はじめに
AIの発展に伴い、MLOpsに関する話題も盛んになってきています。ただ、ほとんどは本番環境用の話題で、開発環境整備についての話題が少ないように感じました。本番環境と違い、開発環境の整備はあまり重要視されてない場面も多いような気がしますが(Notebookで全部やってるなど)、研究開発環境も整ってないとすぐに深刻な状況になっていってしまうと思います。
そこで本記事では、開発環境整備の重要性と方法について書いてみようと思います。話題のKubeflow Pipelines(GCP AI-Platform Pipelines)、CloudTPU、TensorFlow等、これらの技術を使って環境構築を行なってきたのでその話をします。(互いに親和性が高く、やりたいことが十分に行えるため選定しました)
要約:現在の研究開発環境
これらの技術を使えば、簡単に以下のことができるようになります。
1. 作業・実験の記録(実験設定・結果・ログ・メトリクス)と単一ダッシュボードへの集約化
2. 一連の処理のパイプラインジョブ化による属人性排除
3. k8s、Preempt-TPUの利用(ジョブの分散並列化 & コスパの良いトレーニング)
4. エラー発生時の自動リトライ・復旧、ジョブ異常/正常終了時のSlack通知
5. 便利なプロファイリングツールによるボトルネックの発見
開発環境整備の必要性
まず、上記それぞれの話題に入る前に、開発環境整備の重要性について書いておきます。
環境整備を疎かにし、何も考えずに研究開発を進めると、非常に属人的になりやすく、お金や時間などのコスト効率も悪く、またストレスの溜まりやすい作業になる可能性が、ML系(特にDeep)においては極めて高いと考えています。
自分自身、学生時代は特に何も考えずに実験していて、使い捨てのスクリプトやNotebookが乱立し、管理もろくにできていないひどい状況に陥ってしまいました。
以下では、いくつかの観点において、環境が整備されてない場合に生じる問題を書いていきます(少し誇張したケースも含みますが、)。
「1. 作業・実験の記録管理」をやらない場合
- MLの実験では、複数バージョンのデータセットやモデルを使い分けたり、複数のパラメータが設定されて実験が行われます。実験設定と実験結果の記録が重要です。
- 整備されてない状態では、これらを手動で記録している、もしくは記録もせず個人の記憶に頼るような状態になります
これにより
=> 時間が経つにつれてスクリプトをどのように実行したか、つまり、どうやってデータセットを作ったか、どのデータセットでどうやってトレーニングしたか等が分からなくなってしまう。
=> 結果の再現ができず、他の実験との比較も困難な状況に陥る
「2. 一連の処理のパイプラインジョブ化による属人性排除」をやらない場合
- MLの実験を行うには、データ抽出・データ加工・トレーニング・評価など、一つの実験実施までに様々なステップがあり、様々なスクリプトを手作業で実行している
- 各処理のパラメータも手作業で設定して実行している状態
=> 人の入れ替わりがあったときに使い方が分からなくなって詰む。作成者本人も時間が経つと手順を忘れる
=> そもそも毎回手動でパラメータ設定・実行を行なっているとミスややり忘れも発生する
=> 非常に属人化してしまう
「3. k8s、Preempt-TPUの利用」をやらない場合
MLの実験は、大規模なデータを扱う上に、改善のために何度も実験サイクルを回すため、非常に時間とコストがかかる。使用するマシンスペックも基本高いものになる。
- GPUマシンやJupyterNotebookが立ちっぱなしというのがありがち
- とりあえずGPUを使うなどの安易な判断になる。大幅に改善できるはずの機会を逃す。
=> 1つの実験結果を得るまでの時間が長く、結果として本番リリースが遅れてしまう
=> コストも嵩み、プロジェクト自体が失敗に終わる可能性も。
「4. エラー発生時の自動リトライ・復旧、ジョブ異常/正常終了時のSlack通知」をやらない場合
- 実験では様々な要因でジョブ(及びその一部)が失敗する可能性がある
- 失敗の原因はコードのバグの可能性もあるし、MLにおいてはそれ以外のケースも多々ある
- 設定したパラメータが原因で生じたり(adamの勾配爆発など)、リソースが枯渇する(プリエンプトされたり)など様々
- エラー発生時に手動で再実行しなければならない。ジョブの状態も手動で確認が必要
- エラー終了に気づかなかったらそれだけ時間をロスすることにもなる
=> 実験ジョブの状況を常に気にしていなければならないため、他の作業に支障が出る
=> 実験の経過が気になって夜も眠れない
「5. 便利なプロファイリングツールによるボトルネックの発見」をやらない場合
- プロファイリングは特に気にせず実行している
=> 他のものと比べてそこまで必要性は高く無いが、TPU使う場合は、使用するモデルがTPUに対応しているかを確認するのに便利。モデルで実行される演算がどれくらいの割合でTPUに対応しているか、1トレーニングステップにおけるTPU利用率はどれくらいかなどを確認できる。
=> その他データパイプラインのボトルネックなども。
開発環境の整備
ここまで環境整備の重要性を書いてきましたが、ここからは、GCPのAI-Platform Pipelines(Kubeflow Pipelinesのマネージドサービス)とCloudTPU、TensorFlowを使った環境構築について書いていきます。
では、これらを使うことで開発環境がどんな感じになるか書いていきます。
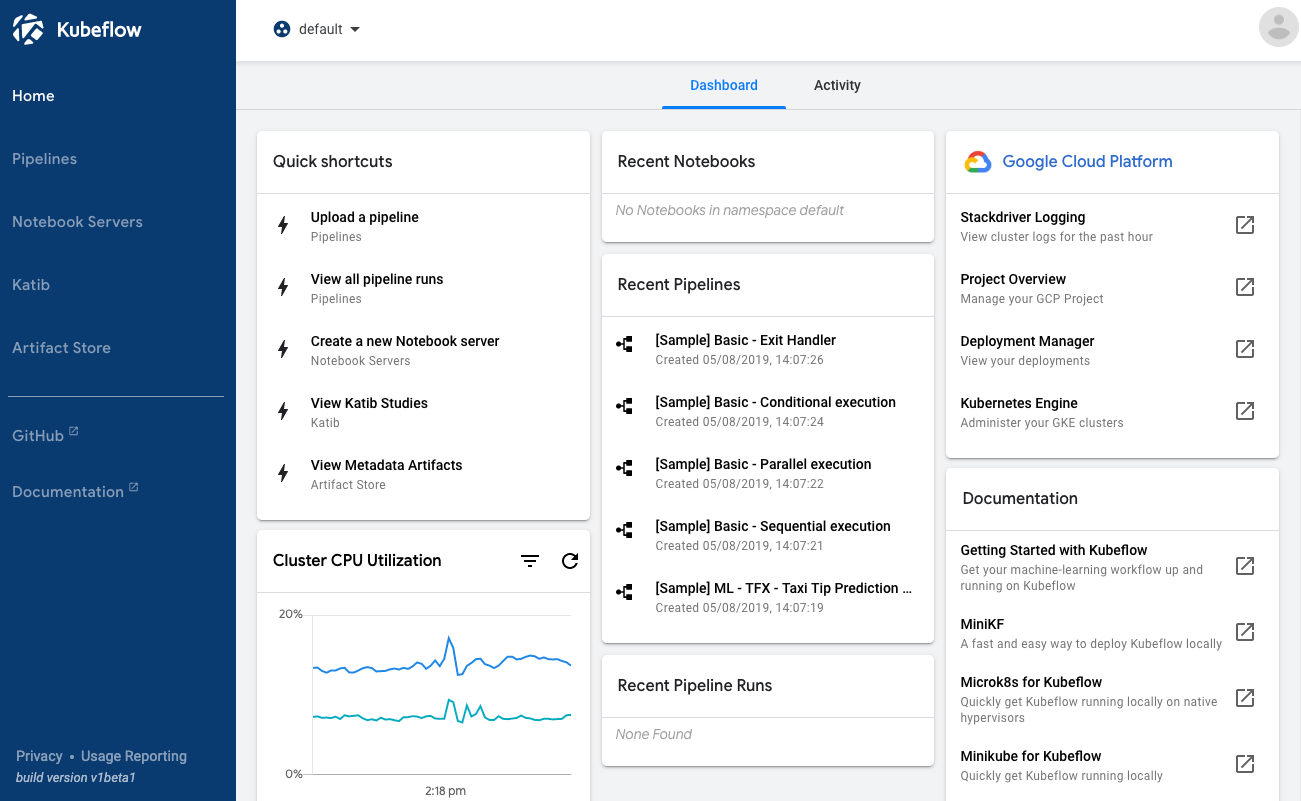
1. 作業・実験の記録管理(実験パラメータ・結果・ログ・メトリクス)と単一ダッシュボードへの集約化
Kubeflowを立ち上げると、以下のようなダッシュボードが起動できます(AI-Platform Pipelinesの場合はKubeflowの中でもPipelinesだけなので機能が絞られていますが、以下の内容は同じです)。
引用:https://www.kubeflow.org/docs/components/pipelines/introduction/
基本的にこの画面上から以下のようなあらゆる操作が可能です。パイプラインの開発(コーディング)以外は基本的にここだけで完結するのは嬉しいところです(Stackdriverのリンクを踏んだりはありますが)。
- パイプラインジョブの実行
- パイプラインの閲覧、追加・削除
- 実験の記録(パラメータや結果など)
- 実験一覧画面、詳細画面の閲覧
- その他関連機能
実験結果の可視化
Kubeflow Pipelinesでは、ダッシュボード上で結果を可視化する方法が色々と用意されています。その中でも、tensorboardをKubeflowのポッドとして任意に起動できるのがかなり便利です(普通はtensorboard用にサーバとか用意しなきゃだった)。
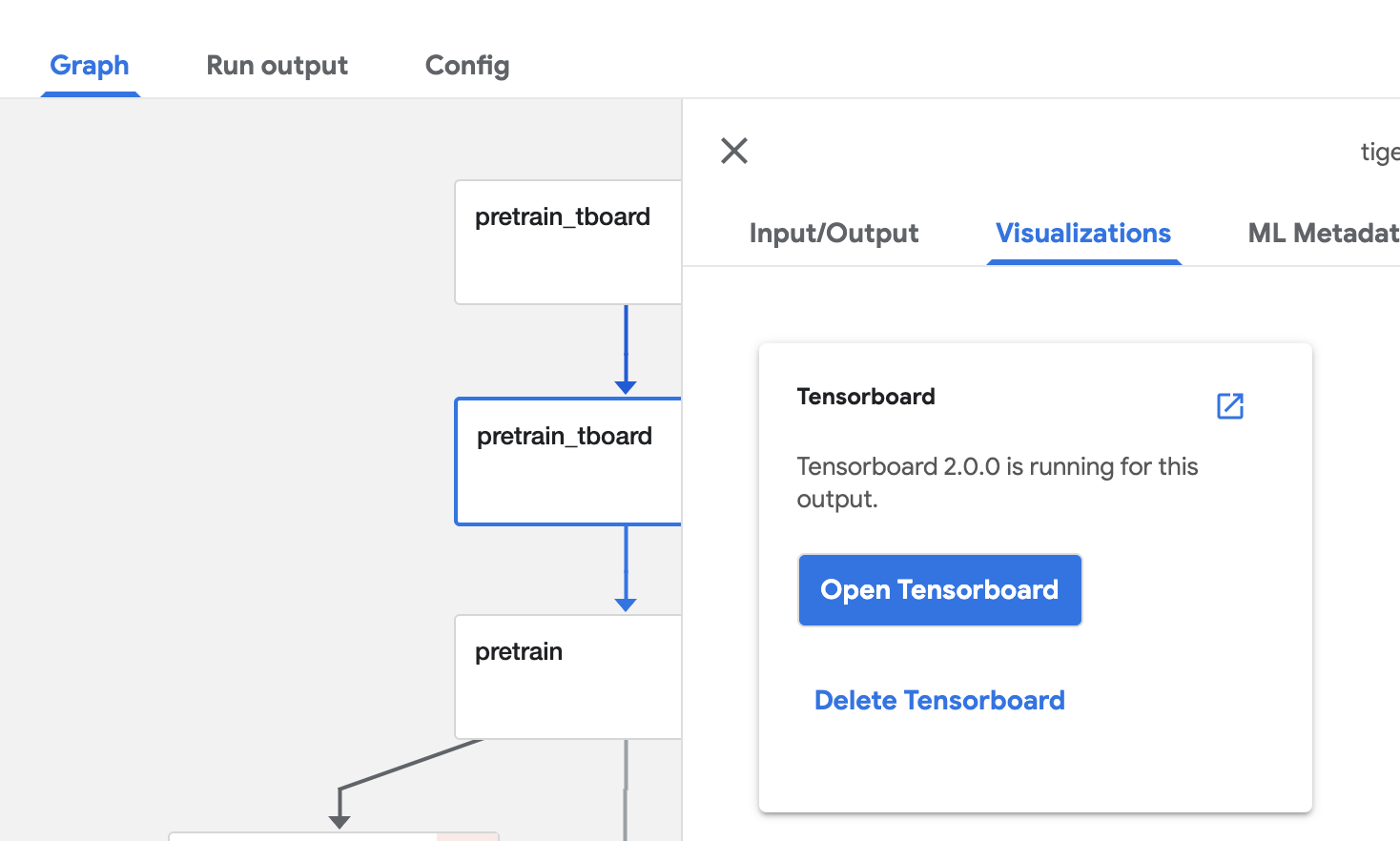
引用:https://www.kubeflow.org/docs/components/pipelines/introduction/
↑簡単な設定をするだけで任意のタイミングでTensorBoard用ポッドの起動が可能(見たい時にすぐ見れるのはすごく便利)
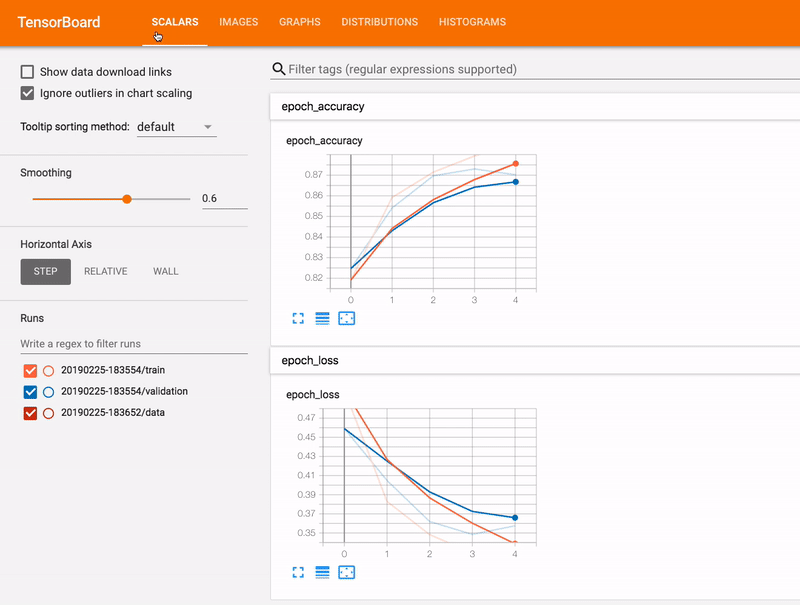
TensorBoard自体、可視化ツールとしてすごく高機能ですし、使っている人も多いと思います。ここが連携しているのは便利な部分です。
2. 一連の処理のパイプラインジョブ化による属人性排除
これもKubflow PipelinesのDSLを使用することで簡単に構築できます。基本的に、Dockerイメージにまとめたタスク処理単位(コンポーネント)を任意に繋げてパイプライン化しています。
以下がパイプラインの例です。以下のような複雑なジョブも、パイプラインパラメータの設定と開始ボタンを押すだけで実行できます。
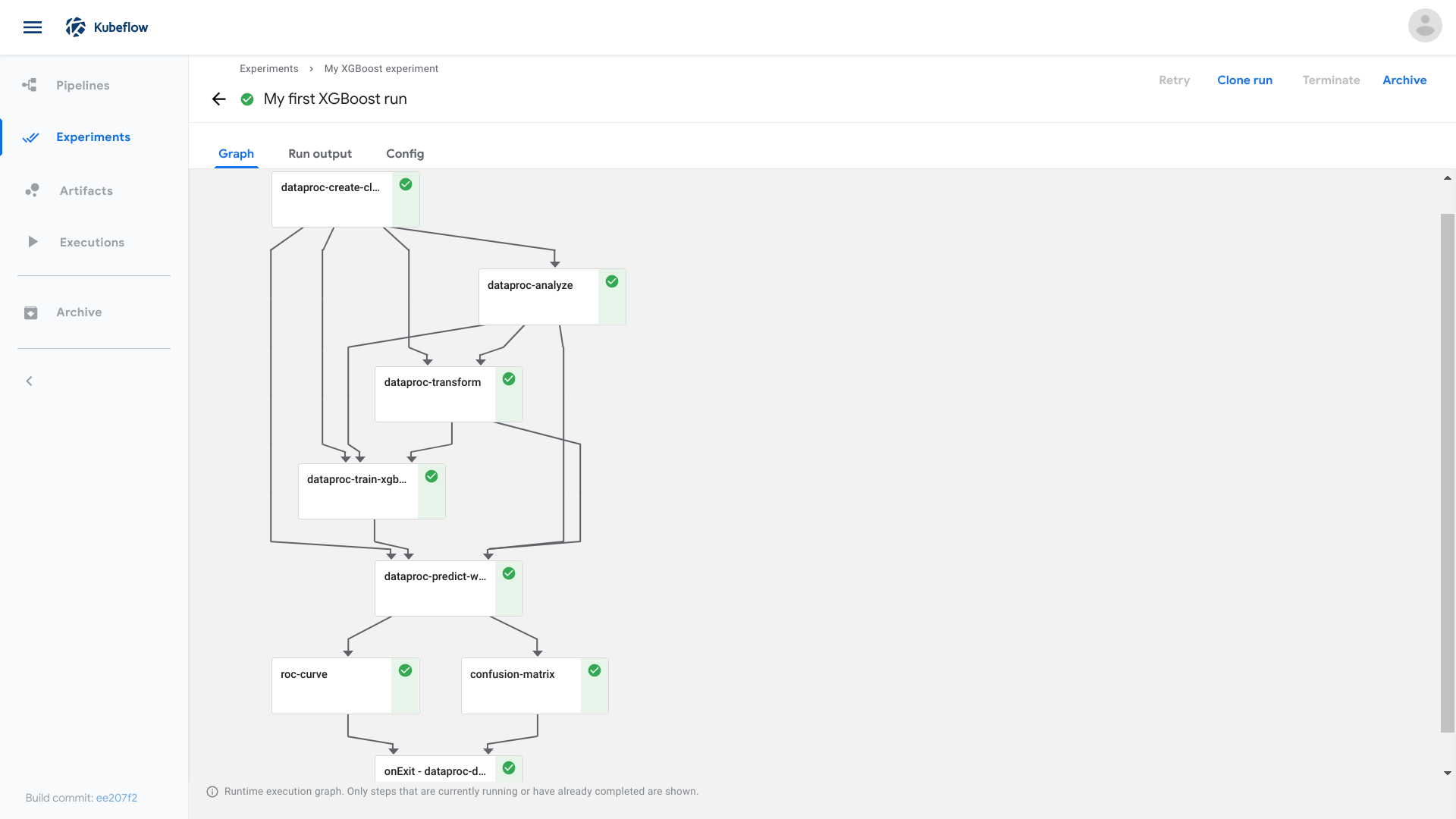
引用:https://www.kubeflow.org/docs/components/pipelines/introduction/
パイプラインジョブ化することを意識しておくことで、一連の処理フローが明確に定義され、複雑なステップを踏まずにコマンド一発で実行できるようになります。これだけでも、属人化を大分防げると思います。
3. k8s、Preempt-TPUの利用(ジョブの分散並列化 & コスパの良いトレーニング)
k8sの利用
AI-Platform Pipelinesを使用すればバックエンドはk8sです。必要な時に必要なリソースのみ使うというだけでも、Notebook立ちっぱなしなどよりは大分ましになりますが、それ以上にジョブの分散並列化が簡単にできる点が強力です。
KubeflowのDSLを使えば簡単に分散処理にすることができます。公式サンプルの例を以下に載せておきます。dsl.ParalelForで並列化します。
@dsl.pipeline(name='my-pipeline')
def pipeline():
loop_args = [{'A_a': 1, 'B_b': 2}, {'A_a': 10, 'B_b': 20}]
with dsl.ParallelFor(loop_args, parallelism=10) as item:
print_op(item)
自分はdsl.ParalelForをやる前のタスクで、GCSのジョブディレクトリのファイルリストを出力させ、そのファイル単位で分散並列化させるのをよくやっています。ジョブファイルは予め分割しておいておきます。
def load_data_chunk_op(
dataset_path: str,
):
return dsl.ContainerOp(
name='data_chunk_loader',
image='gcr.io/〇〇', # gsutilが使えるイメージを指定
command=['sh', '-c'],
arguments=['gsutil ls $0/* | jq -R -s -c \'split("\\n")\'[:-1] > /tmp/out.json', dataset_path],
file_outputs={'out': '/tmp/out.json'},
)
# ParallelForの引数は以下を指定
with dsl.ParallelFor(load_chunk_task.output) as item:
〇〇_task = 〇〇_op(item)
こんな感じで簡単にできます。
CloudTPUの利用
TPUはお金がかかる印象があるかもしれませんが、実は結構コスパが良いです。以下にTPUとGPU(v100)のコスト表を載せておきます。
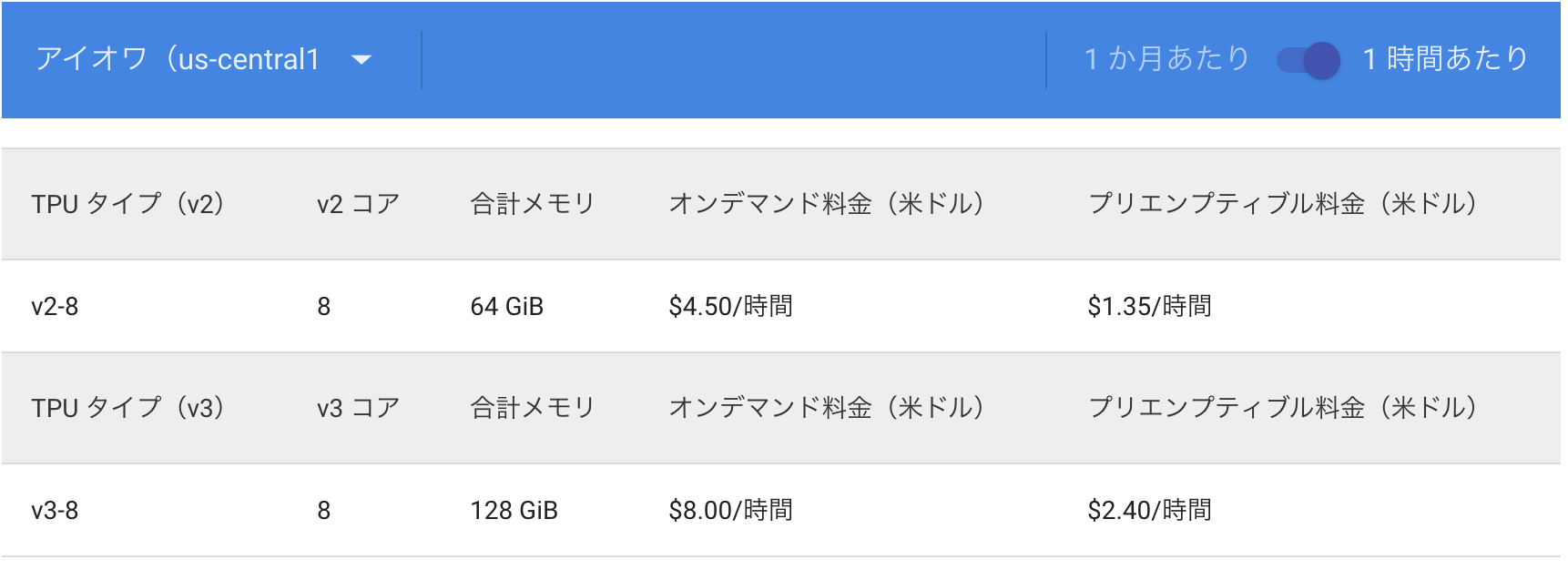
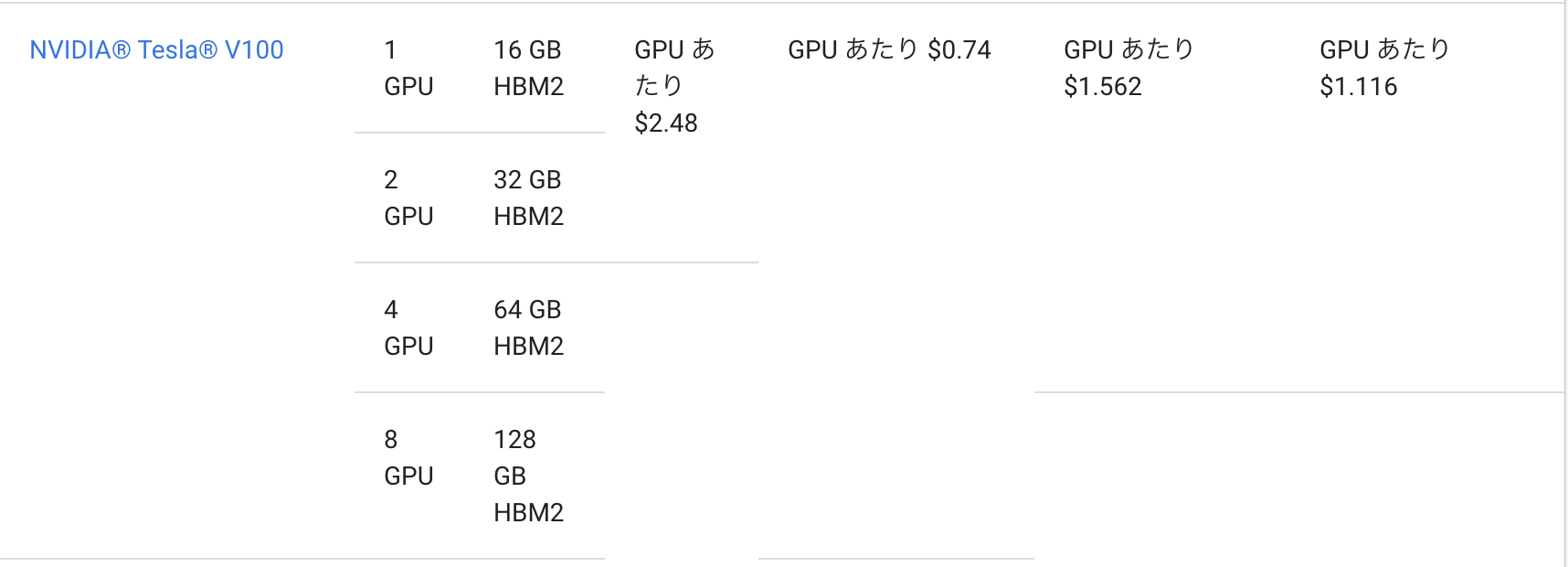
両方プリエンプティブの料金で比較すると、TPU v3-8は$2.4/h、一方、GPUは(同様に8台換算で)$5.92/hです。このようにコスト的にも実は安く、尚且つトレーニング時間も何倍に減らせるので、TPUに対応しているモデルであればTPUを使った方が圧倒的にコスパが良くなります。ML実験ではトレーニングで待たされる時間が大半を占めるので、ここを減らせるとすごく楽になります。
実装については、TensorFlowのDistributeStrategyを使うと簡単にTPUを利用できます。後述のプロファイリングツールを使えば、使おうとしているモデルがどれくらいTPUに対応しているかを測ることもできます。
文献
4. エラー発生時の自動リトライ・復旧、ジョブ異常/正常終了時のSlack通知
リトライ機能はKubeflow Pipelinesに実装されているので、簡単にできます。とにかく、ジョブ実行後に実験の状態を気にしていなければならない状態からできるだけ開放されることが目的です。開発者がやるべきことは、処理途中の適切な状態保存と再開処理の実装です。以下の観点が必要です。
- ジョブIDでの管理
- パイプラインパラメータとして渡す
- 中間ファイルや成果物の保存先のパスに含める
- ジョブIDのパス見に行って色々制御(スキップとか)
- パイプラインパラメータとして渡す
- トレーニング状態の保存・復旧
- 重みパラメータの保存
-
Optimizerの状態保存(これも大事)
-
tf.keras.Modelを使っていれば、model.save時にOptimizerの状態も保存してくれる(引数include_optimizerで保存切り替え) - これ意外と考慮されてないケースが多いが、学習率などに関わる重要な部分
-
TPUのプリエンプト時の復旧
これは自前でやろうとすると結構大変だったんですが、TPUもKubeflowの管理下にしておけばすごく簡単です。手順は以下の通りです。
- Kubeflow PipelinesをデプロイするGKEクラスタの設定から、
TPUの有効化をON - パイプライン定義のところでTPUを使用する設定を適用
training_task = \
training_op(...) \
.apply(gcp.use_preemptible_nodepool()) \
.apply(gcp.use_tpu(tpu_cores=8, tpu_resource="preemptible-v3", tf_version="nightly")) \
.set_retry(num_retries=2)
これだけで、このタスクの実行時に勝手にTPUが起動し、終了した時にTPUの削除も行なってくれます。TPUのプリエンプトの検知もやってくれて、リトライを設定しておけば自動復旧されます。TPUのプリエンプトはリソース枯渇以外にも24時間で必ず発生するという仕様があるので、これをやっておくと便利です。
=> これらにより、ジョブ実行後に人の監視・オペレーションはいらなくなります。
=> Slack通知の設定もしておけば、異常終了にしても正常終了にしても通知を待てば良いので、ジョブを気にすることなく他の作業に打ち込めることになります。
※Slack通知はkfp.dslのExitHandlerを使って実装します。
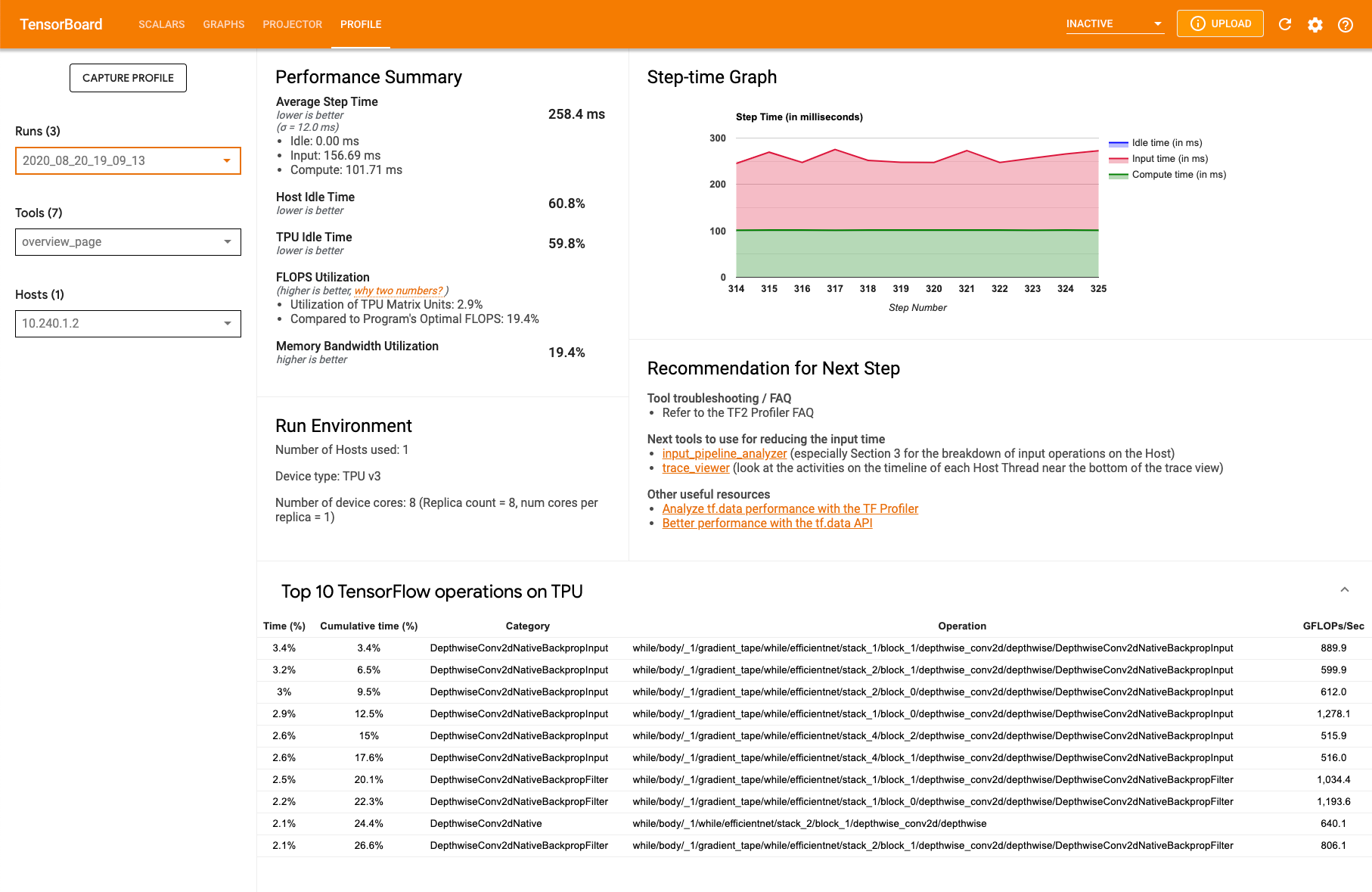
5. 便利なプロファイリングツールによるボトルネックの発見
ここはオプションの話題ですが、TPU Profiler tensorboardプラグインというのがあって、これがすごく便利です。以下のようにtensorboard上でTPUのプロファイリング情報を確認できます。詳細はこのページ:https://cloud.google.com/tpu/docs/cloud-tpu-tools?hl=ja
-
入力パイプラインのボトルネックを調べたり
-
各レイヤーOpのTPU互換性も見ることもできる
- 特にカスタムレイヤーを実装する場合に有用
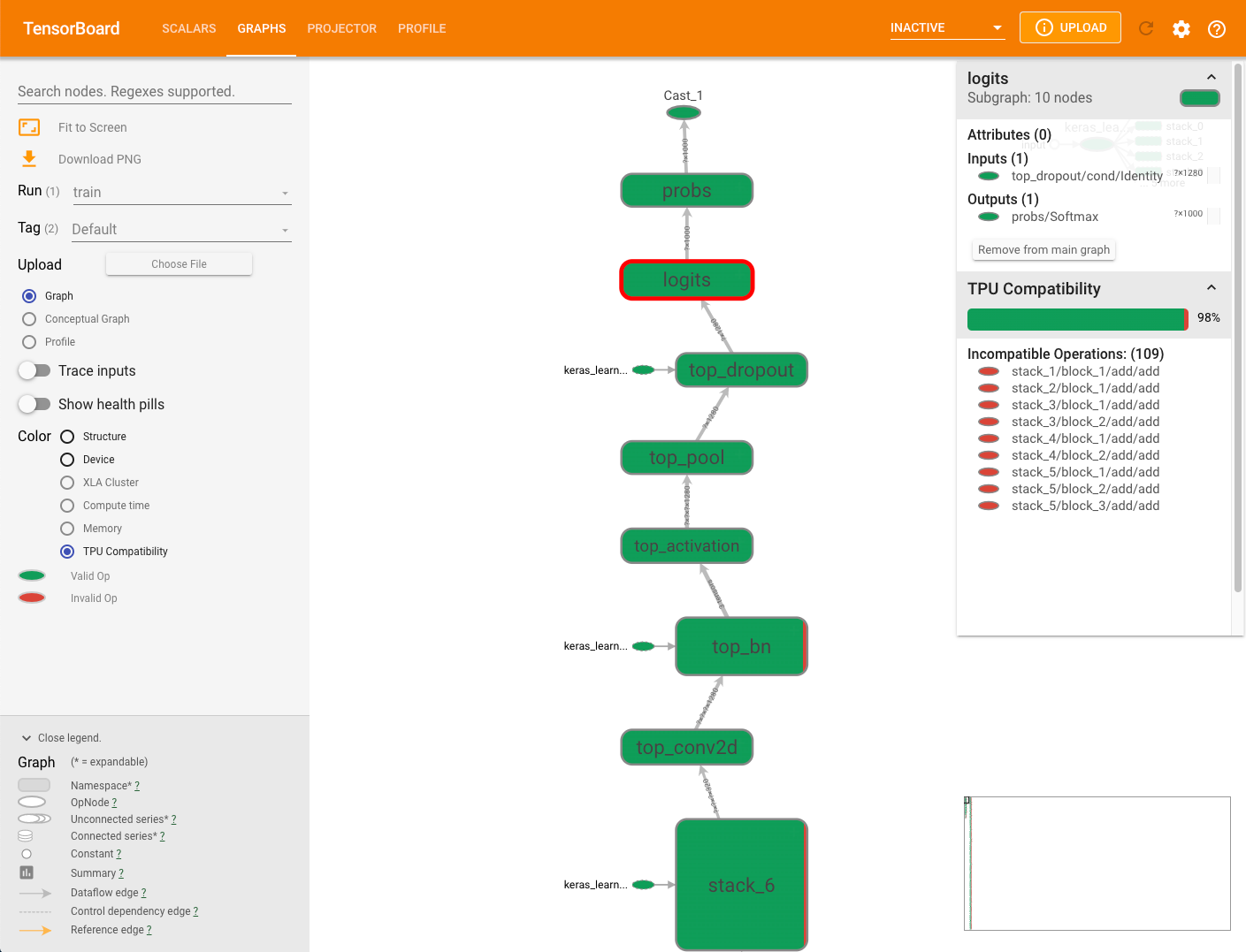
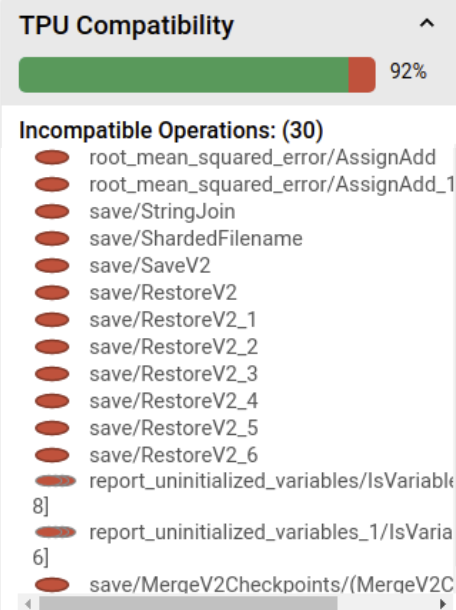
対応していない演算は上記のように赤く表示される。
備考
- 本来tensorboard画面上から任意のタイミングでTPUのプロファイリングを実行して確認できるが、Kubeflow PipelinesがTensorBoard起動用に使ってるDockerイメージ(
tensorflow/tensorflow)が必要なパッケージが足りない都合で実行できないので、プロファイリングは別途実行する必要がある - 自前でKubeflowをデプロイする際は、ここのイメージを変えれば良い
6. CI/CD(追記)
ここのリポジトリが参考になる。
https://github.com/ksalama/kubeflow-examples/tree/master/kfp-cloudbuild
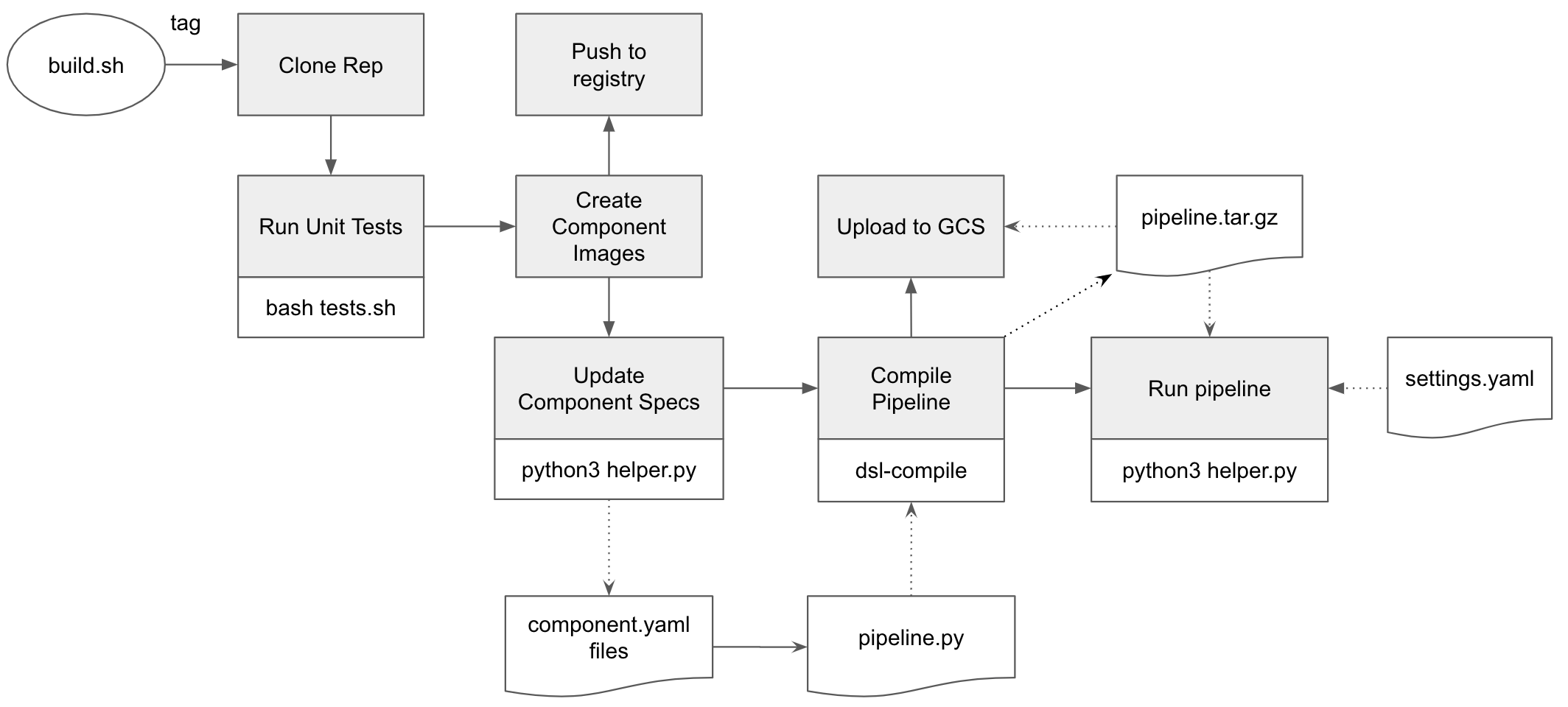
特にコンポーネントのバージョン(Dockerイメージのバージョン)とパイプラインのバージョンの対応付けに難しさを感じていたが、上記のUpdate Component Specsのステップで解決している。
まとめ
長々と書いてしまいましたが、こんな感じで、環境整備をやるのとやらないのでは大分違いが出ると思います。何よりいろんな部分が整備されていると、かっこいいし、良い気分で研究できるというのも大きなメリットだと思います。開発環境整備の参考になれば幸いです。