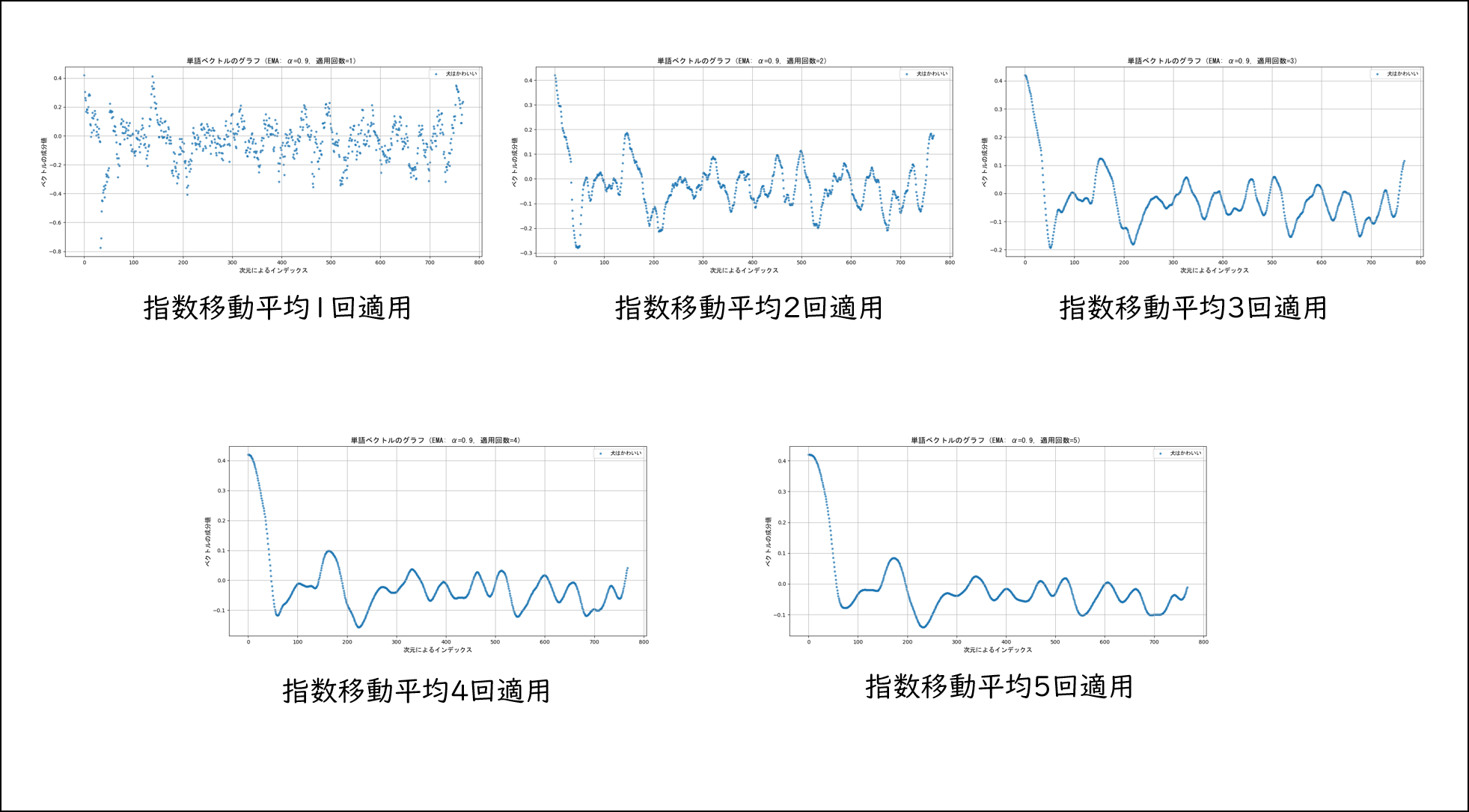
ここまでくるとさすがに異なるベクトルどうしを比較できるのではないでしょうか?
実際に上で紹介した3つのベクトルに指数移動平均を5回適用してプロットしたのが下の図です。
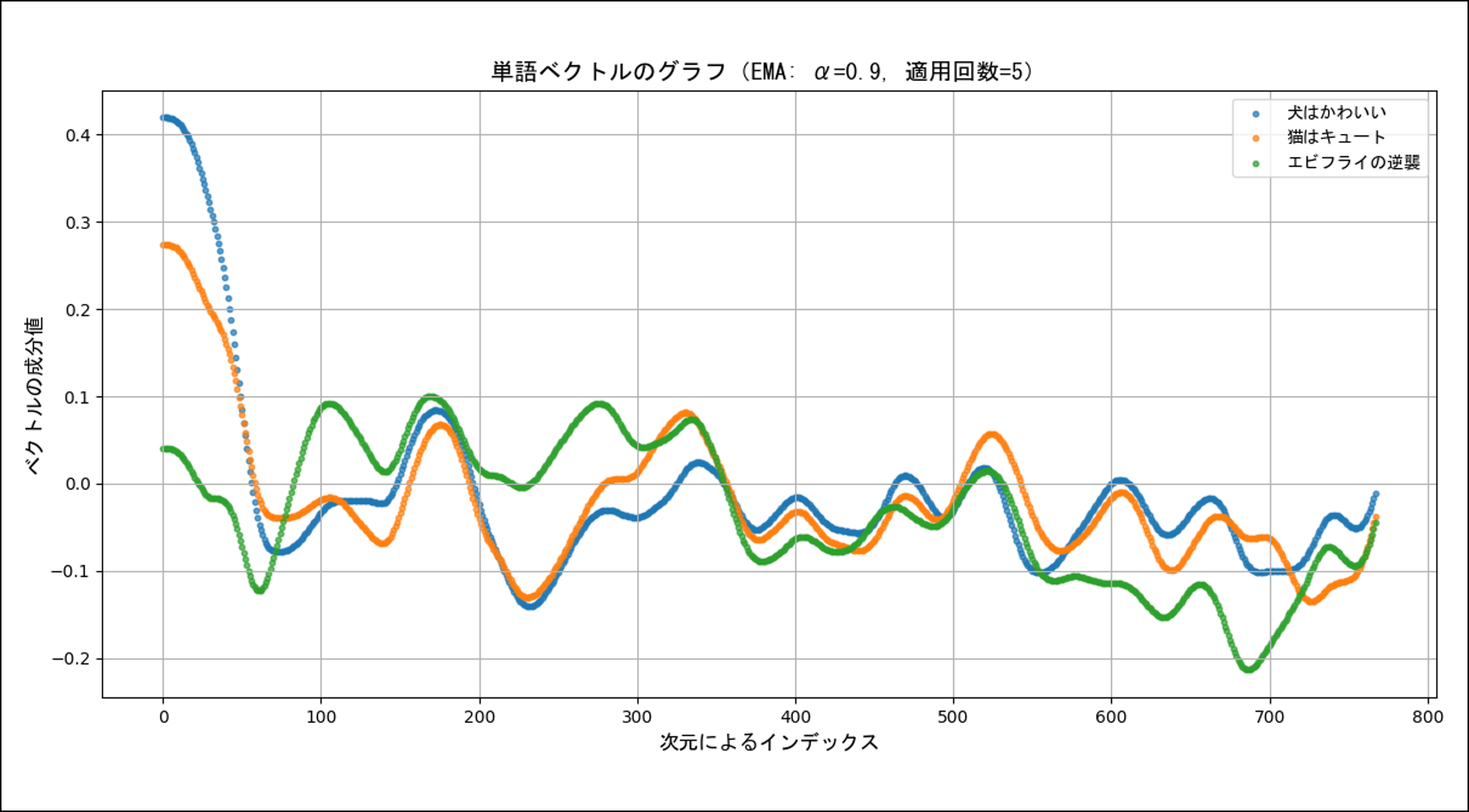
おー!けっこうイイ感じじゃあないですか!
意味が似ている文章のグラフは各所で類似の変化をしているみたいですね。もっと詳しく調べていけば、新しいベクトルの評価方法なども作れるかもしれません。
最後まで読んでいただきありがとうございました!
最後まで読んでいただきありがとうございました。
以前からやりたかった高次元ベクトルの可視化が、なんとか実現できました(すでに同じことはやられていそうですが)。
よく紹介されるようなベクトルを点として空間上にプロットする方法ではありませんが、もとのベクトルの情報を失わずに比較できるという部分で何かおもしろい発展ができるのではないかと思っています。
余談ですが、今回使った移動指数平均を同じベクトルに何回も適用すれば、おそらく、そのグラフが1つの定値関数に収束していくのではないか思います(証明はしていません)。もしかしたらその値がベクトルを識別または分類するための特別な意味を持つ値になるのでは?というような予想を素人ながらにしています。