1. はじめに
- 2018年11月12日のリリース時から気になっていた Amazon Aurora カスタムエンドポイント をようやく試すきっかけができたので、いろいろ検証してみた結果と考察の備忘録。
- 定時バッチの重い参照系クエリによる長時間DB負荷を、カスタムエンドポイントを使えばサービス用DBから分離できるのか、というのが今回の検証の目的。
2. 使うべきかどうかの最重要ポイント
-
リリース内容はいい感じに書いてあるけど、実際は「目的」「コスト」「スケールアウト/イン」「フェイルオーバー」といった要素を総合的に考慮して、利用すべきかどうかを検討する必要がある。
-
特に注意すべきポイント
編集アクションによる変更の進行中は、カスタムエンドポイントへの接続やカスタムエンドポイントの使用はできません。エンドポイントのステータスが [使用可能] に戻り、再度接続できるようになるまでに数分かかることがあります。
(引用元: https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/Aurora.Overview.Endpoints.html#aurora-endpoint-editing)これの挙動を確認したところ、カスタムエンドポイントの設定変更進行中は、そのカスタムエンドポイントを名前解決してもメンバーのインスタンス情報が返ってこなくなる状態が数分間あった。
つまり、カスタムエンドポイントに新しくレプリカを追加する、あるい、カスタムエンドポイントからレプリカを削除するなどで、カスタムエンドポイント設定に何からの編集を行うと、変更進行中の数分間、そのカスタムエンドポイントのメンバーインスタンスにDB接続ができなくなる。そのカスタムエンドポイントが集計や分析などのバッチ用途ならまだ許容できるが、サービス用の読み込み利用であれば致命的だ。
-
サービスへ影響を与えることなくカスタムエンドポイントのメンバーを変更する方法はあるが、手順が増えるため対応スピードは落ちる。
-
レプリカを追加する場合の手順
- 「クラスター内に新たに作成されたインスタンスをクラスターエンドポイントに自動的に追加するかどうかを設定」を無効
- レプリカ作成
- 新しいメンバー構成を設定したカスタムエンドポイントを新規に作成
- プログラム側でエンドポイントを入れ替える
3. バッチ用 replicaインスタンス 導入検証
- いくつかのAuroraクラスター構成を想定して、実際に設定を行い挙動を確認する。
- カスタムエンドポイントの作成や設定変更は terraform を使う。
- AWSマネジメントコンソールからカスタムエンドポイントを作成した場合は、カスタムエンドポイントのタイプが必ず「ANY」になってしまう。
- terraform は、カスタムエンドポイントのタイプを「READER」に設定することができる。
3.1. 検証1
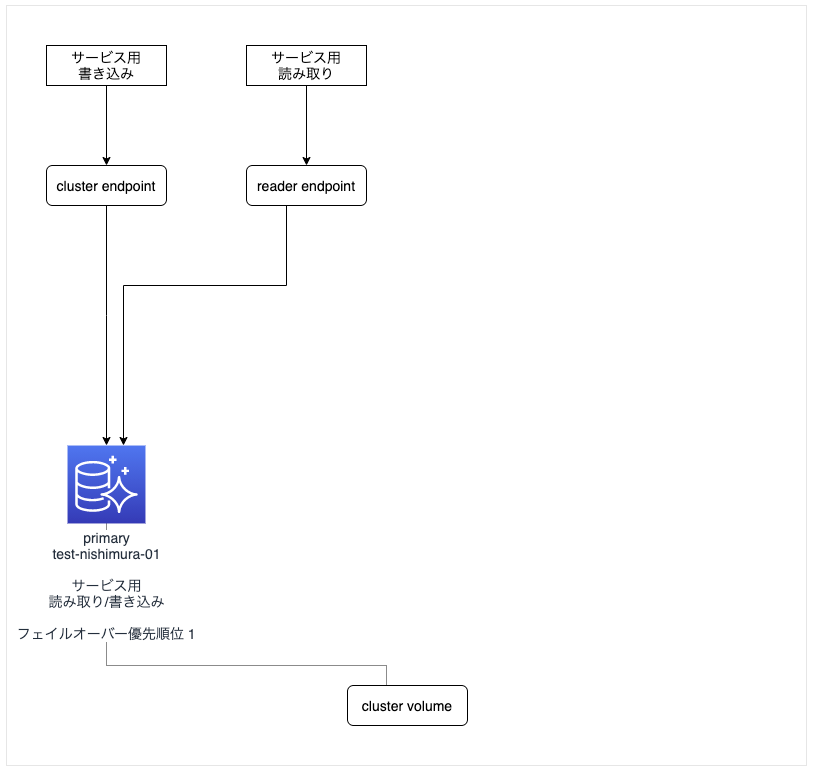
元の構成
- 1つの primary インスタンス「test-nishimura-01」で「サービス用書き込み」と「サービス用読み込み」を行う構成。
- コスト重視で冗長性はない。
- 図
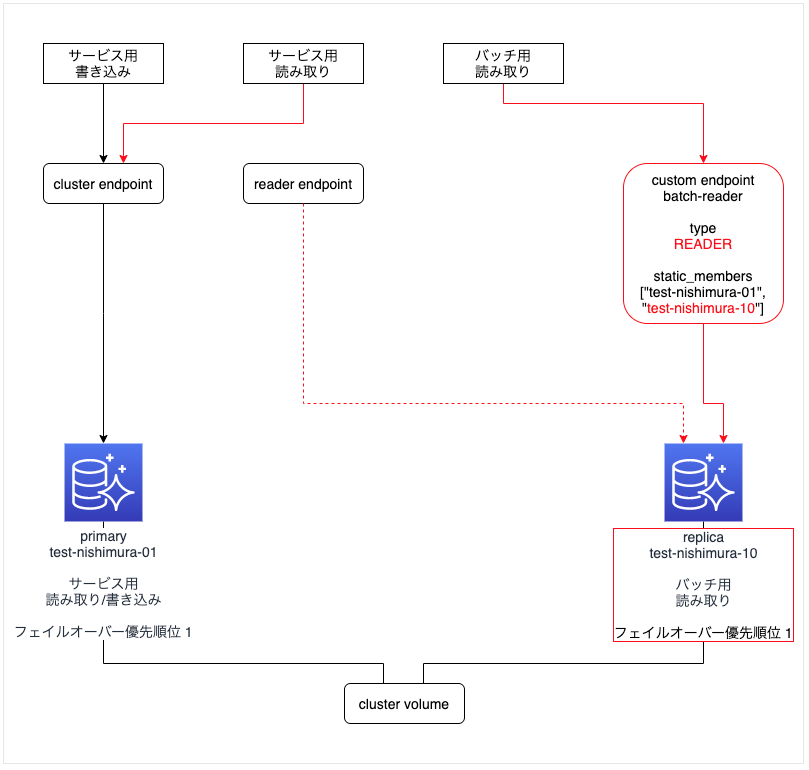
バッチ用 replica インスタンスを追加した構成
- バッチ用 replica インスタンス「test-nishimura-10」を作成する。
- フェイルオーバー優先順位を primary インスタンスと同じにする(ここでは "1" にしている)。
primary インスタンス「test-nishimura-01」をフェイルオーバーする
- 「test-nishimura-01」と「test-nishimura-10」のフェイルオーバー優先順位が同じ "1" なので、replica だった 「test-nishimura-10」 が昇格して primary になり、「test-nishimura-01」が replica となった。
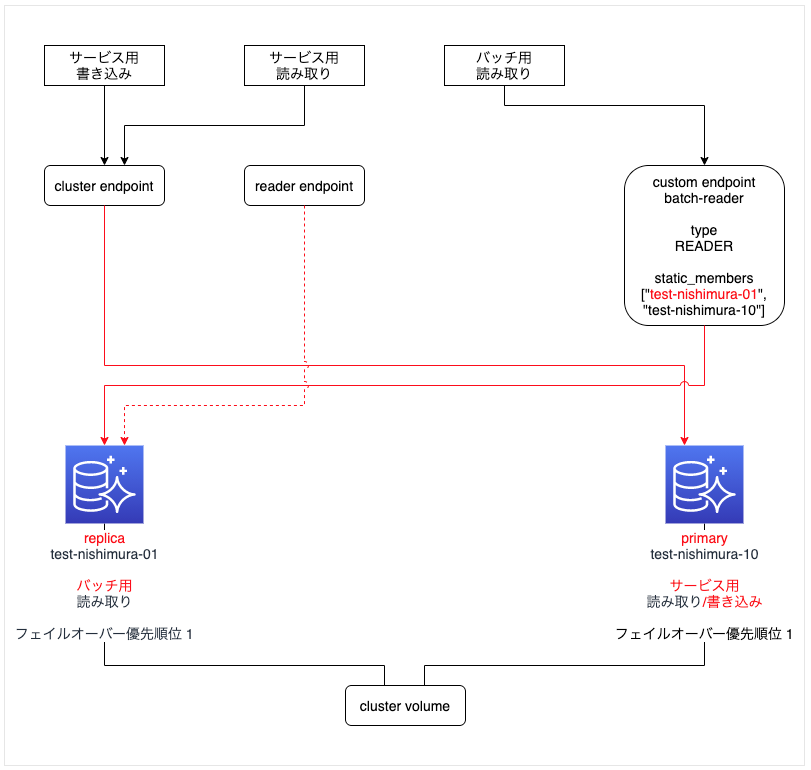
考察
- フェイルオーバー後も、サービス用とバッチ用でインスタンスを分離することができる。
- フェイルオーバーによりインスタンスの役割が入れ替わったので、サービス用とバッチ用のインスタンスクラスは同じにする必要がある。
- 追加した replica インスタンスは、バッチ用に加えてサービス用のフェイルオーバーとしても機能するので、クラスターの冗長性を確保できるようになった。
3.1. 検証2
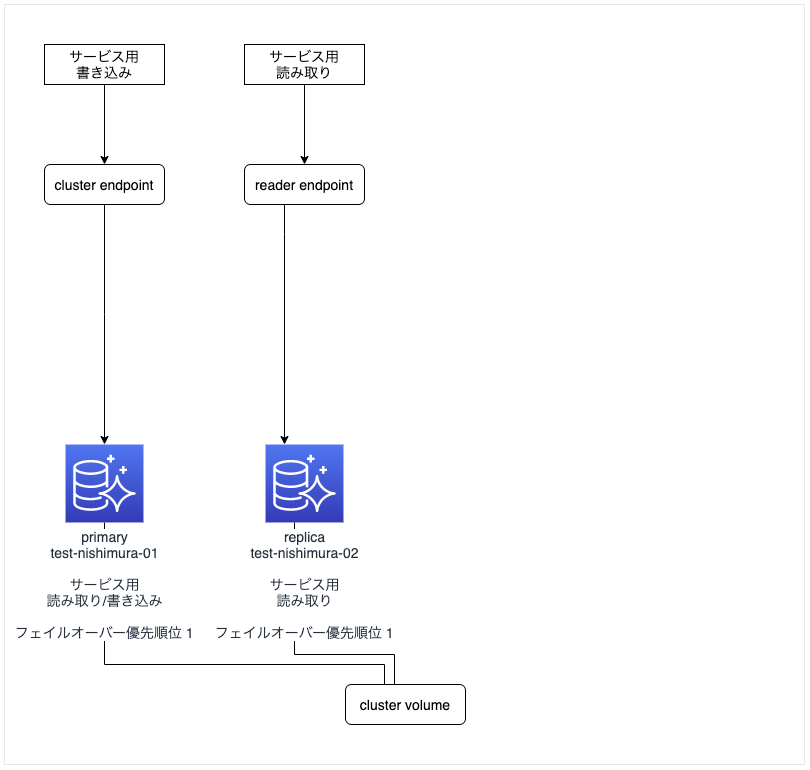
元の構成
- 1つの primary インスタンス「test-nishimura-01」で「サービス用書き込み」を、1つの replica インスタンス「test-nishimura-02」で「サービス用読み込み」を行う構成。
バッチ用 replica インスタンスを追加した構成
- バッチ用 replica インスタンス「test-nishimura-10」を作成する。
- フェイルオーバー優先順位をサービス用インスタンス群より低い数値にする(ここでは "10" にしている)。
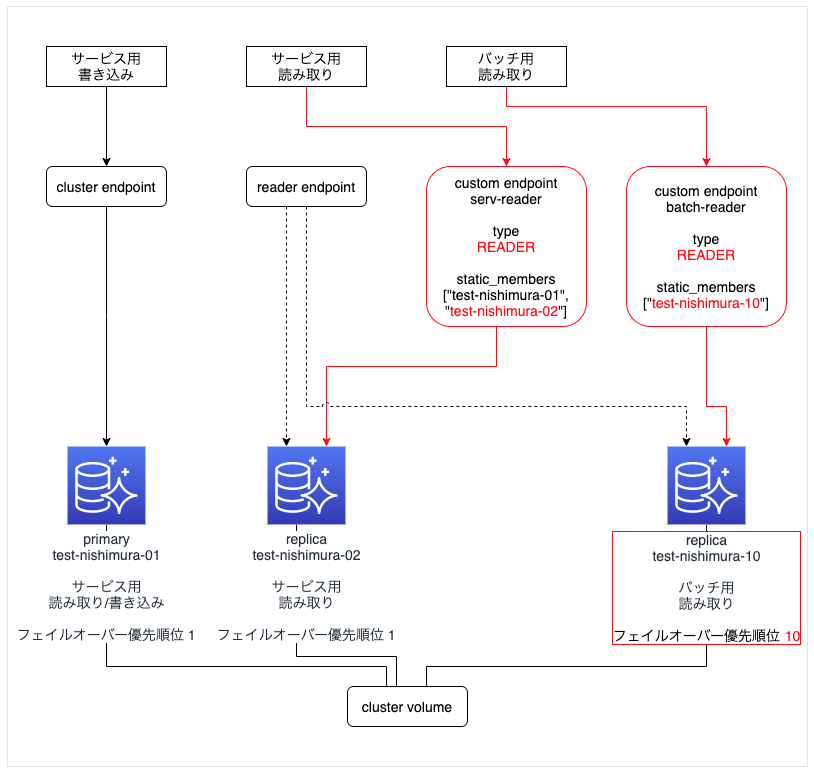
primary インスタンス「test-nishimura-01」をフェイルオーバーする
- 「test-nishimura-01」と「test-nishimura-02」のフェイルオーバー優先順位が同じ "1" なので、replica だった 「test-nishimura-02」 が昇格して primary になり、「test-nishimura-01」が replica となった。

考察
- フェイルオーバー後も、サービス用インスタンス と バッチ用インスタンス を完全に分離できる。
3.3. 検証3
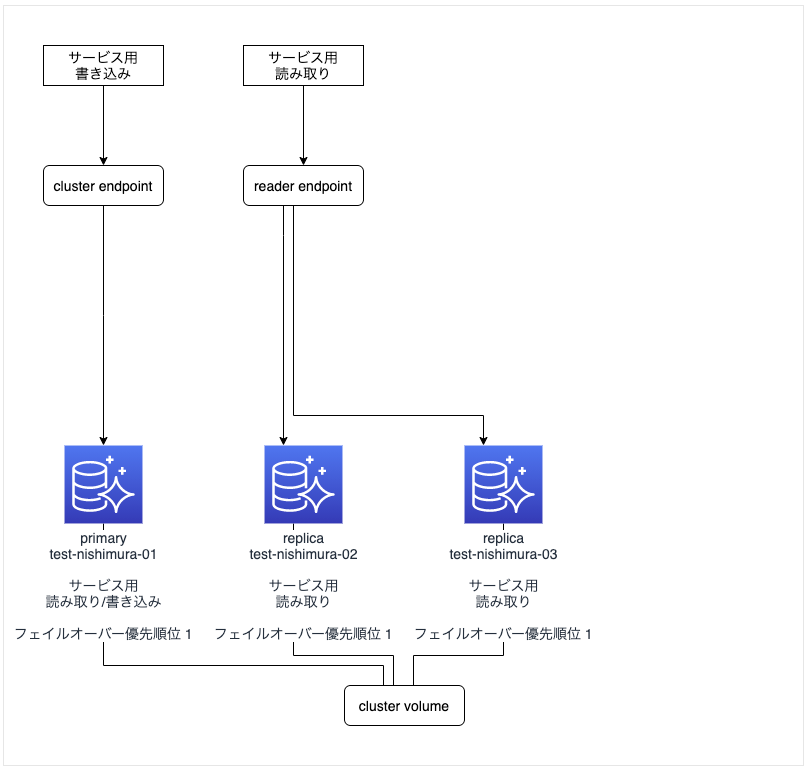
元の構成
- 1つの primary インスタンス「test-nishimura-01」で「サービス用書き込み」を、2つの replica インスタンス「test-nishimura-02」と「test-nishimura-03」で「サービス用読み込み」を行う構成。
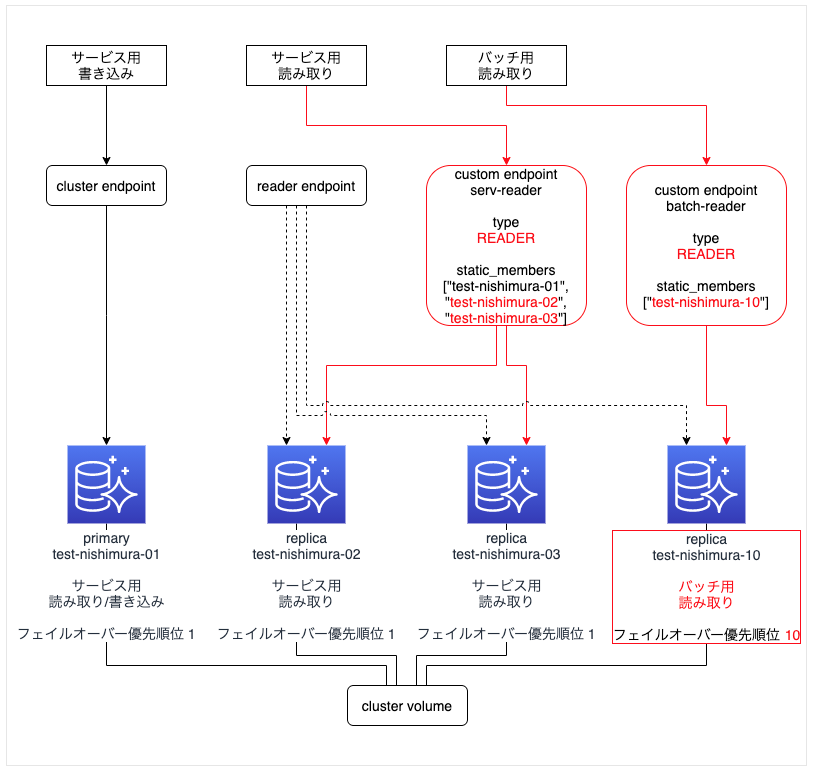
バッチ用 replica インスタンスを追加した構成
- 設定ポイントは、検証2 と同じ
- 図
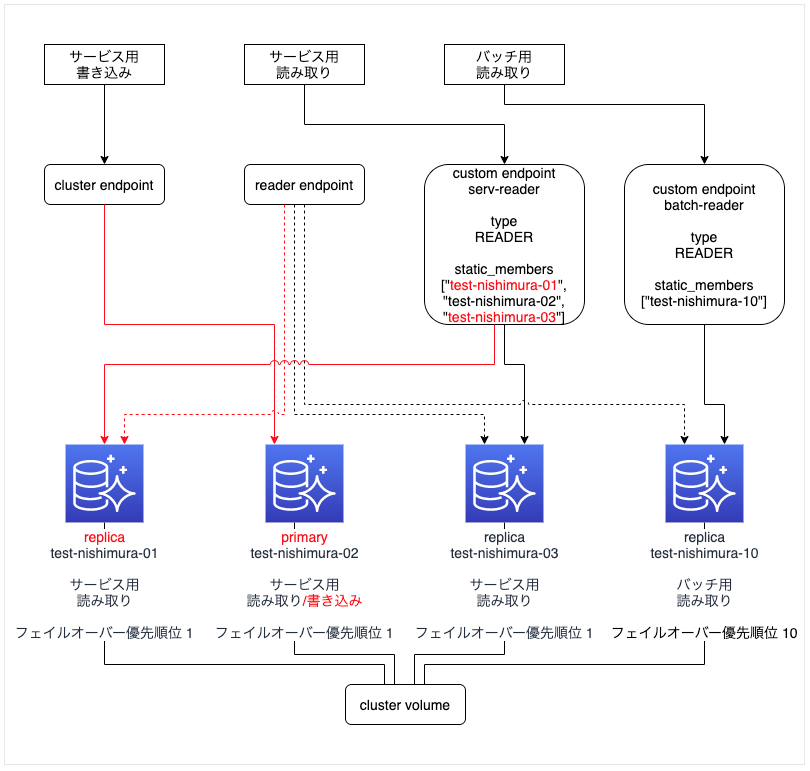
primary インスタンス「test-nishimura-01」をフェイルオーバーする
- 挙動は 検証2 と同じ
- 図
考察
- 検証2 と同じ
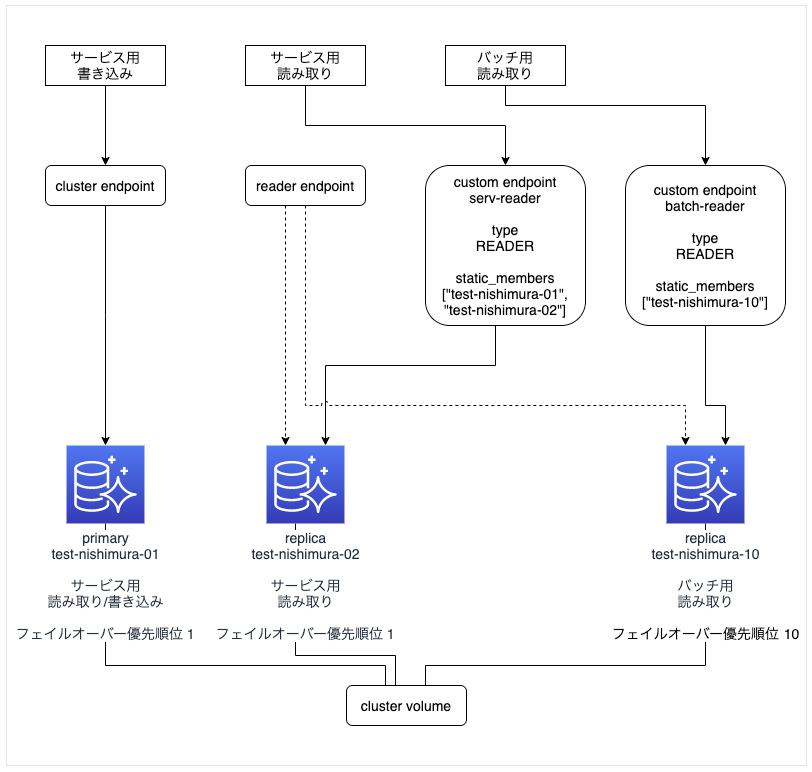
4. カスタムエンドポイントにメンバーを追加する検証
元の構成
- 1つの primary インスタンス「test-nishimura-01」で「サービス用書き込み」を、
1つの replica インスタンス「test-nishimura-02」で「サービス用読み込み」を、
1つの replica インスタンス「test-nishimura-10」でバッチ用読み込みを行う構成
(検証2 のバッチ用 replica インスタンスを追加した構成と同じ)。
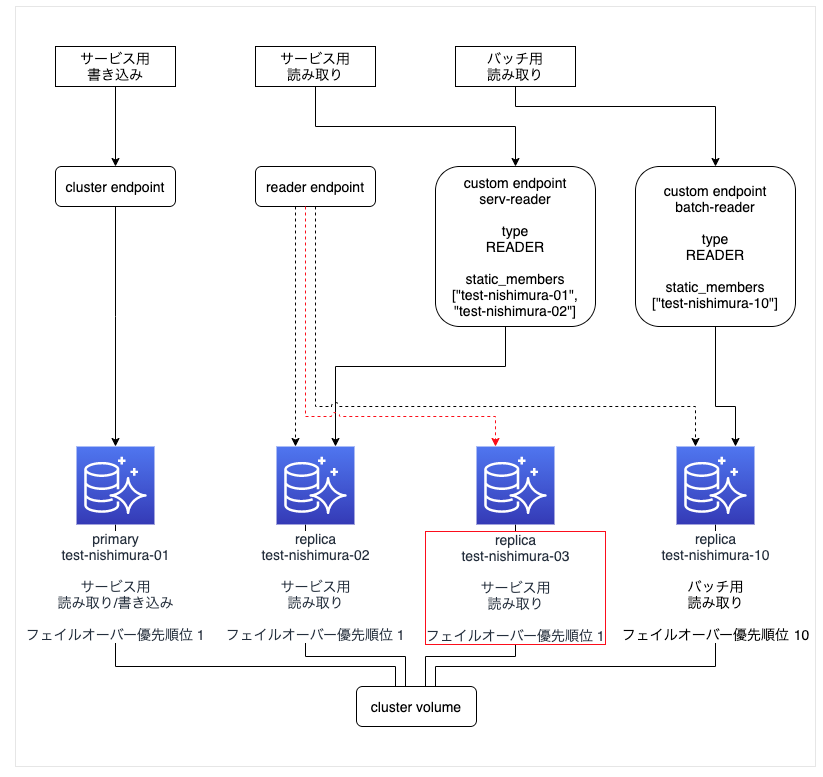
元の構成に サービス用読み取り replica を追加する
-
まずは、サービス用読み取り replica「test-nishimura-03」を新規作成する (terraformで)。
-
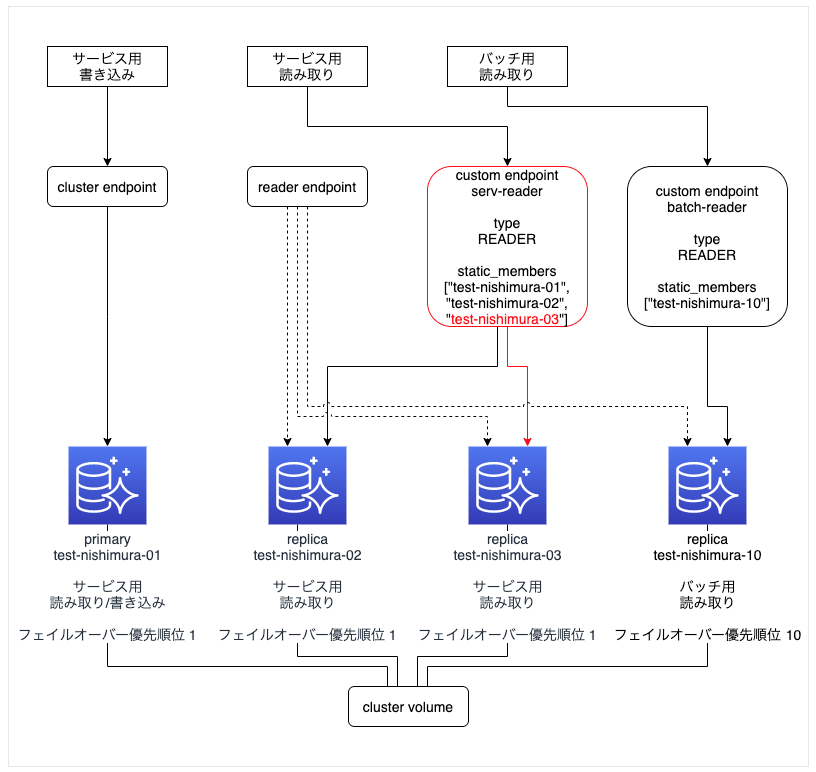
新しい replica 「test-nishimura-03」は、reader endpoint に自動的に追加されるが、custom endpoint「serv-reader」には追加されない
-
カスタムエンドポイント「serv-reader」の static_members 設定に 「test-nishimura-03」を追加する (terraformで)。
resource "aws_rds_cluster_endpoint" "serv-reader" {
cluster_endpoint_identifier = "serv-reader"
cluster_identifier = "test-nishimura"
custom_endpoint_type = "READER"
#static_members = ["test-nishimura-01", "test-nishimura-02"]
static_members = ["test-nishimura-01", "test-nishimura-02", "test-nishimura-03"]
}
- この時、各エンドポイントに対して1秒間隔で名前引きするスクリプトを動かしておく。
#!/bin/bash
LANG=C
for i in {1..2000}
do
date
dig +short serv-reader.cluster-custom-※※※※※※※※※※※※.ap-northeast-1.rds.amazonaws.com
sleep 1
echo
done
- 結果
- 11:03:24 ころに terraform plan を実施 (カスタムエンドポイント変更を開始)
$ sh dig-serv-reader-ep.sh
Sun Nov 8 11:03:24 JST 2020
test-nishimura-02.※※※※※※※※※※※※.ap-northeast-1.rds.amazonaws.com.
172.31.11.88
Sun Nov 8 11:03:25 JST 2020
test-nishimura-02.※※※※※※※※※※※※.ap-northeast-1.rds.amazonaws.com.
172.31.11.88
〜snip〜
Sun Nov 8 11:05:02 JST 2020
test-nishimura-02.※※※※※※※※※※※※.ap-northeast-1.rds.amazonaws.com.
172.31.11.88
Sun Nov 8 11:05:03 JST 2020
Sun Nov 8 11:05:04 JST 2020
〜snip〜
Sun Nov 8 11:06:21 JST 2020
Sun Nov 8 11:06:22 JST 2020
test-nishimura-02.※※※※※※※※※※※※.ap-northeast-1.rds.amazonaws.com.
172.31.11.88
Sun Nov 8 11:06:23 JST 2020
Sun Nov 8 11:06:24 JST 2020
test-nishimura-03.※※※※※※※※※※※※.ap-northeast-1.rds.amazonaws.com.
172.31.12.227
Sun Nov 8 11:06:25 JST 2020
Sun Nov 8 11:06:26 JST 2020
〜snip〜
Sun Nov 8 11:06:58 JST 2020
Sun Nov 8 11:06:59 JST 2020
Sun Nov 8 11:07:00 JST 2020
test-nishimura-02.※※※※※※※※※※※※.ap-northeast-1.rds.amazonaws.com.
172.31.11.88
Sun Nov 8 11:07:01 JST 2020
test-nishimura-02.※※※※※※※※※※※※.ap-northeast-1.rds.amazonaws.com.
172.31.11.88
Sun Nov 8 11:07:02 JST 2020
test-nishimura-03.※※※※※※※※※※※※.ap-northeast-1.rds.amazonaws.com.
172.31.12.227
Sun Nov 8 11:07:04 JST 2020
test-nishimura-03.※※※※※※※※※※※※.ap-northeast-1.rds.amazonaws.com.
172.31.12.227
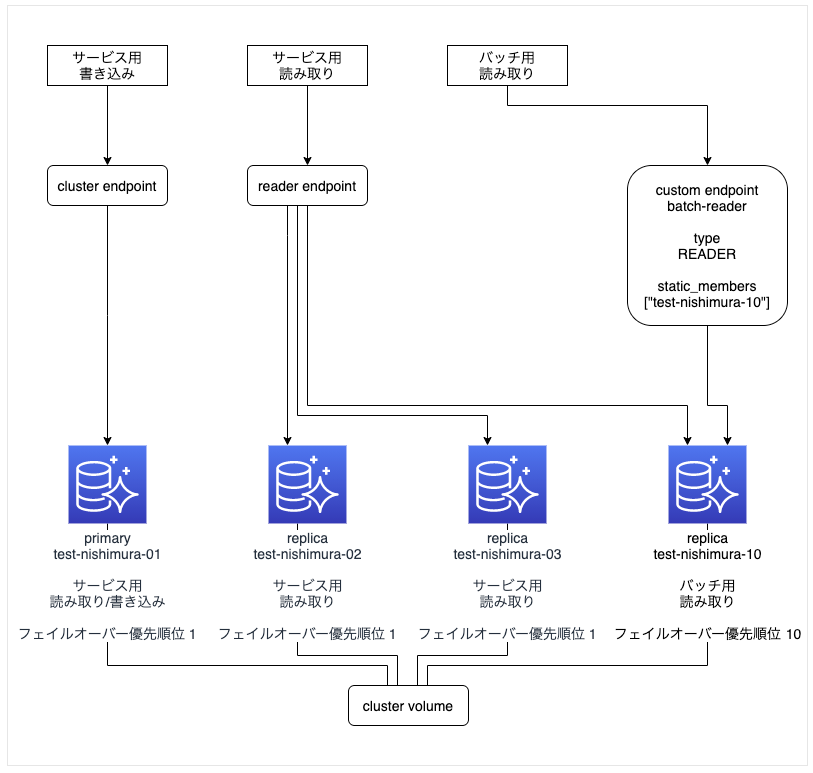
変更後の構成
考察
- やはり、カスタムエンドポイントの設定変更中は、数分間そのカスタムエンドポイントは使用できなくなる。
5. 個人的着地点
その1
1つの primary インスタンスで「サービス用書き込み」と「サービス用読み込み」を行っている構成に、バッチ用 replica インスタンスを追加したい場合
- もともとカスタムエンドポイントの利用を検討したきっかけは、検証1 のケースが発生したから。
- このケースの場合は、検証1 の「バッチ用 replica インスタンスを追加した構成」で良いと思う。
その2
サービス用レプリカを頻繁に即座にスケールイン・アウトしたい場合
- サービス用読み取りのカスタムエンドポイントは作成せずに、reader endpoint を使う。
- バッチ用読み取りのカスタムエンドポイントを作成する。
- そのインスタンスのクラスを他のサービス用インスタンスよりも高めにする(サービス用読み取りクエリも受けるため)。
- そのインスタンスのフェイルオーバー優先順を他のサービス用インスタンスよりも低めにする(primaryのフェイルオーバーによって昇格させないため)。
- 必要に応じて、 Amazon Aurora Auto Scaling でレプリカをスケールアウト/インする設定をいれる。
6. その他気になったこと
AWSマネジメントコンソール
- AWSマネジメントコンソールからカスタムエンドポイントを作成した場合は、カスタムエンドポイントのタイプが必ず「ANY」になってしまう。タイプを指定できる設定項目が存在しない。何でだろう・・
- 「今後追加されるインスタンスをこのクラスターにアタッチする」の利用目的がわからない・・
- カスタムエンポイントを作成するときは、タイプを「READER」にしたいとので、現時点でAWSマネジメントコンソールからカスタムエンドポイントを作成することはないな・・
terraform
- aws_rds_cluster_endpoinリソースでカスタムエンドポイントの作成・削除・編集ができる。
- AWSマネジメントコンソール設定できる「今後追加されるインスタンスをこのクラスターにアタッチする」の設定は、terraform ではできない。
7. 今後の期待
- カスタムエンドポイント設定変更中も、クラスターやリーダーエンドポイント同様に、名前解決が途切れることなく切り変わってほしい。