レーシングシミュレータの実データを使って、データサイエンスの概念を実装とともに解説しています。この記事では 特徴量エンジニアリング(時系列の分解) を扱います。
こんな人に役立ちます
- 集約統計(mean/max/min/std)を超えた特徴量の作り方を知りたい
- 「どの特徴量が効くか」を仮説検証するプロセスを実データで追いたい
- 特徴量追加がモデル精度に与える影響を定量的に確認したい
結論
富士スピードウェイ1コーナー(T1区間、500〜1000m)のスロットル操作を時系列で分解した5個の特徴量を追加しました。
- CV R²:0.848 → 0.866(+0.018改善)
- 残差の標準偏差:0.1560秒 → 0.1464秒(-6.2%)
-
最も効いた特徴量:
throttle_above90_ratio(アクセル全開区間の割合)→ 全体3位の重要度(0.048) -
仮説(アクセルオン位置)は外れた:
throttle_above90_first_dist(アクセルを踏み始めた距離)の重要度は低かった(27位)
「いつ踏み始めたか」ではなく「どれだけ踏み続けられたか」が精度改善の鍵でした。
問い
前記事の残差分析で、次の仮説を立てました。
「アクセルオン位置(T1区間のどの距離でアクセルを踏み始めたか)という情報が欠けているため、モデルが外れるラップが生じている」
現在の特徴量はすべて T1区間全体の集約統計(mean/max/min/std)です。throttle_pct__mean=48% の2本のラップが「T1序盤は低く終盤に大きく開ける」と「終始中途半端に開け続ける」では実際のタイムが異なりますが、mean だけでは区別できません。
この仮説を検証します。スロットル操作を時系列で分解した特徴量を追加し、精度が改善するか——そしてどの特徴量が有効だったかを確認します。
この問い方はどんな分析プロジェクトにも応用できます。 「現在の特徴量で捉えきれていない情報は何か」を残差から仮説し、特徴量に変換して検証するサイクルは、モデル改善の基本的な手順です。
| 領域 | 集約統計の限界 | 時系列分解で追加できる情報 |
|---|---|---|
| モータースポーツ | throttle_pct__mean(平均開度) | いつ踏んだか・どれだけ続いたか |
| 製造業 | 温度の平均値 | 温度が上限を超えた時間・タイミング |
| EC | 訪問時間の合計 | どのページに長く滞在したか |
| 金融 | 月次平均残高 | 残高が閾値を下回った日数・時期 |
追加した5つの特徴量
T1区間(500〜1000m)を前半(500〜750m)と後半(750〜1000m)に分割し、スロットル操作の時間的な構造を捉えます。
| 特徴量 | 意味 | 平均値 |
|---|---|---|
throttle_first_half_mean |
T1前半(ブレーキング〜旋回)の平均スロットル | 23.3% |
throttle_second_half_mean |
T1後半(旋回〜加速)の平均スロットル | 73.7% |
throttle_above90_first_dist |
アクセル全開(>90%)になった距離(T1開始からm) | 0.73m |
throttle_above90_ratio |
T1区間中アクセル全開だった時間割合 | 45.6% |
throttle_ramp_rate |
アクセル増加フレームの平均増加幅(%/frame) | 7.0 |
T1_MID_M = 750 # 前半・後半の境界
THROTTLE_FULL = 90 # アクセル全開の閾値(%)
seg_first = seg[seg['dist'] < T1_MID_M]
seg_second = seg[seg['dist'] >= T1_MID_M]
# 前半・後半の平均スロットル
row['throttle_first_half_mean'] = seg_first['throttle_pct'].mean()
row['throttle_second_half_mean'] = seg_second['throttle_pct'].mean()
# アクセル全開になった最初の距離(T1開始からの相対距離)
above90 = seg[seg['throttle_pct'] > THROTTLE_FULL]
row['throttle_above90_first_dist'] = (
above90['dist'].iloc[0] - T1_START_M if len(above90) > 0
else T1_END_M - T1_START_M # 全開にならなかった場合はT1全長
)
# アクセル全開区間の割合
row['throttle_above90_ratio'] = len(above90) / len(seg)
# アクセル増加率(throttleが増加したフレームの平均増加幅)
diff = np.diff(seg['throttle_pct'].values)
pos_diff = diff[diff > 0]
row['throttle_ramp_rate'] = pos_diff.mean() if len(pos_diff) > 0 else 0.0
データ準備
使用ライブラリ:pandas、numpy、scipy、scikit-learn、matplotlib
元の24個の操作変数に5個を加えた29個でモデルBを構築し、元のモデルA(24個)と比較します。
op_cols = [...] # 元の操作変数24個
op_plus_cols = op_cols + NEW_THROTTLE_COLS # 追加後29個
# モデルA
X_a = StandardScaler().fit_transform(df_clean[op_cols].values)
cv_r2_a = cross_val_score(rf, X_a, y, cv=kf, scoring='r2')
y_pred_a = cross_val_predict(rf, X_a, y, cv=kf)
# モデルB
X_b = StandardScaler().fit_transform(df_clean[op_plus_cols].values)
cv_r2_b = cross_val_score(rf, X_b, y, cv=kf, scoring='r2')
y_pred_b = cross_val_predict(rf, X_b, y, cv=kf)
図1:CV R² の比較
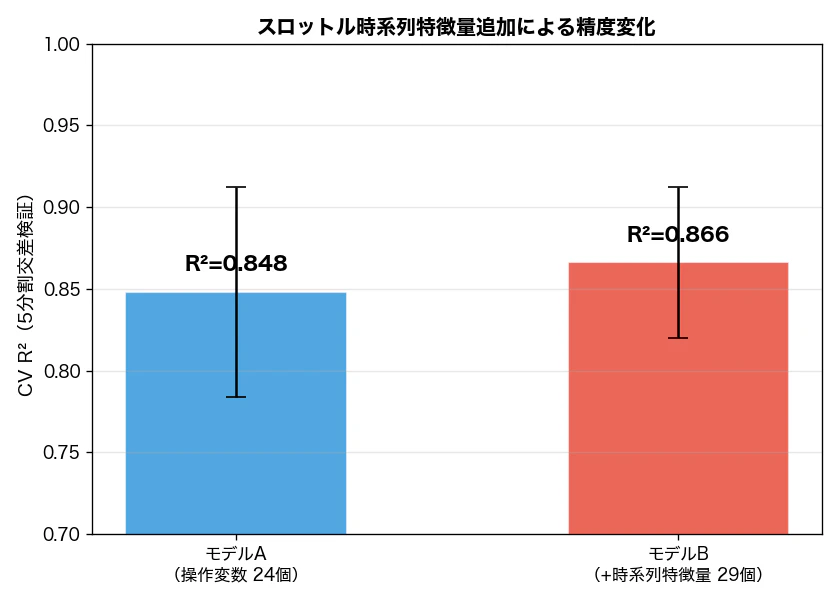
| モデル | CV R² | 残差 std |
|---|---|---|
| A(操作変数 24個) | 0.848 ± 0.064 | 0.156秒 |
| B(+時系列特徴量 29個) | 0.866 ± 0.046 | 0.146秒 |
CV R² が 0.848 → 0.866 に改善しました。+0.018 は一見小さく見えますが、すでに 0.84 台の高精度モデルに対する改善としては有意であり、相対的には約2%の精度向上に相当します。特徴量5個の追加効果としては実務上も十分な値です。注目すべきは CV R²スコアの標準偏差が 0.064 → 0.046 に縮小 している点です。5-fold交差検証ではデータを5分割し、各分割(Fold)を順番にテストデータとして使いながら5回評価します。この標準偏差はFoldごとのR²のばらつきを表しており、小さいほど「どのデータで評価しても安定して高い精度が出る」ことを意味します。
図2:残差分布の比較
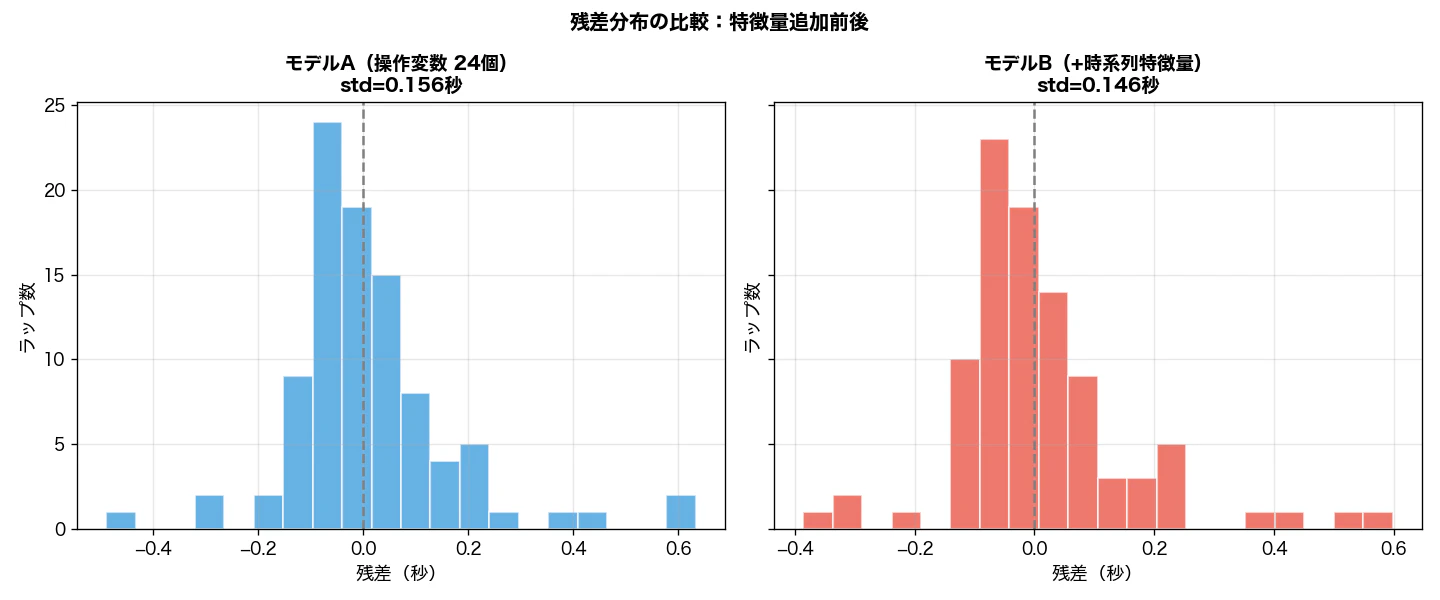
モデルBの残差分布はモデルAよりやや左右に締まっています。右テール(遅い方向への大外れ)の最大値が 0.633秒 → 0.598秒 に縮小しており、前記事で問題にしたラップの一部が改善されました。
図3:追加特徴量の重要度
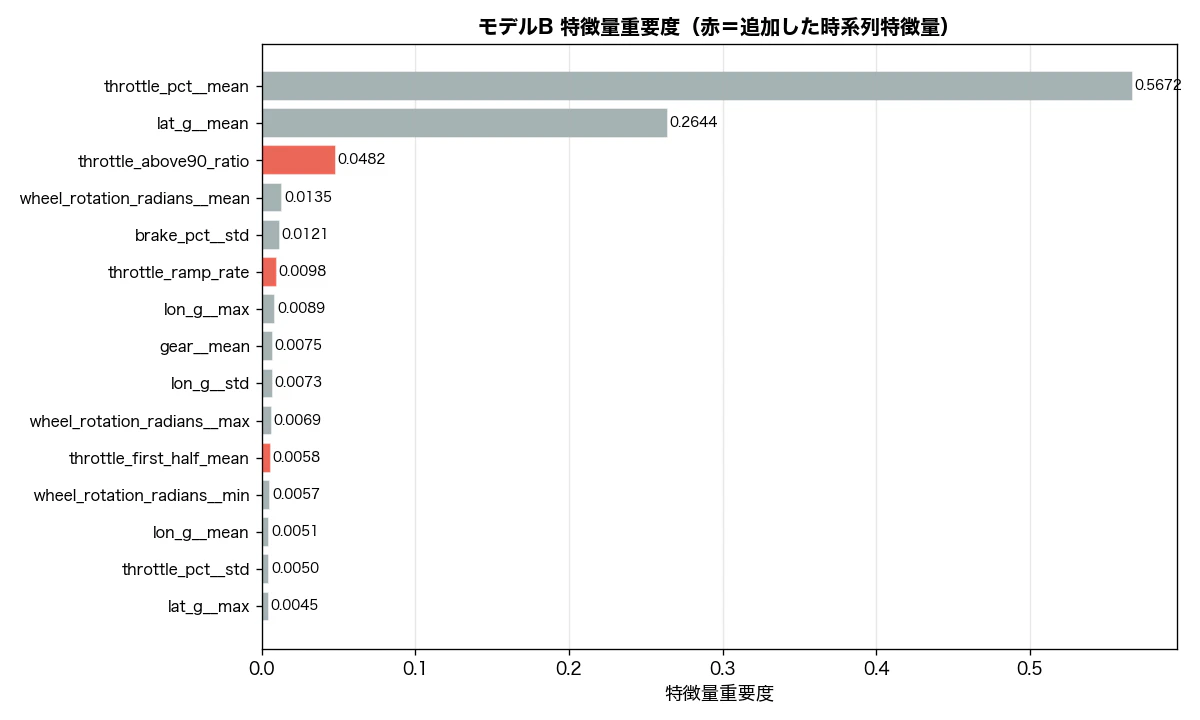
全体の特徴量重要度(上位10):
1. throttle_pct__mean 0.567
2. lat_g__mean 0.264
3. throttle_above90_ratio 0.048 ← 追加特徴量
4. wheel_rotation_radians__mean 0.014
5. brake_pct__std 0.012
6. throttle_ramp_rate 0.010 ← 追加特徴量
仮説していた throttle_above90_first_dist(アクセルオン位置)の重要度は 27位(0.003) と低く、仮説は外れました。この特徴量の平均値が 0.73m(std=0.59m)という点がその理由を示しています。T1区間はメインストレートからの高速進入で始まるため、ほぼすべてのラップで T1 突入時点からアクセルが全開(>90%)状態にあります。つまりこの特徴量は「コーナー出口でアクセルを踏み直した位置」ではなく「T1進入時点で全開だった最初の地点」を捉えており、ラップ間の差異がほとんど生まれませんでした。
代わりに有効だったのは throttle_above90_ratio(全開区間の割合、3位、0.048)です。「いつ踏み始めたか」ではなく「T1区間の何%を全開で走れたか」がタイムに直結していました。全開割合が効くということは、「早く踏む」よりも「安定して踏み続けられる状態を作れているか」が重要であり、これはコーナー出口での車両姿勢の安定性を間接的に表している可能性があります。
図4:アクセル全開になった距離 vs T1タイム(仮説の検証)
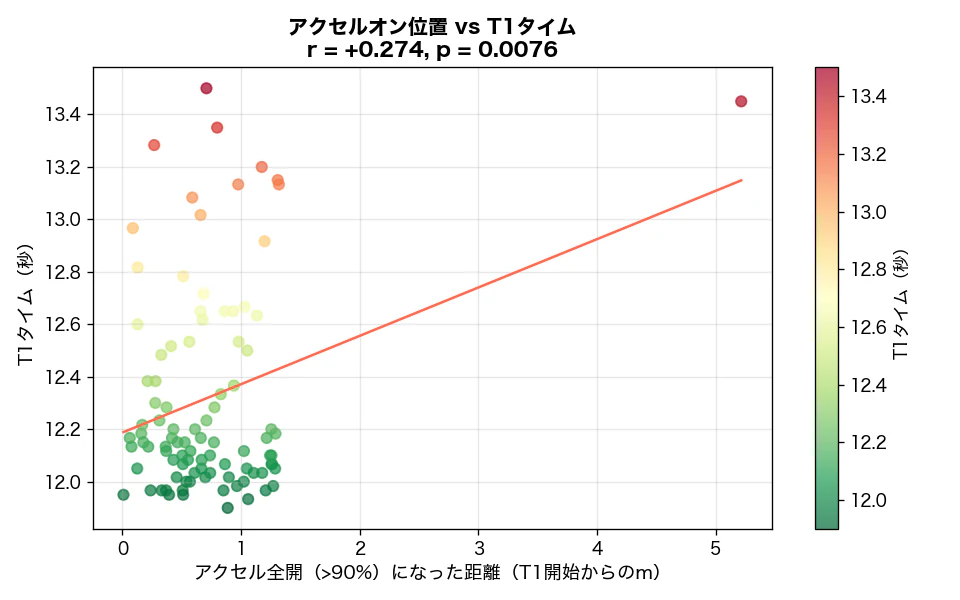
throttle_above90_first_dist(アクセルが全開になった距離)と T1タイムの散布図です。仮説では「早く踏み始めるほど速い」という右下がりのパターンを期待しましたが、相関は明確ではありません。
T1コーナーの構造(ブレーキング→旋回→加速)上、アクセルを踏み始める「位置」よりも「踏み続けた時間の割合」の方がタイムへの影響が大きいことを示しています。
大外れラップの改善
前記事で最大残差だったラップがモデルBでどう変わったかを確認します。
| idx | 実測 | モデルAの残差 | モデルBの残差 | 改善量 |
|---|---|---|---|---|
| 29 | 13.500秒 | +0.633秒 | +0.598秒 | +0.036秒 |
| 25 | 13.450秒 | +0.613秒 | +0.514秒 | +0.098秒 |
| 46 | 13.083秒 | +0.446秒 | +0.432秒 | +0.014秒 |
改善はありますが、大きくはありません。スロットル操作の時系列分解で捉えられるのは「アクセルを踏む量・タイミング」の情報だけです。これらのラップに潜む「説明できない遅さ」の主因は、現在の特徴量セットに含まれない走行ライン(軌跡)の情報にある可能性が高く、操作単体の分解には本質的な限界があります。
まとめ
| ポイント | 内容 |
|---|---|
| CV R² の改善 | 0.848 → 0.866(+0.018) |
| 最も効いた新特徴量 |
throttle_above90_ratio(全開割合、全体3位) |
| 外れた仮説 |
throttle_above90_first_dist(アクセルオン位置)は重要度27位 |
| 大外れラップへの効果 | 限定的(最大改善 0.098秒) |
残差分析から立てた仮説(「アクセルオン位置が鍵」)は外れましたが、時系列特徴量の追加自体は精度改善に有効でした。データサイエンスの実務では、仮説が外れることは珍しくありません。どの仮説が外れ、どれが当たったかを記録することが、次の改善につながります。
本記事の本質は精度の数値そのものではなく、「残差から仮説を立て、特徴量に変換し、検証する」というサイクルを実データで示した点にあります。操作変数の分解で残る限界(走行ライン)を次の問いとして、テレメトリの pos_x/pos_y/pos_z から軌跡特徴量を構築する方向に進みます。